Автор: Денис Аветисян
Новый подход к обработке видеоданных позволяет значительно повысить скорость и эффективность работы моделей искусственного интеллекта, анализирующих видео в режиме онлайн.
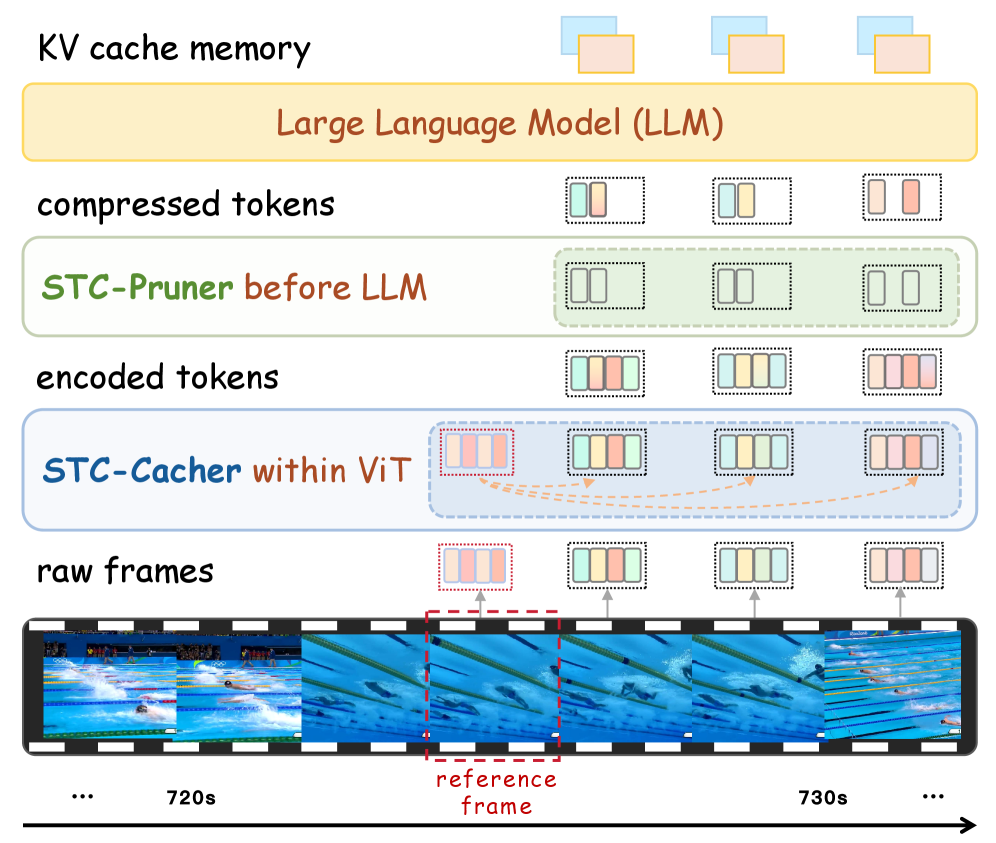
Предложена схема иерархического сжатия токенов (Streaming Token Compression) для оптимизации кодирования видео и работы языковых моделей, использующих временную избыточность.
Несмотря на впечатляющий прогресс в области анализа видео, современные большие языковые модели для видео (VideoLLM) сталкиваются со значительными вычислительными трудностями при обработке непрерывных потоков данных в реальном времени. В статье ‘Accelerating Streaming Video Large Language Models via Hierarchical Token Compression’ предложен инновационный подход — Streaming Token Compression (STC), иерархический фреймворк, оптимизирующий как этап кодирования видео (ViT), так и предварительное заполнение языковой модели. STC, за счет эффективного использования временной избыточности и каузальной компрессии, позволяет значительно снизить задержку и потребление памяти без существенной потери точности. Сможет ли предложенный метод стать ключевым фактором в развертывании VideoLLM для широкого спектра практических задач, требующих обработки видео в реальном времени?
Понимание Видеопотока в Реальном Времени: Вызов для Современных Алгоритмов
Понимание потокового видео в режиме реального времени (Streaming Video Understanding, SVU) представляет собой сложную задачу, обусловленную необходимостью минимальной задержки обработки. В отличие от анализа предварительно записанных видео, SVU требует немедленной интерпретации каждого кадра, что становится критическим препятствием для ресурсоемких ВидеоLLM. Высокая вычислительная сложность этих моделей, способных к пониманию видеоконтента, напрямую влияет на скорость обработки потока, и даже небольшие задержки могут сделать систему непригодной для интерактивных приложений, таких как видеоконференции или автоматизированное вождение. Поэтому, разработка эффективных методов снижения задержки является ключевым направлением исследований в области SVU, чтобы обеспечить возможность оперативной интерпретации видеоданных и своевременного реагирования на происходящие события.
Обработка видеопотоков в режиме реального времени представляет собой серьезную проблему для существующих методов анализа видео. Огромный объем данных, генерируемый каждым кадром, требует значительных вычислительных ресурсов и времени для обработки. Традиционные подходы, основанные на последовательном анализе каждого фрейма, быстро становятся неэффективными, приводя к неприемлемым задержкам в обработке. Это особенно заметно при анализе видео высокого разрешения или с высокой частотой кадров, где объем данных экспоненциально возрастает. В результате, попытки применить традиционные алгоритмы к потоковому видео часто приводят к существенному отставанию от реального времени, делая их непригодными для приложений, требующих мгновенной реакции, таких как автономное вождение или интерактивные системы наблюдения.
Существенная вычислительная нагрузка является ключевой проблемой в задачах понимания видео в реальном времени. Каждый кадр видеопотока требует обработки не только визуальной информации, но и преобразования этой информации в последовательность токенов — числовых представлений, необходимых для анализа моделями искусственного интеллекта. Этот процесс, включающий в себя извлечение признаков, кодирование и декодирование, требует значительных ресурсов центрального или графического процессора. Увеличение разрешения видео, частоты кадров или сложности анализируемого контента экспоненциально увеличивает объем необходимых вычислений, что приводит к задержкам и делает невозможным применение современных видео-LLM для задач, требующих мгновенной реакции, таких как автономное вождение или интерактивные трансляции. Таким образом, оптимизация вычислительной эффективности обработки каждого кадра и его токенов является критически важной для развития технологий понимания видео в реальном времени.

Временная Осознанность: Ключ к Эффективности Кодирования Видео
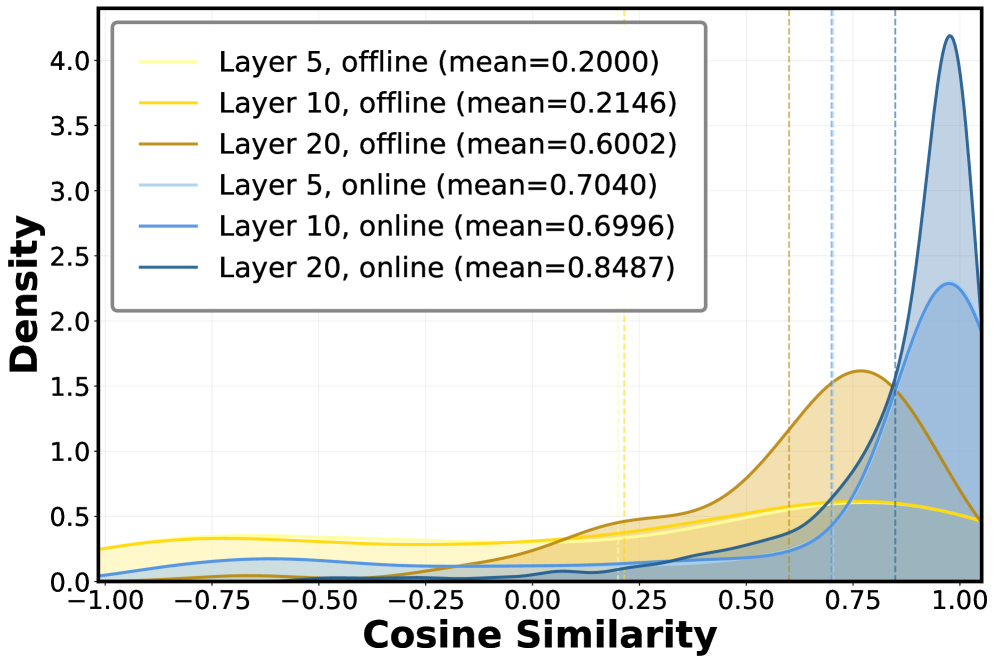
В процессе кодирования видео с использованием архитектуры ViT (Vision Transformer) наблюдается значительная временная избыточность между соседними кадрами. Это связано с тем, что многие визуальные признаки, извлекаемые из последовательных кадров, оказываются идентичными или очень похожими. В результате, повторное вычисление этих признаков для каждого кадра приводит к неэффективному использованию вычислительных ресурсов. Избыточность возникает из-за высокой корреляции между кадрами в видеопоследовательности, что означает, что значительная часть вычислений, выполняемых для одного кадра, может быть потенциально перенесена или повторно использована для следующих кадров, вместо того чтобы выполняться заново.
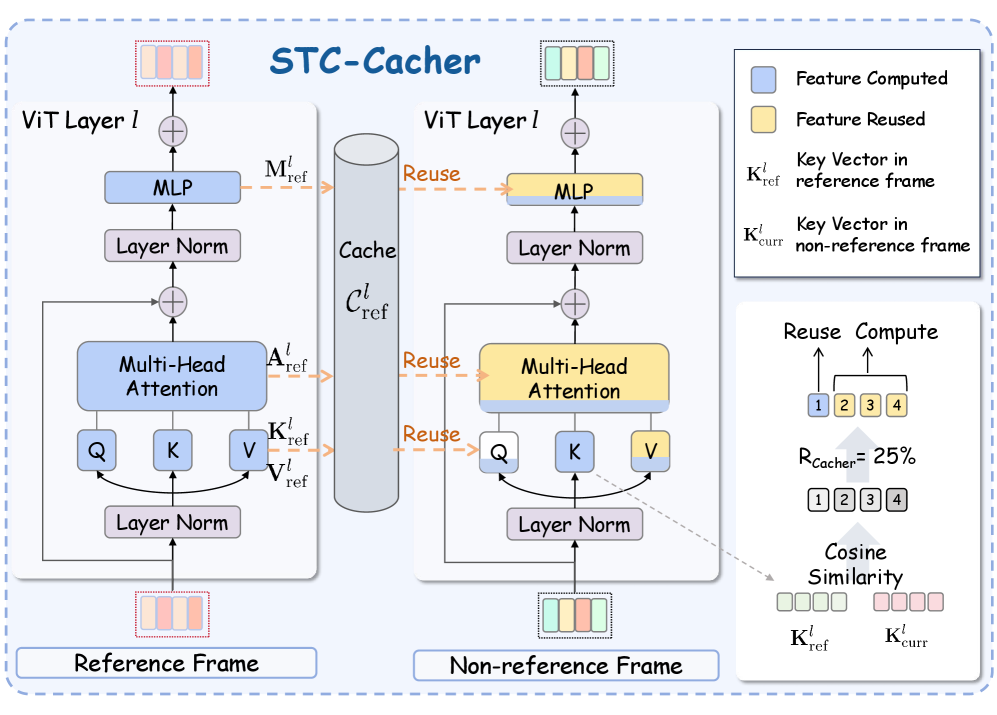
STC-Cacher использует временную избыточность между соседними кадрами для оптимизации процесса кодирования ViT. Вместо повторного вычисления признаков для каждого кадра, система идентифицирует и повторно использует ранее вычисленные и сохраненные признаки из кэша. Это достигается путем анализа схожести признаков между текущим и предыдущими кадрами, что позволяет значительно сократить количество прямых проходов (forward passes) через модель и, следовательно, снизить вычислительные затраты и время обработки видеопотока. Эффективное управление кэшем позволяет избежать избыточных вычислений и повысить общую производительность системы.
Реализация достигается посредством выборочных вычислений с учетом кэша (Cache-Aware Selective Computation), где повторные вычисления избегаются за счет использования ранее сохраненных признаков. Определение уникальности кадров производится на основе оценки схожести пространственных признаков (Spatial Feature Similarity). Этот метод предполагает сравнение текущего кадра с ранее обработанными кадрами по их пространственным характеристикам. Если схожесть превышает заданный порог, используются сохраненные признаки из кэша, минуя повторный проход через ViT-энкодер. В противном случае, кадр обрабатывается стандартно, а его признаки сохраняются в кэше для последующего использования.

Оптимизация Потока Токенов: Компрессия и Эффективность
Методы, такие как Streaming Token Compression (STC) и ToMe, направлены на снижение вычислительных затрат за счет уменьшения количества обрабатываемых токенов. STC выполняет совместную оптимизацию кодирования ViT и предварительной загрузки LLM, что позволяет сократить задержку предварительной загрузки LLM. ToMe, в свою очередь, использует технику разреженного представления токенов, отбрасывая наименее значимые токены без существенной потери точности. Оба подхода позволяют повысить эффективность обработки последовательностей токенов, что особенно важно при работе с большими языковыми моделями и ограниченными вычислительными ресурсами.
Технология Streaming Token Compression (STC) позволяет снизить задержку префилла (предварительной загрузки) больших языковых моделей (LLM) за счет совместной оптимизации кодирования ViT и процесса префилла. Согласно результатам тестирования на ReKV, STC обеспечивает уменьшение задержки префилла на 45.3%, при этом сохраняя 99% точности. Это достигается за счет минимизации объема данных, передаваемых между этапами кодирования изображения и обработки языковой моделью, что повышает общую эффективность и скорость обработки запросов.
VidCom2 представляет собой подключаемый фреймворк для ускорения инференса, использующий Flash Attention для оптимизации обработки токенов. Данная архитектура позволяет значительно снизить вычислительные затраты и задержки, связанные с обработкой последовательностей токенов, за счет эффективной реализации механизма внимания. Flash Attention минимизирует операции чтения/записи в память, что особенно важно при работе с большими моделями и длинными последовательностями. Фреймворк VidCom2 спроектирован таким образом, чтобы легко интегрироваться с существующими пайплайнами инференса, не требуя существенных изменений в коде или архитектуре модели.

Реальная Валидация и Онлайн-Производительность: От Теории к Практике
Методы ReKV и StreamForest продемонстрировали выдающиеся результаты на эталонных наборах данных StreamingBench и OVO-Bench, подтверждая их способность эффективно обрабатывать потоковое видео в реальном времени. Данные модели, ориентированные на обработку данных по мере поступления, успешно справляются с задачами анализа видеопотока без необходимости полной загрузки и обработки всего файла. Это особенно важно для приложений, требующих мгновенного реагирования, таких как системы видеонаблюдения, автоматическое обнаружение событий или интерактивные видеосервисы. Высокая производительность ReKV и StreamForest на этих эталонных наборах данных указывает на их потенциал для широкого спектра приложений, связанных с анализом и пониманием видеоконтента в режиме реального времени.
Предложенная архитектура демонстрирует значительное увеличение производительности — в 1.6 раза — при обработке данных на стандартных бенчмарках OVO-Bench и StreamingBench, по сравнению с моделью VidCom2. Данный прирост обусловлен оптимизацией ключевых компонентов и эффективной обработкой последовательностей видеоданных. Улучшение производительности позволяет осуществлять более быструю и эффективную обработку видеопотоков в реальном времени, открывая новые возможности для задач, требующих оперативного анализа, таких как ответы на вопросы по видеоконтенту и понимание длинных видеофрагментов. Повышенная скорость обработки делает систему особенно привлекательной для приложений, где важна минимальная задержка и максимальная пропускная способность.
Разработанные сквозные онлайн-модели открывают новые возможности для анализа видеопотоков в режиме реального времени. Благодаря им становится возможным не только оперативное ответы на вопросы о содержании видео — например, определение происходящих событий или идентификация объектов — но и понимание более сложных и продолжительных видеофрагментов. Это позволяет системам не просто фиксировать отдельные моменты, но и выстраивать целостную картину происходящего, что особенно важно для задач вроде мониторинга, анализа поведения или создания автоматизированных видео-резюме. Такой подход значительно расширяет сферу применения компьютерного зрения, позволяя создавать интеллектуальные системы, способные эффективно работать с видеоданными в динамичной среде.
Будущее Интеллектуального Понимания Видео: Горизонты и Перспективы
Для дальнейшего развития систем анализа потокового видео (SVU) и их применения в более сложных задачах, ключевым направлением является постоянное совершенствование методов компрессии токенов и стратегий кэширования. Эффективная компрессия позволяет уменьшить объем данных, необходимых для обработки видеопотока, что снижает вычислительную нагрузку и задержки. Одновременно, интеллектуальное кэширование позволяет сохранять наиболее часто используемые данные в быстродоступной памяти, избегая повторных вычислений и обеспечивая плавную работу системы даже при высокой нагрузке. Развитие этих технологий позволит SVU эффективно функционировать в задачах, требующих обработки видео в реальном времени, таких как автономное вождение, робототехника и интерактивные мультимедийные приложения, открывая путь к более интеллектуальным и отзывчивым системам искусственного интеллекта.
Предложенная платформа продемонстрировала значительное повышение эффективности кодирования видео, достигающее 5.6-кратного увеличения по сравнению с ToMe на трех ключевых бенчмарках: OVO-Bench, StreamingBench и EgoSchema. Этот прогресс обусловлен оптимизацией архитектуры ViT (Vision Transformer), позволяющей существенно снизить вычислительные затраты и требования к памяти при обработке видеопотоков. Улучшенная эффективность кодирования не только ускоряет анализ видео в реальном времени, но и открывает возможности для развертывания передовых алгоритмов искусственного интеллекта на устройствах с ограниченными ресурсами, таких как мобильные телефоны и встраиваемые системы. Полученные результаты свидетельствуют о значительном шаге вперед в области интеллектуальной обработки видео и закладывают основу для создания более эффективных и масштабируемых систем видеоаналитики.
Схождение этих усовершенствований предвещает будущее, в котором понимание видео в реальном времени станет бесшовным и повсеместным, открывая новые возможности для приложений на основе искусственного интеллекта. Представьте себе системы, способные мгновенно анализировать видеопоток, адаптируясь к изменяющимся условиям и предоставляя актуальную информацию. Такая возможность позволит создавать интеллектуальные системы безопасности, автономные транспортные средства с улучшенным восприятием окружающей среды, а также персонализированные развлекательные платформы, способные предвосхищать предпочтения пользователя. Подобные технологии найдут применение в медицине для удаленного мониторинга пациентов, в образовании для интерактивного обучения, и во множестве других сфер, радикально меняя способы взаимодействия человека с цифровым миром и открывая принципиально новые горизонты для развития искусственного интеллекта.
В представленной работе отчетливо прослеживается стремление к элегантности в обработке потокового видео. Авторы, подобно опытным архитекторам, не просто строят систему, а тщательно оптимизируют каждый её компонент, используя принципы иерархического сжатия токенов. Этот подход, направленный на снижение избыточности и повышение эффективности, особенно заметен в использовании каузального сжатия, позволяющего обрабатывать видеопоток в реальном времени без потери информации. Как однажды заметил Эндрю Ын: «Мы должны стремиться к тому, чтобы алгоритмы были не только мощными, но и изящными». Действительно, представленное решение демонстрирует, что красота масштабируется, беспорядок — нет, и что глубокое понимание принципов обработки данных позволяет создавать системы, отличающиеся не только функциональностью, но и гармонией.
Куда же дальше?
Представленная работа, подобно хорошо настроенному инструменту, открывает новые возможности для понимания потокового видео. Однако, даже самый изящный механизм не избавляет от необходимости дальнейшей шлифовки. В текущей реализации, акцент на временной избыточности, безусловно, эффективен, но вопрос о том, насколько универсальна эта стратегия для видеоконтента различной природы, остаётся открытым. Словно мелодия, написанная для одного инструмента, она может потребовать транспонирования для другого.
Будущие исследования, вероятно, будут сосредоточены на адаптивном сжатии, где степень компрессии динамически изменяется в зависимости от сложности сцены и критичности информации. Интерфейс «поёт» не тогда, когда он молчит, а когда каждый элемент гармонирует, даже в условиях меняющейся нагрузки. Важно также исследовать возможности интеграции STC с другими методами сжатия, чтобы добиться ещё большей эффективности. Любая деталь важна, даже если её не замечают — особенно в потоке данных.
И, наконец, не стоит забывать о вопросе масштабируемости. Прекрасно, когда система демонстрирует впечатляющие результаты на ограниченном наборе данных, но истинное искусство заключается в её способности справляться с непрерывным, непредсказуемым потоком информации. Элегантность — не опция; это признак глубокого понимания и гармонии между формой и функцией.
Оригинал статьи: https://arxiv.org/pdf/2512.00891.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Укрощение Бесконечности: Алгебраические Инструменты для Кватернионов и За их Пределами
- Сияние фотонов: новый уровень точности в предсказаниях столкновений частиц
- Эхо чёрных дыр: как квантовая гравитация меняет гравитационные волны
- Квантовая Физика и Безопасность: Анализ Последних Новостей
- Трансформация нейросетей: от плотных моделей к разреженным экспертам без обучения
- Биосети в руках ИИ: Автоматизация системной фармакологии
- Квантовые вычисления на службе беспроводной связи
- Квантовый Беспорядок и Наша Готовность к Нему
- Оживляя движение: новый подход к генерации траекторий
- Оптические Тензорные Ядра: Путь к Масштабируемым Вычислениям
2025-12-03 04:00