Автор: Денис Аветисян
Новый бенчмарк RefineBench позволяет комплексно оценить, насколько хорошо большие языковые модели могут улучшать собственные ответы, опираясь на четкие критерии.
Представлен RefineBench — фреймворк для оценки возможностей саморефлексии и направленного улучшения ответов языковых моделей в различных областях и задачах.
Несмотря на растущие возможности больших языковых моделей, их способность к самосовершенствованию и уточнению ответов на запросы остаётся недостаточно изученной. В данной работе представлена новая платформа ‘RefineBench: Evaluating Refinement Capability of Language Models via Checklists’ для всесторонней оценки возможностей языковых моделей в режиме саморефлексии и при получении направленных подсказок. Полученные результаты демонстрируют, что даже самые современные модели испытывают трудности с самостоятельным улучшением ответов, в то время как при наличии чёткой обратной связи способны достигать почти идеальных результатов за несколько итераций. Какие прорывы необходимы для создания языковых моделей, способных самостоятельно исправлять собственные ошибки и эффективно учиться на обратной связи?
Проблема Итеративного Улучшения в Языковых Моделях
Несмотря на значительный прогресс в области языковых моделей, обеспечение стабильного качества ответов в течение продолжительного диалога остается сложной задачей. Существующие модели часто демонстрируют снижение эффективности по мере увеличения числа реплик, что связано с трудностями в поддержании контекста и последовательности. Данная проблема особенно актуальна в сценариях, требующих долгосрочного планирования или запоминания деталей предыдущих реплик. Исследования показывают, что языковые модели склонны к «забыванию» информации, что приводит к противоречивым ответам или повторению одних и тех же утверждений. Улучшение способности моделей к последовательному рассуждению и сохранению контекста является ключевым направлением современных исследований, направленных на создание более реалистичных и полезных диалоговых систем.
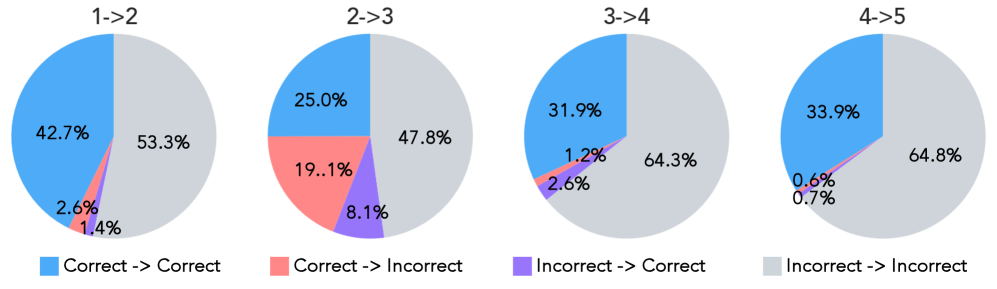
Существующие методы оценки качества языковых моделей зачастую не способны адекватно отразить тонкие улучшения, достигаемые в процессе итеративной доработки. Традиционные метрики, ориентированные на однократные ответы, не учитывают способность модели к самокоррекции и адаптации в ходе продолжительного диалога. Это приводит к недооценке прогресса, особенно в сценариях, где модель получает обратную связь и использует её для повышения своей производительности. Неспособность точно измерить эти нюансы затрудняет разработку и совершенствование алгоритмов самосовершенствования, поскольку не позволяет объективно оценить эффективность различных стратегий и подходов к итеративной доработке. В результате, оценивается лишь поверхностный результат, а важные улучшения в способности модели к обучению и адаптации остаются незамеченными.
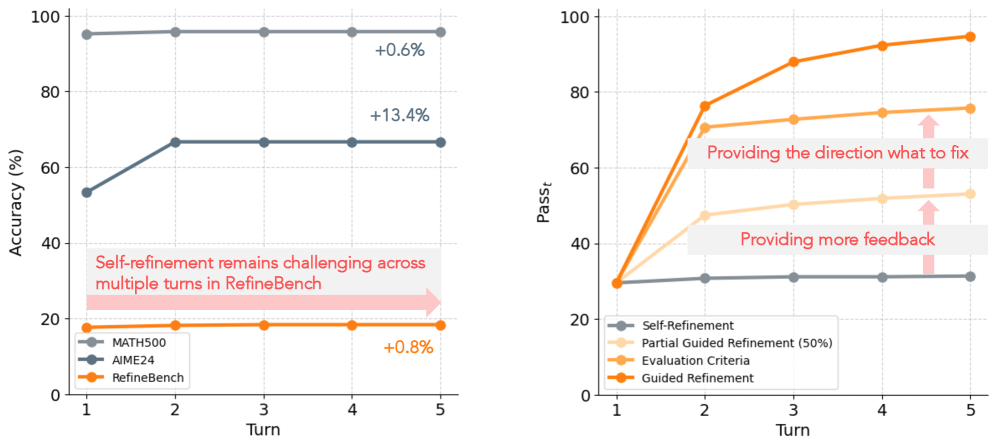
Для всесторонней оценки способности языковых моделей к адаптации и совершенствованию в ходе продолжительных диалогов необходим надежный эталонный набор данных. Существующие методы оценки часто не позволяют точно измерить прогресс, достигнутый за счет итеративного улучшения ответов. Исследования показывают, что даже самые передовые модели демонстрируют лишь около 32% успешных случаев самосовершенствования, что подчеркивает острую потребность в более строгих и комплексных критериях оценки. Разработка такого эталона позволит не только объективно измерить эффективность различных подходов к обучению, но и выявить ключевые ограничения текущих моделей, способствуя созданию более интеллектуальных и отзывчивых систем искусственного интеллекта.
RefineBench: Комплексный Фреймворк для Оценки
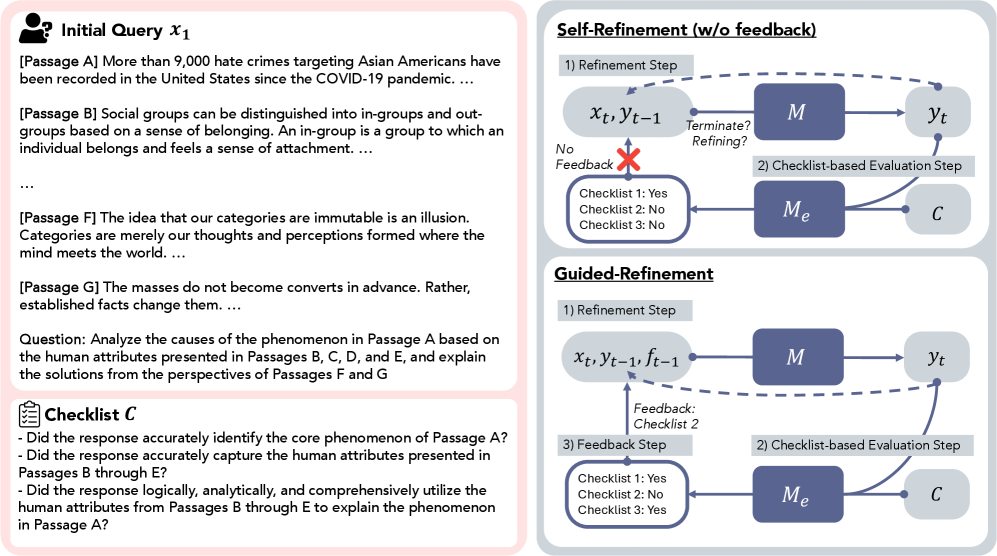
RefineBench использует методологию оценки на основе контрольных списков, обеспечивая детализированную оценку качества улучшения ответов по множеству параметров. Данный подход позволяет оценить не только общую корректность, но и конкретные аспекты, такие как устранение фактических ошибок, повышение логической последовательности, улучшение ясности и точности формулировок, а также соответствие ответа заданным требованиям. Каждый пункт контрольного списка представляет собой четко определенный критерий, позволяющий объективно оценить, было ли улучшение достигнуто в конкретной области. Такая гранулярность позволяет выявить сильные и слабые стороны различных моделей в процессе улучшения ответов и предоставляет ценную информацию для дальнейшей оптимизации.
RefineBench разработан для оценки двух основных стратегий улучшения ответов языковых моделей. Саморефлексия подразумевает автономную переработку ответов моделью без внешнего вмешательства. В то же время, управляемая рефлексия использует обратную связь от пользователя для последовательного улучшения ответа. Оценка проводится по обоим сценариям, что позволяет комплексно оценить способность модели к самокоррекции и адаптации к внешним указаниям, а также выявить сильные и слабые стороны каждой стратегии улучшения.
RefineBench применим к широкому спектру архитектур языковых моделей, включая модели с открытым исходным кодом и проприетарные решения. Особую актуальность данный бенчмарк представляет для моделей, ориентированных на рассуждения (reasoning) и моделей, обученных с использованием инструкций (instruction-tuned). Результаты показывают, что использование RefineBench для направленной (guided) доработки ответов может достигать производительности до 98.4%, что продемонстрировано на модели Claude-Opus-4.1. Это указывает на эффективность RefineBench в улучшении качества ответов за счет итеративного уточнения.
Механизмы Улучшения: Обратная Связь и Прекращение
Управляемое улучшение (guided refinement) предполагает наличие надежного механизма обратной связи, который передает информацию языковой модели для корректировки последующих итераций. Этот механизм может включать в себя предоставление модели оценок качества сгенерированного текста, указание на конкретные ошибки или неточности, а также предоставление примеров желаемого результата. Эффективность обратной связи напрямую влияет на скорость и качество улучшения модели, позволяя ей последовательно приближаться к заданным критериям производительности. Ключевым аспектом является не только предоставление информации об ошибках, но и указание направления для исправления, что позволяет модели более эффективно адаптироваться и оптимизировать свои выходные данные.
Самосовершенствование языковой модели требует разработки критериев завершения — условий, определяющих момент, когда дальнейшие итерации перестают быть полезными или даже приводят к ухудшению результатов. Отсутствие чёткого критерия может привести к бесконечному циклу пересмотра, потребляющему вычислительные ресурсы без значимого улучшения качества. Определение оптимального критерия завершения подразумевает баланс между стремлением к повышению точности и предотвращением переобучения или потери когерентности в процессе саморефлексии модели.
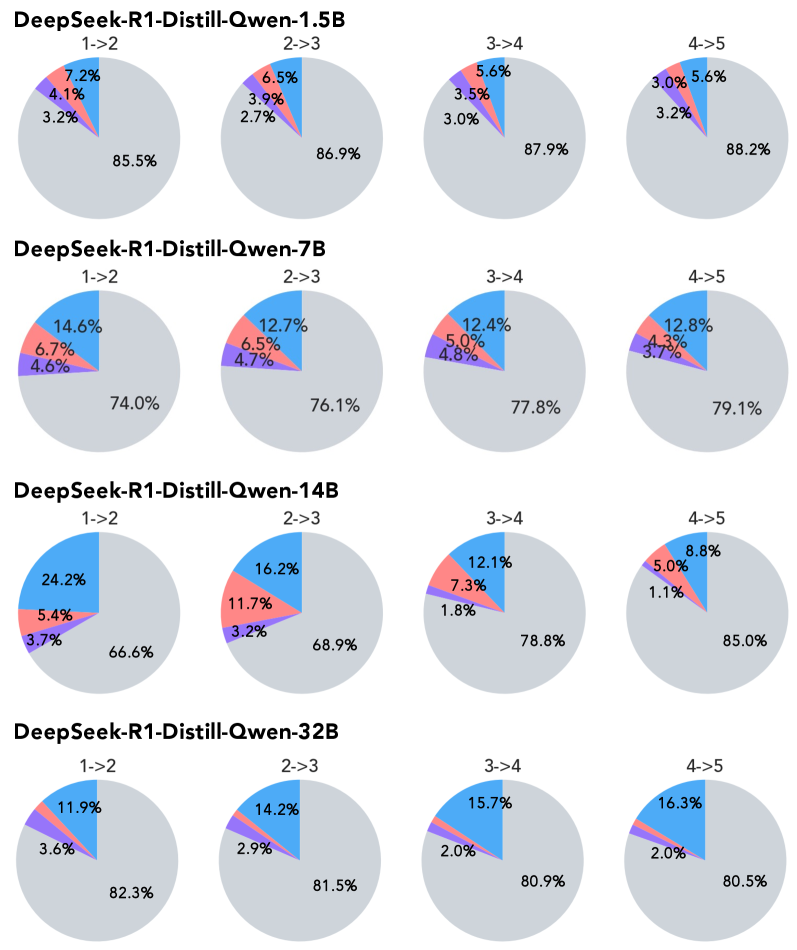
Анализ модели DeepSeek-R1 показал снижение количества токенов, используемых для рассуждений, на 69.7% между первым и вторым этапами самосовершенствования. Данный показатель указывает на потенциальное уменьшение глубины рассуждений в процессе саморефлексии модели. Уменьшение числа токенов, связанных с рассуждениями, может свидетельствовать о склонности модели к более лаконичным, но возможно и менее детализированным ответам на последующих итерациях.
Надёжность разработанной нами оценочной системы подтверждается высоким уровнем согласования с оценками, полученными от экспертной модели GPT-4.1, достигающим 90%. Это означает, что в 90% случаев оценки, выдаваемые нашей системой, совпадают с оценками, выставленными экспертной моделью, что свидетельствует о её валидности и способности адекватно оценивать качество генерируемого текста или решений. Высокий уровень согласования позволяет использовать данную систему для автоматизированной оценки, снижая потребность в дорогостоящих и трудоёмких ручных оценках.
Влияние на Интерактивный ИИ и Перспективы Развития
Разработанный RefineBench представляет собой стандартизированный подход к оценке возможностей языковых моделей в области уточнения и улучшения генерируемого текста. Этот инструмент позволяет исследователям объективно сравнивать различные модели, выявлять их сильные и слабые стороны в процессе итеративного совершенствования ответов. Благодаря унифицированной метрике и набору тестовых задач, RefineBench существенно ускоряет прогресс в области разработки искусственного интеллекта, позволяя более эффективно разрабатывать и оптимизировать языковые модели для решения сложных задач, требующих последовательного улучшения результатов и повышения точности.
Анализ процессов уточнения ответов языковыми моделями предоставляет ценные сведения для создания более эффективных и устойчивых систем диалогового искусственного интеллекта. Изучение того, как модели корректируют и улучшают свои первоначальные ответы, позволяет выявить ключевые факторы, влияющие на качество и связность беседы. Эти знания могут быть использованы для разработки алгоритмов, оптимизирующих процесс самокоррекции, что, в свою очередь, приведет к созданию более надежных и способных к поддержанию длительных и осмысленных диалогов систем. Понимание механизмов, лежащих в основе успешного уточнения, открывает путь к созданию искусственного интеллекта, способного не только генерировать текст, но и активно учиться на своих ошибках, приближая нас к созданию по-настоящему интеллектуальных собеседников.
Разработка языковых моделей, способных к содержательному и продолжительному диалогу с пользователем, всё ближе становится реальностью благодаря акценту на итеративном улучшении. Однако, текущие методы самосовершенствования демонстрируют ограниченную эффективность: процент успешных итераций не превышает 32%. Это указывает на необходимость дальнейших исследований в области алгоритмов саморефлексии и обучения с подкреплением, направленных на повышение способности моделей к самостоятельному выявлению и исправлению ошибок в процессе взаимодействия. Успешное преодоление этих сложностей позволит создавать системы искусственного интеллекта, которые не просто генерируют текст, а действительно понимают и адаптируются к потребностям собеседника, открывая новые горизонты в области интерактивного ИИ и за его пределами.
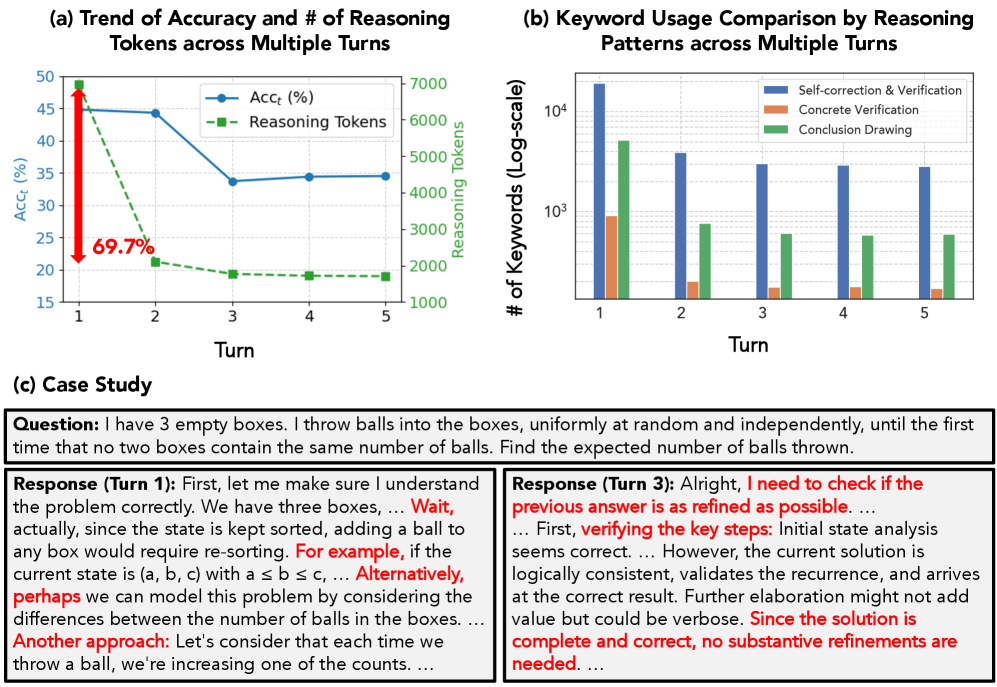
Представленный анализ RefineBench демонстрирует стремление к глубокому пониманию возможностей языковых моделей в процессе самосовершенствования и корректировки. Подобный подход к оценке, основанный на тщательно разработанных контрольных списках, позволяет выйти за рамки поверхностного анализа и выявить истинный потенциал систем искусственного интеллекта. Тим Бернерс-Ли однажды сказал: «Веб — это не просто набор документов, это система для организации знаний». Аналогично, RefineBench — это не просто набор тестов, а система для организации понимания возможностей языковых моделей, позволяющая взломать систему недостатков и уязвимостей, выявляя и устраняя пробелы в их способностях к саморефлексии и улучшению.
Куда же дальше?
Представленный RefineBench, как и любой тщательно сконструированный инструмент, скорее обнажает пропасти в понимании, чем заполняет их. Оценка способности языковых моделей к самосовершенствованию через контрольные списки — элегантный ход, несомненно. Но не превращается ли эта элегантность в самообман? Ведь сам процесс создания контрольного списка уже несет в себе субъективные предположения о том, что вообще значит «улучшение». И не сводится ли вся эта «рефлексия» модели к простому перебору вариантов, пока не сработает заранее заложенный критерий?
Очевидно, что необходимо переосмыслить саму концепцию «рефлексии» в контексте искусственного интеллекта. Достаточно ли оценивать лишь конечный результат? Или же следует пристальнее изучать процесс изменения, внутренние представления модели, её «мышление» (если, конечно, это уместный термин)? Ключевым вопросом остаётся: способность к «улучшению» — это лишь умение подстраиваться под заданные метрики, или же проявление подлинного понимания задачи и её контекста?
В конечном счёте, RefineBench — это лишь отправная точка. Следующим шагом должно стать создание более гибких, адаптивных и непредвзятых методов оценки, способных уловить не только что модель делает, но и почему она это делает. Иначе рискуем построить иллюзию интеллекта, основанную на тщательно отлаженных алгоритмах манипуляции данными.
Оригинал статьи: https://arxiv.org/pdf/2511.22173.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Биосети в руках ИИ: Автоматизация системной фармакологии
- Эхо чёрных дыр: как квантовая гравитация меняет гравитационные волны
- Трансформация нейросетей: от плотных моделей к разреженным экспертам без обучения
- Сияние фотонов: новый уровень точности в предсказаниях столкновений частиц
- Квантовый поиск гравитационных волн: новый алгоритм для повышения точности
- Квантовый скачок в многомасштабном моделировании
- Квантовый горизонт: взгляд изнутри
- Джозефсоновские переходы на квантовых материалах: новые горизонты сверхпроводимости
- Искусственный интеллект проектирует белки: новый горизонт биоинженерии
- Луна раскрывает свои секреты: Искусственный интеллект восстанавливает древнюю формулу
2025-12-01 13:26