Автор: Денис Аветисян
Исследователи представили систему Matrix, позволяющую создавать синтетические данные в условиях высокой нагрузки за счет децентрализованной, многоагентной архитектуры.
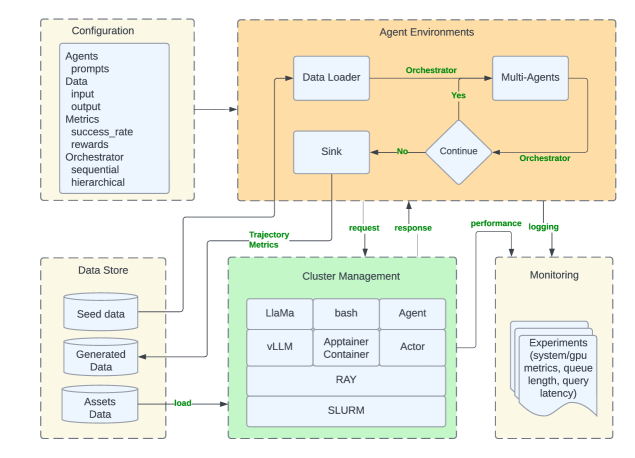
Matrix — масштабируемая, децентрализованная среда выполнения для генерации синтетических данных с использованием многоагентных систем и асинхронного исполнения.
Несмотря на растущую потребность в синтетических данных для обучения больших языковых моделей, существующие многоагентные системы часто сталкиваются с ограничениями масштабируемости и гибкости. В данной работе представлена система ‘Matrix: Peer-to-Peer Multi-Agent Synthetic Data Generation Framework’, реализующая децентрализованный подход к генерации данных, основанный на peer-to-peer архитектуре и асинхронном выполнении задач. Такая организация позволяет добиться значительного увеличения пропускной способности — до 15 раз — при сохранении качества генерируемых данных. Способна ли данная система стать основой для создания более эффективных и адаптивных систем генерации данных в различных областях применения?
Преодолевая ограничения: К ясной архитектуре агентных систем
Несмотря на впечатляющие способности в генерации текста и понимании языка, большие языковые модели (БЯМ) часто сталкиваются с трудностями при решении сложных задач, требующих многоэтапного рассуждения. Эти модели, хотя и превосходно справляются с задачами, требующими мгновенного распознавания закономерностей, испытывают проблемы с последовательным применением логики и планированием действий для достижения долгосрочных целей. Например, БЯМ может успешно ответить на вопрос о фактах, но с трудом справляется с задачей, требующей синтеза информации из нескольких источников, формирования гипотез и проверки их на соответствие реальности. Ограничения в многоэтапном рассуждении обусловлены архитектурой этих моделей, которые в основном ориентированы на прогнозирование следующего слова в последовательности, а не на моделирование сложных когнитивных процессов, необходимых для решения проблем.
Традиционные подходы к увеличению масштаба языковых моделей, заключающиеся в наращивании объемов данных и вычислительных мощностей, демонстрируют тенденцию к уменьшению эффективности. Дальнейшее увеличение размеров моделей приносит все меньше прироста в решении сложных задач, что связано с ограничениями в архитектуре и принципах работы этих систем. В связи с этим, исследователи обращают внимание на альтернативные архитектуры, такие как многоагентные системы. Эти системы предполагают распределение процесса рассуждения между несколькими специализированными агентами, каждый из которых отвечает за определенный аспект задачи. Такой подход позволяет преодолеть ограничения, связанные с необходимостью хранения и обработки огромных объемов информации в рамках одной модели, и повысить эффективность решения сложных, многоступенчатых задач, требующих специализированных знаний и навыков.
Агентные системы представляют собой перспективный подход к преодолению ограничений больших языковых моделей (LLM) в решении сложных задач, требующих многоступенчатого рассуждения. Вместо монолитной обработки информации, агентные системы распределяют процесс рассуждения между множеством специализированных агентов, каждый из которых отвечает за конкретный аспект задачи. Такой подход позволяет разделить сложную проблему на более мелкие, управляемые части, что значительно повышает эффективность и точность решения. Каждый агент, функционируя как независимый модуль, может применять свои уникальные навыки и знания, а взаимодействие между агентами обеспечивает целостный и когерентный результат. Это позволяет не только решать более сложные задачи, но и повышает надежность системы, поскольку отказ одного агента не обязательно приводит к сбою всей системы. В результате, агентные системы открывают новые возможности для автоматизации и интеллектуальной обработки информации, превосходящие возможности традиционных LLM в определенных областях.
Matrix: Масштабируемая среда для экспериментов с агентами
Matrix представляет собой распределенную среду выполнения, разработанную для масштабируемого создания синтетических данных и проведения экспериментов с участием множества агентов. Архитектура платформы позволяет распределять задачи генерации данных между несколькими вычислительными узлами, что обеспечивает высокую пропускную способность и возможность обработки больших объемов данных. Ключевой особенностью является поддержка параллельного выполнения задач агентами, что позволяет значительно сократить время, необходимое для генерации синтетических наборов данных, и повысить эффективность экспериментов в различных областях, таких как машинное обучение и моделирование. Платформа спроектирована для гибкой адаптации к различным типам задач и позволяет легко масштабировать вычислительные ресурсы в соответствии с потребностями конкретного проекта.
Для оптимизации производительности Matrix использует эффективные методы преобразования данных, включающие пакетную обработку и планирование на уровне строк. Пакетная обработка позволяет обрабатывать данные большими группами, снижая накладные расходы, связанные с каждой отдельной операцией. Планирование на уровне строк обеспечивает гибкое управление очередью задач и позволяет эффективно использовать доступные вычислительные ресурсы. Комбинация этих методов позволяет Matrix достигать высокой пропускной способности и снижать задержки при генерации синтетических данных, особенно при работе с большими объемами данных и сложными преобразованиями.
Платформа Matrix обеспечивает интеграцию с ключевыми элементами инфраструктуры, такими как SLURM для управления вычислительными ресурсами и планирования задач, Apptainer для создания переносимых и воспроизводимых окружений исполнения, и Ray для распределенных вычислений и масштабирования. Данная интеграция позволяет эффективно использовать существующие ресурсы, упрощает развертывание и управление агентами, а также обеспечивает гибкость в настройке и масштабировании экспериментов по генерации синтетических данных. Совместимость с данными инструментами значительно расширяет возможности платформы Matrix и позволяет интегрировать ее в существующие рабочие процессы.
Архитектура “peer-to-peer” в Matrix обеспечивает прямую коммуникацию между агентами, что позволяет значительно повысить пропускную способность при генерации синтетических данных. В ходе тестирования было достигнуто увеличение производительности до 15.4x по сравнению с традиционными централизованными подходами. При этом, качество генерируемых данных остается сопоставимым с результатами, полученными с использованием централизованных систем, что подтверждает эффективность данной архитектуры для масштабируемых экспериментов с агентами и генерации больших объемов синтетических данных.

Генерация и оценка задач и поведения агентов: Устойчивость через автоматизацию
TaskCraft — это автоматизированная система генерации многошаговых задач, требующих использования нескольких инструментов для их решения. Она позволяет создавать наборы задач, предназначенные для систематической оценки возможностей агентов искусственного интеллекта в различных сценариях. Генерация задач осуществляется автоматически, что позволяет проводить масштабные тестирования и сравнительный анализ эффективности различных агентов и подходов к построению агентов. Система позволяет контролировать сложность задач, количество необходимых шагов и типы используемых инструментов, обеспечивая точную и воспроизводимую оценку производительности агентов.
AgentSynth и SWE-Synth представляют собой масштабируемые методы для автоматизированного создания задач и синтеза верифицируемых исправлений ошибок, соответственно. AgentSynth генерирует разнообразные задачи, необходимые для систематической оценки возможностей агентов, обеспечивая широкий охват сценариев. SWE-Synth, в свою очередь, специализируется на создании патчей для исправления обнаруженных ошибок, с возможностью автоматической верификации правильности внесенных изменений. Оба инструмента используют подходы, позволяющие эффективно масштабировать процесс генерации и синтеза, что особенно важно при тестировании и обучении сложных агентских систем и программного обеспечения.
Agent Instruct представляет собой инструмент, предназначенный для генерации многоходовых наборов данных инструкций и ответов, необходимых для обучения и совершенствования поведения агентов. Эти наборы данных формируются путем моделирования взаимодействий, где агент последовательно получает инструкции и предоставляет ответы, что позволяет оценить и улучшить его способность понимать сложные запросы и генерировать релевантные ответы в динамичной среде. Созданные таким образом данные используются для обучения моделей, повышая их эффективность в задачах, требующих последовательного выполнения инструкций и адаптации к изменяющимся условиям.
Использование Collaborative Reasoner позволило системе Matrix достичь в 6.8 раза более высокую пропускную способность токенов по сравнению с официальной реализацией. Данный результат демонстрирует существенный прирост производительности, что подтверждается количественными данными о скорости обработки и генерации токенов. Увеличение пропускной способности токенов напрямую влияет на эффективность системы в задачах, требующих обработки больших объемов текстовой информации и генерации развернутых ответов.
Оценивая и масштабируя интеллект агентов: На пути к новым горизонтам
Разработанный Tau2-Bench представляет собой принципиально новый эталон для оценки возможностей разговорных агентов в условиях двойного управления, где взаимодействие происходит как с человеком, так и с другими агентами. Этот эталон выходит за рамки традиционных тестов, фокусируясь на способности агента адаптироваться к сложным сценариям, требующим координации и совместного решения задач. Tau2-Bench позволяет исследователям более точно оценить, насколько эффективно агент может понимать намерения другого участника, планировать свои действия и реагировать на изменяющуюся ситуацию, тем самым продвигая границы взаимодействия человека и искусственного интеллекта и открывая новые перспективы для создания более интеллектуальных и полезных систем.
Система SWE-Agent демонстрирует принципиально новый подход к автоматизации задач в области разработки программного обеспечения, фокусируясь на выявлении и устранении ошибок в коде. В ходе экспериментов, система успешно справлялась с поиском и исправлением багов в реальных проектах, используя возможности агентного интеллекта для анализа кода, генерации тестовых примеров и применения патчей. Особенностью SWE-Agent является способность к самообучению и адаптации к различным кодовым базам, что позволяет значительно повысить эффективность процесса отладки и снизить нагрузку на разработчиков. Полученные результаты подтверждают перспективность использования агентных систем для автоматизации рутинных задач в разработке, открывая возможности для создания более надежного и качественного программного обеспечения.
Разработанный набор данных NaturalReasoning представляет собой масштабный ресурс, призванный значительно улучшить способности больших языковых моделей (LLM) к логическому мышлению и решению задач, требующих анализа и выводов. Этот обширный датасет состоит из разнообразных сценариев и вопросов, специально созданных для проверки и развития навыков рассуждения у искусственного интеллекта. Предоставляя LLM доступ к таким данным, исследователи стремятся преодолеть существующие ограничения в способности моделей к комплексному анализу и принятию обоснованных решений, что является ключевым шагом на пути к созданию действительно интеллектуальных агентов. Использование NaturalReasoning способствует прогрессу в области агентского интеллекта, позволяя создавать системы, способные к более эффективному и надежному решению сложных проблем в различных областях.
Система Matrix, использующая технологию vLLM, продемонстрировала впечатляющую производительность в обработке естественного языка. В ходе экспериментов было сгенерировано 185 376 127 токенов, используя вычислительные ресурсы 13 графических процессоров H100. Особым достижением является возможность одновременной обработки 1500 задач, что в три раза превышает базовый уровень в 500 параллельных процессов. Этот результат подчеркивает значительный прогресс в масштабировании и оптимизации больших языковых моделей, открывая новые возможности для решения сложных задач в области искусственного интеллекта и обработки данных.
За пределами текущих возможностей: Будущее агентных систем
Генерация синтетических данных, интегрированная в рамках фреймворка Matrix, приобретает всё большее значение для обучения устойчивых и обобщающих агентов. В условиях ограниченности реальных данных и высокой стоимости их сбора, искусственно созданные наборы данных позволяют значительно расширить возможности обучения, особенно в сложных и динамичных средах. Использование Matrix позволяет эффективно моделировать различные сценарии и генерировать данные, отражающие широкий спектр возможных ситуаций, что критически важно для повышения надежности и адаптивности агентов к новым условиям. Такой подход не только ускоряет процесс обучения, но и позволяет избежать переобучения на ограниченном наборе реальных данных, что способствует созданию более универсальных и интеллектуальных систем.
В условиях масштабирования многоагентных систем, оптимизация коммуникационной эффективности становится критически важной задачей. Исследования показали, что применение методов переноса сообщений, или “message offloading”, позволяет значительно снизить нагрузку на сеть. В ходе экспериментов было продемонстрировано, что подобные техники способны уменьшить потребление сетевой полосы пропускания до 20%, что особенно актуально для систем, работающих в условиях ограниченных ресурсов или с большим количеством взаимодействующих агентов. Подобный подход заключается в передаче не всей информации, а лишь ее ключевых аспектов или агрегированных данных, что снижает объем передаваемых сообщений без существенной потери полезности для принимающей стороны. Это позволяет агентам взаимодействовать более эффективно, снижая задержки и повышая общую производительность системы.
Дальнейшая разработка эталонных тестов и метрик оценки представляется критически важной для отслеживания прогресса в области агентных систем и выявления направлений для совершенствования. Без стандартизированных способов измерения производительности и обобщающей способности агентов, объективная оценка новых алгоритмов и архитектур становится затруднительной. Создание комплексных, реалистичных сценариев, охватывающих широкий спектр задач и условий, позволит более точно определить сильные и слабые стороны различных подходов. Кроме того, необходимо разработать метрики, учитывающие не только эффективность решения задач, но и такие аспекты, как надежность, безопасность и этичность поведения агентов. Подобные инструменты позволят исследователям и разработчикам эффективно сравнивать различные системы, ускоряя процесс создания более интеллектуальных и полезных агентных решений.
Слияние агентивных систем с другими парадигмами искусственного интеллекта открывает перспективы для достижения качественно новых уровней интеллекта и возможностей решения задач. Исследования показывают, что интеграция агентов с такими областями, как глубокое обучение с подкреплением, генеративные модели и нейросимволические системы, позволяет создавать более адаптивные, обучаемые и эффективные системы. Например, объединение агентивных систем с генеративными моделями позволяет агентам самостоятельно генерировать новые стратегии и решения, а интеграция с нейросимволическими системами обеспечивает возможность логического рассуждения и объяснения принимаемых решений. Подобные гибридные подходы не только расширяют спектр решаемых задач, но и способствуют развитию более надежного и интерпретируемого искусственного интеллекта, способного к сложным формам обучения и адаптации в динамически меняющейся среде.
Представленная работа демонстрирует стремление к редукции сложности в области генерации синтетических данных. Архитектура Matrix, построенная на принципах одноранговой сети, позволяет обойти ограничения централизованных подходов, обеспечивая масштабируемость и асинхронное выполнение. Это соответствует убеждению, что истинное понимание системы проявляется в её лаконичном описании. Как заметил Андрей Колмогоров: «Математика — это искусство упрощения». Применение данного принципа в контексте многоагентных систем позволяет достичь высокой пропускной способности, устраняя узкие места и оптимизируя процесс генерации данных. В стремлении к простоте и эффективности кроется ключ к созданию надежных и масштабируемых решений.
Куда же дальше?
Представленная работа, хоть и демонстрирует очевидное превосходство децентрализованного подхода к генерации синтетических данных, не решает, а лишь откладывает фундаментальную проблему: достоверность. Повышение пропускной способности — лишь средство, а не цель. Вопрос о том, насколько сгенерированные данные отражают реальность, остается открытым, и здесь требуются не столько ухищрения в архитектуре, сколько более глубокое понимание механизмов, формирующих сами данные. До тех пор, пока агент не научится различать правду и ложь, его творения останутся лишь изящными иллюзиями.
Очевидным направлением дальнейших исследований представляется разработка метрик, оценивающих не только объем, но и качество сгенерированных данных, а также методов, позволяющих агентам самостоятельно верифицировать свою работу. Попытки создать «идеальный» синтетический набор данных — тщеславие. Гораздо продуктивнее сосредоточиться на создании систем, способных адаптироваться к неполноте и противоречивости информации, подобно тому, как это делает живой организм.
И, наконец, стоит признать, что архитектура, подобная Matrix, лишь усложняет задачу интерпретации результатов. Чем сложнее система, тем труднее понять, почему она выдает именно такие данные. Возможно, в будущем, вместо стремления к максимальной сложности, стоит вернуться к принципам простоты и элегантности, помня, что истина часто скрывается в очевидном.
Оригинал статьи: https://arxiv.org/pdf/2511.21686.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Белки-хамелеоны: Пределы предсказания гибкости структуры
- Сердце музыки: открытые модели для создания композиций
- Самообучающиеся системы: новый подход к созданию многоагентных взаимодействий
- Квантовые системы в полуклассическом режиме: новый подход к моделированию
- Энергоэффективность сотовой сети: обучение с подкреплением и управление режимами сна
- Искусственный интеллект и архитектура будущего: новый виток эволюции
- Многоязычны ли современные нейросети на самом деле?
- Искусственный интеллект на службе материаловедения: платформа AGAPI
- Искусственный нос будущего: как квантовая механика и машинное обучение распознают запахи
- Автопилот нового поколения: Единая модель для понимания, планирования и предвидения
2025-11-29 07:25