Автор: Денис Аветисян
Исследователи предлагают инновационный фреймворк для активного анализа и проверки объяснений работы внутренних механизмов больших языковых моделей.
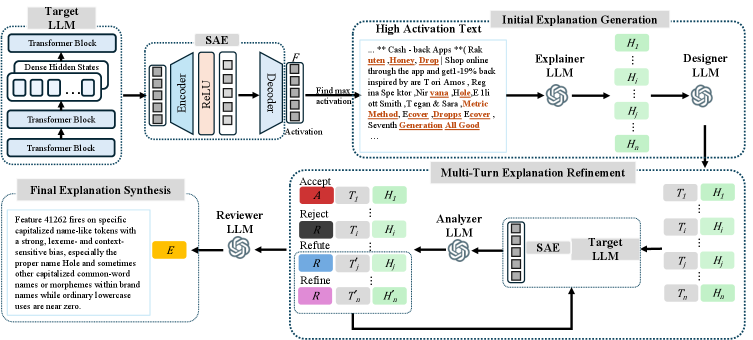
Представлен SAGE — агент-ориентированный фреймворк, позволяющий интерпретировать особенности, выявленные с помощью разреженных автокодировщиков (Sparse Autoencoders) в больших языковых моделях.
Несмотря на впечатляющие успехи больших языковых моделей, интерпретация их внутренних механизмов остается сложной задачей. В данной работе представлена система SAGE: An Agentic Explainer Framework for Interpreting SAE Features in Language Models, — основанный на агентах фреймворк, предназначенный для активного тестирования и уточнения объяснений для признаков, полученных с помощью разреженных автоэнкодеров. Предложенный подход позволяет получать более точные и согласованные интерпретации, что важно для повышения надежности и управляемости LLM. Способствует ли такая активная методология интерпретации более глубокому пониманию принципов работы языковых моделей и открывает ли новые возможности для их совершенствования?
Раскрытие Непрозрачности: Вызов SAE-Признаков
Современные языковые модели, демонстрирующие впечатляющую производительность в различных задачах, зачастую функционируют как “чёрные ящики”, скрывая внутренние механизмы принятия решений. В частности, так называемые SAE Features — внутренние представления данных, формирующиеся в процессе обработки текста — остаются непрозрачными для анализа. Эти признаки, хотя и критически важны для работы модели, сложно интерпретировать напрямую, поскольку они представляют собой абстрактные числовые векторы, не имеющие очевидной связи с исходным текстом. Невозможность “заглянуть внутрь” и понять, как именно модель приходит к определенным выводам, создает серьезные трудности при отладке, контроле и, что особенно важно, построении доверия к этим сложным системам искусственного интеллекта. Эта непрозрачность является одной из ключевых проблем, стоящих перед исследователями в области машинного обучения и искусственного интеллекта.
Понимание внутренних представлений, так называемых SAE-признаков, в современных языковых моделях критически важно для отладки, контроля и формирования доверия к этим системам. Однако, прямая интерпретация этих признаков представляет собой сложную задачу. В отличие от программируемых систем, где логика работы понятна, SAE-признаки формируются в процессе обучения и представляют собой распределенные представления, которые трудно соотнести с конкретными лингвистическими особенностями входного текста. Это затрудняет выявление причин, по которым модель принимает то или иное решение, и препятствует эффективному управлению её поведением. Отсутствие прозрачности в работе модели подрывает доверие пользователей и ограничивает возможности её применения в критически важных областях, где необходима надежность и предсказуемость.
Традиционные методы анализа активаций признаков в современных языковых моделях часто оказываются неэффективными при выявлении конкретных текстовых паттернов, вызывающих эти активации. Исследователи сталкиваются с трудностями в определении, какие именно слова или фразы в исходном тексте приводят к определенной реакции нейронной сети. Это затрудняет не только понимание логики работы модели, но и отладку её ошибок, а также контроль над её поведением. Отсутствие четкой связи между входными данными и внутренними представлениями модели препятствует установлению доверия к её решениям, поскольку невозможно точно объяснить, почему модель пришла к тому или иному выводу. По сути, это ограничивает возможность полноценного анализа и оптимизации языковых моделей, оставляя значительную часть их работы невидимой и непонятной.
SAGE: Агентская Платформа для Объяснения
SAGE — это агентская платформа, использующая несколько больших языковых моделей (LLM) для формирования, проверки и уточнения объяснений работы функций автоматизированного вождения (SAE). Платформа функционирует как система взаимодействующих агентов, где каждый агент выполняет специализированную задачу в процессе объяснения. Использование нескольких LLM позволяет SAGE оценивать и сопоставлять различные гипотезы, повышая надежность и точность получаемых объяснений. Архитектура платформы разработана для динамического анализа и позволяет проводить эксперименты с входными текстовыми данными для валидации или опровержения предложенных объяснений, что отличает ее от методов статического анализа.
В основе SAGE лежит агент «Объяснитель», который формирует начальные гипотезы, используя «Образцовые Данные» — фрагменты текста с высокой степенью активации. Эти фрагменты, выделенные на основе внутренних метрик модели, служат отправной точкой для построения объяснений. Агент «Объяснитель» анализирует эти высокоактивированные сегменты, выявляя закономерности и связи, которые затем формируются в виде проверяемых гипотез относительно работы функции безопасности. Использование «Образцовых Данных» позволяет системе фокусироваться на наиболее релевантных участках входного текста, повышая эффективность и точность процесса объяснения.
В отличие от методов статического анализа, основанных на изучении текста без его изменения, SAGE использует активное экспериментирование с текстовыми данными для проверки выдвинутых объяснений. Система намеренно модифицирует входные тексты и наблюдает за изменениями в поведении модели, чтобы подтвердить или опровергнуть гипотезы о причинах конкретных результатов. Такой подход позволяет выявить причинно-следственные связи, которые не обнаруживаются при однократном анализе текста, и обеспечивает более надежную и обоснованную интерпретацию работы модели. Это динамическое тестирование повышает достоверность объяснений и позволяет оценить чувствительность модели к различным входным данным.
Итеративное Уточнение: Тестирование и Валидация Объяснений
Агент “Проектировщик” (Designer Agent) в системе SAGE формирует специализированные тестовые тексты, предназначенные для проверки поведения конкретных признаков модели. Эти тексты создаются с целью либо подтвердить, либо опровергнуть выдвинутые Агентом “Объяснитель” (Explainer Agent) гипотезы о принципах работы модели. Формирование тестовых текстов осуществляется на основе анализа текущих объяснений и направлено на целенаправленное исследование активации определенных признаков в ответ на специфические входные данные. Результаты тестирования служат основой для оценки точности и полноты объяснений, позволяя уточнить понимание логики работы модели.
Агент-анализатор фиксирует полученную “Обратную связь по активации” — измеренные значения активации признаков, которые служат ключевыми данными для оценки качества объяснений. Эти значения представляют собой количественную оценку того, насколько сильно каждый признак был активирован в ответ на тестовый текст, сгенерированный агентом-конструктором. Анализ активации позволяет определить, какие признаки наиболее релевантны для конкретного поведения модели и подтверждают или опровергают выдвинутые гипотезы. Полученные данные об активации признаков являются основой для дальнейшей итеративной доработки объяснений.
Агент-рецензент осуществляет оценку полученной обратной связи об активациях, используя процесс уточнения гипотез для обновления объяснений. Данный процесс представляет собой многооборотное уточнение объяснений (Multi-Turn Explanation Refinement), в ходе которого агент-рецензент анализирует данные, полученные от агента-анализатора, и, основываясь на них, корректирует первоначальные гипотезы, сформулированные агентом-объяснителем. Циклический характер процесса позволяет последовательно улучшать качество и точность предоставляемых объяснений, до тех пор, пока не будет достигнута приемлемая степень соответствия между объяснениями и наблюдаемым поведением модели.
Синтез Понимания: От Гипотезы к Интерпретации
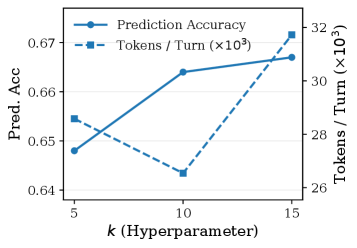
В процессе итеративного уточнения, система SAGE стремится к формированию объяснений, которые не просто предсказывают активацию признаков, но и способны каузально их генерировать. Данный подход демонстрирует значительное превосходство над существующими методами, такими как Neuronpedia. В частности, SAGE достигает показателей предсказательной точности в диапазоне 0.65-0.83, в то время как Neuronpedia показывает результаты в пределах 0.52-0.70. Однако ключевым отличием является способность SAGE к каузальной генерации, что открывает новые возможности для понимания и контроля над поведением нейронных сетей, значительно превосходя существующие аналоги. Мы видим здесь не просто статистическую корреляцию, но и возможность выявить истинные причины поведения модели.
Процесс “Финального Синтеза Объяснений” объединяет в себе подтвержденные гипотезы, формируя всестороннее понимание поведения признака SAE. Данный подход позволяет не просто предсказывать активацию признаков, но и каузально генерировать их, демонстрируя значительный прирост генеративной точности — от 29% до 458% по сравнению с базовым уровнем Neuronpedia. Это свидетельствует о способности системы не только описывать наблюдаемые явления, но и активно воспроизводить их, что открывает новые возможности для анализа и контроля над функционированием языковых моделей.
Предложенная методология открывает перспективные пути к созданию языковых моделей, характеризующихся повышенной прозрачностью, управляемостью и надежностью. Вместо “черного ящика”, данный подход позволяет не только предсказывать активацию определенных признаков в модели, но и объяснять причины этих активаций, что критически важно для понимания принципов работы искусственного интеллекта. Такой уровень интерпретируемости способствует более осознанному использованию моделей, позволяя разработчикам и пользователям контролировать их поведение и выявлять потенциальные смещения или ошибки. В конечном итоге, это способствует повышению доверия к языковым моделям и расширению областей их применения, особенно в сферах, требующих высокой степени ответственности и точности.
Представленная работа демонстрирует стремление к математической чистоте в интерпретации внутренних механизмов больших языковых моделей. Подход SAGE, активно тестирующий и уточняющий объяснения признаков разреженных автоэнкодеров, соответствует принципу доказуемости алгоритма. Вместо простой констатации «работает на тестах», авторы предлагают строгий, агент-ориентированный фреймворк для проверки согласованности и точности интерпретаций. Как говорил Алан Тьюринг: «Существование машины не означает, что она может думать». Данное исследование, подобно стремлению Тьюринга к созданию мыслящей машины, фокусируется не просто на функциональности, но и на глубоком понимании принципов работы системы, стремясь к корректному и непротиворечивому объяснению ее поведения.
Куда Ведет Этот Путь?
Представленная работа, хоть и демонстрирует прогресс в интерпретации разреженных автоэнкодеров в больших языковых моделях, оставляет открытым вопрос о фундаментальной воспроизводимости полученных результатов. Агентный подход SAGE, безусловно, элегантен в своей попытке активного тестирования объяснений, однако, истинная проверка заключается не в успешном прохождении тестового набора, а в математической доказуемости полученных интерпретаций. Если одно и то же агентное окружение, с идентичными начальными условиями, не приводит к абсолютно одинаковым выводам, то ценность таких объяснений стремится к нулю.
Полисемантичность признаков, выявленная в ходе исследования, не является неожиданностью, но требует более строгого формализма. Недостаточно констатировать, что признак «может означать» несколько вещей; необходимо разработать метрики, позволяющие количественно оценить степень неоднозначности и её влияние на предсказательную силу модели. В противном случае, мы рискуем лишь перефразировать незнание, облекая его в псевдонаучную форму.
Будущие исследования должны сосредоточиться на разработке формальных методов верификации интерпретаций, а не на их эмпирической валидации. Алгоритм должен быть доказуемо корректным, а не просто «работать» на ограниченном наборе данных. И лишь тогда, возможно, мы сможем приблизиться к истинному пониманию того, что на самом деле происходит внутри этих сложных нейронных сетей.
Оригинал статьи: https://arxiv.org/pdf/2511.20820.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Сердце музыки: открытые модели для создания композиций
- Самообучающиеся системы: новый подход к созданию многоагентных взаимодействий
- Квантовые системы в полуклассическом режиме: новый подход к моделированию
- Маленькие модели – большие возможности: Искусственный интеллект в поиске онкологических исследований
- Вариационные и полувариационные неравенства: от теории к практике
- Искусственный интеллект, который знает, когда ему нужна подсказка
- Обучение языковых моделей: как контролировать длину ответов
- В поисках подлинной новизны: как оценить оригинальность научных работ?
- Думай глубже: как искусственный интеллект помогает нам мыслить критически
- Визуальный анализ документов: новый вызов для искусственного интеллекта
2025-11-28 06:15