Автор: Денис Аветисян
Новое исследование предлагает масштабируемый и биологически правдоподобный метод обучения рекуррентных импульсных нейронных сетей, основанный на распространении пригодности, управляемом событиями.
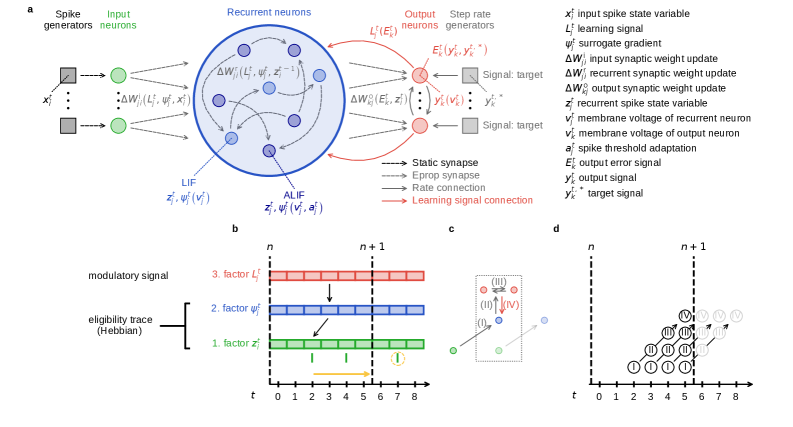
Предложен алгоритм распространения пригодности, адаптированный для больших разреженных импульсных нейронных сетей, демонстрирующий сопоставимую производительность с традиционными методами, но с повышенной эффективностью и биологической достоверностью.
Несмотря на значительный прогресс в области искусственного интеллекта, достижение энергоэффективности и масштабируемости остается сложной задачей. В работе под названием ‘Event-driven eligibility propagation in large sparse networks: efficiency shaped by biological realism’ предложен биологически правдоподобный подход к обучению рекуррентных спайковых нейронных сетей, основанный на событийно-управляемом распространении пригодности. Показано, что предложенный метод обеспечивает сопоставимую с традиционными алгоритмами производительность, при этом существенно повышая вычислительную эффективность и приближая модели к принципам работы мозга. Сможет ли данная концепция стать основой для создания устойчивых и масштабируемых систем искусственного интеллекта, вдохновленных нейробиологией?
За гранью традиционного обучения: Необходимость событийных систем
Современные системы глубокого обучения, демонстрирующие впечатляющие результаты в различных областях, зачастую требуют непрерывных и энергозатратных вычислений. В отличие от биологических нейронных сетей, которые обрабатывают информацию лишь при появлении значимых событий, искусственные системы постоянно активны, даже когда входные данные не меняются. Эта постоянная активность приводит к значительному потреблению энергии и ограничивает возможности развертывания на устройствах с ограниченными ресурсами. Эффективность мозга заключается в его способности реагировать на изменения в окружающей среде, а не в постоянном пересчете всех возможных сценариев. Поэтому, разработка систем, способных к разреженной активности и обработке событий, представляется ключевым шагом на пути к созданию более энергоэффективного и адаптивного искусственного интеллекта, приближенного к принципам работы мозга.
Биологические нейронные сети отличаются принципиальной экономией ресурсов при обработке информации. В отличие от современных алгоритмов глубокого обучения, требующих непрерывных вычислений, мозг реагирует преимущественно на события, а не на постоянное обновление данных. Такой подход, известный как разреженное кодирование, позволяет нейронам активироваться лишь при получении значимого сигнала, значительно снижая энергопотребление и ускоряя процесс обучения. По сути, нервная система функционирует, как система раннего оповещения, фокусируясь на изменениях в окружающей среде и игнорируя статичные данные, что обеспечивает высокую скорость реакции и эффективность использования энергии. Эта концепция представляет собой перспективное направление для разработки более энергоэффективных и адаптивных систем искусственного интеллекта.
Переход к обучению, ориентированному на события, требует разработки принципиально новых правил обучения, способных адаптироваться к асинхронной, импульсной коммуникации. В отличие от традиционных подходов, где информация обрабатывается непрерывно, эта система реагирует исключительно на значимые изменения во входных данных, имитируя эффективность биологических нейронных сетей. Такие правила обучения должны учитывать временные задержки между событиями и не требовать глобальной синхронизации, что позволяет создавать системы с минимальным энергопотреблением и высокой скоростью обучения. Разработка подобных алгоритмов представляет собой сложную задачу, требующую учета не только силы сигнала, но и точного момента его поступления, что открывает новые возможности для создания интеллектуальных систем, способных к адаптации и самообучению в реальном времени.
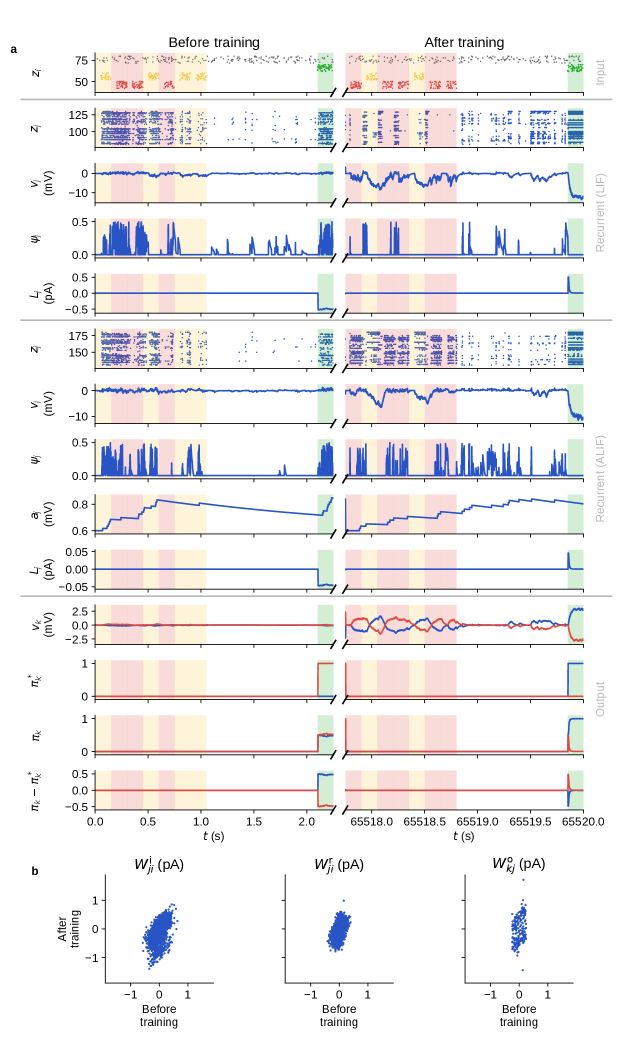
E-prop: Локальное и причинно-следственное правило обучения
Алгоритм E-prop представляет собой правило обучения, основанное на событиях, которое обновляет синаптические веса исключительно при одновременной активации пре- и постсинаптических нейронов. Такой подход позволяет избежать ненужных вычислений и эффективно распределять вычислительные ресурсы, поскольку обновления происходят только в ответ на значимые изменения в активности сети. Это обеспечивает экономию энергии и повышает скорость обучения, особенно в больших нейронных сетях, где глобальные обновления весов могут быть вычислительно затратными и неэффективными. Принцип работы алгоритма предполагает, что синаптическая пластичность напрямую связана с временной корреляцией между пре- и постсинаптическими импульсами.
В основе алгоритма E-prop лежит концепция следа пригодности (eligibility trace), представляющего собой память о недавней активности нейрона. Этот след, как правило, представляет собой экспоненциально затухающее среднее активаций, позволяющее оценить вклад каждого пресинаптического нейрона в активацию постсинаптического. Значение следа пригодности используется для взвешивания изменений веса синапса, таким образом, только те синапсы, которые внесли значимый вклад в активацию постсинаптического нейрона, подвергаются обновлению. Такой подход позволяет установить причинно-следственную связь между активностью пре- и постсинаптических нейронов, обеспечивая локальное и эффективное обучение, основанное на реальном вкладе каждого синапса в текущую активность сети.
Локальность алгоритма E-prop, заключающаяся в том, что обновления синаптических весов зависят исключительно от активности пре- и постсинаптических нейронов, значительно упрощает его реализацию и способствует масштабируемости. В отличие от глобального градиентного спуска, требующего синхронизации и обработки информации по всей сети, E-prop выполняет обновления локально, непосредственно в синапсе при совпадении активности. Это позволяет избежать «узких мест» и задержек, возникающих при глобальных обновлениях, а также снижает вычислительные затраты, особенно в крупномасштабных нейронных сетях.
В алгоритме E-prop для эффективной реализации обратного распространения ошибки в сетях, основанных на спайках, используется суррогатный градиент. Нейроны, функционирующие по принципу «все или ничего», имеют недифференцируемую функцию активации — ступенчатую функцию. Для преодоления этой проблемы, вместо фактического градиента ступенчатой функции, используется дифференцируемая аппроксимация, такая как сигмоидальная функция или гиперболический тангенс. Это позволяет вычислить градиент и обновить веса синапсов, даже если функция активации не является дифференцируемой, обеспечивая эффективное обучение спайковых нейронных сетей.
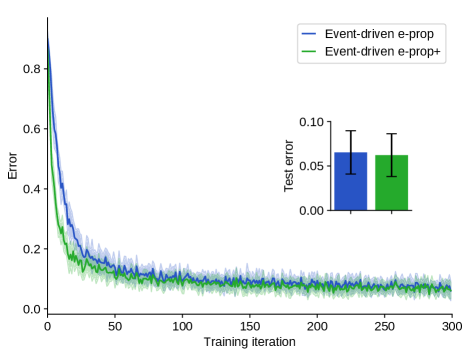
Реализация E-prop в спайковых нейронных сетях
Алгоритм E-prop реализован посредством специализированных компонентов — нейрона EpropNeuron и синапса EpropSynapse. Эти компоненты обеспечивают обновления, запускаемые событиями (event-driven updates), что позволяет сети реагировать непосредственно на входящие спайки. В отличие от традиционных алгоритмов обратного распространения ошибки, E-prop не требует глобальной синхронизации и вычислений градиентов. Вместо этого, обновления весов синапсов происходят локально в ответ на активность пре- и постсинаптических нейронов, что повышает энергоэффективность и позволяет реализовать обучение в реальном времени. Компоненты EpropNeuron и EpropSynapse совместно формируют основу для обучения в спайковых нейронных сетях без использования традиционных градиентов.
Нейрон EpropNeuron реализует адаптивный механизм порога, позволяющий динамически регулировать чувствительность к входным сигналам на основе их статистики. Этот механизм позволяет нейрону автоматически изменять уровень активации, необходимый для генерации спайка, в зависимости от частоты и интенсивности входящих сигналов. В частности, при увеличении частоты входящих спайков порог активации повышается, снижая вероятность нежелательных ложных срабатываний, и наоборот — при снижении частоты порог понижается, увеличивая чувствительность к слабым сигналам. Такая адаптация позволяет нейрону эффективно обрабатывать входные данные с переменной статистикой и оптимизировать свою реакцию на различные стимулы, улучшая общую производительность сети.
Реализация алгоритма E-prop использует принципы пластичности, зависящей от времени спайков (STDP), для уточнения синаптических связей. STDP предполагает, что сила синапса изменяется в зависимости от относительного времени прибытия пре- и постсинаптических спайков. Если пресинаптический спайк предшествует постсинаптическому, синапс усиливается (Long-Term Potentiation — LTP). В противном случае, если пресинаптический спайк следует за постсинаптическим, синапс ослабляется (Long-Term Depression — LTD). Величина изменения синаптической силы зависит от временного интервала между спайками; более короткие интервалы приводят к более существенным изменениям. Таким образом, STDP позволяет сети обучаться, связывая причинно-следственные связи между событиями, представленными во времени, и оптимизируя синаптические веса для повышения эффективности обработки информации.
Компонент ArchivingNode предназначен для хранения информации о прошлой активности нейронной сети, что позволяет алгоритму E-prop обучаться на основе предыдущих событий и повышать свою производительность с течением времени. Этот компонент функционирует как долгосрочная память, сохраняя данные о временных метках спайков и других релевантных параметрах. Сохраняемая историческая активность используется для вычисления градиентов и обновления весов синапсов, позволяя сети адаптироваться к изменяющимся условиям и улучшать точность прогнозирования.
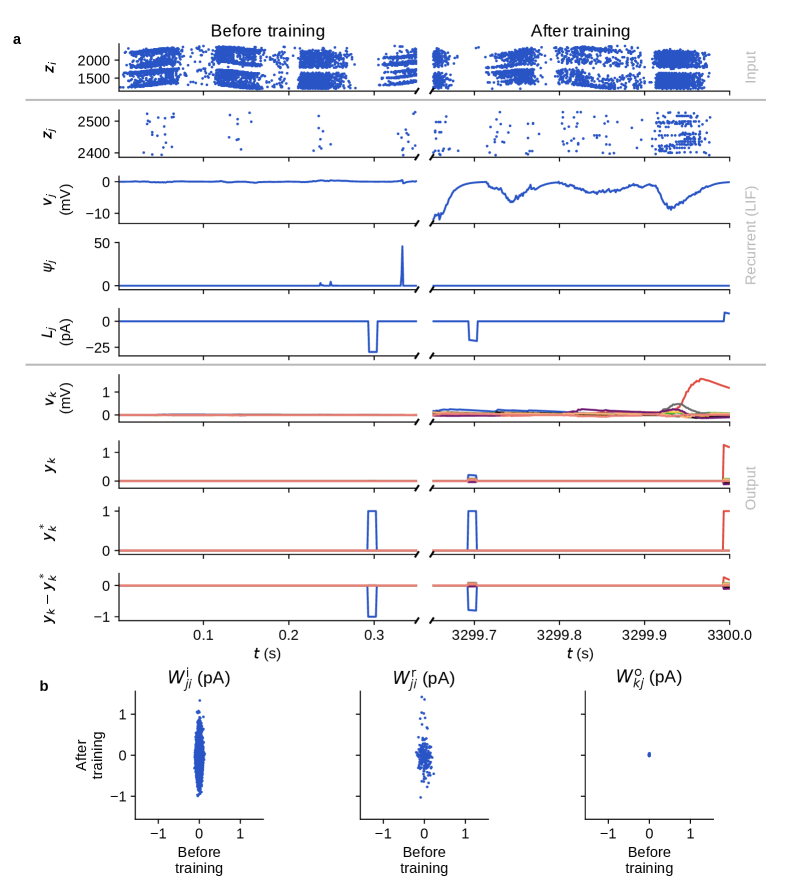
Производительность и перспективы дальнейших исследований
Исследования на наборе данных N-MNIST продемонстрировали, что алгоритм E-prop способен достигать сопоставимой производительности с традиционными подходами глубокого обучения, при этом обеспечивая существенную экономию энергии. В ходе экспериментов было показано, что E-prop эффективно решает задачу распознавания рукописных цифр, аналогичную той, что используется в классическом наборе MNIST, но с гораздо большим объемом данных и сложностью. Особенность заключается в том, что достижение сопоставимой точности при этом требует значительно меньшего количества вычислительных ресурсов и, следовательно, потребления энергии. Данный результат указывает на перспективность E-prop для создания энергоэффективных систем искусственного интеллекта, особенно в задачах, где ограничены вычислительные мощности и время работы от батареи, например, в мобильных устройствах и периферийных вычислениях.
Алгоритм E-prop, благодаря присущей ему разреженности и локальности вычислений, представляет особый интерес для реализации на нейроморфных аппаратных платформах. Эта особенность позволяет значительно снизить энергопотребление при обработке информации, поскольку вычисления производятся только для активных связей между нейронами, а не для всей сети. В отличие от традиционных вычислительных архитектур, где данные перемещаются между памятью и процессором, нейроморфные системы позволяют выполнять вычисления непосредственно в памяти, что еще больше сокращает потребление энергии. Такой подход открывает перспективы для создания ультра-маломощных систем искусственного интеллекта, способных к эффективной обработке данных непосредственно на устройствах, таких как мобильные телефоны, носимые датчики и автономные роботы.
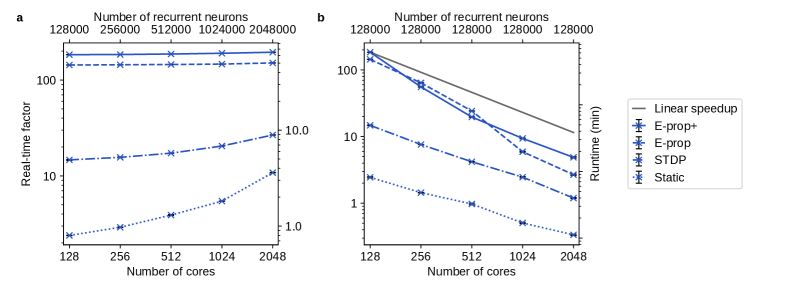
Разработанная платформа успешно масштабируется до нейронных сетей, насчитывающих миллионы нейронов, что демонстрирует впечатляющие характеристики масштабируемости. В частности, наблюдается сверхлинейное сильное масштабирование, означающее, что производительность увеличивается быстрее, чем количество используемых вычислительных ресурсов при фиксированном размере задачи. Одновременно с этим, достигается почти линейное слабое масштабирование, при котором время решения задачи остается относительно постоянным при увеличении как размера задачи, так и количества доступных ресурсов. Эти результаты указывают на то, что данная архитектура способна эффективно использовать параллельные вычислительные системы и потенциально подходит для решения масштабных задач искусственного интеллекта, требующих значительных вычислительных мощностей.
Дальнейшие исследования E-prop сосредоточены на расширении возможностей алгоритма для работы со сложными рекуррентными нейронными сетями. Это направление позволит создать системы, способные обрабатывать последовательности данных и демонстрировать поведение, близкое к человеческому мышлению. Особое внимание уделяется изучению потенциала E-prop в задачах непрерывного обучения, или «обучения на протяжении всей жизни». В рамках данного направления предполагается разработка алгоритмов, способных адаптироваться к новым данным и улучшать свои характеристики без необходимости переобучения с нуля, что открывает перспективы для создания самообучающихся систем, способных к долгосрочной работе в динамично меняющейся среде. Такой подход может привести к появлению интеллектуальных систем, способных к самостоятельному приобретению знаний и навыков на протяжении всего жизненного цикла.
Использование разреженной связности значительно повышает эффективность и масштабируемость представленного алгоритма. Вместо обработки каждого синапса при обновлении весов, алгоритм фокусируется лишь на небольшом подмножестве активных связей, что существенно снижает вычислительную нагрузку. Это достигается за счет того, что большинство связей в нейронной сети не участвуют в каждом отдельном шаге вычислений, а лишь активируются при определенных условиях. Такой подход позволяет сократить количество необходимых операций и, как следствие, уменьшить потребление энергии, особенно при работе с крупномасштабными нейронными сетями, содержащими миллионы нейронов. Разреженность также упрощает аппаратную реализацию, поскольку требуется меньше памяти и вычислительных ресурсов для хранения и обработки синаптических весов, что открывает возможности для создания энергоэффективных систем искусственного интеллекта.
Исследование демонстрирует, что даже элегантные математические модели, такие как правило распространения пригодности, неизбежно адаптируются к суровой реальности практической реализации. Авторы предлагают масштабируемое и биологически правдоподобное расширение, что закономерно — ведь нейронные сети, стремящиеся к реализму, должны учитывать ограниченность ресурсов и необходимость эффективной обработки событий. Как заметил Г.Х. Харди: «Математика — это не набор фактов, а способ мышления». Здесь это особенно заметно: принцип распространения пригодности, изначально абстрактный, обретает форму в контексте разреженных сетей и онлайн-обучения, демонстрируя, что теория без учета инженерных компромиссов обречена на академическую изоляцию. И вновь подтверждается, что архитектура — это не схема, а компромисс, переживший деплой.
Что дальше?
Представленная работа, безусловно, добавляет ещё один кирпичик в башню, которую кто-то когда-то назвал «искусственным интеллектом». Эффективность распространения eligibility в разреженных сетях — это хорошо. Особенно если это позволяет задержать неизбежный момент, когда продакшен начнёт генерировать ошибки, о которых авторы даже не подозревали. Биологическая правдоподобность — это приятно, пока не выяснится, что мозг устроен ещё сложнее, и все эти упрощения — просто самообман.
Однако, не стоит обольщаться. Проблема масштабируемости в нейронных сетях — это не техническая задача, а скорее философская. Каждая «революционная» архитектура рано или поздно сталкивается с ограничениями железа и алгоритмической сложности. Интересно, сколько ещё вариантов backpropagation нужно перебрать, прежде чем поймут, что проблема не в алгоритме, а в данных? Или, что ещё вероятнее, в фундаментальной несовместимости между математической моделью и реальным миром.
В конечном счете, всё новое — это старое, только с другим именем и теми же багами. Дальнейшие исследования, вероятно, сосредоточатся на оптимизации существующих методов и поиске новых способов скрыть недостатки. И это хорошо. Потому что, как известно, работа всегда найдёт способ сломать даже самую элегантную теорию. А до тех пор можно просто ждать.
Оригинал статьи: https://arxiv.org/pdf/2511.21674.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые системы в полуклассическом режиме: новый подход к моделированию
- Сердце музыки: открытые модели для создания композиций
- Белки-хамелеоны: Пределы предсказания гибкости структуры
- Энергоэффективность сотовой сети: обучение с подкреплением и управление режимами сна
- Самообучающиеся системы: новый подход к созданию многоагентных взаимодействий
- Растительность под прицетом ИИ: Оценка биофизических параметров по снимкам Sentinel-2
- Мир моделей: смогут ли роботы ориентироваться без карт?
- Маленькие модели – большие возможности: Искусственный интеллект в поиске онкологических исследований
- Искусственный интеллект против аналитика: кто точнее?
- Сжатие изображений и текста: как эффективно уменьшить размер больших моделей
2025-11-27 18:37