Автор: Денис Аветисян
Новое исследование показывает, что обучение на задачах разной сложности не гарантирует улучшения производительности нейронных сетей при переходе на задачи других уровней.

Работа посвящена анализу способности больших языковых моделей к обобщению на задания различной сложности, используя принципы теории отклика на вопросы.
Несмотря на впечатляющие успехи больших языковых моделей (LLM), вопрос об их способности к обобщению на задачах различной сложности остается открытым. В работе ‘Revisiting Generalization Across Difficulty Levels: It’s Not So Easy’ проводится систематическое исследование обобщающей способности LLM, основанное на оценке сложности примеров из шести наборов данных с использованием как результатов работы тысяч LLM, так и теории отклика на предметы. Полученные результаты демонстрируют, что обучение на примерах как высокой, так и низкой сложности не обеспечивает стабильного улучшения производительности во всем диапазоне сложностей. Не означает ли это, что для эффективного обучения и оценки LLM необходимо учитывать разнообразие уровней сложности задач?
Оценка Обобщающей Способности: Преодоление Границ Языковых Моделей
Современные языковые модели демонстрируют впечатляющую эффективность при работе с данными, на которых они были обучены, однако их способности заметно снижаются при столкновении с задачами, отличающимися по сложности или формату представления информации. Это проявляется в том, что модель, успешно справляющаяся с простыми вопросами, может испытывать затруднения при решении более сложных, требующих логического вывода или анализа контекста. Аналогично, изменение формата входных данных — например, переход от четко сформулированного вопроса к неполной фразе или запросу с опечатками — может существенно ухудшить результаты. Данное ограничение подчеркивает необходимость разработки моделей, способных к более гибкому и адаптивному обучению, позволяющего им эффективно функционировать в реальных условиях, где данные часто отличаются от тех, что использовались при обучении.
Оценка и улучшение способности к обобщению на задачах различной сложности является ключевым фактором в создании действительно надежных систем искусственного интеллекта. Современные языковые модели часто демонстрируют высокие результаты на обучающих данных, однако их производительность резко снижается при столкновении с задачами, отличающимися по уровню сложности или формату представления. Развитие способности к обобщению на задачах различной сложности позволяет создавать системы, способные адаптироваться к новым, неожиданным ситуациям, не требуя переобучения или тонкой настройки. Исследования показывают, что модели склонны к концентрации производительности вокруг задач, близких по сложности к тем, на которых они обучались, что подчеркивает необходимость разработки новых методов и метрик для оценки и повышения устойчивости к изменениям в сложности решаемых задач. Это, в свою очередь, открывает возможности для создания более гибких, универсальных и надежных систем ИИ, способных эффективно функционировать в реальных условиях.
Исследования показали, что стандартные метрики оценки языковых моделей не способны адекватно отразить, как их вычислительные возможности проявляются при решении задач различной сложности. Полученные результаты демонстрируют ограниченную способность моделей к обобщению между уровнями сложности: их производительность наиболее высока на задачах, сопоставимых по сложности с теми, на которых они обучались. Это указывает на то, что увеличение размера модели не всегда приводит к улучшению обобщающей способности, и что необходимы новые подходы к оценке и обучению, учитывающие вариативность сложности задач. Фактически, модели склонны «концентрироваться» на задачах определенного уровня, демонстрируя существенное снижение эффективности при переходе к более сложным или, наоборот, слишком простым заданиям.

Количественная Оценка Сложности: Выход за Рамки Субъективных Оценок
Предлагаемый нами подход к оценке сложности задач, обозначенный как ‘Difficulty Estimation’, разработан для преодоления ограничений, связанных с использованием субъективных, основанных на оценках людей, метрик сложности. Традиционные методы часто полагаются на экспертные оценки или краудсорсинг, что приводит к непоследовательности и зависимости от индивидуального опыта. Наша система, в отличие от этого, стремится к объективному определению сложности, используя статистические модели для анализа характеристик самих задач, а не восприятия людей. Это позволяет создать более надежную и воспроизводимую шкалу сложности, применимую к широкому спектру задач и моделей.
Для определения объективного уровня сложности задач используется теория отклика на задачу (IRT), статистическая модель, оценивающая вероятность правильного ответа в зависимости от способности решающего и сложности самой задачи. В рамках IRT каждому элементу (задаче) присваивается значение сложности, представляющее собой параметр $b_i$, отражающий порог способности, необходимый для 50%-й вероятности правильного ответа. Модель предполагает, что вероятность правильного ответа описывается логистической функцией, учитывающей как сложность задачи, так и уровень компетентности решающего. Параметры модели оцениваются с использованием методов максимального правдоподобия на основе данных о результатах выполнения задач различными участниками.
Для валидации разработанной системы оценки сложности задач использовались разнообразные наборы данных, включая ARC, GSM8K, MMLU-Pro, BBH, MATH и MuSR. Анализ корреляции между значениями сложности, полученными с помощью теории отклика на задачу (IRT), и субъективными оценками, предоставленными людьми, показал, что она, как правило, слабая. Это указывает на расхождение между автоматической оценкой сложности на основе IRT и восприятием сложности человеком, что требует дальнейшего исследования и калибровки системы.

Выявление Паттернов Обобщения: От Простого к Сложному и Обратно
Анализ показывает, что языковые модели демонстрируют оба типа обобщения: от простого к сложному («Easy-to-Hard Generalization») и от сложного к простому («Hard-to-Easy Generalization»). Это означает, что модели, обученные на простых задачах, могут успешно справляться с более сложными, и наоборот, модели, обученные на сложных задачах, могут показывать хорошие результаты на более простых задачах. Наблюдается, что оба этих типа обобщения встречаются в различных моделях и на различных наборах данных, что указывает на сложную взаимосвязь между сложностью задачи и способностью модели к обобщению.
Наши исследования показали, что модели, прошедшие тонкую настройку на более сложных задачах, зачастую демонстрируют превосходящие результаты по сравнению с моделями, обученными на более простых задачах, при тестировании на упрощенных проблемах. Этот феномен указывает на то, что решение сложных задач может способствовать развитию у модели более общих навыков решения проблем, которые применимы и к более легким задачам. В частности, модели, обученные на сложных наборах данных, лучше справляются с экстраполяцией и переносом знаний, что позволяет им эффективнее решать более простые задачи, где менее сложные модели могут допускать больше ошибок. Этот результат противоречит интуитивному предположению о том, что обучение на простых задачах всегда обеспечивает лучшую производительность на простых задачах.
Наше исследование показало, что общая способность к обобщению у языковых моделей ограничена. Несмотря на то, что модели, обученные на более сложных задачах, могут превосходить модели, обученные на более простых, в решении задач меньшей сложности, это не приводит к стабильному улучшению производительности на задачах всех уровней сложности. Результаты демонстрируют, что обучение на определенном уровне сложности не гарантирует улучшения обобщающей способности модели в целом, и наблюдается несоответствие между сложностью обучающих данных и способностью модели к обобщению на задачах различной сложности.
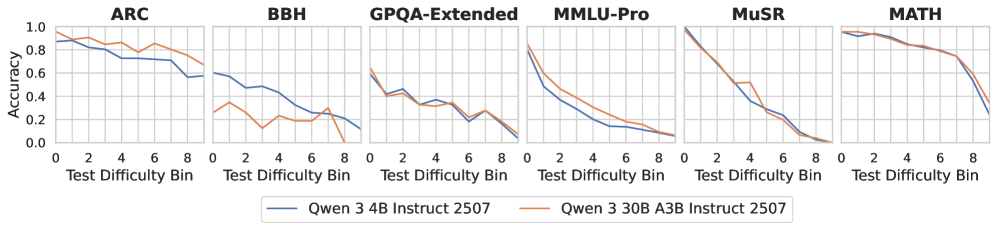
Тонкая Настройка для Надежной Производительности: Достижение Оптимальных Результатов
Для адаптации моделей Qwen и Llama к различным уровням сложности задач применялись методы тонкой настройки, или fine-tuning. Этот процесс подразумевает дальнейшее обучение предварительно обученной модели на специализированном наборе данных, соответствующем конкретным уровням сложности. В результате, модели приобрели способность более эффективно решать задачи различной трудности, демонстрируя повышенную устойчивость и точность. Тонкая настройка позволила оптимизировать параметры моделей для достижения оптимальной производительности в рамках установленной системы оценки, что подтверждается результатами, опубликованными на Open LLM Leaderboard.
Эксперименты показали, что модели демонстрируют значительное улучшение производительности при обучении на данных, охватывающих широкий спектр уровней сложности. Обучение, включающее как простые, так и сложные примеры, позволяет моделям лучше обобщать знания и эффективнее справляться с разнообразными задачами. Этот подход способствует формированию более устойчивых и гибких нейронных сетей, способных адаптироваться к новым, ранее не встречавшимся условиям. В результате, модели, прошедшие обучение на данных различной сложности, демонстрируют повышенную точность и надежность в различных сценариях применения, что делает их более полезными и востребованными.
Результаты экспериментов, включающие детальную оценку производительности адаптированных моделей Qwen и Llama, находятся в открытом доступе на платформе Open LLM Leaderboard. Публикация этих данных призвана обеспечить прозрачность и способствовать более глубокому пониманию возможностей и ограничений современных больших языковых моделей в сообществе исследователей и разработчиков. Открытый доступ к результатам позволяет другим специалистам воспроизвести эксперименты, провести сравнительный анализ и внести свой вклад в развитие области, стимулируя дальнейшие инновации и улучшения в сфере искусственного интеллекта. Эта практика способствует коллективному прогрессу и ускоряет темпы исследований в области обработки естественного языка.

Исследование, представленное в статье, демонстрирует ограниченные возможности обобщения у больших языковых моделей при переходе между задачами разной сложности. Это подтверждает необходимость пристального внимания к корректности алгоритмов и их способности к формальному доказательству. Как отмечал Джон Маккарти: «Всякий, кто пытается программировать без математической логики, обречен на создание хаотичных систем». Данное наблюдение особенно актуально в контексте оценки сложности задач, поскольку недостаточная точность в определении этой самой сложности препятствует созданию действительно обобщающих моделей, способных к эффективной работе на задачах любой сложности.
Что дальше?
Представленное исследование, констатируя ограниченность способности больших языковых моделей к обобщению между задачами различной сложности, подчёркивает фундаментальную проблему: простое увеличение объёма обучающих данных не гарантирует приобретение истинной интеллектуальной гибкости. Наблюдаемая неспособность к переносу знаний между уровнями сложности указывает на необходимость переосмысления метрик оценки обобщающей способности — достаточно ли констатировать “работу на тестах”, или требуется доказательство асимптотической устойчивости алгоритма к изменениям в распределении входных данных?
Перспективы дальнейших исследований лежат, вероятно, в области разработки более точных моделей оценки сложности задач, выходящих за рамки стандартной теории отклика на предметы. Необходимо сосредоточиться на выявлении тех характеристик задач, которые препятствуют переносу знаний, и разработке алгоритмов, способных адаптироваться к этим особенностям. Простое масштабирование моделей, без углублённого анализа принципов обучения, рискует лишь усугубить существующие проблемы.
Истинная элегантность в машинном обучении заключается не в количестве параметров, а в способности алгоритма к абстракции и обобщению. Поиск таких алгоритмов требует не только вычислительных ресурсов, но и глубокого математического осмысления принципов познания — задачи, кажущейся на первый взгляд куда более сложной, чем обучение нейронной сети.
Оригинал статьи: https://arxiv.org/pdf/2511.21692.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Устойчивое обучение языковых моделей: новый подход к контролю стратегии
- Сердце музыки: открытые модели для создания композиций
- Квантовый усилитель света на чипе: новый уровень эффективности
- Самообучающиеся системы: новый подход к созданию многоагентных взаимодействий
- Взгляд под капот: Анализ кода, сгенерированного нейросетями
- Квантовые системы в полуклассическом режиме: новый подход к моделированию
- 💸 Великобритания тратит 500 миллионов фунтов стерлингов на квантовые технологии – может быть, кот Шрёдингера только что разбогател?
- Искусственный интеллект и архитектура будущего: новый виток эволюции
- Искусственный интеллект: курс для жизни и общества
- Самостоятельность в эпоху ИИ: Как студенты учатся учиться с искусственным интеллектом
2025-11-27 11:40