Автор: Денис Аветисян
Новое исследование показывает, что интерфейс для одновременного сравнения результатов работы моделей, преобразующих текст в изображения, позволяет более эффективно выявлять детали и предвзятости в их работе.

Работа посвящена анализу влияния интерфейса MIRAGE на стратегии аудита генеративных моделей и выявление особенностей их ‘личности’.
Несмотря на растущую популярность генеративных систем искусственного интеллекта, оценка их надежности и выявление потенциальных предвзятостей остаются сложной задачей. В своей работе ‘Seeing Twice: How Side-by-Side T2I Comparison Changes Auditing Strategies’ авторы исследуют, как интерфейс для одновременного сравнения результатов работы различных моделей преобразования текста в изображение (T2I) влияет на стратегии аудита. Полученные результаты демонстрируют, что такой подход стимулирует более целостную оценку, позволяя пользователям выявлять закономерности в поведении моделей и формировать представление об их «личностях». Способен ли простой сравнительный интерфейс значительно ускорить процесс обнаружения предвзятостей и изменить наше понимание генеративных моделей?
Разоблачение предвзятостей: вызовы прозрачности ИИ
Бурное развитие моделей преобразования текста в изображения создаёт серьёзные трудности в понимании и смягчении потенциальных предвзятостей. Неуклонное увеличение числа таких моделей, доступных широкой публике, приводит к экспоненциальному росту возможностей для непреднамеренного усиления и распространения стереотипов, а также неточного или несправедливого представления различных социальных групп. Отсутствие всестороннего анализа и контроля над процессом генерации изображений может привести к формированию искажённых представлений о мире и увековечиванию существующих неравенств. В связи с этим, крайне важно разработать эффективные инструменты и методики для выявления и нейтрализации предвзятостей в этих моделях, обеспечивая их ответственное и этичное использование.
Существующие методы оценки моделей преобразования текста в изображения зачастую оказываются неспособными зафиксировать тонкие различия в их поведении и субъективное восприятие результатов пользователями. Традиционные метрики, ориентированные на количественную оценку, не всегда отражают качественные аспекты, такие как стилистические особенности, культурная уместность или потенциальная предвзятость. Это связано с тем, что оценка изображений сильно зависит от индивидуального опыта и интерпретации, а существующие автоматизированные системы не способны адекватно учесть эту сложность. В результате, даже при высоких показателях по формальным метрикам, модели могут генерировать изображения, которые кажутся неестественными, оскорбительными или усиливают стереотипы, оставаясь незамеченными при стандартном анализе.
Отсутствие надёжных инструментов аудита представляет значительную угрозу для моделей преобразования текста в изображения, поскольку они могут невольно увековечивать вредные стереотипы и искажения. Вследствие сложности алгоритмов и огромного количества генерируемых данных, выявление предвзятости становится чрезвычайно сложной задачей. Модели, обученные на нерепрезентативных или предвзятых данных, способны воспроизводить и усиливать существующие социальные предубеждения, что может привести к несправедливым или дискриминационным результатам. Без эффективных механизмов контроля и оценки, существует риск, что эти технологии будут способствовать распространению негативных представлений и усугублять неравенство, что требует разработки и внедрения строгих протоколов аудита для обеспечения справедливости и этичности их использования.
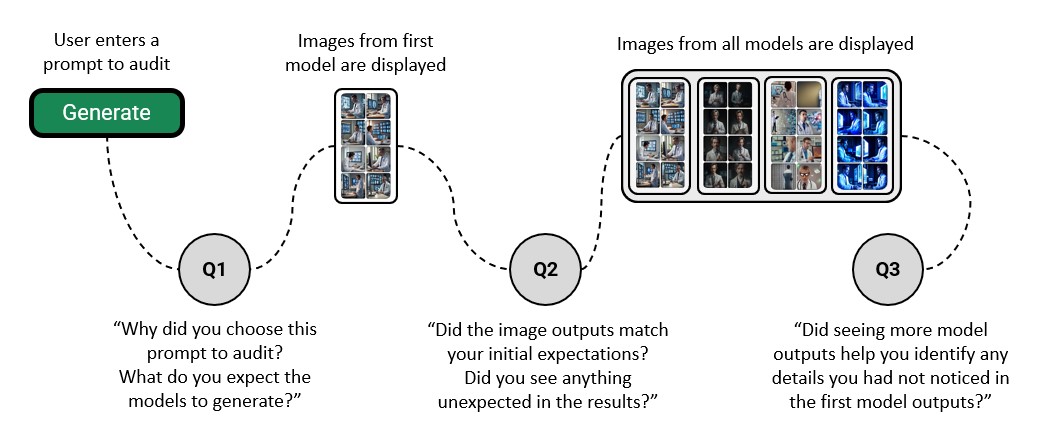
Исследование показало, что сопоставление результатов работы различных моделей преобразования текста в изображения стимулирует пользователей к переходу от оценки отдельных изображений к анализу общих закономерностей в выдаче. Такой подход позволяет выявлять скрытые предубеждения и стереотипы, которые остаются незамеченными при просмотре результатов работы только одной модели. Вместо фокусировки на конкретном изображении, пользователи начинают оценивать распределение полученных результатов, замечая, как различные модели интерпретируют один и тот же запрос и какие тенденции проявляются в их ответах. Это смещение фокуса открывает возможности для более глубокого аудита и выявления систематических ошибок, способствуя созданию более справедливых и репрезентативных систем искусственного интеллекта.

MIRAGE: платформа для сравнительного анализа моделей
MIRAGE — это веб-приложение, разработанное для поддержки сопоставительного анализа результатов, генерируемых различными моделями преобразования текста в изображения. Платформа позволяет пользователям одновременно просматривать и оценивать визуальные выходные данные нескольких моделей на основе одного и того же текстового запроса. Основная функция приложения заключается в организации бок-о-бок сравнения, что упрощает выявление различий в стиле, качестве и интерпретации запроса разными моделями. Это облегчает процесс оценки и выбора наиболее подходящей модели для конкретной задачи или применения.
Платформа MIRAGE использует сервис Replicate для хостинга и генерации изображений, что значительно упрощает процесс оценки. Replicate предоставляет унифицированный API для доступа к различным моделям генерации изображений, избавляя от необходимости самостоятельной установки и обслуживания этих моделей. Это позволяет исследователям и разработчикам быстро сравнивать результаты, полученные от разных моделей, не отвлекаясь на инфраструктурные вопросы. Интеграция с Replicate также обеспечивает масштабируемость и надежность процесса генерации изображений, необходимые для проведения всесторонней оценки.
В основе платформы MIRAGE лежит механизм микро-буферизации взаимодействий, предназначенный для смягчения влияния задержек при генерации изображений. Данная технология позволяет скрывать сетевые задержки и время обработки запросов к сервису Replicate, предоставляя пользователю более плавный и отзывчивый интерфейс. Вместо немедленного отображения промежуточных результатов или индикаторов загрузки, система накапливает небольшие порции данных, прежде чем представить их пользователю, создавая иллюзию мгновенной реакции и снижая когнитивную нагрузку, связанную с ожиданием завершения генерации.
В ходе пользовательского исследования было установлено, что 4 участника перешли от детального анализа отдельных изображений к оценке общих распределений выходных данных при сравнении нескольких моделей с использованием платформы MIRAGE. Это свидетельствует о том, что инструмент позволяет пользователям перейти от покомпонентного анализа к более глобальной оценке производительности моделей, фокусируясь на закономерностях и тенденциях в генерируемых изображениях, а не только на качестве отдельных результатов.

Раскрытие «личности» моделей и скрытых предубеждений
В ходе сравнительного анализа, проведенного в рамках платформы MIRAGE, было зафиксировано формирование различных визуальных стилей, характеризующих отдельные модели генерации изображений. В частности, модель Kandinsky 2.2 демонстрировала тенденцию к созданию ярких и насыщенных изображений, что позволило выделить её как модель с выраженной визуальной «личностью». Наблюдаемые различия в стилистике свидетельствуют о вариативности подходов к обработке и интерпретации входных данных различными моделями, а также о специфических особенностях их архитектуры и обучения.
В ходе анализа, модели генерации изображений Stable Diffusion демонстрировали склонность к неточностям в пропорциях объектов на сгенерированных изображениях. Данная особенность проявлялась в систематических искажениях размеров и соотношений частей изображения. Модель Latent Consistency, в свою очередь, часто выдавала результаты, характеризующиеся преувеличенными и мультяшными чертами. Это выражалось в гиперболизации форм и деталей, создавая эффект карикатурности. Наблюдения показали, что 6 участников отметили несоответствия в пропорциях изображений, сгенерированных Stable Diffusion, а 3 участника описали результаты Latent Consistency как преувеличенные или карикатурные.
Наблюдаемые визуальные различия в результатах, генерируемых разными моделями, напрямую связаны с предвзятостями и ограничениями, присутствующими в их обучающих данных. Неточности в пропорциях, характерные для Stable Diffusion, и склонность Latent Consistency к карикатурности, вероятно, являются следствием недостаточного или неравномерного представления определенных объектов и сцен в наборах данных, использованных для обучения. Это указывает на то, что модели воспроизводят и усиливают существующие смещения в данных, а не создают объективные изображения. Анализ, проведенный в рамках MIRAGE, показал, что 6 участников отметили неточности в пропорциях изображений, сгенерированных Stable Diffusion, а 3 — карикатурность или преувеличенность результатов Latent Consistency, что подтверждает зависимость визуального стиля от состава обучающего набора.
В ходе пользовательского тестирования было выявлено, что 6 из участников отметили несоответствия в пропорциях изображений, сгенерированных моделью Stable Diffusion. 3 участника описали результаты, полученные от Latent Consistency, как карикатурные или преувеличенные. Кроме того, у одного участника проявилось понимание смещения в отображении профессий — различие в цветотипе изображаемых рабочих (темнокожие в строительной одежде и светлокожие в офисной) — только после сопоставления результатов, полученных от нескольких моделей.
К надёжному и прозрачному аудиту ИИ: взгляд в будущее
Платформа MIRAGE представляет собой ценный инструмент для разработчиков искусственного интеллекта, исследователей и лиц, принимающих политические решения, стремящихся понять и смягчить потенциальные риски, связанные с моделями преобразования текста в изображения. Она позволяет комплексно анализировать выходные данные этих моделей, выявляя потенциальные предвзятости, нежелательный контент или несоответствия между текстовым запросом и сгенерированным изображением. Благодаря возможности сравнительного анализа и оценки восприятия пользователями, MIRAGE способствует разработке более надёжных и прозрачных систем искусственного интеллекта, отвечающих этическим нормам и требованиям безопасности. Этот подход особенно важен в контексте быстрого развития технологий генеративного ИИ и растущей необходимости в эффективных механизмах контроля качества и оценки рисков.
В центре внимания платформы MIRAGE находится визуальное сравнение и оценка восприятия пользователями, что отражает растущую потребность в объяснимом искусственном интеллекте. Вместо того чтобы полагаться исключительно на сложные метрики или внутреннюю работу модели, система акцентирует внимание на как изображения воспринимаются людьми. Такой подход позволяет выявить потенциальные предубеждения или нежелательные артефакты, которые могут быть незаметны при автоматизированном анализе. По сути, платформа стремится сделать процесс «аудита» моделей преобразования текста в изображения более прозрачным и понятным для широкой аудитории, от разработчиков до регуляторов, обеспечивая возможность оценки не только технических характеристик, но и фактического визуального результата и его соответствия ожиданиям пользователей.
Разработанная функция анонимного аудита предоставляет разработчикам возможность оценивать собственные проприетарные модели искусственного интеллекта, не раскрывая при этом конфиденциальную информацию о них. Этот подход позволяет проводить независимую оценку безопасности и надёжности моделей, выявляя потенциальные уязвимости и предвзятости, не ставя под угрозу интеллектуальную собственность. Система обеспечивает конфиденциальность данных, передаваемых для аудита, за счёт использования методов шифрования и обезличивания, гарантируя, что результаты оценки не могут быть сопоставлены с конкретной моделью или её создателем. Такой механизм способствует повышению прозрачности в сфере разработки ИИ и стимулирует создание более безопасных и ответственных технологий, позволяя разработчикам совершенствовать свои модели, не опасаясь утечки ценной информации.
В рамках исследования, в котором приняли участие 15 человек, был проведен 45-минутный опрос с денежным вознаграждением в размере 15 долларов за участие. Результаты показали, что пятеро респондентов особо выделили модель ByteDance Sdxl, отметив её выдающееся качество и наибольшее разнообразие генерируемых изображений. Данная оценка подчеркивает потенциал данной модели в сфере генерации визуального контента и может служить ориентиром для дальнейших разработок и совершенствования алгоритмов преобразования текста в изображения.

Исследование демонстрирует, что интерфейс MIRAGE, предлагая сопоставление изображений, созданных нейросетью, способствует более глубокому анализу и выявлению скрытых особенностей модели. Этот подход напоминает о важности взгляда на систему с разных сторон, что позволяет увидеть не только явные результаты, но и тонкие нюансы её ‘личности’. Как однажды заметил Пол Эрдёш: «Математика — это искусство видеть невидимое». Подобно тому, как математик ищет закономерности в абстракциях, так и аудитор, используя MIRAGE, стремится раскрыть скрытые предубеждения и особенности генеративных моделей, понимая, что детальное сопоставление — ключ к пониманию всей системы.
Куда же дальше?
Представленные исследования обнажают интересный парадокс: стремясь обуздать непредсказуемость генеративных моделей, наблюдатель невольно становится соучастником их «личностных» особенностей. Интерфейс, позволяющий сопоставлять изображения, порожденные текстом, — это лишь инструмент, но он подчеркивает, что истинная проверка — не в поиске единственно верного ответа, а в понимании логики, стоящей за ошибками. Важно помнить, что безопасность не в сокрытии алгоритмов, а в их прозрачности, дающей возможность реконструировать процесс генерации.
Остается открытым вопрос о масштабируемости подобного подхода. Способность человека к детальному сравнению ограничена, а сложность моделей постоянно растет. Следующим шагом видится разработка автоматизированных систем, имитирующих «боковое зрение» опытного аудитора, способных выявлять неявные закономерности и «слепые пятна» в генерациях. Необходимо отойти от поиска единых метрик «правильности» и сосредоточиться на выявлении паттернов отклонений, сигнализирующих о предвзятости или нежелательном поведении.
В конечном счете, задача не в том, чтобы «исправить» искусственный интеллект, а в том, чтобы научиться с ним взаимодействовать, понимая его ограничения и используя его сильные стороны. Это требует пересмотра самого понятия «аудита» — от простого контроля соответствия стандартам к постоянному процессу «реверс-инжиниринга» реальности, создаваемой машинами.
Оригинал статьи: https://arxiv.org/pdf/2511.21547.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Динамика в кадре: Как научить ИИ понимать физику видео
- Сердце музыки: открытые модели для создания композиций
- Автономные агенты для анализа материалов: новый уровень автоматизации
- Энергоэффективность сотовой сети: обучение с подкреплением и управление режимами сна
- Учимся разделять: Эффективное обучение пересечениям полупространств
- Распознавание антинуклеарных антител: обучение на собственном темпе
- Матричное умножение: новый рекорд эффективности
- Квантовая криптография: Готовность инфраструктуры открытых ключей к будущему
- Искусственный интеллект и выбор: как понять логику машины?
- Поиск ускользающих тау-лептонов: новые алгоритмы для CMS
2025-11-30 10:18