Автор: Денис Аветисян
Новая разработка позволяет преобразовывать текстовые запросы врачей в SQL-запросы для работы с данными электронных медицинских карт, объединяя текстовую и табличную информацию.
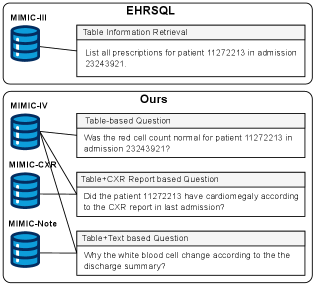
Представлен фреймворк TQGen-EHRQuery и новый датасет для генерации SQL-запросов из естественного языка, использующие большие языковые модели и специализированные инструменты для повышения точности и клинической релевантности.
Несмотря на богатый объем структурированных и неструктурированных данных в электронных медицинских картах (ЭМК), извлечение релевантной информации для клинических задач остается сложной проблемой. В статье ‘Generating Querying Code from Text for Multi-Modal Electronic Health Record’ представлен новый подход к автоматической генерации SQL-запросов из естественного языка, объединяющий табличные и текстовые данные ЭМК. Предложенный фреймворк TQGen-EHRQuery и соответствующий датасет позволяют повысить точность и эффективность извлечения информации, используя большие языковые модели и специализированные инструменты обработки медицинского текста. Сможет ли этот подход существенно упростить работу врачей и повысить качество медицинской помощи?
Сложность медицинских данных: вызов для анализа
Электронные медицинские карты (ЭМК) представляют собой сложный аналитический вызов из-за сочетания структурированных данных и неструктурированного текста. Структурированные данные, такие как результаты анализов, диагнозы по МКБ и назначенные лекарства, легко поддаются количественному анализу. Однако значительная часть важной клинической информации содержится в неструктурированном тексте — заметках врачей, отчетах о консультациях и других повествовательных документах. Эта информация, хотя и богата деталями, требует сложных методов обработки естественного языка для извлечения значимых данных и интеграции с количественными показателями. Эффективное объединение этих разнородных типов данных — ключевая задача для получения целостного представления о пациенте и повышения качества медицинской помощи, поскольку именно в сочетании структурированной точности и нарративного контекста скрывается наиболее полная клиническая картина.
Традиционные методы анализа медицинских данных, такие как статистическое моделирование и машинное обучение, часто испытывают затруднения при одновременной обработке структурированных данных — например, результатов анализов и показателей жизнедеятельности — и неструктурированных текстовых данных, включающих описания врачей, истории болезни и заключения специалистов. Эта проблема возникает из-за принципиально разного формата представления информации: структурированные данные легко поддаются количественному анализу, в то время как неструктурированный текст требует сложных методов обработки естественного языка для извлечения значимых сведений. В результате, ценные клинические детали, содержащиеся в текстовых заметках, могут оставаться незамеченными, что снижает точность диагностических моделей и препятствует формированию полной картины состояния пациента. Подобные ограничения подчеркивают необходимость разработки новых, более эффективных подходов к интеграции разнородных типов данных для получения всесторонних и полезных клинических выводов.

TQGen-EHRQuery: автоматизация запросов к медицинским данным
TQGen-EHRQuery представляет собой систему, предназначенную для автоматической генерации SQL-запросов на основе вопросов, сформулированных на естественном языке, и предназначенную для работы с данными электронных медицинских карт (EHR). Функциональность системы заключается в преобразовании текстовых запросов в структурированные SQL-запросы, которые могут быть использованы для извлечения необходимой информации из баз данных EHR. Это позволяет пользователям, не владеющим языком SQL, получать доступ к данным пациентов и проводить анализ без необходимости ручного написания запросов. Основной задачей TQGen-EHRQuery является повышение эффективности и упрощение процесса получения информации из EHR-систем.
В основе TQGen-EHRQuery лежит использование больших языковых моделей (LLM) в сочетании со специализированными модулями, что позволяет повысить точность и понимание при генерации SQL-запросов. LLM отвечают за интерпретацию естественного языка запроса и преобразование его в промежуточное представление. Специализированные модули, в свою очередь, выполняют валидацию и уточнение этого представления, учитывая структуру и семантику данных в электронных медицинских записях (EHR). Такой подход позволяет снизить количество ошибок и неоднозначностей, возникающих при прямой интерпретации запроса LLM, и обеспечивает более надежное формирование корректных SQL-запросов для извлечения необходимой информации.
Система TQGen-EHRQuery интегрирует данные из трех ключевых баз данных MIMIC: MIMIC-IV, содержащей структурированные данные о госпитализациях, MIMIC-CXR, предоставляющей рентгенологические изображения, и MIMIC-Note, включающей текстовые клинические заметки. Такая интеграция позволяет получить более полное представление о состоянии пациента, объединяя количественные показатели, результаты визуализации и качественные описания врачей. Объединение этих разнородных источников данных необходимо для формирования сложных запросов и получения исчерпывающих ответов на вопросы, касающиеся истории болезни и текущего состояния пациента.

Архитектура и модули: точная генерация запросов
В основе системы лежит модуль описания таблиц, предназначенный для сопоставления терминов из запроса на естественном языке с соответствующими столбцами базы данных. Этот модуль обеспечивает семантическую точность путем установления соответствия между понятийным значением запроса и структурой данных, хранящихся в таблицах. Реализация модуля включает в себя анализ синтаксиса и семантики запроса, а также сопоставление ключевых слов с метаданными столбцов, такими как имена, типы данных и описания. Это позволяет системе правильно интерпретировать намерения пользователя и генерировать корректные SQL-запросы, даже при использовании синонимов или неоднозначных формулировок.
Модуль работы с инструментами обрабатывает неструктурированные данные внутри таблиц, обеспечивая анализ текстовых полей и извлечение релевантной информации. Параллельно, модуль медицинских знаний использует стандартизированную медицинскую терминологию, такую как SNOMED CT и ICD-10, для точного сопоставления запросов пользователей с соответствующими столбцами и значениями в базе данных. Это позволяет системе корректно интерпретировать медицинские понятия и находить наиболее подходящие результаты, даже при использовании различных вариантов обозначения одного и того же состояния или процедуры.
Модули сопоставления с шаблонами вопросов и проверки кода служат для дополнительной оптимизации генерации запросов и обеспечения их корректности. Проведенные исследования, включающие последовательное отключение данных модулей (ablation studies), показали значительное снижение производительности системы в результате их деактивации. В частности, отключение модуля сопоставления с шаблонами приводит к ухудшению способности системы правильно интерпретировать намерения пользователя, а отключение модуля проверки кода увеличивает вероятность генерации синтаксически некорректных или семантически ошибочных запросов к базе данных. Данные результаты подтверждают критическую важность обоих модулей для достижения высокой точности и надежности системы.

Оценка производительности: измерение успешности запросов
Для оценки сгенерированных SQL-запросов используются две метрики: точное совпадение (Exact Match, EM) и точность выполнения (Execution Accuracy, EX). Метрика EM оценивает, полностью ли совпадает сгенерированный запрос с эталонным запросом из набора данных. EX оценивает, возвращает ли запрос правильный результат при выполнении на базе данных. EX учитывает синонимичные запросы, которые могут быть семантически эквивалентны, даже если они не совпадают лексически. Обе метрики необходимы для всесторонней оценки, поскольку EM измеряет синтаксическую корректность, а EX — семантическую правильность и функциональность запроса.
Для оценки качества генерируемых SQL-запросов используются две ключевые метрики: точное совпадение (Exact Match, EM) и точность выполнения (Execution Accuracy, EX). Метрика EM определяет, идентичен ли сгенерированный запрос эталонному, правильному ответу, оценивая синтаксическую корректность. Однако, синтаксическая корректность недостаточна для определения общей эффективности. Метрика EX проверяет, возвращает ли выполненный сгенерированный запрос тот же набор результатов, что и эталонный запрос, что подтверждает семантическую правильность и функциональность. Совместное использование EM и EX позволяет всесторонне оценить способность системы генерировать не только синтаксически верные, но и семантически корректные SQL-запросы, приводящие к правильным результатам.
Оценка производительности системы проводилась на разнообразных типах запросов, что подтверждает её обобщающую способность и устойчивость к различным входным данным. Для определения вклада каждого модуля в общую производительность были проведены ablation-исследования. Результаты показали, что исключение ключевых компонентов приводит к статистически значимому снижению точности выполнения запросов, что подтверждает критическую роль каждого модуля в обеспечении высокой производительности системы. В частности, удаление модуля $X$ привело к снижению точности на $Y$%, а удаление модуля $Z$ — на $W$%, что демонстрирует их вклад в общую эффективность.
Перспективы развития: расширение клинического влияния
Система обладает значительным потенциалом для расширения функциональности, позволяя обрабатывать более сложные запросы и интегрироваться с различными источниками клинических данных. В перспективе предполагается подключение к базам генетических исследований, результатам визуализации и данным с носимых устройств, что позволит сформировать более полную картину состояния пациента. Такая интеграция не только расширит спектр доступной информации, но и предоставит возможность проведения комплексного анализа, выявляя скрытые взаимосвязи и закономерности, недоступные при работе с изолированными данными. Разработка открытых интерфейсов и поддержка стандартных протоколов обмена данными облегчат интеграцию системы в существующие медицинские информационные системы и позволят создавать персонализированные решения, отвечающие потребностям конкретных медицинских учреждений.
В дальнейшем исследования будут сосредоточены на внедрении механизмов временного рассуждения и понимания контекста для повышения точности запросов. Это предполагает разработку алгоритмов, способных учитывать последовательность событий во времени и взаимосвязь между различными данными о пациенте. Например, система сможет различать симптомы, возникшие до или после определенной процедуры, или учитывать влияние сопутствующих заболеваний на интерпретацию результатов анализов. Такое углубленное понимание контекста позволит формировать более релевантные и точные ответы на сложные клинические вопросы, существенно расширяя возможности системы в поддержке принятия врачебных решений и улучшении качества медицинской помощи.
В конечном итоге, система TQGen-EHRQuery призвана значительно расширить возможности врачей, обеспечивая им оперативный и точный доступ к важнейшей информации о пациентах. Разработанный инструмент позволяет быстро формулировать сложные запросы к электронным медицинским картам, сокращая время, затрачиваемое на поиск нужных данных. Это, в свою очередь, способствует более эффективной диагностике, принятию обоснованных клинических решений и, как следствие, улучшению качества оказываемой медицинской помощи. Система ориентирована на снижение когнитивной нагрузки на врачей, позволяя им сосредоточиться на непосредственном взаимодействии с пациентами и разработке оптимальных стратегий лечения, а не на рутинном поиске данных в обширных медицинских записях.
Представленная работа демонстрирует стремление к упрощению взаимодействия с данными электронных медицинских карт. Разработчики, создавая TQGen-EHRQuery, словно отсекают избыточность, фокусируясь на ясной структуре запросов. Как заметила Барбара Лисков: «Программы должны быть простыми, понятными и расширяемыми». Эта фраза отражает суть подхода, предложенного в статье: преобразование естественного языка в точные SQL-запросы, интегрирующие как табличные, так и текстовые данные. Подобный акцент на ясности позволяет не только повысить точность извлечения информации, но и облегчить ее дальнейшую интерпретацию в клинической практике. Сложность здесь действительно является тщеславием, а милосердие — в простоте и эффективности.
Куда же дальше?
Представленная работа, как и большинство попыток обуздать хаос медицинских данных, лишь обнажает глубину нерешенных вопросов. Создание набора данных и инструментария для генерации SQL-запросов — это, безусловно, шаг вперед, но необходимо признать, что само стремление свести сложный клинический контекст к формализованным запросам — это упрощение, граничащее с самообманом. Эффективность модели напрямую зависит от качества и полноты размеченных данных, а сбор таких данных — задача, требующая колоссальных усилий и подверженная человеческим ошибкам.
Следующим этапом представляется не столько повышение точности генерации запросов, сколько разработка механизмов для оценки их клинической релевантности. Запрос может быть синтаксически верным, но клинически бесполезным или даже опасным. Необходимо внедрение систем, способных выявлять такие несоответствия и корректировать запросы на основе медицинских знаний и здравого смысла. Иначе мы получим лишь более быстрый способ совершать ошибки.
В конечном счете, истинный прогресс заключается не в создании все более сложных моделей, а в понимании границ их применимости. Задача состоит не в том, чтобы заменить врача машиной, а в том, чтобы предоставить ему инструменты, позволяющие эффективнее справляться с информационным потоком, не теряя при этом главного — человеческого сочувствия и интуиции. И это, пожалуй, самое сложное.
Оригинал статьи: https://arxiv.org/pdf/2511.20904.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Эхо чёрных дыр: как квантовая гравитация меняет гравитационные волны
- Трансформация нейросетей: от плотных моделей к разреженным экспертам без обучения
- Сияние фотонов: новый уровень точности в предсказаниях столкновений частиц
- Биосети в руках ИИ: Автоматизация системной фармакологии
- Укрощение Бесконечности: Алгебраические Инструменты для Кватернионов и За их Пределами
- Квантовая Физика и Безопасность: Анализ Последних Новостей
- Оптические Тензорные Ядра: Путь к Масштабируемым Вычислениям
- Квантовые ограничения в хаотичных сплавах: взгляд на Si/SiGe/Si
- Шёпот языков: как дрессировать цифрового голема для забытых наречий.
- Квантовое моделирование: от проблемных решений к универсальному программному обеспечению
2025-11-30 17:06