Автор: Денис Аветисян
Исследователи предлагают метод HTTM, позволяющий значительно повысить скорость работы модели VGGT при создании трехмерных моделей из видеоданных.

HTTM — это подход к объединению токенов, не требующий обучения, который эффективно использует временную согласованность и особенности внимания на уровне голов для ускорения 3D-реконструкции.
Несмотря на значительный прогресс в 3D-реконструкции, модель Visual Geometry Grounded Transformer (VGGT) сталкивается с ограничениями по скорости обработки больших сцен из-за вычислительно сложных механизмов глобального внимания. В данной работе, представленной под названием ‘HTTM: Head-wise Temporal Token Merging for Faster VGGT’, предлагается метод обучения без учителя — head-wise temporal token merging (HTTM) — для ускорения VGGT, который эффективно использует временную согласованность и особенности внимания на уровне отдельных голов. HTTM позволяет добиться ускорения до 7 раз при незначительной потере производительности, сохраняя уникальность признаков после объединения токенов. Возможно ли дальнейшее совершенствование HTTM для адаптации к еще более крупным и сложным 3D-сценам и снижения вычислительных затрат?
Предел масштабируемости: вызовы 3D-реконструкции
Традиционные методы трехмерной реконструкции, такие как используемые в моделях DUSt3R и MASt3R, основанные на прямом распространении данных, сталкиваются со значительными вычислительными трудностями при работе с высокодетализированными сценами. Проблема заключается в экспоненциальном росте требуемых ресурсов по мере увеличения разрешения и сложности реконструируемого объекта. В частности, обработка большого объема данных, необходимого для создания точной трехмерной модели, требует огромных объемов памяти и процессорного времени, что делает реконструкцию высококачественных сцен крайне затратной и часто непрактичной на доступном оборудовании. Поэтому поиск эффективных алгоритмов, способных снизить вычислительную нагрузку без потери качества реконструкции, является ключевой задачей в данной области.
Квадратичная сложность механизмов внимания, лежащих в основе современных трансформаторных сетей, представляет собой существенное препятствие для масштабирования 3D-реконструкции. В процессе обработки длинных последовательностей данных, необходимых для детализированных сцен, вычислительные затраты растут пропорционально квадрату числа элементов. Это означает, что увеличение разрешения реконструируемой среды или длины обрабатываемой последовательности приводит к экспоненциальному увеличению требуемых ресурсов. В результате, даже при использовании мощных вычислительных систем, эффективность трансформаторов в задачах реконструкции ограничивается, что препятствует созданию высококачественных 3D-моделей сложных и обширных пространств. Преодоление этой вычислительной сложности является ключевой задачей для развития более эффективных и масштабируемых методов 3D-реконструкции.
Ограничения существующих методов обработки визуальной информации требуют разработки инновационных подходов к 3D-реконструкции. Традиционные алгоритмы сталкиваются с трудностями при обработке больших объемов данных, необходимых для создания высокодетализированных моделей. В связи с этим, активно исследуются новые архитектуры и методы оптимизации, направленные на повышение эффективности обработки изображений без потери качества реконструкции. Особое внимание уделяется алгоритмам, способным масштабироваться для работы с длинными последовательностями данных и сложными сценами, позволяя создавать реалистичные и точные 3D-модели даже при ограниченных вычислительных ресурсах. Разработка таких подходов является ключевой задачей для расширения возможностей 3D-реконструкции в различных областях, от виртуальной реальности до робототехники.

Разреженность как путь к эффективности: первые шаги
Разреженные трансформеры, такие как Sparse Transformer и BigBird, стремятся снизить вычислительную сложность за счет фокусировки механизма внимания на подмножестве наиболее релевантных токенов. Этот подход основан на принципе разреженности, подразумевающем, что не все связи между токенами одинаково важны для обработки. Вместо вычисления внимания для каждой пары токенов, эти модели выбирают только определенные, наиболее значимые связи, что позволяет значительно уменьшить количество операций и потребление памяти, особенно при работе с длинными последовательностями данных. Выбор подмножества токенов осуществляется различными методами, включая фиксированные паттерны, обучение масок разреженности или использование структурных признаков данных.
Несмотря на снижение вычислительной сложности, методы разреженных трансформаторов сталкиваются с ограничениями, связанными с необходимостью определения наиболее значимых токенов для формирования разреженной матрицы внимания. Процесс выбора этих токенов требует дополнительных вычислений, что вносит накладные расходы и может снизить общую эффективность. Некорректный выбор важных токенов приводит к потере информации, необходимой для точного представления данных, что негативно влияет на качество конечного результата, особенно в задачах, требующих учета контекста и взаимосвязей между всеми элементами входной последовательности.
Существующие методы разреженного внимания, такие как Sparse Transformer и BigBird, зачастую разрабатываются и применяются вне контекста специфических требований задач трехмерной реконструкции. Это приводит к неоптимальной производительности, поскольку они не учитывают особенности данных, характерные для 3D-сцен, и не адаптированы к специфическим потребностям эффективного восстановления геометрии и текстур. Отсутствие интеграции с процессами обработки 3D-данных и ограничения в учете пространственной структуры ограничивают потенциал этих методов в задачах трехмерной реконструкции по сравнению с подходами, разработанными специально для этой цели.

Слияние токенов: новый подход к эффективности
Метод объединения токенов (ToMe, ToMeSD) представляет собой эффективный подход к сокращению длины последовательности, что приводит к снижению вычислительных затрат. Данный метод основан на интеллектуальном объединении схожих токенов в единый токен, уменьшая тем самым общее количество элементов в последовательности. Снижение длины последовательности напрямую влияет на объем необходимой памяти и количество операций, требуемых для обработки, особенно в задачах, связанных с большими языковыми моделями и обработкой видео. Эффективность ToMe и ToMeSD обусловлена способностью сохранять семантическую информацию при уменьшении размера входных данных, что делает их применимыми в различных сценариях, где важна оптимизация ресурсов.
Расширения, такие как ToFu, усовершенствуют процесс объединения токенов, предлагая не только их слияние, но и отсечение (pruning). Это обеспечивает повышенную гибкость и контроль над сокращением последовательностей. Отсечение позволяет удалять незначимые токены, не влияющие на качество модели, в то время как слияние объединяет семантически близкие токены. Комбинация этих двух методов позволяет более эффективно управлять длиной последовательности и снижать вычислительные затраты, сохраняя при этом необходимую информацию для точного анализа и генерации данных. ToFu позволяет пользователям настраивать параметры отсечения и слияния, оптимизируя процесс под конкретные задачи и модели.
Эффективность объединения токенов напрямую зависит от качества процесса и потенциальной потери информации. Особенно критичным является сохранение пространственно-временной согласованности — способности модели правильно интерпретировать взаимосвязи между элементами последовательности во времени и пространстве. Некачественное объединение токенов может привести к искажению или потере важных деталей, что негативно скажется на производительности модели в задачах, требующих понимания последовательностей, таких как обработка видео, анализ временных рядов или моделирование физических процессов. Для минимизации этих рисков необходимо тщательно оценивать критерии объединения и проводить валидацию на репрезентативных данных, чтобы убедиться в сохранении ключевой информации после применения процедуры объединения.
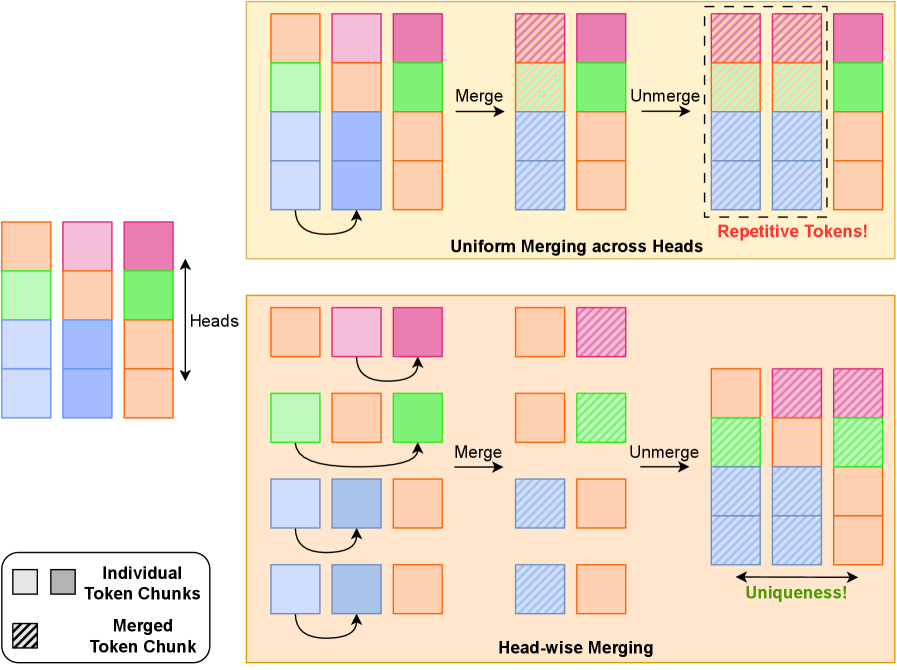
HTTM: Слияние токенов без обучения для VGGT
Метод HTTM представляет собой способ объединения токенов, не требующий обучения, и предназначен для глобальных слоёв внимания в VGGT. Он позволяет снизить вычислительные затраты на объединение токенов в 4.58 раза, что значительно ускоряет процесс 3D-реконструкции сцен. В отличие от методов, требующих предварительного обучения, HTTM оперирует непосредственно с входными данными, что снижает сложность и время, необходимые для подготовки модели. Это достигается за счет оптимизации процесса агрегации токенов, что позволяет эффективно обрабатывать большие объемы данных, необходимые для создания детализированных 3D-моделей.
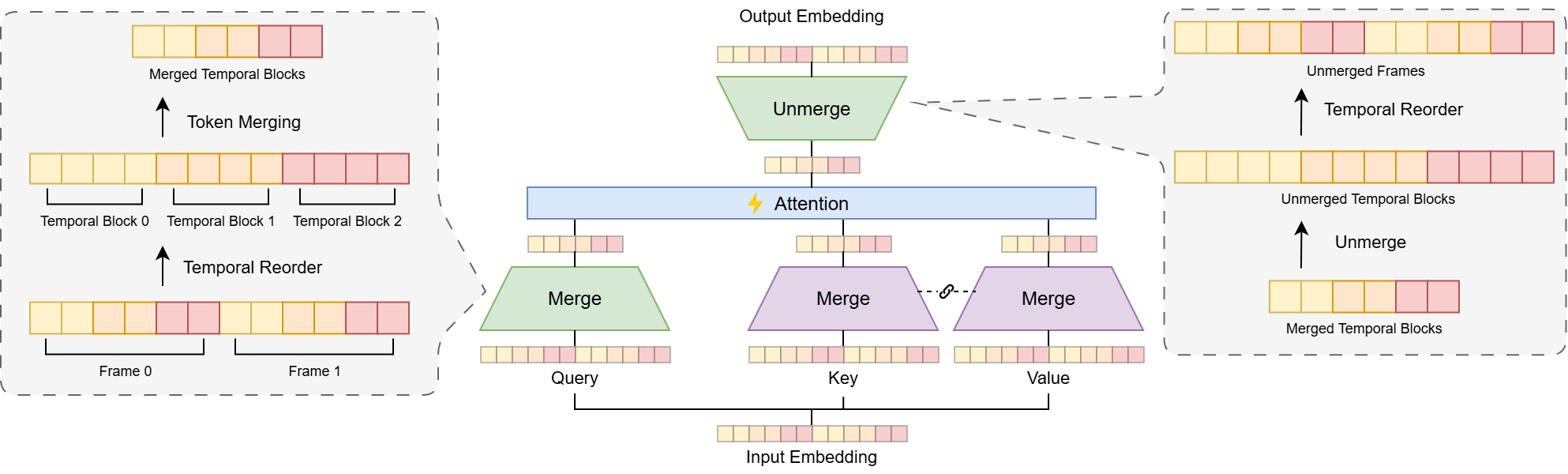
Метод HTTM использует комбинацию из трех ключевых компонентов для обеспечения высокого качества и пространственно-временной согласованности при объединении токенов. Временная перестановка оптимизирует порядок обработки токенов во временной последовательности, что позволяет более эффективно использовать ресурсы и ускорить процесс. Блочное объединение токенов группирует токены в блоки для параллельной обработки, что существенно повышает производительность. Наконец, адаптивная фильтрация выбросов выявляет и удаляет нерелевантные или ошибочные токены, улучшая точность и стабильность результата объединения. Совместная работа этих компонентов позволяет HTTM эффективно обрабатывать длинные последовательности данных, сохраняя при этом высокую степень детализации и согласованности реконструируемых 3D-сцен.
Метод HTTM обеспечивает значительное повышение эффективности за счет использования разреженности блоков и FlashAttention. При обработке длинных последовательностей (1000 кадров) достигается ускорение в 7 раз по сравнению с традиционными методами, при этом точность реконструкции не снижается. Использование разреженности блоков позволяет уменьшить объем вычислений и потребление памяти, а FlashAttention оптимизирует вычисления внимания, что особенно важно при работе с длинными последовательностями данных. Данная оптимизация позволяет снизить вычислительную сложность и повысить пропускную способность при реконструкции 3D-сцен.
Перспективы развития: масштабирование и за его пределами
Успех методики HTTM наглядно демонстрирует потенциал слияния токенов без этапа обучения для эффективной 3D-реконструкции. В отличие от традиционных подходов, требующих обширных наборов данных и длительного обучения, HTTM позволяет создавать трехмерные модели, используя лишь геометрическую информацию, что значительно ускоряет процесс и снижает вычислительные затраты. Этот прорыв открывает перспективы для создания приложений, работающих в режиме реального времени, где быстрая и точная реконструкция трехмерного пространства является критически важной. Представьте себе системы дополненной реальности, мгновенно воссоздающие окружение, или роботов, способных ориентироваться в сложных условиях без предварительного обучения — все это становится возможным благодаря эффективности HTTM и принципу слияния токенов без обучения.
Дальнейшие исследования направлены на оптимизацию вычислительных затрат, связанных с процессом объединения токенов, что позволит повысить скорость и эффективность реконструкции трехмерных объектов. Особое внимание уделяется разработке более устойчивых алгоритмов для обработки выбросов — аномальных токенов, которые могут искажать конечную модель. Кроме того, планируется интеграция данной технологии с передовыми конвейерами рендеринга и обработки данных, такими как нейронные сети для повышения реалистичности и детализации. Такое сочетание позволит не только ускорить процесс реконструкции, но и значительно улучшить качество получаемых трехмерных моделей, открывая новые возможности для применения в различных областях, включая робототехнику, дополненную и виртуальную реальность, а также сохранение культурного наследия.
В конечном итоге, представленные усовершенствования в области трехмерной реконструкции обещают сделать высококачественное моделирование доступным широкому кругу пользователей. Это открывает новые перспективы для создания захватывающих иммерсивных впечатлений, а также значительно расширяет возможности в таких областях, как робототехника, дополненная и виртуальная реальность. Более того, данная технология может сыграть ключевую роль в сохранении и популяризации культурного наследия, позволяя создавать цифровые копии исторических артефактов и памятников архитектуры с беспрецедентной точностью. Возможность быстрого и эффективного создания трехмерных моделей снижает барьеры для творчества и инноваций, стимулируя развитие новых приложений и сервисов в самых разных сферах деятельности.

Исследование демонстрирует стремление к оптимизации, к поиску компромисса между вычислительной сложностью и качеством результата. Авторы предлагают подход HTTM, который, по сути, признает неизбежность технических ограничений и пытается их обойти, используя временную когерентность и особенности внимания. Это напоминает о том, что элегантная теория часто сталкивается с суровой реальностью продакшена. Как однажды заметил Дэвид Марр: «Проблема не в том, что мы не можем создать идеальную модель, а в том, что идеальная модель не поместится в память». Попытка ускорить VGGT, не прибегая к переобучению, — это прагматичный шаг, признающий, что иногда лучшее решение — это не самое красивое, а самое рабочее.
Что дальше?
Предложенный подход HTTM, безусловно, демонстрирует прирост скорости, но не стоит обманываться иллюзией окончательного решения. Каждый «ускоритель» порождает новую узкую точку. В конечном итоге, прирост производительности всегда будет съедаться возрастающей сложностью данных и желанием получить ещё большую детализацию реконструкций. Багтрекер скоро пополнится новыми тикетами о проблемах с временной когерентностью на граничных случаях.
Настоящая проблема не в скорости вычислений, а в самом представлении временных рядов. Ускорять обработку данных — это лишь временное облегчение. Гораздо важнее — найти более компактное и эффективное представление информации о движении, которое не требовало бы обработки каждого кадра по отдельности. Вполне вероятно, что следующая «революция» будет заключаться не в улучшении существующих attention-механизмов, а в полном отказе от них в пользу чего-то принципиально нового.
Этот труд — лишь ещё одна ступенька на пути к автоматизированной 3D-реконструкции. В конечном итоге, все эти оптимизации — лишь попытки отсрочить неизбежное: необходимость переосмыслить сам подход к моделированию временных последовательностей. Мы не деплоим — мы отпускаем этот алгоритм в дикую природу, где он столкнется с реальностью, намного более жестокой, чем любые бенчмарки.
Оригинал статьи: https://arxiv.org/pdf/2511.21317.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Трансформация нейросетей: от плотных моделей к разреженным экспертам без обучения
- Эхо чёрных дыр: как квантовая гравитация меняет гравитационные волны
- Сияние фотонов: новый уровень точности в предсказаниях столкновений частиц
- Сверхпроводящая логика: управление магнитным полем
- Квантовый взрыв: Разговор о голосах и перспективах
- Квантовые смеси: от капель жидкости до сверхтекучих кристаллов
- Волшебство по запросу: ИИ создает заклинания в игре
- Визуальный интеллект для эмбриона: Искусственный интеллект описывает развитие зародыша
- Квантовый скачок через SPAC: Анализ рынка и физика надежды
- Луна раскрывает свои секреты: Искусственный интеллект восстанавливает древнюю формулу
2025-12-01 06:14