Автор: Денис Аветисян
Исследователи предложили инновационный метод, позволяющий значительно ускорить обработку длинных текстов большими языковыми моделями, не жертвуя точностью.
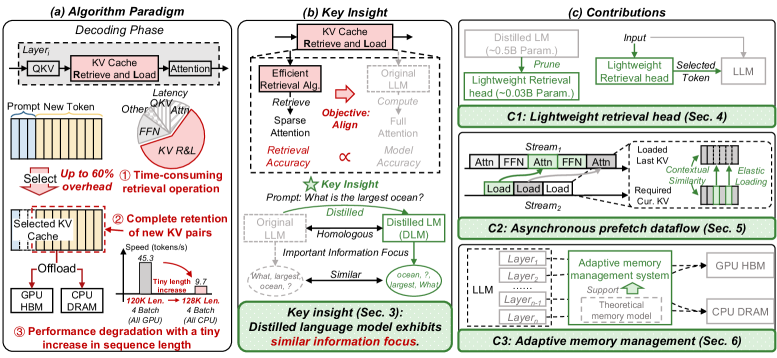
SpeContext использует дистиллированную языковую модель для оптимизации кэша KV, обеспечивая повышение скорости и пропускной способности при работе с длинным контекстом.
Несмотря на впечатляющие возможности больших языковых моделей (LLM), обработка длинных контекстов остается ресурсоемкой задачей. В данной работе, представленной под названием ‘SpeContext: Enabling Efficient Long-context Reasoning with Speculative Context Sparsity in LLMs’, предлагается новый подход к эффективному выводу LLM, основанный на использовании дистиллированной языковой модели для интеллектуального выбора данных KV-кэша. Предложенная система SpeContext обеспечивает значительное увеличение пропускной способности и скорости обработки за счет совместной оптимизации алгоритмов, системы и компиляции. Сможет ли данный подход расширить границы применимости LLM в сценариях, требующих обработки больших объемов информации?
Вызов длинного контекста: границы традиционных больших языковых моделей
Современные большие языковые модели (БЯМ) стали краеугольным камнем в области обработки естественного языка, демонстрируя впечатляющие возможности в различных задачах — от генерации текста до перевода и анализа данных. Однако, несмотря на значительный прогресс, эти модели сталкиваются с серьезными ограничениями при работе с длинными последовательностями входных данных. Способность эффективно обрабатывать и запоминать информацию из объемных текстов существенно снижается, что приводит к ухудшению качества ответов и снижению точности при решении сложных задач, требующих учета контекста. Проблема заключается не в неспособности модели понимать язык как таковой, а в экспоненциальном росте вычислительных затрат и требований к памяти при увеличении длины входной последовательности, что ограничивает возможности применения БЯМ в сценариях, где критически важна обработка больших объемов информации.
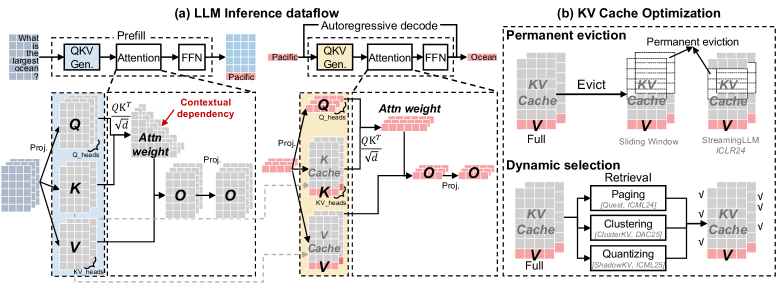
Основным препятствием для обработки длинных последовательностей в больших языковых моделях (LLM) является механизм внимания и связанный с ним кэш “ключ-значение” (KV-кэш). Принцип работы механизма внимания требует вычисления взаимосвязей между всеми токенами во входной последовательности, что приводит к квадратичному росту вычислительных затрат и объема памяти с увеличением длины последовательности. В частности, для последовательности длиной $n$, объем памяти, необходимый для KV-кэша, пропорционален $n^2$, что делает обработку очень длинных текстов крайне ресурсоемкой и ограничивает возможности LLM в задачах, требующих анализа больших объемов информации, таких как суммирование длинных документов или ответы на вопросы по объемным текстам. Эта квадратичная зависимость становится критическим узким местом, препятствующим дальнейшему масштабированию LLM и расширению спектра решаемых ими задач.
Масштабируемость механизма внимания, являющегося основой современных больших языковых моделей, представляет собой серьезную проблему при работе с длинными последовательностями текста. По мере увеличения длины входных данных, потребность в вычислительных ресурсах и памяти для хранения и обработки матрицы внимания возрастает квадратично, что существенно ограничивает возможности моделей в задачах, требующих анализа и синтеза информации из обширных контекстов. Это оказывает негативное влияние на производительность в сложных приложениях, таких как обобщение длинных документов, ответы на вопросы, требующие глубокого понимания контекста, и построение связных нарративов, поскольку модели испытывают трудности с удержанием и обработкой всей релевантной информации из длинных последовательностей, что приводит к снижению точности и когерентности результатов.
SpeContext: Спекулятивная разреженность для эффективных рассуждений
SpeContext представляет собой алгоритм и совместную разработку системы, направленные на снижение вычислительных затрат за счет использования спекулятивной разреженности контекста. В основе подхода лежит предварительное определение и приоритизация наиболее релевантных токенов входной последовательности. Это позволяет минимизировать объем обрабатываемой информации, снижая нагрузку на большую языковую модель (LLM) и, как следствие, уменьшая требуемые вычислительные ресурсы. Алгоритм предполагает, что не все части входного контекста одинаково важны для принятия решения, и за счет спекулятивного исключения менее значимых токенов достигается повышение эффективности обработки данных.
В основе SpeContext лежит алгоритм, позволяющий выборочно обрабатывать токены входной последовательности. Вместо последовательной обработки всех токенов, система идентифицирует и ранжирует их по степени релевантности для решаемой задачи. Приоритет отдается наиболее информативным токенам, что позволяет значительно сократить объем вычислений, необходимых для обработки контекста. Такой подход уменьшает вычислительную нагрузку на большую языковую модель (LLM) за счет исключения из рассмотрения менее значимых частей входной последовательности, что приводит к повышению эффективности и снижению задержек.
Подход SpeContext снижает вычислительную нагрузку на большую языковую модель (LLM) за счет избирательной обработки наиболее информативных токенов входной последовательности. Вместо обработки всего контекста, система динамически определяет и приоритизирует фрагменты, которые оказывают наибольшее влияние на процесс рассуждения. Это позволяет LLM концентрироваться на релевантной информации, снижая потребность в вычислительных ресурсах и повышая эффективность обработки длинных последовательностей. В результате, уменьшается задержка и потребление энергии, что особенно важно для приложений, требующих обработки в реальном времени и развертывания на устройствах с ограниченными ресурсами.
Оптимизированный поток данных и управление памятью для масштабируемости
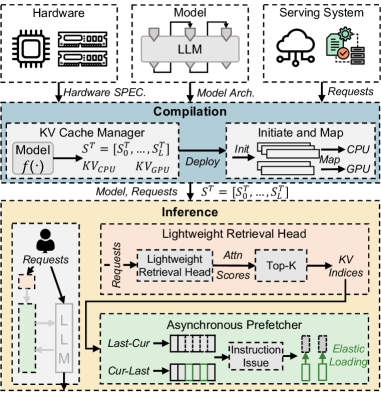
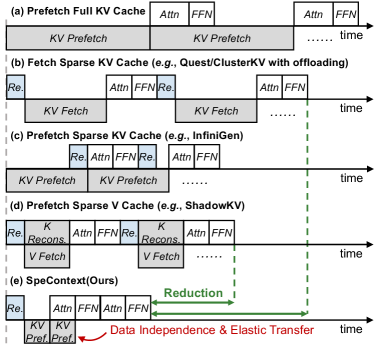
В системе реализован асинхронный поток предварительной выборки данных (Asynchronous Prefetch Dataflow), позволяющий одновременно выполнять вычисления и предварительную загрузку данных из кэша “ключ-значение” (KV cache). Этот подход обеспечивает перекрытие операций ввода-вывода и вычислений, что существенно повышает пропускную способность системы. Вместо последовательного выполнения этих задач, асинхронный поток позволяет начать загрузку данных для последующих вычислений, пока текущие вычисления все еще выполняются, минимизируя время простоя GPU и увеличивая общую эффективность обработки данных. Это особенно важно для больших моделей и массивов данных, где время доступа к памяти может стать узким местом.
Эластичная загрузка (Elastic Loading) оптимизирует процесс загрузки данных в кэш ключ-значение (KV cache) путем повторного использования ранее загруженных данных. Вместо полной перезагрузки KV cache при каждом запросе, система определяет и загружает только те порции данных, которые были изменены или обновлены. Этот подход значительно снижает объем передаваемых данных, уменьшает задержки и повышает общую пропускную способность системы, особенно при работе с большими объемами данных и частыми обновлениями. Эффективность эластичной загрузки напрямую зависит от точности определения измененных порций данных и оптимизации механизма обновления кэша.
Адаптивное управление памятью динамически регулирует выделение ресурсов памяти GPU в процессе работы модели. Эта система отслеживает текущую загрузку памяти и потребность в ресурсах, автоматически перераспределяя память между различными компонентами модели и слоями. Это позволяет избежать ситуаций, когда один компонент занимает избыточные ресурсы, приводя к неэффективному использованию GPU и возникновению узких мест. В частности, система может освобождать память, занятую временными данными или неактивными слоями, и перенаправлять ее на вычисления, требующие больше ресурсов. Такой подход позволяет поддерживать высокую утилизацию GPU, минимизировать задержки и максимизировать пропускную способность при обработке больших объемов данных.
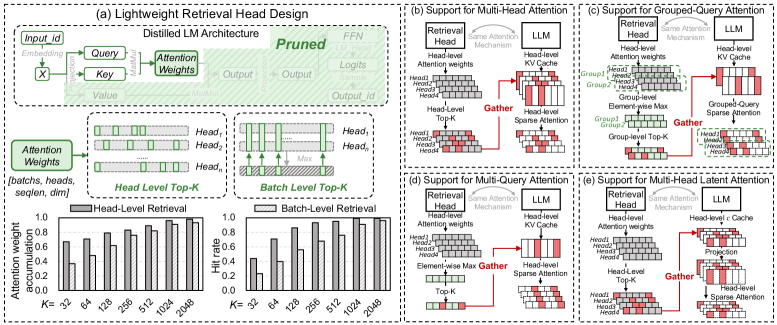
Легкий поиск и дистиллированные модели: интеллектуальный отбор
Для повышения эффективности работы больших языковых моделей (LLM) используется облегченная система извлечения информации, построенная на основе дистиллированной языковой модели. Данная система предшествует процессу инференса LLM и выполняет отбор наиболее значимых токенов из входного текста. Дистилляция позволяет создать компактную модель, сохраняющую ключевые способности исходной LLM, что обеспечивает высокую скорость работы системы извлечения. Отбираемые токены затем передаются в LLM для дальнейшей обработки, что позволяет снизить вычислительные затраты и повысить скорость генерации ответа за счет фокусировки внимания модели на релевантной информации.
Процесс отбора важных токенов основывается на принципах теории информации, в частности на понятиях взаимной информации ($I(X;Y)$) и неравенства обработки данных (Data Processing Inequality). Взаимная информация определяет количество информации об одной переменной, содержащееся в другой, и используется для оценки релевантности токенов. Неравенство обработки данных гласит, что обработка переменной не может увеличить количество информации о другой переменной, что позволяет гарантировать, что отбор токенов не приводит к потере критически важной информации, необходимой для последующей работы языковой модели. Данные принципы позволяют эффективно определить наиболее информативные токены, минимизируя шум и максимизируя производительность.
Метод интеллектуального отбора токенов, основанный на дистилляции языковой модели, значительно повышает эффективность и производительность больших языковых моделей (LLM). Сосредоточение внимания LLM исключительно на наиболее релевантной информации позволяет сократить объем вычислений, необходимых для обработки входных данных. Это приводит к уменьшению задержки при выводе и снижению требований к вычислительным ресурсам, сохраняя или даже улучшая точность результатов. В частности, снижение количества токенов, подаваемых на вход LLM, напрямую влияет на $O(n)$ сложность процесса инференса, где $n$ — количество токенов.
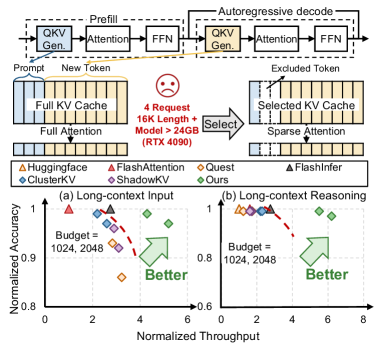
Оценка и результаты: подтверждение подхода
Исследование демонстрирует, что SpeContext, в сочетании с оптимизированным потоком данных и выбором токенов, обеспечивает существенный прирост производительности на эталонных наборах данных LongBench и LongWriter. Данная комбинация позволила добиться значительного ускорения обработки длинных последовательностей, что особенно важно для задач, требующих глубокого контекстного анализа. Улучшения не ограничиваются теоретическими показателями; система эффективно справляется с обработкой больших объемов информации, открывая новые возможности для применения больших языковых моделей в сценариях, где скорость и эффективность имеют решающее значение. Полученные результаты подтверждают, что оптимизация как архитектуры, так и процесса обработки данных является ключевым фактором для раскрытия полного потенциала современных языковых моделей при работе с длинным контекстом.
Система продемонстрировала впечатляющий прирост производительности, достигнув 24.89-кратного увеличения пропускной способности в облачных средах и 10.06-кратного ускорения в граничных вычислениях. Важно отметить, что столь значительное увеличение скорости обработки не сопровождается снижением точности — наблюдаемые потери являются пренебрежимо малыми по сравнению с базовыми моделями. Данные результаты подтверждают эффективность предложенного подхода и открывают новые возможности для реализации больших языковых моделей в задачах, требующих обработки длинных контекстов, без ущерба для качества генерируемых ответов.
Полученные результаты демонстрируют значительный потенциал предложенного подхода к раскрытию полного спектра возможностей больших языковых моделей (LLM) в задачах, требующих обработки длинного контекста. Возможность существенно ускорить обработку информации, не жертвуя при этом точностью, открывает новые горизонты для применения LLM в сложных сценариях, таких как анализ объемных документов, многоэтапное решение задач и глубокое понимание сложных взаимосвязей. Это не просто увеличение производительности, а принципиальное расширение границ возможного для LLM, позволяющее им эффективно работать с информацией, ранее недоступной из-за вычислительных ограничений. Такое улучшение открывает путь к созданию более интеллектуальных и эффективных систем, способных решать задачи, требующие глубокого понимания и анализа больших объемов данных.
В представленной работе наблюдается стремление к элегантности и эффективности в обработке длинных контекстов, что перекликается с философией Джона фон Неймана. Он говорил: «В науке нет места для предположений, только для доказательств». SpeContext, предлагая алгоритмическую, системную и компиляционную оптимизацию KV-кэша, демонстрирует аналогичный подход — избавление от избыточности и концентрацию на необходимом. Уменьшение вычислительной нагрузки при сохранении точности — это и есть компрессия без потерь, воплощенная в архитектуре обработки данных. Работа подчеркивает, что истинное совершенство достигается не за счет добавления сложности, а за счет ее сокращения, что соответствует принципам лаконичности и ясности.
Что дальше?
Предложенный подход, как и большинство нововведений, лишь отодвигает проблему, а не решает её. Они назвали это «разрежением», чтобы скрыть панику перед экспоненциальным ростом требований к памяти. Искусственное сужение контекста, даже при помощи дистиллированной модели, — это всё равно упрощение сложного мира. Вместо того, чтобы усердно оптимизировать хранение уже обработанной информации, следует задуматься о принципиально иных архитектурах, способных к более эффективному извлечению релевантных знаний из потока данных.
Настоящая сложность заключается не в скорости вычислений, а в понимании. Очевидно, что увеличение размера контекстного окна само по себе не гарантирует появление разума. Более перспективным представляется поиск способов интеграции символьных и нейронных подходов, позволяющих модели не только «видеть» больше, но и «понимать» смысл увиденного. Это потребует отказа от упрощенных представлений о «внимании» и разработки более тонких механизмов рассуждений.
В конечном итоге, вся эта гонка за параметрами и скоростью напоминает строительство огромного, но хрупкого замка из песка. Простота — признак зрелости. Следующий шаг — не усложнять, а отсекать лишнее, выявляя фундаментальные принципы, лежащие в основе интеллекта. Тогда и оптимизации, и алгоритмы обретут истинный смысл.
Оригинал статьи: https://arxiv.org/pdf/2512.00722.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Укрощение Бесконечности: Алгебраические Инструменты для Кватернионов и За их Пределами
- Сияние фотонов: новый уровень точности в предсказаниях столкновений частиц
- Эхо чёрных дыр: как квантовая гравитация меняет гравитационные волны
- Квантовая Физика и Безопасность: Анализ Последних Новостей
- Биосети в руках ИИ: Автоматизация системной фармакологии
- Трансформация нейросетей: от плотных моделей к разреженным экспертам без обучения
- Квантовые вычисления на службе беспроводной связи
- Квантовый Беспорядок и Порядок: Размышления о Современной Физике
- Укрощение шума: как оптимизировать квантовые алгоритмы
- Интеллектуальное моделирование: от телеметрии к точным уравнениям
2025-12-03 00:36