Автор: Денис Аветисян
Исследователи предлагают инновационную архитектуру DualVLA, направленную на повышение надежности и обобщающей способности роботов, способных понимать язык и выполнять действия в реальном мире.
Предложен фреймворк DualVLA, использующий частичное разделение рассуждений и действий, а также новый показатель VLA Score для комплексной оценки эффективности.
Несмотря на успехи в создании моделей «Зрение-Язык-Действие» (VLA), объединение навыков рассуждения и манипулирования в единой системе часто приводит к ухудшению точности выполнения действий. В данной работе, ‘DualVLA: Building a Generalizable Embodied Agent via Partial Decoupling of Reasoning and Action’, предлагается новый подход, позволяющий смягчить эффект «деградации действий» за счет интеллектуальной фильтрации данных и адаптивной дистилляции знаний. Предложенная архитектура DualVLA демонстрирует улучшенную производительность в задачах манипулирования, сохраняя при этом способность к рассуждению и достигая высокой оценки по предложенному новому показателю VLA Score. Способны ли подобные методы приблизить нас к созданию действительно универсальных и надежных воплощенных агентов?
Раскрытие Потенциала Воплощенного Разума: Перспективы и Препятствия
Модели «Зрение-Язык-Действие» (VLA) представляют собой значительный шаг на пути к созданию универсального искусственного интеллекта. Эти системы, в отличие от традиционных подходов, способны не просто распознавать визуальную информацию и понимать язык, но и активно взаимодействовать с окружающим миром посредством действий. Объединяя в себе возможности восприятия, рассуждения и осуществления физических манипуляций, VLA модели стремятся воспроизвести когнитивные способности человека, позволяя им решать сложные задачи в реальном времени. Например, система может получить текстовую инструкцию, такую как “положи красный кубик на синий”, распознать соответствующие объекты на изображении и затем выполнить необходимое действие, используя роботизированную руку или виртуального агента. Такая интеграция различных когнитивных функций открывает перспективы для создания более гибких и адаптивных интеллектуальных систем, способных к самостоятельному обучению и решению проблем в разнообразных областях, от автоматизации производства до помощи людям в повседневной жизни.
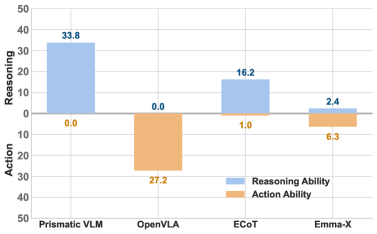
Исследования показали, что простое добавление возможностей рассуждения к моделям, объединяющим зрение, язык и действие (VLA), может неожиданно привести к ухудшению их производительности при выполнении базовых задач манипулирования объектами. Этот парадоксальный эффект, получивший название “Деградация Действий”, демонстрирует, что добавление когнитивных способностей не всегда автоматически улучшает функциональность робототехнических систем. Оказывается, неадекватно интегрированные процессы рассуждения могут приводить к неоптимальным стратегиям управления и, как следствие, к снижению точности и эффективности выполнения физических действий. Данное явление подчеркивает необходимость более тонкого подхода к разработке VLA, где рассуждения и действия должны быть тщательно согласованы и оптимизированы для достижения желаемых результатов.
Оценка Рассуждений VLA: Преодоление Ограничений Традиционных Метрик
Традиционные эталоны для оценки роботов зачастую не позволяют полноценно оценить сложность рассуждений, лежащих в основе поведения. Существующие метрики, как правило, фокусируются на конечном результате выполнения задачи, игнорируя процесс принятия решений и логическую последовательность действий. Это приводит к тому, что роботы, достигающие правильного ответа случайным образом или используя упрощенные стратегии, могут получать оценки, сопоставимые с роботами, демонстрирующими сложные когнитивные способности. В частности, стандартные тесты часто не учитывают способность робота адаптироваться к новым ситуациям, объяснять свои действия или выявлять и исправлять собственные ошибки, что является ключевым аспектом истинного рассуждения.
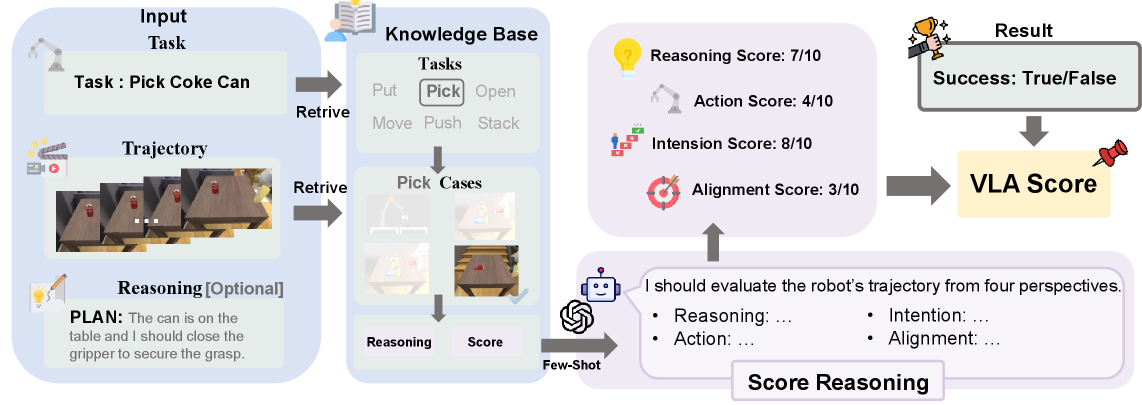
Мы представляем ‘VLA Score’ — систему оценки, использующую большие языковые модели (GPT-4o) в качестве экспертов для анализа поведения виртуальных агентов (VLA). В отличие от традиционных метрик, оценивающих только результат действий VLA, ‘VLA Score’ анализирует и обоснование принятых решений. Оценка производится на основе анализа текстовых объяснений, предоставляемых VLA, что позволяет выявить не только что агент делает, но и почему он это делает. Это обеспечивает более глубокое понимание способности VLA к логическому мышлению и планированию действий, а также позволяет выявлять потенциальные ошибки в процессе принятия решений.
Оценка VLA Score осуществляется в рамках бенчмарка ‘SimplerEnv’, который предоставляет контролируемую среду для изоляции компонентов рассуждения и действий. ‘SimplerEnv’ разработан таким образом, чтобы минимизировать влияние факторов, не связанных с логическим выводом, таких как сложность сенсорного ввода или кинематики робота. Это позволяет более точно оценить способность VLA к планированию и принятию решений, основываясь исключительно на качестве рассуждений, а не на эффективности выполнения действий в реальном окружении. Использование контролируемой среды упрощает анализ результатов и выявление слабых мест в логике VLA.

Разделение Рассуждений и Действий: Архитектура DualVLA
DualVLA представляет собой фреймворк пост-обучения, предназначенный для разделения процессов рассуждения и действия в визуально-языковых агентах (VLA). В отличие от традиционных подходов, где эти функции тесно переплетены, DualVLA позволяет независимо оптимизировать компоненты, отвечающие за логический анализ и физическое взаимодействие с окружающей средой. Данный подход направлен на повышение эффективности и гибкости VLA, позволяя им более точно выполнять задачи, требующие как когнитивных, так и моторных навыков, за счет раздельной обработки информации и адаптации стратегий.
DualVLA использует метод ‘Двойной фильтрации данных’ (Dual-Layer Data Pruning) для целенаправленного удаления избыточных сегментов рассуждений, сосредотачиваясь на информации, критически важной для действий и основанной на ‘Воплощенном Рассуждении’ (Embodied Reasoning). Этот процесс предполагает анализ и отсечение участков логической цепочки, не оказывающих прямого влияния на успешное выполнение манипуляций. Приоритет отдается сохранению данных, непосредственно связанных с сенсорными входными данными и моторными командами, обеспечивая тем самым более эффективное и целенаправленное обучение модели для задач, требующих взаимодействия с физическим окружением. В результате происходит снижение вычислительной нагрузки и повышение скорости обработки, без ущерба для ключевых навыков манипулирования.
Для обучения в рамках DualVLA используется методика адаптивной дистилляции с двумя учителями. Оригинальная VLA выступает в роли “учителя рассуждений”, передавая знания о логических цепочках. Параллельно используется “специализированная VLA” (“учитель действий”), обученная исключительно на задачах манипулирования объектами. Такой подход позволяет минимизировать искажение базовых навыков управления, сохраняя при этом способность к логическому выводу, благодаря совместному обучению с использованием знаний обоих учителей.

Оптимизация Процесса Обучения: KL-Дивергенция и Адаптивное Наблюдение
В основе метода Dual-Teacher Adaptive Distillation лежит использование расхождения Кульбака-Лейблера (KL-дивергенции) — метрики, позволяющей количественно оценить разницу между вероятностными распределениями, предсказанными учителем и учеником. Данное расхождение применяется для измерения несоответствия между предсказаниями учителя и ученика в отношении логических рассуждений и действий. Вычисляя $KL$-дивергенцию для обеих модальностей, система способна определить, в каких аспектах ученик отстает от учителя, и скорректировать процесс обучения. Это позволяет более эффективно передавать знания от учителя к ученику, улучшая общую производительность модели и обеспечивая сбалансированное развитие как способностей к рассуждениям, так и навыков выполнения действий.
В процессе обучения визуально-языковой модели (VLA) применяется механизм адаптивного взвешивания сигналов обучения, поступающих от двух «учителей»: одного, фокусирующегося на рассуждениях, и другого — на выполнении действий. Такой подход позволяет модели эффективно совершенствовать навыки выполнения задач, не теряя при этом способности к логическому мышлению и анализу. Адаптивное взвешивание позволяет динамически регулировать вклад каждого учителя в процесс обучения, обеспечивая баланс между точностью рассуждений и эффективностью действий. В результате модель учится не просто «думать», но и успешно применять свои знания на практике, что критически важно для решения сложных задач и взаимодействия с реальным миром. Данный метод обеспечивает более гибкое и эффективное обучение, позволяя модели достигать высоких показателей как в задачах, требующих логического анализа, так и в задачах, требующих точного выполнения действий.
Результаты экспериментов демонстрируют, что DualVLA достигает средней успешности в 61.0% на бенчмарке SimplerEnv, что на 8.0% превосходит базовую модель InstructVLA-G. Более того, разработанная система обходит лидирующие специализированные и модели, ориентированные на рассуждения, с отрывом в 5.0% и 3.9% соответственно. Значительный прогресс наблюдается и при решении задач в реальных условиях, где DualVLA показывает успешность в 60.0% случаев, заметно улучшая результат в 45%, достигнутый ранее.

К Генерализации Интеллекта: Перспективы Будущих Исследований
Исследования подчеркивают критическую важность тщательной оценки и целенаправленных корректировок при интеграции рассуждений в воплощенные агенты. Недостаточно просто добавить модуль логического вывода; необходимо пристально следить за тем, как эти рассуждения влияют на действия агента в реальном времени и в различных ситуациях. Полученные данные свидетельствуют о том, что без систематической оценки и своевременной коррекции, даже кажущиеся логичными рассуждения могут привести к деградации действий и снижению общей производительности агента. Поэтому, при разработке интеллектуальных систем, способных к взаимодействию с окружающим миром, необходимо уделять особое внимание не только созданию эффективных механизмов рассуждения, но и разработке методов оценки и коррекции их влияния на поведение агента, обеспечивая тем самым надежность и предсказуемость действий.
Перспективные исследования направлены на разработку более сложных методов разделения процессов рассуждения и действий, что позволит создавать агентов, способных к более гибкому и адаптивному поведению. В частности, предполагается, что использование графовых архитектур позволит эффективно представлять и обрабатывать знания о мире, а иерархическое обучение с подкреплением — структурировать сложные задачи на более простые подзадачи. Такой подход позволит агентам планировать свои действия на основе логического вывода, а не только на непосредственных ощущениях, что значительно повысит их способность к обобщению и решению новых задач в различных условиях. Разделение этих процессов является ключевым шагом к созданию действительно универсального интеллекта, способного к обучению и адаптации в реальном мире.
Преодоление проблемы деградации действий представляется ключевым шагом к реализации полного потенциала визуально-лингвистических агентов (VLAs). Исследования показывают, что со временем, даже при изначально успешном выполнении задач, агенты склонны к упрощению и ухудшению качества действий, что существенно ограничивает их адаптивность и обобщающую способность. Устранение этой тенденции требует разработки более устойчивых механизмов планирования и контроля, способных поддерживать сложность и разнообразие действий на протяжении длительного взаимодействия с окружающей средой. Решение данной задачи позволит создать интеллектуальные системы, способные эффективно функционировать в реальном мире, демонстрируя гибкость, надежность и способность к обучению на протяжении всего жизненного цикла, что, в конечном итоге, приблизит нас к созданию действительно обобщенного искусственного интеллекта.
Представленная работа демонстрирует стремление к математической чистоте в области воплощенного искусственного интеллекта. Авторы, подобно архитекторам, выстраивают систему, где разделение рассуждений и действий не является произвольным, а подчиняется строгой логике. Этот подход, направленный на смягчение деградации действий, перекликается с идеей о необходимости доказуемости алгоритмов, а не просто их работоспособности на тестовых примерах. Как отмечает Дэвид Марр: “Цель вычислительной теории — понять, как работает разум, моделируя его функциональную архитектуру.” В данном контексте, DualVLA стремится к созданию именно такой функциональной архитектуры, где рассуждения и действия гармонично взаимодействуют, обеспечивая надежную и обобщенную работу агента. Введение VLA Score позволяет оценить эту гармонию с точки зрения как рассуждений, так и манипуляций, подтверждая стремление к элегантности и точности в проектировании интеллектуальных систем.
Куда двигаться дальше?
Представленная работа, хотя и демонстрирует улучшение в области согласования рассуждений и действий у воплощенных агентов, не решает фундаментальной проблемы: истинная обобщающая способность алгоритма требует доказательства, а не просто улучшения метрик на ограниченном наборе данных. Введение VLA Score — шаг в правильном направлении, однако, оценка качества агента по принципу “работает здесь и сейчас” — лишь временное решение. Необходимо разработать метрики, устойчивые к изменениям в окружающей среде и задачах, метрики, отражающие глубину понимания, а не просто успешное выполнение команд.
Особенно остро стоит вопрос о разрыве между симуляцией и реальностью. Успешная работа в виртуальной среде не гарантирует аналогичный результат в физическом мире. В дальнейшем необходимо сосредоточиться на разработке алгоритмов, устойчивых к шумам, неточностям сенсоров и непредсказуемости реального окружения. Иными словами, необходимо стремиться к созданию агентов, которые не просто имитируют разум, а демонстрируют робастность и адаптивность, свойственные живым организмам.
В конечном итоге, задача не в создании более сложных моделей, а в разработке принципиально новых подходов к построению искусственного интеллекта. Алгоритм должен быть элегантным в своей простоте и доказуемо корректным, а не просто “рабочим”. Именно в этом, а не в увеличении количества параметров, кроется путь к созданию истинно разумных машин.
Оригинал статьи: https://arxiv.org/pdf/2511.22134.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Трансформация нейросетей: от плотных моделей к разреженным экспертам без обучения
- Биосети в руках ИИ: Автоматизация системной фармакологии
- Эхо чёрных дыр: как квантовая гравитация меняет гравитационные волны
- Сияние фотонов: новый уровень точности в предсказаниях столкновений частиц
- Сверхпроводящая логика: управление магнитным полем
- Квантовый взрыв: Разговор о голосах и перспективах
- Квантовые смеси: от капель жидкости до сверхтекучих кристаллов
- Волшебство по запросу: ИИ создает заклинания в игре
- Луна раскрывает свои секреты: Искусственный интеллект восстанавливает древнюю формулу
- Визуальный интеллект для эмбриона: Искусственный интеллект описывает развитие зародыша
2025-12-01 11:32