Автор: Денис Аветисян
Новое исследование предлагает метод корректировки знаний больших языковых моделей, чтобы они не предлагали устаревшие или неактуальные API для разработчиков.

Представлен бенчмарк EDAPIBench для оценки и улучшения способности языковых моделей избегать рекомендаций по устаревшим API, а также продемонстрирована эффективность модифицированной техники AdaLoRA-L.
Несмотря на впечатляющие возможности больших языковых моделей (LLM) в задачах генерации кода, их знания часто устаревают из-за использования в обучающих данных устаревших API. В работе ‘Lightweight Model Editing for LLMs to Correct Deprecated API Recommendations’ представлено исследование, направленное на эффективное обновление знаний LLM об API с использованием методов легковесного редактирования моделей. Показано, что модификация метода AdaLoRA, названная AdaLoRA-L, позволяет значительно улучшить точность генерации актуальных API, одновременно сохраняя общие знания модели. Какие перспективы открываются для применения подобных методов редактирования моделей для адаптации LLM к быстро меняющимся требованиям современной разработки программного обеспечения?
Эволюция API и Вызовы для Больших Языковых Моделей
Современное программное обеспечение в значительной степени опирается на интерфейсы прикладного программирования (API), которые, однако, подвержены постоянным изменениям и обновлениям. Эта динамичная среда характеризуется регулярным появлением новых версий API и выводом из эксплуатации устаревших, что требует от разработчиков постоянной адаптации и внесения изменений в свои приложения. Примером такой практики служит концепция “устаревшего API”, когда прежние методы взаимодействия становятся неактуальными, а разработчикам необходимо переходить на новые. Подобная изменчивость, хотя и необходима для прогресса и внедрения инноваций, создает определенные трудности в поддержании стабильности и долгосрочной работоспособности программных систем, требуя постоянного мониторинга и оперативного реагирования на изменения в API.
Крупные языковые модели (LLM) испытывают значительные трудности при адаптации к постоянно меняющимся интерфейсам прикладного программирования (API). Каждое обновление или прекращение поддержки существующего API требует дорогостоящей переподготовки модели, чтобы сохранить её функциональность и точность. Это связано с тем, что LLM, как правило, обучаются на конкретных версиях API, и изменения в этих интерфейсах приводят к несоответствиям и ошибкам в обработке данных. В результате, разработчики сталкиваются с необходимостью регулярных и ресурсоемких циклов переобучения, что существенно увеличивает стоимость обслуживания приложений, использующих LLM, и ограничивает их долгосрочную надежность и масштабируемость. Таким образом, проблема адаптации к API-эволюции является одним из ключевых вызовов для широкого внедрения и эффективного использования LLM в реальных приложениях.
Постоянные изменения в API создают ощутимую нагрузку на сопровождение приложений, использующих большие языковые модели (LLM). Необходимость регулярной переподготовки моделей для адаптации к обновленным или устаревшим API не только требует значительных вычислительных ресурсов и времени, но и снижает долгосрочную стабильность и надежность программного обеспечения. В условиях динамично меняющегося ландшафта API, приложения, зависящие от LLM, сталкиваются с риском внезапного прекращения работы или снижения качества предоставляемых услуг, что требует от разработчиков постоянного мониторинга и оперативного реагирования на изменения. Эта ситуация подчеркивает важность разработки более гибких и адаптивных LLM, способных самостоятельно справляться с эволюцией API без необходимости дорогостоящей переподготовки.

Целенаправленная Адаптация: Эффективная Настройка с Минимальными Затратами
Традиционная тонкая настройка больших языковых моделей (LLM) требует значительных вычислительных ресурсов, поскольку предполагает обновление всех параметров модели. Это делает процесс дорогостоящим и непрактичным для многих приложений, особенно при работе с ограниченными аппаратными средствами или при необходимости частого обновления модели. Параметрически-эффективная тонкая настройка (Parameter-Efficient Fine-tuning, PEFT) представляет собой альтернативный подход, позволяющий адаптировать LLM к новым задачам или данным, обновляя лишь небольшую часть параметров. Вместо обновления всех $n$ параметров, PEFT методы используют стратегии, такие как добавление небольшого числа новых параметров или использование низкоранговых адаптаций, что значительно снижает вычислительные затраты и требования к памяти, сохраняя при этом производительность, сопоставимую с полной тонкой настройкой.
Парадигма редактирования модели позволяет большим языковым моделям (LLM) усваивать новую информацию или исправлять ошибки без необходимости обновления всех параметров модели. Вместо полной перенастройки, этот подход фокусируется на модификации лишь небольшого подмножества параметров, что значительно снижает вычислительные затраты и требования к памяти. Это достигается путем идентификации и обновления только тех весов, которые наиболее релевантны для конкретной задачи или исправления, оставляя остальную часть модели неизменной. Такой подход позволяет поддерживать существующие знания модели, избегая “катастрофического забывания”, и обеспечивает более эффективное и экономичное обучение.
Методы, такие как AdaLoRA, позволяют эффективно обновлять большие языковые модели (LLM) с минимальными вычислительными затратами за счет использования низкоранговых адаптеров. Вместо обновления всех параметров модели, AdaLoRA вводит небольшое количество обучаемых параметров — низкоранговые матрицы — которые добавляются к существующим весам. Это существенно снижает количество параметров, требующих градиентного обновления, что приводит к уменьшению потребления памяти и ускорению процесса обучения. Эффективность AdaLoRA достигается за счет декомпозиции изменений весов на низкоранговые представления, что позволяет модели адаптироваться к новым данным, сохраняя при этом большую часть исходных знаний. Данный подход особенно полезен при работе с моделями, насчитывающими миллиарды параметров, где традиционное обучение с обратным распространением ошибки становится непрактичным из-за высоких требований к вычислительным ресурсам и памяти.
AdaLoRA-L: Точное Редактирование для API-Специфичных Знаний
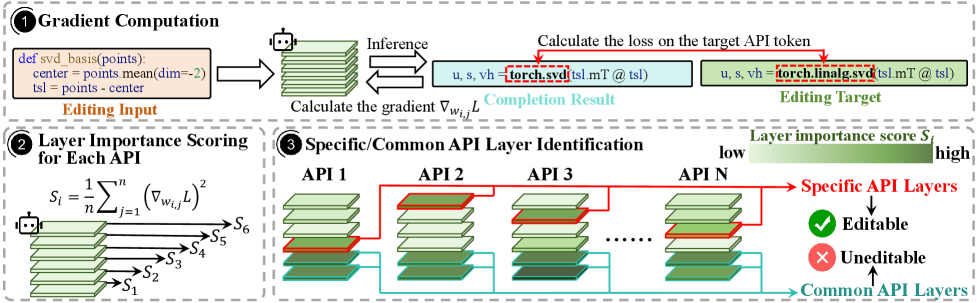
AdaLoRA-L расширяет возможности AdaLoRA за счет концентрации изменений на специфических слоях API, что обеспечивает целенаправленное обновление знаний, связанных с API. В отличие от AdaLoRA, который модифицирует все слои, AdaLoRA-L выделяет и редактирует только те слои, которые непосредственно отвечают за обработку и использование конкретных API. Такой подход позволяет более точно адаптировать модель к изменениям в API, минимизируя при этом влияние на общие знания и функциональность. Фокусировка на специфических слоях API повышает эффективность обучения и позволяет достичь более высоких показателей точности при работе с API-запросами и данными.
В AdaLoRA-L исключение из процесса редактирования слоев, относящихся к общим API, направлено на повышение специфичности изменений и снижение вероятности внесения нежелательных корректировок в общие знания модели. Такой подход позволяет более точно нацеливать обновления на API-специфичные слои, избегая влияния на другие части модели, что обеспечивает сохранение её общих способностей и улучшает производительность при работе с конкретными API. Это позволяет избежать деградации модели в задачах, не связанных с целевыми API, и повышает стабильность и предсказуемость её поведения.
Оценка эффективности AdaLoRA-L проводилась с использованием специализированных бенчмарков, таких как EDAPIBench и CodeSyncBench. EDAPIBench предназначен для проверки способности модели корректировать изменения параметров API, в то время как CodeSyncBench оценивает поддержание согласованного поведения при использовании обновленных API. Эти бенчмарки позволяют количественно оценить, насколько точно модель адаптируется к изменениям в API и сохраняет функциональность кода после внесения изменений, что является критически важным для практического применения в реальных проектах разработки.
Оценка AdaLoRA-L на платформе CodeUpdateArena подтверждает её эффективность в генерации корректного кода с учетом обновленных вызовов API. Данная платформа позволяет оценить способность модели адаптироваться к изменениям в API и генерировать код, который правильно использует новые версии функций и параметров. Результаты тестирования на CodeUpdateArena демонстрируют, что AdaLoRA-L превосходит базовую модель AdaLoRA в задачах, требующих точного применения обновленных API, что свидетельствует о её улучшенной способности к адаптации и генерации кода, соответствующего текущим требованиям API.
В ходе экспериментов AdaLoRA-L продемонстрировала значительное повышение точности при редактировании API-специфичных знаний. На модели Qwen2.5-Coder наблюдалось улучшение показателя Specificity (API Exact Match) до 836.2% по сравнению с базовой моделью AdaLoRA, что свидетельствует о значительном повышении способности точно воспроизводить API-интерфейсы. На модели DeepSeek-Coder улучшение составило 33.5%, подтверждая эффективность подхода AdaLoRA-L в различных архитектурах моделей. Данные результаты указывают на существенное повышение способности AdaLoRA-L к точной адаптации к изменениям в API.
Экспериментальные данные демонстрируют, что AdaLoRA-L обеспечивает повышение переносимости (Portability) на 6.9-29.8% при использовании различных моделей. Переносимость в данном контексте оценивает способность адаптироваться к новым архитектурам моделей без существенной потери производительности. Увеличение данного показателя свидетельствует о более эффективной генерализации знаний, специфичных для API, и снижает зависимость от конкретных параметров модели, что делает AdaLoRA-L более гибким и применимым в различных сценариях разработки.
Влияние и Перспективы для Адаптивности Больших Языковых Моделей
Разработанная методика AdaLoRA-L значительно повышает переносимость больших языковых моделей (LLM), позволяя им беспрепятственно адаптироваться к обновленным API в различных экземплярах. Вместо полной переподготовки модели при изменении внешнего интерфейса, AdaLoRA-L использует эффективную настройку параметров, что обеспечивает плавную интеграцию с новыми версиями API без потери производительности. Это особенно важно в динамичных средах разработки, где API часто обновляются, и позволяет существенно снизить затраты на сопровождение и ускорить цикл разработки приложений, использующих LLM.
Снижение затрат на поддержку и ускорение цикла разработки приложений, использующих внешние API, стало возможным благодаря AdaLoRA-L. Традиционно, любое изменение в API требовало значительных усилий по перенастройке и тестированию, что приводило к существенным финансовым и временным затратам. Однако, благодаря адаптивности, обеспечиваемой данной технологией, приложения способны автоматически подстраиваться под обновленные интерфейсы API, минимизируя необходимость ручного вмешательства. Это позволяет разработчикам быстрее внедрять новые функции и исправления, а также существенно сократить расходы на сопровождение и поддержку существующих систем, что особенно важно для быстро развивающихся облачных сервисов и приложений, зависящих от внешних источников данных и функциональности.
Внедрение больших языковых моделей, таких как GPT-4.1, значительно упрощает процесс обновления и доработки кода, необходимого для взаимодействия с внешними API. Эти модели способны автоматически генерировать и предлагать фрагменты кода, адаптирующиеся к изменениям в структуре API, что позволяет разработчикам избегать рутинной работы и оперативно реагировать на обновления. Использование GPT-4.1 не только ускоряет процесс разработки, но и снижает вероятность ошибок, связанных с человеческим фактором при внесении изменений в код, обеспечивая более стабильную и эффективную интеграцию с внешними сервисами. Это, в свою очередь, позволяет приложениям оставаться актуальными и функциональными даже при частых обновлениях используемых API.
Дальнейшие исследования направлены на полную автоматизацию процесса редактирования API, что позволит существенно упростить адаптацию больших языковых моделей к изменяющимся внешним интерфейсам. Разработчики стремятся расширить возможности AdaLoRA-L для обработки более сложных взаимодействий с API, включая случаи, когда требуется динамическая адаптация к различным параметрам и типам данных. Планируется внедрение алгоритмов, способных автоматически выявлять и устранять несовместимости между моделью и обновлённым API, минимизируя необходимость ручного вмешательства и обеспечивая бесперебойную работу приложений, использующих эти модели. Успешная реализация этих задач позволит значительно сократить время и затраты на поддержку и обновление систем, основанных на больших языковых моделях, и откроет новые возможности для их применения в динамично меняющейся среде.
Представленное исследование демонстрирует, что системы искусственного интеллекта, в частности большие языковые модели, нуждаются не в жестком программировании, а в органическом росте знаний. Авторы предлагают подход к адаптации моделей к изменяющимся условиям — устареванию API — не через перестройку, а через аккуратное добавление новых паттернов. Это напоминает о высказывании Барбары Лисков: «Программы должны быть спроектированы так, чтобы изменения в одной части не влияли на другие». В данном контексте, AdaLoRA-L выступает инструментом для локального, контролируемого “выращивания” знаний, минимизируя риск дестабилизации всей системы. Система, которая никогда не адаптируется к новым условиям, обречена на стагнацию, а в мире программного обеспечения — и на забвение.
Что дальше?
Представленная работа, безусловно, демонстрирует возможность корректировки знаний больших языковых моделей в отношении устаревших API. Однако, следует признать, что «масштабируемость» этой корректировки — лишь слово, призванное оправдать неизбежную сложность. Каждый адаптированный API — это пророчество о будущем, когда и эти изменения потребуют обновления. Неизбежно возникнет вопрос: где предел этой бесконечной адаптации? Попытки создать «идеальную архитектуру» для поддержания актуальности знаний — миф, необходимый, чтобы не сойти с ума, но сам по себе иллюзорен.
Более глубокий вопрос заключается не в том, как быстро корректировать знания, а в том, нужно ли вообще стремиться к их полной актуальности. Возможно, истинная сила больших языковых моделей кроется не в безупречной точности, а в способности генерировать неожиданные, но полезные решения, даже опираясь на слегка устаревшие данные. Всё, что оптимизировано для точности, однажды потеряет гибкость.
Будущие исследования должны сосредоточиться не на совершенствовании механизмов коррекции, а на изучении способов сосуществования актуальных и устаревших знаний, на поиске баланса между точностью и креативностью. Системы — это не инструменты, а экосистемы. Их нельзя построить, только взрастить, признавая, что хаос и непредсказуемость — неотъемлемые части любого растущего организма.
Оригинал статьи: https://arxiv.org/pdf/2511.21022.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Эхо чёрных дыр: как квантовая гравитация меняет гравитационные волны
- Сияние фотонов: новый уровень точности в предсказаниях столкновений частиц
- Сверхпроводящая логика: управление магнитным полем
- Трансформация нейросетей: от плотных моделей к разреженным экспертам без обучения
- Квантовые вычисления: Честность и Прогресс
- Квантовые сети связи: оптимизация расписания для спутниковой передачи
- Квантовый горизонт: взгляд изнутри
- Глубокий поиск: новый взгляд на мультимодальные исследования
- Квантовый поиск гравитационных волн: новый алгоритм для повышения точности
- Квантовый скачок в многомасштабном моделировании
2025-12-01 01:27