Автор: Денис Аветисян
Новое исследование демонстрирует, что даже самые современные языковые модели испытывают серьезные трудности при обработке индийских языков с ограниченными ресурсами.
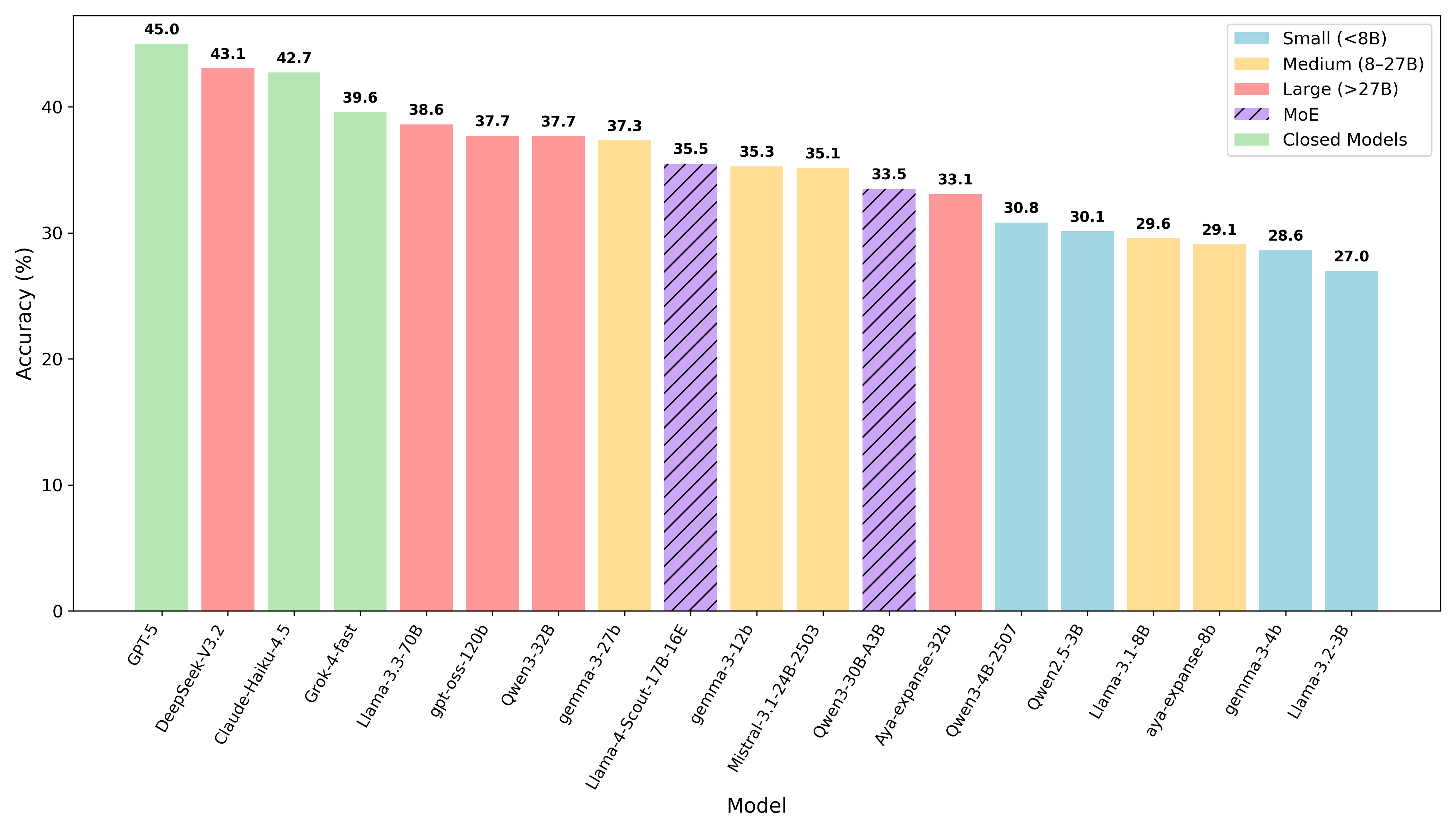
Представлен IndicParam — эталонный набор данных для оценки производительности больших языковых моделей на 11 малоресурсных индийских языках, выявляющий существенные недостатки существующих систем.
Несмотря на успехи больших языковых моделей в обработке распространенных языков, оценка их возможностей в отношении малоресурсных индийских языков остается серьезной проблемой. В данной работе представлена ‘IndicParam: Benchmark to evaluate LLMs on low-resource Indic Languages’ — тщательно разработанный набор данных, включающий более 13 000 вопросов на 11 индийских языках с различной степенью обеспеченности ресурсами. Анализ 19 современных моделей показал, что даже самые передовые из них демонстрируют среднюю точность лишь около 45%, что подчеркивает ограничения кросс-языкового переноса знаний. Какие новые подходы и ресурсы необходимы для повышения эффективности языковых моделей в работе с малоресурсными языками и обеспечения равного доступа к технологиям искусственного интеллекта?
Вызовы и горизонты низкоресурсных языков
Несмотря на значительный прогресс в области больших языковых моделей, их эффективность остается ограниченной для языков, испытывающих дефицит цифровых ресурсов. Это связано с тем, что обучение таких моделей требует огромных объемов текстовых данных, которые попросту недоступны для многих языков мира. В результате, модели часто демонстрируют низкую точность при обработке этих языков, испытывают трудности с пониманием нюансов и контекста, и не способны генерировать связные и грамматически верные тексты. Данное ограничение препятствует распространению преимуществ искусственного интеллекта на глобальном уровне и создает цифровой разрыв между языками, лишая носителей малоресурсных языков доступа к современным технологиям и информации.
Оценка возможностей больших языковых моделей (LLM) в различных языках является критически важной задачей, однако существующие бенчмарки и наборы данных зачастую сконцентрированы на языках с обилием цифровых ресурсов, таких как английский и китайский. Это создает значительный разрыв в понимании того, насколько эффективно LLM функционируют в условиях ограниченности данных, характерных для большинства языков мира. Недостаток всесторонней оценки в отношении низкоресурсных языков препятствует разработке действительно инклюзивных и глобально применимых систем искусственного интеллекта, поскольку производительность моделей в этих языках остается недостаточно изученной и часто значительно ниже, чем в языках с богатыми ресурсами. Исследователи отмечают, что эта проблема требует не только создания новых, более репрезентативных бенчмарков, но и разработки методов адаптации и обучения моделей, способных эффективно работать даже при ограниченном количестве доступных данных.
Отсутствие всесторонней оценки возможностей языковых моделей для малоресурсных языков серьезно препятствует созданию действительно инклюзивных и глобально применимых систем искусственного интеллекта. В то время как значительные инвестиции направлены на совершенствование моделей для доминирующих языков, таких как английский и китайский, языки, используемые меньшинствами или имеющие ограниченное цифровое представление, остаются в тени. Это приводит к тому, что алгоритмы могут демонстрировать предвзятость, неточность или полную неработоспособность при обработке информации на этих языках, что усугубляет цифровое неравенство и исключает целые сообщества из преимуществ, которые может предложить ИИ. Разработка и внедрение эффективных методов оценки, учитывающих лингвистическое разнообразие, является ключевым шагом на пути к созданию искусственного интеллекта, доступного и полезного для всех.
Языковое разнообразие представляет собой серьезную проблему для разработки эффективных методов оценки понимания языка и общих знаний. Недостаточно просто адаптировать существующие тесты, созданные для языков с богатыми ресурсами; необходимы принципиально новые подходы, учитывающие уникальные грамматические, синтаксические и семантические особенности каждого языка. Игнорирование этих нюансов приводит к искаженным результатам и препятствует созданию действительно всеобъемлющих и справедливых систем искусственного интеллекта. Разработка надежных метрик и бенчмарков, способных точно измерить языковые способности в различных лингвистических контекстах, является ключевой задачей для обеспечения равноправного доступа к технологиям обработки естественного языка для всех пользователей, независимо от их родного языка. Особое внимание следует уделять разработке методов, не требующих больших объемов размеченных данных, что особенно важно для малоресурсных языков.
Представляем IndicParam: эталон лингвистического разнообразия
IndicParam представляет собой оценочный набор данных, состоящий из более чем 13 000 вопросов с множественным выбором ответов, предназначенный для оценки производительности больших языковых моделей (LLM) в отношении 11 индийских языков. Набор данных охватывает широкий спектр лингвистических особенностей и предназначен для количественной оценки способности моделей понимать и обрабатывать языки, отличные от доминирующих в области обработки естественного языка. Каждый вопрос имеет четыре варианта ответа, что позволяет проводить автоматизированную оценку и сравнение различных LLM.
Бенчмарк IndicParam делает акцент на языках с низким и крайне низким уровнем ресурсов, что позволяет использовать его в качестве критически важной платформы для оценки способности языковых моделей обобщать знания. В отличие от большинства существующих бенчмарков, ориентированных на широко используемые языки, IndicParam специально разработан для оценки производительности моделей в условиях дефицита данных. Это особенно важно для выявления слабых мест в способности моделей к переносу знаний и адаптации к новым, недостаточно представленным языкам. Использование языков с ограниченными ресурсами позволяет более точно оценить истинный потенциал модели в реальных сценариях, где доступность данных ограничена, и обеспечить прогресс в разработке более универсальных и инклюзивных языковых моделей.
Для создания IndicParam в качестве источника вопросов был использован экзамен UGC-NET, что обеспечило релевантность и качество материала. UGC-NET, являясь общенациональным экзаменом для отбора кандидатов на преподавательские должности в индийских университетах, содержит вопросы, охватывающие широкий спектр дисциплин и уровней сложности. Использование вопросов UGC-NET позволило гарантировать, что IndicParam содержит проверенные и стандартизированные задания, отражающие академический уровень владения языком, а также обеспечить достаточную сложность для оценки возможностей больших языковых моделей (LLM) в обработке индийских языков.
Традиционные бенчмарки для оценки больших языковых моделей (LLM) часто фокусируются на доминирующих языках, таких как английский, что приводит к неполной оценке их возможностей в обработке лингвистического разнообразия. Подход, реализованный в IndicParam, обеспечивает более детальное понимание производительности LLM в отношении языков с ограниченными ресурсами, включая низко- и сверхнизкоресурсные индийские языки. Это позволяет выявить слабые места моделей в обработке менее распространенных языков и оценить их способность к обобщению знаний, полученных на доминирующих языках, на новые лингвистические контексты. Оценка по таким параметрам критически важна для разработки более инклюзивных и универсальных языковых моделей.
Оценка производительности LLM на IndicParam: свидетельства и ограничения
В рамках оценки производительности больших языковых моделей (LLM) был использован бенчмарк IndicParam. В процессе тестирования участвовали модели GPT-5, Claude-Haiku-4.5, DeepSeek-V3.2 и Llama-3.3-70B. IndicParam представляет собой набор задач, предназначенный для оценки способности моделей к решению разнообразных лингвистических и логических задач, характерных для индийских языков и культур. Использование данного бенчмарка позволило сравнить производительность различных LLM в специфической лингвистической среде и выявить их сильные и слабые стороны.
В ходе оценки на бенчмарке IndicParam модель GPT-5 показала наивысшую среднюю точность, составив 45.0%. Этот результат превзошел показатели всех остальных протестированных моделей, включая DeepSeek-V3.2 (43.1%), Claude-Haiku-4.5 (42.7%) и Llama-3.3-70B (39.6%). Таким образом, GPT-5 продемонстрировала лучшую способность к обобщению и решению задач, представленных в IndicParam, по сравнению с конкурентами.
Модель DeepSeek-V3.2, использующая архитектуру Mixture of Experts (MoE), показала среднюю точность в 43.1% при оценке на бенчмарке IndicParam. Данная архитектура предполагает использование нескольких «экспертных» моделей, специализирующихся на различных аспектах задачи, что позволяет достичь высокой производительности. Полученный результат демонстрирует конкурентоспособность DeepSeek-V3.2 по сравнению с другими моделями, участвовавшими в оценке, и подтверждает эффективность подхода MoE в задачах обработки естественного языка.
В ходе оценки на бенчмарке IndicParam модель Claude-Haiku-4.5 показала среднюю точность 42.7%. Модель Llama-3.3-70B, являющаяся моделью с открытым весом, достигла среднего показателя точности в 39.6%. Данные результаты демонстрируют разницу в производительности между этими двумя моделями, при этом Claude-Haiku-4.5 превосходит Llama-3.3-70B по точности на оцениваемом бенчмарке.
Оценка производительности моделей проводилась с использованием метода zero-shot prompting, что позволило оценить способность моделей к обобщению и решению задач без предварительной адаптации к конкретным данным. Результаты показали, что у лидирующих моделей наблюдается разрыв в 10-15 процентных пунктов между задачами, требующими общих знаний ($G$) и задачами, направленными на понимание языка ($L$), что указывает на различную степень эффективности в этих областях. Это свидетельствует о том, что модели лучше справляются с извлечением и применением фактологических знаний, чем с более сложным анализом и интерпретацией лингвистической информации.
Последствия и перспективы: к экосистеме инклюзивного ИИ
Исследования показали, что даже самые современные большие языковые модели испытывают значительные трудности при работе с языками, для которых существует ограниченное количество обучающих данных. Средняя точность моделей на наборе данных IndicParam не превысила 50%, что указывает на существенные пробелы в текущих методах переноса знаний между языками. Данный результат подчеркивает необходимость разработки более эффективных техник кросс-лингвального переноса, позволяющих адаптировать модели, обученные на богатых ресурсах, к языкам с ограниченными данными, и открывает перспективы для улучшения качества машинного перевода и обработки естественного языка в глобальном масштабе.
Разработка IndicParam представляет собой значимый шаг вперёд в области многоязычного искусственного интеллекта, предоставляя исследователям и разработчикам бесценный ресурс для оценки и совершенствования языковых моделей. Этот набор данных, тщательно собранный и аннотированный, охватывает широкий спектр индийских языков, ранее недостаточно представленных в стандартных бенчмарках. Доступность IndicParam позволяет проводить более точную оценку возможностей моделей в обработке низкоресурсных языков, выявлять слабые места и разрабатывать более эффективные методы переноса знаний. Он способствует созданию инклюзивных технологий, способных понимать и генерировать текст на различных языках, расширяя доступ к информации и возможностям для миллионов людей по всему миру.
Исследование показало, что предварительное обучение больших языковых моделей на разнообразных корпусах текстов, в частности, таких как FineWeb2, способно значительно повысить их эффективность при работе с языками, для которых существует ограниченное количество обучающих данных. Данный подход позволяет модели усваивать более общие лингвистические закономерности и лучше адаптироваться к новым языковым контекстам, даже при недостатке специализированных ресурсов. Использование разнообразных данных для предварительного обучения способствует формированию более устойчивых и обобщенных языковых представлений, что, в свою очередь, положительно сказывается на производительности модели при решении задач в условиях дефицита данных для целевого языка.
Перспективные исследования должны быть направлены на разработку более эффективных и экономичных методов адаптации больших языковых моделей (LLM) к новым языкам и лингвистическим контекстам. Существующие подходы часто требуют значительных вычислительных ресурсов и больших объемов данных, что ограничивает их применимость к языкам с ограниченными ресурсами. Необходимо исследовать стратегии, позволяющие LLM быстрее и точнее усваивать грамматические особенности, семантические нюансы и культурные особенности новых языков, возможно, за счет использования методов мета-обучения, трансферного обучения с небольшим количеством примеров или разработки специализированных архитектур моделей, оптимизированных для кросс-лингвистической адаптации. Успех в этой области не только расширит возможности применения LLM в различных сферах, но и поможет сохранить и популяризировать языковое разнообразие во всем мире.
Исследование, представленное в данной работе, демонстрирует, что даже самые современные языковые модели испытывают трудности при работе с малоресурсными индийскими языками. Это подтверждает идею о том, что системы — это не конструкции, а организмы, требующие постоянной адаптации и развития. Как однажды заметил Андрей Колмогоров: «Математика — это искусство открывать закономерности в хаосе». Подобно этому, создание надежных инструментов для работы с языками требует не жесткого контроля, а умения видеть и использовать скрытые закономерности и связи в данных, особенно когда ресурсов для обучения крайне мало. В контексте IndicParam, это означает, что акцент должен быть сделан на методах, позволяющих моделям учиться на небольшом количестве данных и эффективно переносить знания между языками.
Что Дальше?
Представленный анализ, демонстрируя слабость современных языковых моделей перед лицом действительно малоресурсных индийских языков, лишь подтверждает старую истину: разделение системы на микросервисы, или в данном случае, расширение её охвата на новые языки, не устраняет фундаментальную хрупкость. Модель может отвечать на вопросы на английском, но её уверенность — иллюзия, когда речь заходит о языках, где данные — редкий ресурс. Мы видим не улучшение понимания, а лишь перераспределение незнания.
Попытки улучшить производительность через трансфер обучения — это временная отсрочка неизбежного. Система, зависящая от богатства одного языка, обречена на уязвимость, когда лишается этой поддержки. Всё связанное когда-нибудь упадёт синхронно, и каждое добавление нового языка — это добавление новой точки отказа. Необходимо осознать, что задача не в создании более универсальной модели, а в признании её принципиальной ограниченности.
Будущие исследования, вероятно, сосредоточатся на создании искусственных данных или новых архитектур. Но истинный прогресс потребует переосмысления самой концепции «понимания». Язык — это не просто набор символов, а часть культуры, истории, мировоззрения. И никакая модель не сможет воссоздать это без глубокого понимания контекста, которое, по сути, недостижимо. Всё стремится к зависимости, и языковые модели — не исключение.
Оригинал статьи: https://arxiv.org/pdf/2512.00333.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Когда мнения расходятся: как модели принимают решения при конфликте данных
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Шёпот языков: как дрессировать цифрового голема для забытых наречий.
- Взгляд в будущее: как теория динамических систем преобразит анализ временных рядов
- Внимание к квантовой теории поля: нейросети и трансформеры
- Искусственный интеллект на службе науки: самообучающиеся агенты для новых открытий
- Искусственный интеллект в роли астрофизика: эксперимент с задачами
- Трансформеры: От Прогнозирования к Пониманию Причинности
- Оптимизация больших языковых моделей: новый подход к снижению требований к ресурсам
- Кто несет ответственность за ИИ: новый взгляд на причинно-следственные связи
2025-12-02 09:31