Автор: Денис Аветисян
Новый бенчмарк RULER-Bench позволяет оценить способность современных видеогенераторов к рассуждениям и соблюдению когнитивных правил в различных ситуациях.
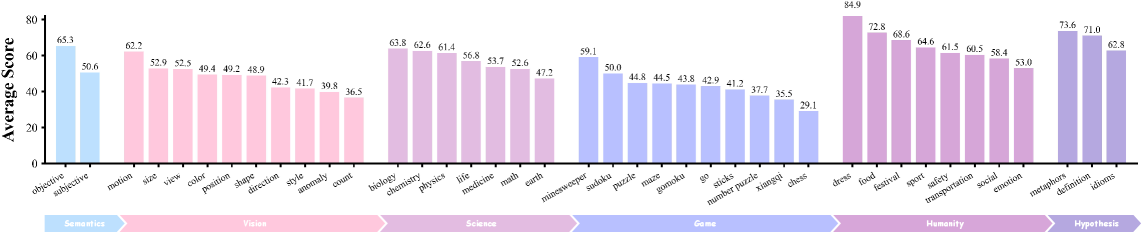
Представлен комплексный тест RULER-Bench для оценки способности моделей создавать видео, соответствующее заданным логическим условиям и правилам.
Несмотря на значительный прогресс в генерации видео, современные модели часто демонстрируют слабость в соблюдении базовых когнитивных правил. В данной работе представлена новая методика оценки, RULER-Bench: Probing Rule-based Reasoning Abilities of Next-level Video Generation Models for Vision Foundation Intelligence, предназначенная для всестороннего анализа способности моделей генерации видео к логическому мышлению и следованию заданным правилам. Разработанный бенчмарк, включающий 622 размеченных сценария, выявил, что даже передовые модели достигают лишь 48.87% по метрике согласованности с правилами, указывая на существенный потенциал для улучшения. Какие шаги необходимы для создания моделей генерации видео, способных не только реалистично отображать мир, но и разумно его моделировать?
Вызов логического мышления в генерации видео
Современные модели генерации видео демонстрируют впечатляющую визуальную точность, однако часто испытывают трудности с последовательным, основанным на правилах рассуждением. Несмотря на способность создавать реалистичные изображения, эти модели нередко допускают логические несостыковки и нарушения физических законов в генерируемых видеороликах. Например, объекты могут появляться и исчезать без причины, игнорироваться гравитация или нарушаться причинно-следственные связи. Это связано с тем, что модели фокусируются на статистическом воспроизведении визуальных паттернов, а не на понимании фундаментальных принципов, управляющих реальным миром. В результате, даже при высокой детализации изображения, отсутствие логической связности подрывает правдоподобие и ограничивает возможности практического применения этих технологий в задачах, требующих надежного и предсказуемого поведения виртуальных сцен.
Современные модели генерации видео, демонстрирующие впечатляющую визуальную достоверность, зачастую не способны к последовательному логическому мышлению. Простого воспроизведения внешнего вида недостаточно; для создания убедительных и правдоподобных сцен необходимо, чтобы модель понимала фундаментальные законы физики, общепринятые социальные нормы и логические связи между объектами и событиями. Например, модель должна учитывать, что вода не может течь вверх по склону, или что люди, как правило, не проходят сквозь стены. Отсутствие подобного понимания приводит к визуальным несоответствиям и неправдоподобным ситуациям, подрывая доверие к генерируемому контенту и ограничивая его практическое применение в задачах, требующих интеллектуального анализа и прогнозирования.
Отсутствие логического мышления в моделях генерации видео приводит к заметным визуальным несоответствиям и неправдоподобным ситуациям, что серьезно ограничивает их применимость и способность создавать действительно убедительный контент. Например, объекты могут появляться и исчезать без видимой причины, физические законы нарушаться, а поведение персонажей противоречить общепринятым нормам. Это не просто эстетические дефекты — они подрывают доверие зрителя и делают сгенерированные видео непригодными для задач, требующих точности и реалистичности, таких как обучение, симуляция или создание виртуальных миров. Поэтому, развитие способности к логическому выводу является ключевой задачей для достижения подлинного прогресса в области генерации видео.

RULER-Bench: Комплексная оценка логических способностей
RULER-Bench представляет собой всесторонний оценочный фреймворк для проверки способности моделей генерировать видео, основанные на логических правилах. Он включает в себя 40 различных задач и 622 конкретных примера, позволяющих комплексно оценить понимание и применение правил в процессе генерации видео. Разнообразие задач обеспечивает проверку моделей в различных сценариях и с разными типами правил, что позволяет получить более полную картину их возможностей в области логического мышления и генерации видеоконтента.
RULER-Bench оценивает модели генерации видео по категориям правил, охватывающим различные области знаний. Категория «Science» (Физика) проверяет понимание базовых физических принципов и их применение в видео. «Humanity» (Поведение человека) оценивает способность модели генерировать реалистичные и правдоподобные взаимодействия между людьми. Категория «Game» (Игровая логика) проверяет понимание правил и стратегий в игровых сценариях, а «Hypothesis» (Гипотетическое рассуждение) оценивает способность модели визуализировать результаты гипотетических ситуаций и «что если» сценариев. Такая классификация позволяет провести всестороннюю оценку возможностей модели в области логического мышления и генерации видео, соответствующего заданным правилам.
В RULER-Bench для оценки рассуждений используются как парадигмы «Текст в видео» (Text-to-Video, T2V), так и «Изображение в видео» (Image-to-Video, I2V). Это позволяет оценить способность моделей к логическим выводам, исходя из различных типов входных данных. Парадигма T2V предполагает генерацию видео на основе текстового описания, требующего понимания языка и установления соответствия между текстом и визуальными элементами. Парадигма I2V, напротив, оценивает способность модели экстраполировать и логически завершать визуальную последовательность, основываясь на начальном изображении, что требует анализа визуальной информации и предсказания последующих кадров. Использование обеих парадигм обеспечивает более полную и объективную оценку возможностей модели в области логического мышления и генерации видео.

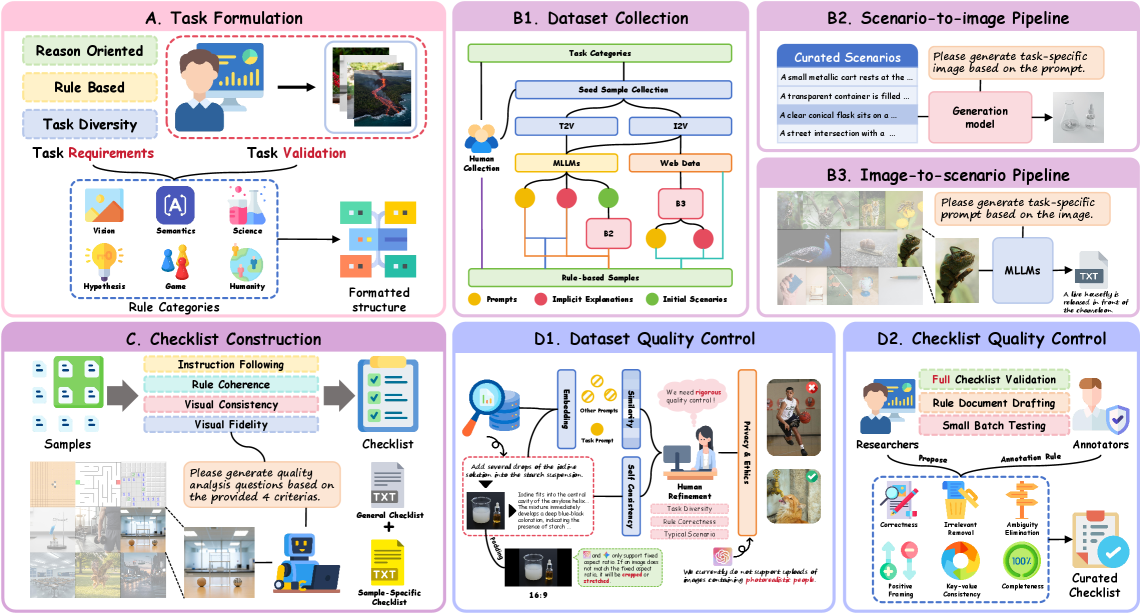
Автоматизированная оценка с использованием контрольного списка и MLLM
Протокол контрольного списка (Checklist Protocol) представляет собой систематизированный метод оценки сгенерированных видеороликов, основанный на наборе заранее определенных правил и критериев. Данный подход позволяет проводить структурированную оценку соответствия видео заданным требованиям, охватывая различные аспекты, такие как соблюдение логической последовательности, соответствие визуального контента инструкциям и общая связность повествования. В отличие от субъективных оценок, протокол обеспечивает объективную и воспроизводимую оценку, позволяя выявить слабые места в процессе генерации видео и оценить эффективность различных моделей. Каждое правило в контрольном списке проверяется на соответствие в сгенерированном видео, что в совокупности формирует общую оценку соответствия.
Протокол оценки использует большую мультимодальную модель (MLLM) o3 для автоматизации процесса анализа сгенерированных видео. Это позволяет снизить субъективность, связанную с ручной оценкой, и обеспечить возможность проведения анализа в больших масштабах. Автоматизация, основанная на o3, обеспечивает последовательное применение критериев оценки ко всем видео, исключая влияние человеческого фактора и повышая надежность результатов. В частности, MLLM анализирует видео, сопоставляя его содержание с заданными правилами и критериями, формируя количественную оценку, что позволяет проводить статистический анализ и сравнивать производительность различных моделей генерации видео.
Согласно результатам автоматизированной оценки с использованием Checklist Protocol, современные модели демонстрируют средний балл 48.87 по метрике «Согласованность с правилами» (Rule Coherence). Этот показатель указывает на существующие ограничения в способности моделей к логическому мышлению и последовательному соблюдению заданных инструкций на протяжении всего генерируемого видео. Низкий результат подчеркивает, что, несмотря на прогресс в других областях, таких как следование инструкциям и визуальная консистентность, обеспечение полного соответствия с заданными правилами остается сложной задачей для современных мультимодальных больших языковых моделей (MLLM).
Модель Veo3.1 демонстрирует высокие результаты в областях следования инструкциям (68.7 баллов), визуальной согласованности (80 баллов) и визуальной достоверности (80 баллов). Несмотря на это, показатель согласованности с правилами (Rule Coherence) остается относительно низким, что указывает на ограниченные возможности модели в области логического вывода и соблюдения заданных ограничений при генерации видеоконтента. Данные результаты подчеркивают необходимость дальнейших исследований и разработок, направленных на улучшение способности моделей к последовательному и корректному выполнению сложных инструкций и правил.
Анализ результатов автоматизированной оценки видео, сгенерированных моделями, показывает существенные трудности в категории «Игры». Средний балл по метрике «Согласованность с правилами» (Rule Coherence) для данной категории составляет менее 15, что значительно ниже, чем для других категорий контента. Это указывает на то, что существующие модели испытывают сложности с соблюдением сложных правил и логических связей, необходимых для корректной генерации видео, имитирующих игровые сценарии. Данный результат подчеркивает необходимость дальнейших исследований и разработок в области улучшения способности моделей к рассуждениям и соблюдению заданных ограничений при генерации видеоконтента.
Перспективы для будущих систем генерации видео
RULER-Bench демонстрирует, что современным моделям генерации видео недостаточно просто создавать визуально правдоподобные сцены. Бенчмарк подчеркивает необходимость перехода к моделям, способным к глубокому пониманию физических законов и здравого смысла. Создание реалистичной картинки — лишь поверхностный уровень; истинная ценность заключается в способности модели логически связывать события, предсказывать последствия действий и обеспечивать последовательность происходящего в видео. Это требует от разработчиков не просто улучшения графики, а разработки принципиально новых архитектур и методов обучения, ориентированных на моделирование причинно-следственных связей и осмысленное представление мира, что открывает путь к созданию видео, которые не просто выглядят правдоподобно, но и понимают то, что изображают.
RULER-Bench подталкивает к разработке новых архитектур и методов обучения для генерации видео, которые делают акцент не только на визуальной правдоподобности, но и на глубине рассуждений и последовательности событий. Исследования в этой области направлены на создание моделей, способных не просто воспроизводить картинку, но и понимать взаимосвязи между объектами и действиями в видеоряде. Особое внимание уделяется построению внутренних представлений о мире, позволяющих модели предсказывать развитие событий и избегать логических противоречий. Подобный подход открывает возможности для создания видео, которые не просто выглядят реалистично, но и демонстрируют осмысленное поведение, что является ключевым для широкого спектра приложений — от образовательных симуляций до систем помощи людям.
Устранение пробелов в логическом мышлении, выявленных в процессе разработки систем генерации видео, открывает широкие перспективы для инноваций в ключевых областях. В образовании это позволит создавать интерактивные обучающие сценарии, достоверно имитирующие реальные ситуации и способствующие глубокому усвоению материала. В сфере моделирования и симуляций, более правдоподобные видеоролики, основанные на логической последовательности событий, повысят точность и надежность прогнозов и анализа. Особую значимость это имеет в ассистивных технологиях, где достоверное и понятное визуальное представление информации необходимо для помощи людям с ограниченными возможностями, например, для обучения безопасным действиям или ориентации в пространстве. Разработка систем, способных к логическому мышлению при генерации видео, является ключевым шагом к созданию более полезных и эффективных технологий для широкого спектра применений.
Исследование, представленное в статье, акцентирует внимание на необходимости оценки способности моделей генерации видео следовать когнитивным правилам. Это требует от систем не просто воспроизведения визуальных данных, но и понимания логических связей между ними. Как однажды заметил Эндрю Ын: «Мы находимся в моменте, когда машинное обучение станет более доступным, и все будут использовать его». RULER-Bench, предложенный в данной работе, служит инструментом для проверки этой способности, выявляя, насколько хорошо модели способны к логическим умозаключениям и предсказаниям, основанным на заданных правилах. Особенно важно, что данный бенчмарк позволяет оценить не только успешность генерации, но и её соответствие заданной логике, что является ключевым шагом на пути к созданию действительно интеллектуальных систем.
Куда двигаться дальше?
Представленный бенчмарк RULER-Bench, несомненно, выявляет пробелы в способности современных генеративных моделей к видео не просто воспроизводить визуальные паттерны, но и оперировать с ними, подчиняясь заданным когнитивным правилам. Однако, стоит признать, что само понятие “разумности” в контексте машинного обучения остается расплывчатым. Проверка соответствия заранее определенным правилам — это лишь один из аспектов, и возможно, искусственно упрощенный. Следующим этапом представляется создание задач, требующих не просто следования инструкциям, а адаптации к меняющимся условиям и неполной информации — то есть, проявления подобия импровизации.
Очевидным ограничением является зависимость от предопределенных правил. Настоящая проверка интеллекта должна заключаться в способности модели самостоятельно выводить правила из примеров, то есть, демонстрировать индуктивное мышление. Разработка подобных бенчмарков требует не только усложнения задач, но и создания метрик, способных оценить не только точность, но и креативность генерируемых видео. Простое соответствие правилу — это механическое выполнение, а вот генерация нового, но логически обоснованного поведения — уже шаг к более глубокому пониманию.
В конечном итоге, оценка способности к рассуждениям в генеративных моделях — это не столько технологическая, сколько философская задача. Необходимо осознать, что имитация интеллекта не равно его проявлению, и что критерии оценки должны быть сформулированы с учетом этой фундаментальной разницы. Следует помнить, что визуальные данные — лишь один из способов познания мира, и для достижения настоящего “видения” необходимо объединить его с другими модальностями и формами представления знаний.
Оригинал статьи: https://arxiv.org/pdf/2512.02622.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Когда мнения расходятся: как модели принимают решения при конфликте данных
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Взгляд в будущее: как теория динамических систем преобразит анализ временных рядов
- Шёпот языков: как дрессировать цифрового голема для забытых наречий.
- Наука больших команд и широких горизонтов
- Поиск ускользающих тау-лептонов: новые алгоритмы для CMS
- Кто несет ответственность за ИИ: новый взгляд на причинно-следственные связи
- Белки-хамелеоны: Пределы предсказания гибкости структуры
- Внимание к квантовой теории поля: нейросети и трансформеры
- Сеть, управляемая интеллектом: новые возможности для экспериментов
2025-12-03 20:49