Автор: Денис Аветисян
Исследователи представили OpenVoxel — систему, способную группировать и описывать трехмерные сцены, используя только воксельную геометрию и возможности больших языковых моделей.
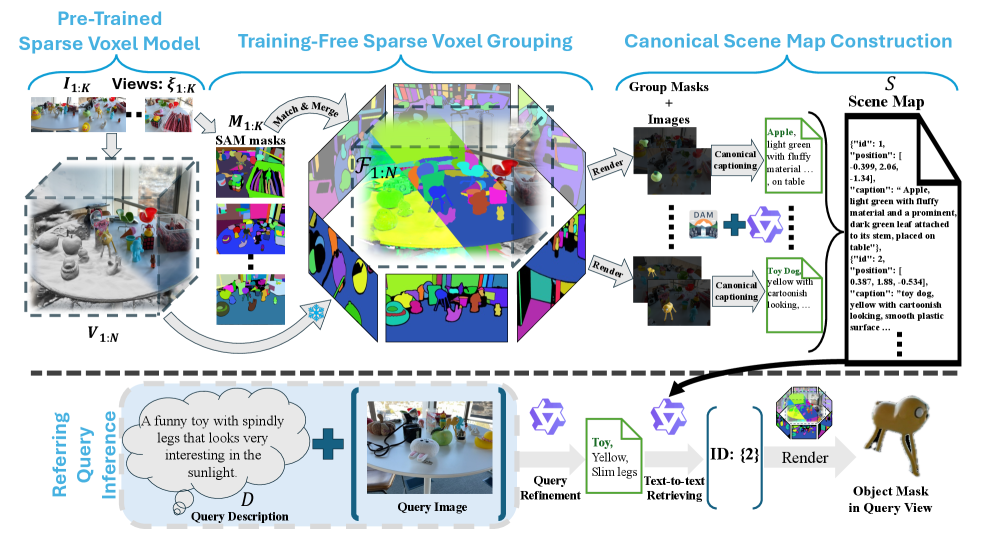
Предложен фреймворк OpenVoxel, позволяющий осуществлять сегментацию и идентификацию объектов в 3D-сценах без необходимости обучения и использования размеченных данных.
Несмотря на значительный прогресс в области 3D-понимания сцен, задача группировки и интерпретации воксельных данных в открытой лексике остается сложной. В данной работе, ‘OpenVoxel: Training-Free Grouping and Captioning Voxels for Open-Vocabulary 3D Scene Understanding’, предложен алгоритм OpenVoxel, позволяющий осуществлять группировку и описание разреженных вокселей без необходимости обучения, используя возможности больших мультимодальных языковых моделей. Этот подход обеспечивает создание информативной карты сцены и демонстрирует превосходные результаты в задачах сегментации и выделения объектов по текстовому описанию. Какие перспективы открываются для дальнейшего развития методов 3D-понимания сцен, основанных на использовании больших языковых моделей и разреженных воксельных представлений?
Тайны Трехмерного Мира: Вызов Реальности
Традиционные методы представления трехмерных сцен, такие как поля нейронного излучения (Neural Radiance Fields), демонстрируют впечатляющую реалистичность и детализацию, однако их вычислительная сложность представляет собой значительное препятствие для практического применения. Обучение и рендеринг этих моделей требуют значительных временных затрат и ресурсов, что делает невозможным использование в приложениях, требующих взаимодействия в реальном времени, например, в робототехнике или дополненной реальности. Несмотря на способность точно воспроизводить сложные сцены, текущие реализации часто сталкиваются с проблемами масштабируемости и эффективности, что стимулирует поиск новых, более быстрых и оптимизированных подходов к представлению и обработке трехмерных данных. Ускорение этих процессов является ключевой задачей для раскрытия полного потенциала трехмерного понимания сцены в широком спектре приложений.
Современные подходы к пониманию трехмерных сцен часто испытывают трудности при одновременной обработке лингвистической информации и пространственного мышления. Это ограничивает возможности выполнения сложных запросов и взаимодействия с виртуальным окружением. Например, система может успешно распознать объекты на изображении, но не сможет ответить на вопрос «Покажи мне самый большой красный куб слева от синего шара», требующий сопоставления языкового описания с трехмерной структурой сцены и пространственными отношениями между объектами. Данное несоответствие препятствует созданию действительно интеллектуальных систем, способных не только «видеть», но и «понимать» трехмерный мир, что критически важно для развития робототехники, дополненной реальности и других передовых технологий.
Актуальность эффективного и учитывающего язык понимания трехмерных сцен становится все более очевидной в контексте стремительного развития робототехники и технологий дополненной реальности. Способность робота ориентироваться в пространстве и взаимодействовать с объектами требует не только точного восприятия геометрии, но и понимания семантического значения окружающих предметов и их взаимосвязей, что достигается за счет интеграции лингвистической информации. В сфере дополненной реальности, подобное понимание позволяет создавать более интерактивные и интуитивно понятные пользовательские интерфейсы, где виртуальные объекты могут быть связаны с реальным миром посредством естественного языка. Таким образом, преодоление ограничений существующих методов в области 3D-понимания открывает новые возможности для создания интеллектуальных систем, способных к сложному взаимодействию с окружающей средой и пользователем.

OpenVoxel: Свобода от Обучения
OpenVoxel представляет собой фреймворк для понимания 3D-сцен, работающий без необходимости обучения. В отличие от традиционных подходов, требующих обширного обучения модели и оптимизации параметров для конкретных задач или сцен, OpenVoxel позволяет выполнять анализ 3D-сцен без предварительной тренировки. Это достигается за счет использования предварительно обученных фундаментальных моделей и инновационного подхода к представлению сцен, что позволяет избежать трудоемкого процесса адаптации модели к новым данным и снижает вычислительные затраты, связанные с обучением и оптимизацией.
OpenVoxel использует разреженное воксельное представление 3D-сцен, что позволяет эффективно визуализировать данные посредством Sparse Voxel Rasterization. В отличие от плотных воксельных представлений, требующих значительных вычислительных ресурсов для обработки и рендеринга, разреженное представление хранит только заполненные воксели, значительно сокращая объем требуемой памяти и вычислительную сложность. Этот подход обходит типичные узкие места, связанные с обработкой больших объемов данных в задачах 3D-восприятия, обеспечивая более быструю и эффективную визуализацию сцены.
В основе OpenVoxel лежит принцип прямого использования предварительно обученных фундаментальных моделей (foundation models) для анализа 3D-сцен, что позволяет достичь значительных результатов без необходимости в дополнительной настройке или обучении модели под конкретные типы сцен. Этот подход исключает этап трудоемкой тонкой настройки параметров модели под специфические данные, поскольку предварительно обученные модели уже содержат обобщенные знания об объектах и их взаимосвязях. Вместо этого, OpenVoxel адаптирует выходные данные этих моделей для работы со sparse voxel представлениями, обеспечивая эффективный анализ и понимание 3D-сцен без дополнительных вычислительных затрат на обучение.
Архитектура OpenVoxel: Заглядывая Внутрь
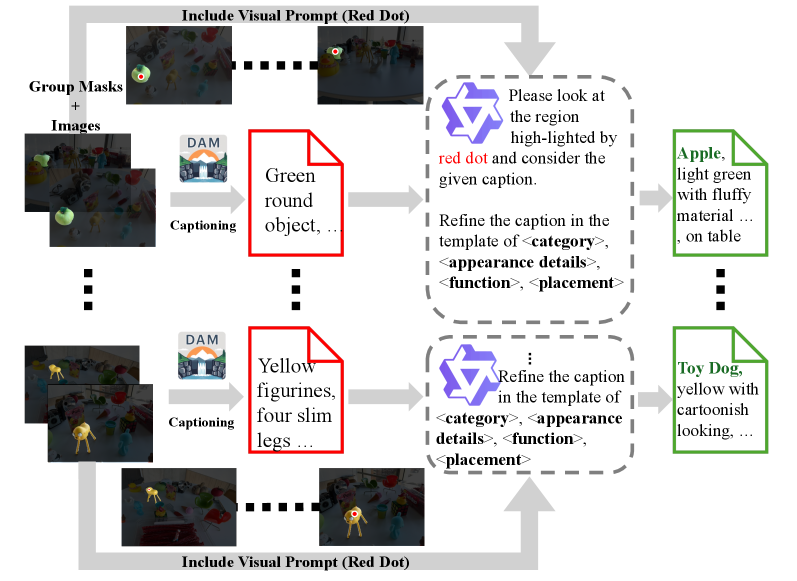
Построение канонической карты сцены осуществляется с использованием модели Describe Anything и Qwen3-VL для генерации детальных описаний и хранения богатой семантической информации для каждой группы вокселей. Модель Describe Anything автоматически генерирует текстовые подписи, описывающие содержимое каждого кластера вокселей, в то время как Qwen3-VL обеспечивает мультимодальную обработку, объединяя визуальные данные вокселей с текстовыми описаниями. Полученная семантическая информация, включающая текстовые описания и визуальные признаки, сохраняется в структуре данных карты сцены, позволяя осуществлять эффективный поиск и извлечение информации об объектах в 3D-сцене на основе текстовых запросов.
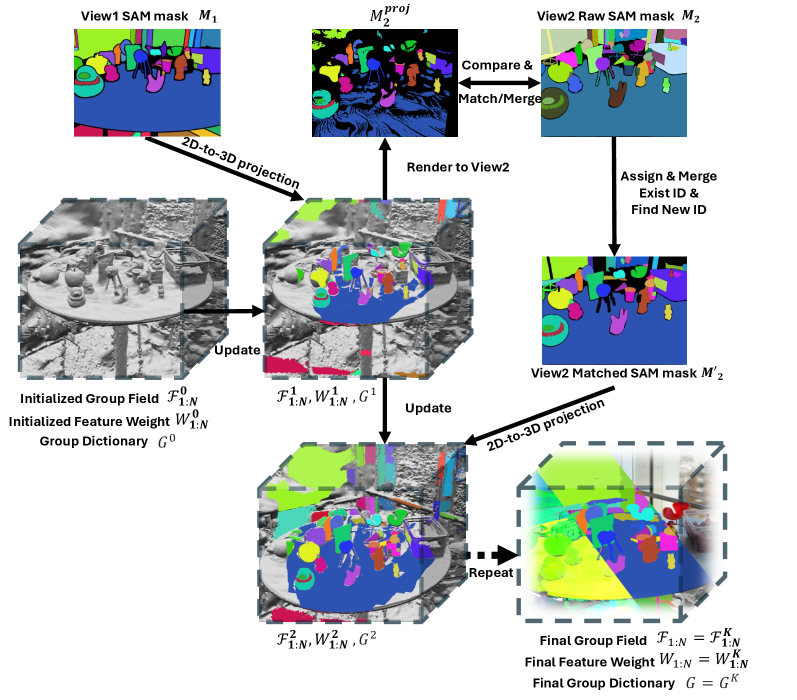
Процесс создания разреженных воксельных групп не требует обучения и использует модель SAM2 для сегментации объектов и формирования связных 3D-инстансов. В основе лежит использование предварительно обученных моделей компьютерного зрения, что позволяет избежать этапа дополнительной тренировки для конкретных задач. SAM2 выполняет сегментацию на основе входного изображения, выделяя отдельные объекты, после чего формируются воксельные группы, представляющие собой трехмерные модели этих объектов. Такой подход обеспечивает эффективное и быстрое создание 3D-представлений без необходимости в больших объемах размеченных данных и вычислительных ресурсов для обучения.
Процесс поиска по запросу осуществляется посредством извлечения информации из семантической карты сцены на основе текстовых запросов на естественном языке. В основе механизма лежит модель Qwen3-VL, которая выполняет сопоставление текста с текстом (text-to-text retrieval) для идентификации целевых объектов. Запрос пользователя обрабатывается моделью, которая сопоставляет его с подробными описаниями воксельных групп, хранящимися в семантической карте. Результатом является определение соответствующих воксельных групп, представляющих объекты, соответствующие запросу пользователя, что позволяет системе точно локализовать и идентифицировать элементы в 3D-сцене.
Подтверждение Эффективности и Дальнейшие Перспективы
Разработанная система OpenVoxel демонстрирует передовые результаты в задачах сегментации открытой лексики и сегментации по текстовому описанию, что подтверждается валидацией на наборе данных LeRF. Данный подход позволяет точно выделять и идентифицировать объекты на изображениях, даже если они ранее не встречались в обучающей выборке, благодаря использованию нейронных сетей и инновационных методов представления данных. Высокая производительность OpenVoxel открывает новые возможности для компьютерного зрения и обработки изображений, позволяя создавать более интеллектуальные и адаптивные системы, способные понимать и взаимодействовать с окружающим миром на качественно новом уровне.
В ходе тестирования на датасете Ref-LeRF, система OpenVoxel продемонстрировала значительное превосходство в задаче сегментации по текстовому описанию. Достигнутый показатель Mean IoU составил 73.1%, что на 13.2% превышает результаты, полученные при воспроизведении алгоритма ReferSplat. Такой существенный прирост точности указывает на эффективность предложенного подхода к построению и анализу трехмерных сцен, позволяя более надежно идентифицировать и сегментировать объекты на основе словесных запросов и открывая новые возможности для взаимодействия с виртуальными окружениями.
В рамках исследований было продемонстрировано, что система OpenVoxel способна создавать карты сцены в десять раз быстрее, чем современные аналоги, затрачивая на этот процесс всего три минуты. Эта значительная оптимизация достигается благодаря инновационной архитектуре и эффективным алгоритмам обработки данных, позволяющим существенно сократить время вычислений без потери точности. Высокая скорость построения карт сцены открывает новые возможности для применения OpenVoxel в динамических 3D-средах, а также для задач, требующих обработки данных в реальном времени, например, в робототехнике и системах дополненной реальности.
Представленная система OpenVoxel выходит за рамки анализа статичных трехмерных сцен, открывая новые возможности для создания динамичных и интерактивных виртуальных сред. Данный подход позволяет не только точно реконструировать окружающее пространство, но и оперативно адаптироваться к изменениям в нем, что критически важно для широкого спектра приложений. В частности, технология имеет огромный потенциал в робототехнике, где роботы смогут эффективно ориентироваться и взаимодействовать с постоянно меняющимся окружением. Кроме того, OpenVoxel может найти применение в сферах дополненной и виртуальной реальности, обеспечивая более реалистичное и отзывчивое взаимодействие пользователя с цифровым миром. Наконец, система способна стать основой для создания цифровых двойников — виртуальных копий реальных объектов и сред, используемых для моделирования, анализа и оптимизации различных процессов.
![Эксперименты на сцене Teatimes показали, что ReferSplat [He et al., 2025b] испытывает трудности с распознаванием ранее невиденных объектов, что свидетельствует о склонности к переобучению на размеченных данных.](https://arxiv.org/html/2601.09575v1/x10.png)
Работа демонстрирует, что даже без обучения, при должном подходе к представлению данных, можно заставить модели понимать окружающий мир. OpenVoxel, оперируя разреженными вокселями, словно шепчет хаосу цифр, уговаривая его принять нужную форму. Всё это напоминает о словах Фэй-Фэй Ли: «Данные — это не цифры, а шёпот хаоса». По сути, эта система — не столько предсказание, сколько умение интерпретировать существующий порядок в трехмерном пространстве, извлекая смысл из кажущейся случайности. Отказ от обучения — не слабость, а признание того, что истинное понимание рождается из способности к адаптации, а не из жестко заданных параметров.
Что дальше?
Предложенный подход, избавляясь от необходимости обучения, безусловно, заманчив. Однако, стоит помнить: всё, что можно посчитать, не стоит доверия. Отсутствие обучения — это не победа над хаосом, а лишь его временное умиротворение. Иллюзия понимания возникает из-за умения приводить разрозненные факты к единому знаменателю, а не из истинного постижения структуры мира. Если OpenVoxel успешно работает без обучения, скорее всего, мы просто не искали достаточно глубоко, чтобы обнаружить скрытые закономерности, требующие адаптации.
Будущие исследования неизбежно столкнутся с необходимостью оценки робастности системы в условиях неидеальных данных. Шум, артефакты, неполнота информации — всё это шепот хаоса, который рано или поздно разрушит хрупное здание без обучения. Попытки обойти ограничения за счёт увеличения масштаба данных или сложности модели, вероятно, лишь отсрочат неизбежное. Более интересным представляется поиск методов, позволяющих модели «слушать» этот шепот и использовать его для самокоррекции.
В конечном счёте, OpenVoxel — это не конец пути, а лишь очередная ступенька. Следующим шагом видится создание систем, способных не просто понимать сцену, но и предвидеть её изменения, адаптироваться к новым условиям и, возможно, даже творить новые миры. Но стоит помнить: любая модель — это заклинание, которое работает до первого продакшена.
Оригинал статьи: https://arxiv.org/pdf/2601.09575.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Борьба: Китай и США на Передовой
- Квантовые симуляторы: проверка на прочность
- Квантовые нейросети на службе нефтегазовых месторождений
- Искусственный интеллект заимствует мудрость у природы: новые горизонты эффективности
- Интеллектуальная маршрутизация в коллаборации языковых моделей
- Квантовый скачок: от лаборатории к рынку
2026-01-16 05:08