Автор: Денис Аветисян
В статье представлен обзор современных подходов к автоматическому созданию unit-тестов с использованием больших языковых моделей.
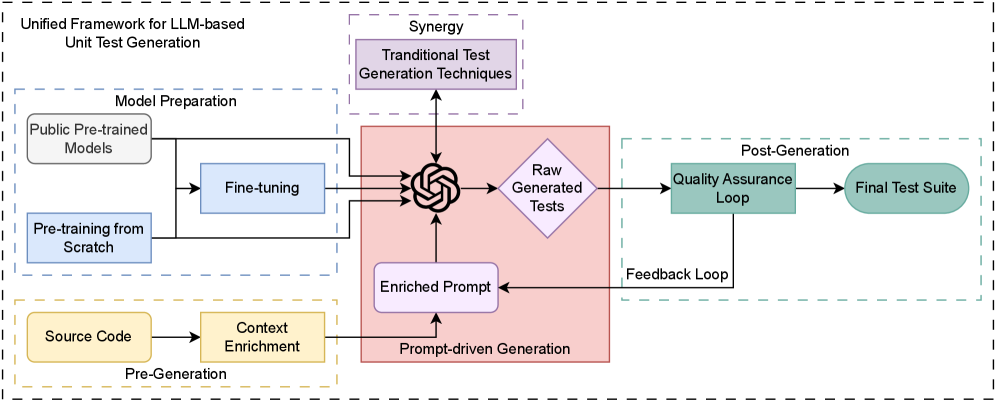
Систематический обзор достижений, проблем и перспектив применения больших языковых моделей для автоматизированного тестирования программного обеспечения.
Несмотря на важность автоматизированного тестирования, создание эффективных юнит-тестов остаётся трудоёмким процессом, требующим глубокого понимания семантики кода. В работе «Large Language Models for Unit Test Generation: Achievements, Challenges, and the Road Ahead» представлен систематический обзор современных подходов к генерации юнит-тестов с использованием больших языковых моделей (LLM), демонстрирующий смещение от автономной генерации к синергетическим системам, объединяющим LLM с традиционными инструментами разработки. Анализ 115 публикаций показал, что prompt engineering является доминирующей стратегией, однако остаются нерешёнными проблемы слабой способности к обнаружению ошибок и отсутствие стандартизированных бенчмарков. Какие перспективы открываются для создания автономных агентов тестирования, способных значительно повысить качество и надёжность программного обеспечения?
От простоты к качеству: эволюция тестирования программного обеспечения
Традиционные методы тестирования программного обеспечения, такие как юнит-тестирование, остаются фундаментальными для обеспечения качества кода, однако их эффективность заметно снижается при работе со сложными и разветвленными кодовыми базами. В подобных системах, где взаимодействие между компонентами становится всё более запутанным, написание и поддержание достаточного количества юнит-тестов требует значительных временных и трудовых затрат. Ручное тестирование, несмотря на свою важность, становится непрактичным для покрытия всех возможных сценариев и выявления скрытых дефектов, что обуславливает необходимость поиска и внедрения более автоматизированных и интеллектуальных подходов к обеспечению качества программного обеспечения. По мере роста масштабов и сложности проектов, традиционные методы тестирования всё чаще оказываются узким местом в процессе разработки, замедляя выпуск новых версий и повышая риск возникновения ошибок в производственной среде.
Современное программное обеспечение становится всё более сложным, что предъявляет повышенные требования к эффективности и автоматизации процессов тестирования. Традиционные методы, хоть и остаются важными, часто оказываются недостаточными для обеспечения качества в условиях постоянно растущей кодовой базы и сокращающихся сроков разработки. Автоматизированное тестирование позволяет значительно ускорить процесс обнаружения и устранения ошибок, снизить вероятность их появления в конечном продукте и, как следствие, сократить время выхода программного обеспечения на рынок. Это достигается за счёт использования специализированных инструментов и фреймворков, способных выполнять повторяющиеся тесты без участия человека, анализировать результаты и предоставлять подробные отчёты о выявленных проблемах. В результате, разработчики получают возможность быстрее реагировать на изменения, повышать надёжность и стабильность своих продуктов и эффективно конкурировать на быстро меняющемся рынке.
Достижение высокого уровня тестового покрытия и выявление скрытых ошибок продолжает оставаться сложной задачей в разработке программного обеспечения. Традиционные методы тестирования, несмотря на свою важность, часто оказываются недостаточно эффективными при работе со сложными кодовыми базами и требуют значительных ручных усилий. В связи с этим, всё большее внимание уделяется инновационным решениям, таким как автоматизированное тестирование, фаззинг и использование искусственного интеллекта для обнаружения уязвимостей и дефектов, которые сложно выявить при ручной проверке. Эти подходы позволяют не только повысить качество программного обеспечения, но и значительно сократить время, необходимое для его тестирования и выпуска на рынок, что особенно важно в условиях быстро меняющихся технологий и высокой конкуренции.
Большие языковые модели: новый взгляд на генерацию тестов
Автоматическая генерация модульных тестов на основе больших языковых моделей (LLM) представляет собой перспективное решение для снижения трудозатрат на ручное тестирование и повышения охвата кода тестами. Этот подход позволяет создавать тестовые примеры непосредственно из исходного кода, автоматизируя процесс, который традиционно требовал значительных усилий разработчиков. В результате, время, необходимое для проведения комплексного тестирования, сокращается, а вероятность обнаружения ошибок на ранних этапах разработки увеличивается. Использование LLM для генерации тестов особенно эффективно в случаях, когда требуется протестировать сложные функции или обеспечить покрытие кода в труднодоступных областях.
Интеграция генерации тестов на основе больших языковых моделей (LLM) в существующие автоматизированные фреймворки тестирования позволяет существенно ускорить циклы тестирования и повысить их охват. Вместо разработки тестов «с нуля», LLM автоматически генерируют юнит-тесты на основе анализа исходного кода, что сокращает время, затрачиваемое на ручное кодирование и проверку. Это, в свою очередь, приводит к более частым и всесторонним циклам тестирования, позволяя разработчикам быстрее выявлять и устранять ошибки на ранних стадиях разработки. Более широкое покрытие тестами, достигнутое благодаря автоматизации, снижает риск проявления дефектов в производственной среде и повышает общую надежность программного обеспечения.
Анализ последних исследований в области автоматической генерации тестов на основе больших языковых моделей (LLM) показал, что методика проектирования запросов (prompt engineering) является доминирующей стратегией, применяемой в 89% проанализированных работ. Данный подход подразумевает формирование четких и структурированных инструкций для LLM, определяющих формат, объем и специфику генерируемых тестов. Эффективность prompt engineering напрямую влияет на качество и релевантность создаваемых тестовых примеров, обеспечивая более точное и полное покрытие кода.

Уточнение и углубление: повышение точности LLM
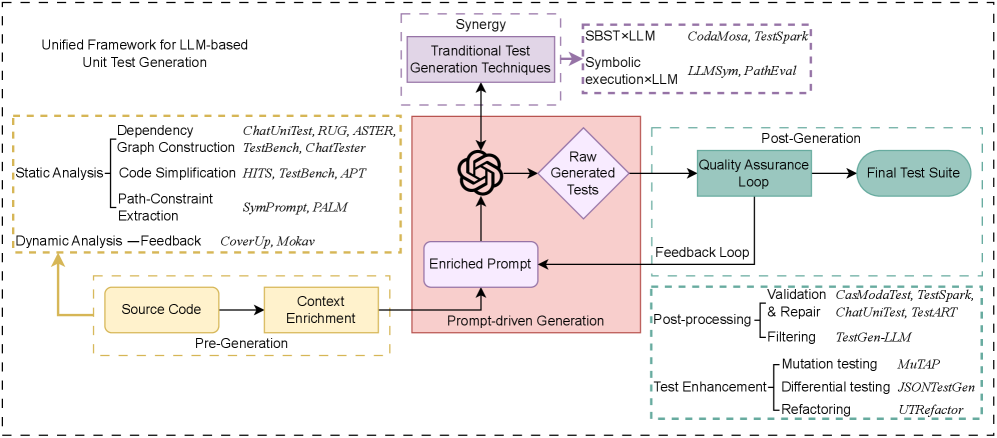
Обогащение контекста является критически важным фактором для повышения производительности больших языковых моделей (LLM) при тестировании кода. Этот процесс включает в себя как статический, так и динамический анализ тестируемого кода. Статический анализ позволяет LLM понять структуру, зависимости и потенциальные уязвимости кода без его фактического выполнения. Динамический анализ, в свою очередь, предполагает выполнение кода и отслеживание его поведения для выявления ошибок и покрытия различных сценариев. Комбинация этих двух подходов обеспечивает LLM более полное представление о кодовой базе, что значительно повышает точность и релевантность генерируемых тестов и, как следствие, улучшает качество проверки программного обеспечения.
Итеративный цикл исправления, включающий генерацию тестовых оракулов, позволяет уточнять сгенерированные тесты путем выявления ошибок и последовательного улучшения их точности и полноты. Исследования показывают, что данный подход эффективно решает проблему низкой практической применимости и повышает общее качество генерируемых тестов. Процесс предполагает автоматическое создание ожидаемых результатов (тестовых оракулов) и сравнение фактических результатов выполнения кода с ними. В случае расхождений, цикл автоматически вносит изменения в тесты или в тестируемый код, стремясь к достижению соответствия и минимизации ложноположительных и ложноотрицательных результатов. Повторение этого цикла позволяет существенно повысить надежность и эффективность автоматизированного тестирования.
Для повышения эффективности применяются методы символьного исполнения и поиска на основе тестирования. Символьное исполнение позволяет исследовать различные пути выполнения кода, анализируя все возможные ветвления и условия, что позволяет выявить потенциальные ошибки и уязвимости. Поиск на основе тестирования, в свою очередь, использует эвристические алгоритмы для автоматического создания тестовых случаев, которые максимизируют покрытие кода и выявляют граничные условия и крайние случаи. Комбинация этих подходов позволяет создавать более полные и надежные наборы тестов, эффективно покрывающие различные сценарии и обеспечивающие более качественное тестирование программного обеспечения.
Автономное тестирование: взгляд в будущее
В результате объединения передовых методов тестирования программного обеспечения сформировался автономный агент тестирования. Этот агент способен самостоятельно планировать последовательность проверок, выполнять их и оценивать результаты, что значительно снижает потребность в ручном вмешательстве. Он анализирует код, определяет потенциальные уязвимости и генерирует тестовые примеры без участия человека, обеспечивая более быструю и эффективную проверку качества программного продукта. Автономность агента позволяет проводить непрерывное тестирование в процессе разработки, выявляя и устраняя ошибки на ранних стадиях, и тем самым повышая надежность и стабильность конечного продукта. Такой подход открывает новые возможности для автоматизации и оптимизации всего цикла разработки программного обеспечения.
Эффективность генерации тестов на основе больших языковых моделей (LLM) подвержена влиянию ряда факторов, что требует дальнейших исследований и оптимизации. Сложность кодовой базы играет существенную роль: чем сложнее код, тем труднее LLM генерировать адекватные и полные тестовые примеры. Кроме того, чувствительность модели к незначительным изменениям во входных данных или архитектуре кода может приводить к нестабильным результатам. Поэтому, для обеспечения надежности и предсказуемости автоматизированного тестирования, необходимо постоянно совершенствовать алгоритмы обучения LLM, а также разрабатывать методы адаптации моделей к различным типам и уровням сложности программного обеспечения. Исследования в данной области направлены на повышение устойчивости и точности генерации тестов, что позволит снизить зависимость от ручного вмешательства и обеспечить более качественное программное обеспечение.
Несмотря на умеренное повышение покрытия кода тестами, современные подходы к автоматической генерации тестов демонстрируют ограничения в показателе мутационного счета. Это указывает на необходимость улучшения семантического понимания кода при генерации тестов, чтобы обеспечить более качественное и надежное программное обеспечение. Низкий мутационный счет означает, что тесты не способны выявлять все возможные ошибки, внесенные в код путем небольших изменений — мутаций. Для повышения эффективности необходимо, чтобы генератор тестов не просто создавал синтаксически корректные тесты, но и понимал смысл кода и генерировал тесты, способные обнаруживать даже тонкие логические ошибки и уязвимости. Дальнейшие исследования направлены на разработку методов, позволяющих генераторам тестов более глубоко анализировать семантику кода и создавать тесты, обеспечивающие более высокий уровень уверенности в качестве программного обеспечения.
Исследование, посвященное генерации модульных тестов с использованием больших языковых моделей, демонстрирует закономерный переход от изолированных решений к симбиотическим системам. В этом процессе классические методы разработки программного обеспечения не уступают позиции, а лишь дополняют новые подходы, повышая надежность и удобство использования. Эта тенденция отражает стремление к ясности и простоте, ведь, как отмечал Дональд Кнут: «Прежде чем оптимизировать код, убедитесь, что он работает». Подобная мудрость применима и здесь: прежде чем стремиться к автоматизации, необходимо обеспечить фундаментальную надежность и понятность базовых процессов. Стремление к совершенству проявляется не в сложности, а в умении отбросить лишнее, оставив только суть.
Что Дальше?
Обзор показывает смещение парадигмы: от попыток создания автономных генераторов модульных тестов к системам, интегрирующим классические принципы разработки программного обеспечения. Это не поражение, а признание сложности. Иллюзия о полной автоматизации тестирования рассеивается, обнажая необходимость в осмысленной синергии искусственного интеллекта и человеческого разума. Упрощение ради упрощения — это насилие над вниманием.
Остается нерешенной проблема верификации сгенерированных тестов. Генерация — лишь половина задачи; гарантия их адекватности — вот где кроется истинный вызов. Простое увеличение объема сгенерированных тестов не решает проблему, а лишь создает иллюзию безопасности. Необходим переход от количественных метрик к качественным, от “сколько” к “насколько хорошо”.
Будущие исследования должны сосредоточиться на разработке метрик, способных оценивать не только покрытие кода, но и способность тестов выявлять реальные дефекты. Искусственный интеллект может генерировать, но только человек может судить о ценности. Плотность смысла — новый минимализм. Задача не в создании всеобъемлющего инструмента, а в создании инструмента, который способствует осмысленному тестированию.
Оригинал статьи: https://arxiv.org/pdf/2511.21382.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Самообучающиеся системы: новый подход к созданию многоагентных взаимодействий
- Квантовые системы в полуклассическом режиме: новый подход к моделированию
- Сердце музыки: открытые модели для создания композиций
- Адаптивное управление временем: новый шаг к эффективным квантовым вычислениям
- Искусственный интеллект на службе материаловедения: платформа AGAPI
- Наука из первых рук: новый вызов для искусственного интеллекта
- Action100M: Видео, которые учат машины видеть мир
- Моделирование клеток: новый подход к скорости и масштабу
- Геометрия в нейросетях: новая архитектура Versor
- Распределенное обучение языковых моделей: новый подход к экономии памяти
2025-11-29 00:43