Автор: Денис Аветисян
Исследователи предлагают инновационный подход к обучению агентов, способных ориентироваться в пространстве, используя визуальные подсказки и оптимизацию стратегии действий.
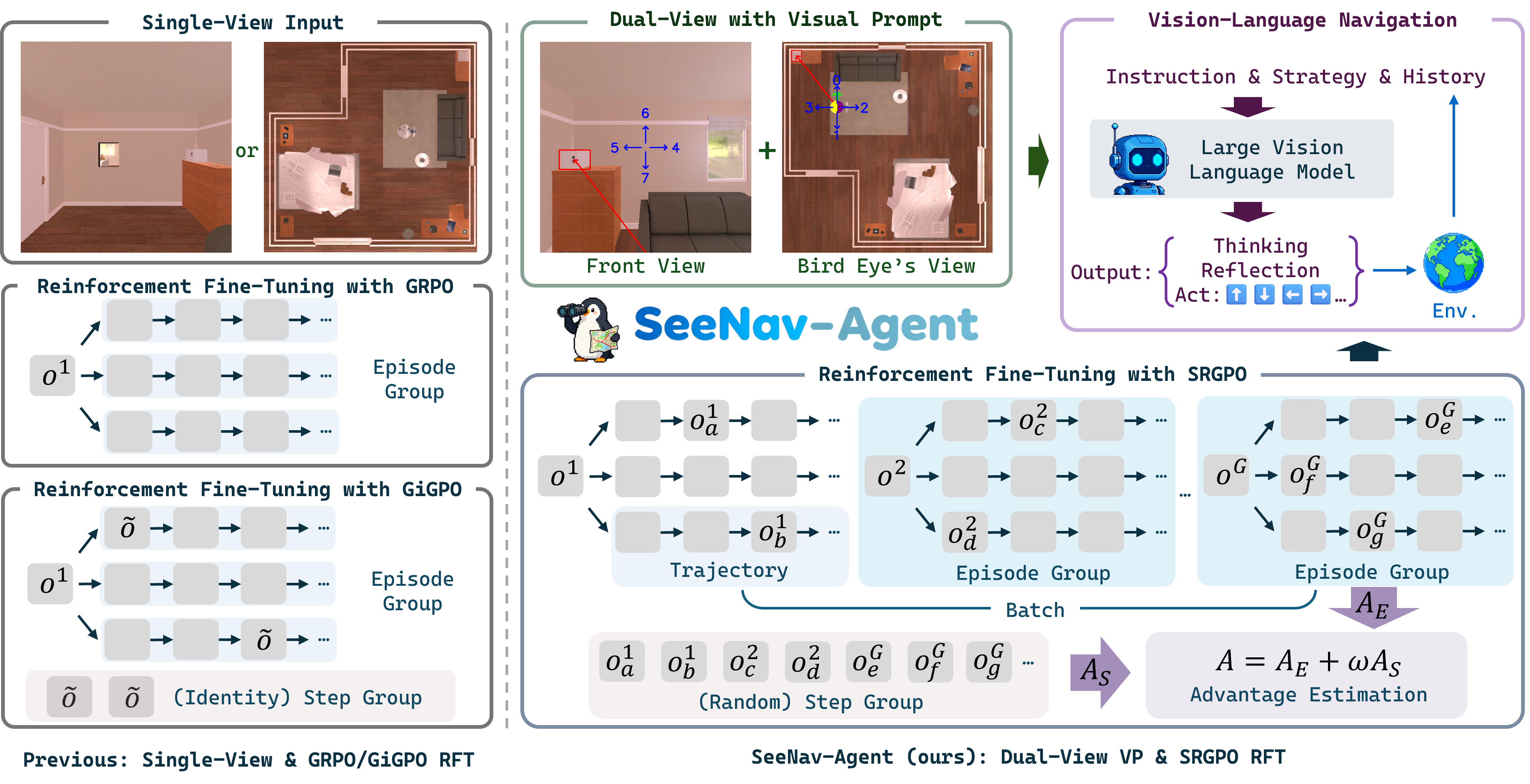
Представлен SeeNav-Agent, фреймворк для навигации, использующий визуальные промпты и алгоритм SRGPO для улучшения восприятия и планирования.
Несмотря на успехи в области навигации, основанной на обработке изображений и языка, существующие агенты часто сталкиваются с ошибками восприятия и планирования. В данной работе представлена новая платформа ‘SeeNav-Agent: Enhancing Vision-Language Navigation with Visual Prompt and Step-Level Policy Optimization’ для улучшения навигации, использующая двойной визуальный промпт для повышения точности восприятия и новый алгоритм обучения с подкреплением (SRGPO) для улучшения рассуждений и планирования. Эксперименты на стандартном бенчмарке EmbodiedBench Navigation показали, что предложенный подход позволяет достичь передовых результатов, значительно превосходя существующие модели. Возможно ли дальнейшее повышение эффективности и обобщающей способности агентов, использующих подобные методы, в более сложных и реалистичных условиях?
Преодолевая Границы Восприятия: Вызовы Визуально-Языковой Навигации
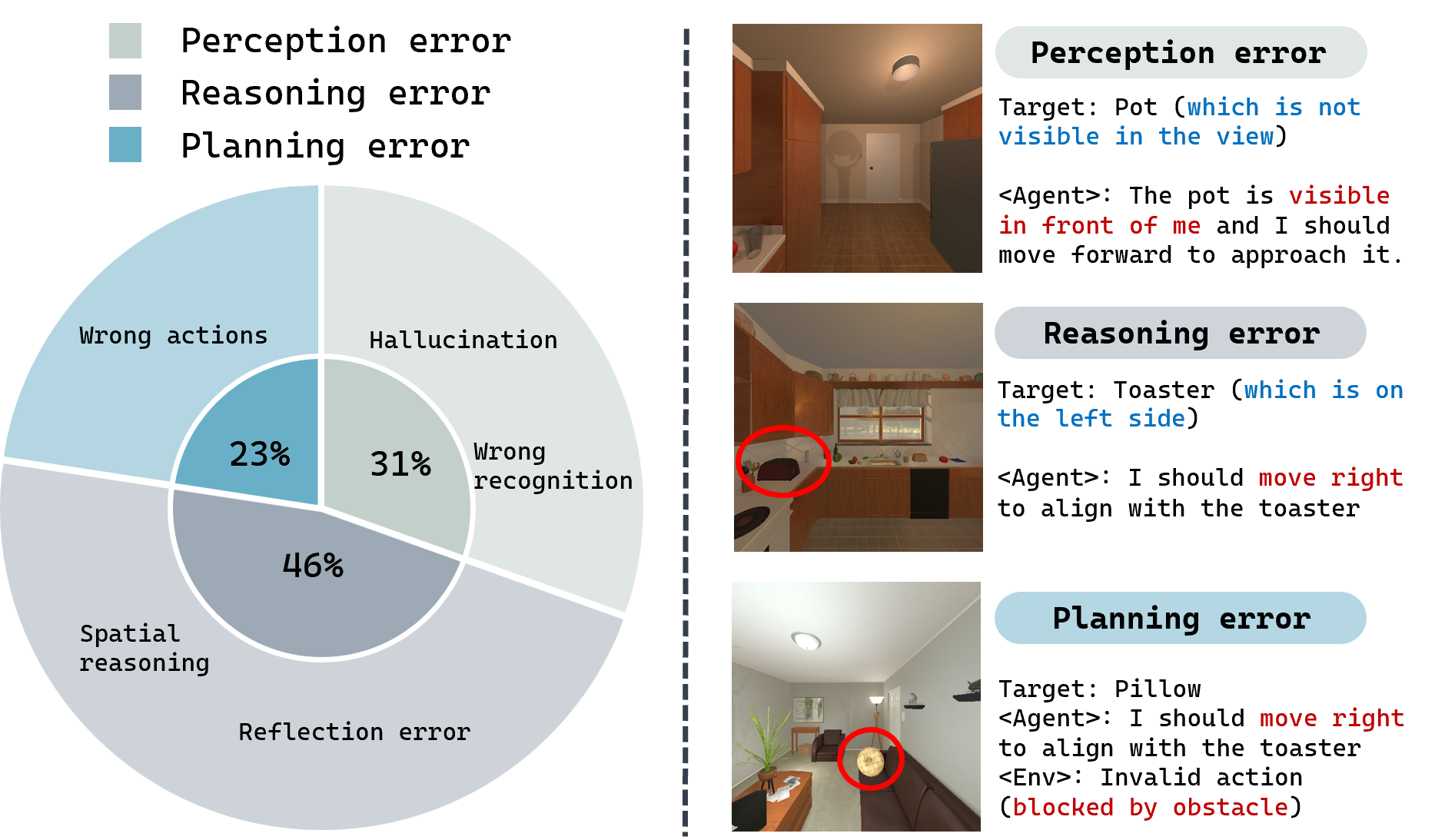
Несмотря на значительный прогресс в области Vision-and-Language Navigation (VLN), агенты, предназначенные для навигации по визуальным инструкциям, часто сталкиваются с неточностями восприятия и ошибками в логических рассуждениях. Эти недостатки проявляются в неспособности корректно интерпретировать визуальную информацию, что приводит к неверному пониманию окружения и, как следствие, к ошибочным решениям при планировании маршрута. Агенты могут испытывать трудности с распознаванием объектов в сложных сценах, оценкой расстояний или определением взаимосвязей между различными элементами окружения, что существенно ограничивает их способность к успешной навигации в реальных условиях. Проблемы с перцептивной точностью и логическим выводом подчеркивают необходимость дальнейших исследований в области разработки более надежных и эффективных алгоритмов для VLN-агентов.
В процессе навигации по визуальным инструкциям, агенты, использующие модели «зрение-язык», часто сталкиваются с ошибками, проявляющимися в виде «визуальных галлюцинаций» и неверной интерпретации пространственных взаимосвязей. Это означает, что система может «видеть» объекты, которых на самом деле нет, или неверно определять их расположение относительно друг друга и самого агента. Например, модель может ошибочно принять тень за препятствие или перепутать «слева» и «справа», что приводит к неверным решениям о дальнейших действиях и, как следствие, к сбоям в навигации и столкновениям с окружающей средой. Неспособность корректно воспринимать и анализировать визуальную информацию и пространственные отношения является серьезным препятствием для создания надежных и эффективных систем автономной навигации.
Существующие системы навигации, основанные на зрении и языке, зачастую демонстрируют неспособность генерировать корректные последовательности действий, что приводит к столкновениям с препятствиями или отклонению от заданного маршрута. Данная проблема обусловлена сложностью интерпретации визуальной информации и преобразования её в последовательность управляющих команд для агента. Несмотря на прогресс в области машинного обучения, системы всё ещё склонны к ошибкам в планировании траектории, особенно в динамичных или непредсказуемых средах. Некорректная генерация действий может быть вызвана неточностями в оценке расстояний, неправильным определением углов поворота или неспособностью учитывать ограничения пространства, что в итоге приводит к неэффективной и небезопасной навигации.
Очевидные недостатки существующих систем навигации, основанных на обработке изображений и языка, подчеркивают настоятельную необходимость разработки более надежных и устойчивых подходов к воплощенному искусственному интеллекту. Неспособность адекватно интерпретировать визуальную информацию и пространственные отношения приводит к ошибкам, таким как столкновения и отклонения от заданного маршрута, что ограничивает практическое применение этих систем в реальных условиях. Разработка принципиально новых архитектур и алгоритмов, способных к более точному восприятию окружающей среды и принятию обоснованных решений, является ключевой задачей для дальнейшего прогресса в области воплощенного ИИ и создания автономных агентов, способных эффективно функционировать в сложных и динамичных средах. Успешное решение этой задачи позволит расширить возможности робототехники, автоматизации и взаимодействия человека с машиной.
SeeNav-Agent: Двойной Взгляд на Пространство
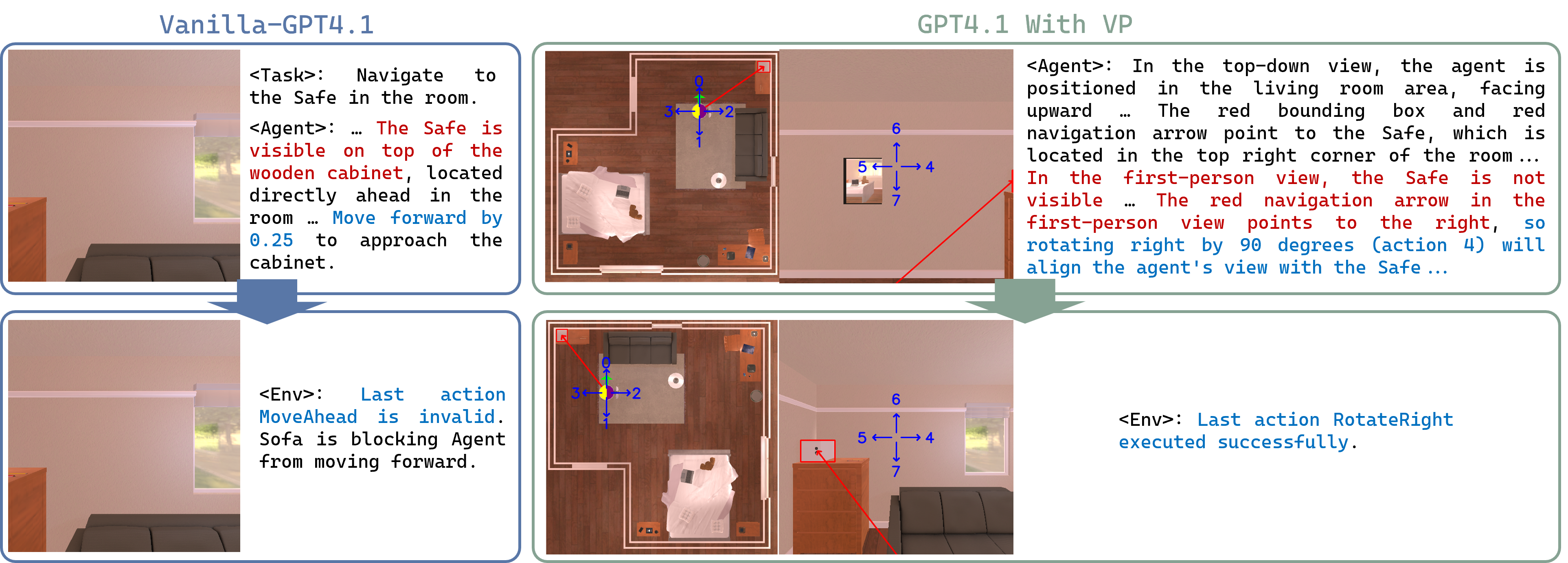
SeeNav-Agent представляет собой фреймворк, основанный на LVLM (Large Vision-Language Model) и использующий подход с “двумя видами” визуальных подсказок. Данный подход подразумевает использование как фронтальной, так и “птичьего полета” перспективы для улучшения восприятия окружающей среды агентом. Комбинирование этих двух видов позволяет модели получить более полное представление о сцене, что необходимо для точного определения местоположения, распознавания объектов и планирования дальнейших действий. Использование двух перспектив повышает устойчивость системы к различным условиям освещения и частичной видимости объектов.
Метод “проекции действий” позволяет преобразовать задачу планирования маршрута в задачу визуального вопросно-ответного анализа (VQA). Вместо непосредственного определения последовательности действий, агент получает визуальный запрос, основанный на предполагаемом действии, и должен определить, является ли это действие допустимым в текущей среде. Такой подход значительно снижает неоднозначность, возникающую при интерпретации сложных сцен, и повышает точность принятия решений, поскольку визуальный контекст непосредственно связан с планируемым действием. Преобразование задачи планирования в задачу VQA упрощает процесс рассуждения и позволяет агенту более эффективно использовать визуальную информацию для навигации.
Интеграция двойных визуальных подсказок (front и bird’s-eye view) с большими языковыми моделями (LLM), такими как GPT4.1 или Qwen2.5-VL-3B-Instruct, позволяет значительно повысить качество принимаемых решений агентом. LLM обрабатывают визуальную информацию, представленную в виде двойных подсказок, и используют ее для формирования более точных и контекстуально обоснованных планов действий. Это достигается за счет расширения возможностей модели в понимании окружающей среды и предвидении последствий действий, что критически важно для успешной навигации в сложных условиях. Использование LLM в качестве центрального блока принятия решений позволяет агенту эффективно оперировать визуальной информацией и преобразовывать ее в осмысленные команды.
Предложенный подход, основанный на использовании двойных визуальных подсказок и механизма проецирования действий, создает основу для разработки агентов, способных более надежно ориентироваться в сложных средах. Данная архитектура позволяет преобразовывать задачи планирования в задачи визуального вопросно-ответного типа (VQA), что снижает неоднозначность и повышает точность принятия решений. Интеграция с большими языковыми моделями, такими как GPT4.1 или Qwen2.5-VL-3B-Instruct, обеспечивает возможность более обоснованного выбора действий в динамически изменяющихся условиях, что критически важно для успешной навигации в реальных и виртуальных окружениях.

Шаг за Шагом к Оптимизации: Алгоритм SRGPO
Алгоритм Step Reward Group Policy Optimization (SRGPO) представляет собой метод обучения с подкреплением, разработанный для повышения эффективности оценки преимущества. SRGPO использует группировку шагов и независимую от состояния награду, что позволяет более точно оценивать качество действий агента и, как следствие, оптимизировать политику обучения. Основная цель разработки SRGPO — снижение количества необходимых образцов для достижения стабильного обучения и повышения общей эффективности алгоритма в задачах обучения с подкреплением, особенно в сложных средах.
Алгоритм SRGPO использует “верифицируемое вознаграждение за процесс” (verifiable process reward), которое не зависит от текущего состояния среды. Данный сигнал вознаграждения оценивает непосредственно качество совершаемых агентом действий, а не итоговый результат или достижение определенной точки в среде. Это позволяет алгоритму фокусироваться на улучшении стратегии действий, независимо от случайных факторов, влияющих на конечное состояние, и обеспечивает более стабильное обучение за счет непосредственной оценки качества каждого шага. Вознаграждение определяется исключительно на основе предпринятых действий и не подвержено влиянию внешних переменных, обеспечивая объективную оценку производительности агента.
Комбинация сигнала вознаграждения, основанного на процессе, с использованием вознаграждения, основанного на шаге, в ходе этапа точной настройки с подкреплением, направляет агента к оптимальным стратегиям навигации. Во время точной настройки, процесс-ориентированное вознаграждение корректирует поведение агента, используя информацию о качестве выполненных действий. Этот механизм позволяет агенту не только оценивать непосредственные результаты действий, но и учитывать их вклад в общую эффективность навигации, что способствует более стабильному и эффективному обучению. Использование сигнала, основанного на процессе, обеспечивает более надежную оценку преимуществ действий и, следовательно, улучшает сходимость алгоритма к оптимальной политике.
Алгоритм SRGPO значительно повышает эффективность использования данных и стабильность обучения за счет применения случайной группировки шагов. Вместо оценки преимущества на основе отдельных переходов, SRGPO группирует несколько последовательных шагов в эпизод и оценивает совокупное вознаграждение за этот эпизод. Случайное формирование этих групп позволяет снизить дисперсию оценки преимущества, что, в свою очередь, ускоряет сходимость и улучшает стабильность обучения, особенно в сложных средах с разреженным вознаграждением. Такой подход позволяет агенту более эффективно использовать ограниченные данные и избегать застревания в локальных оптимумах, что приводит к улучшению общей производительности.
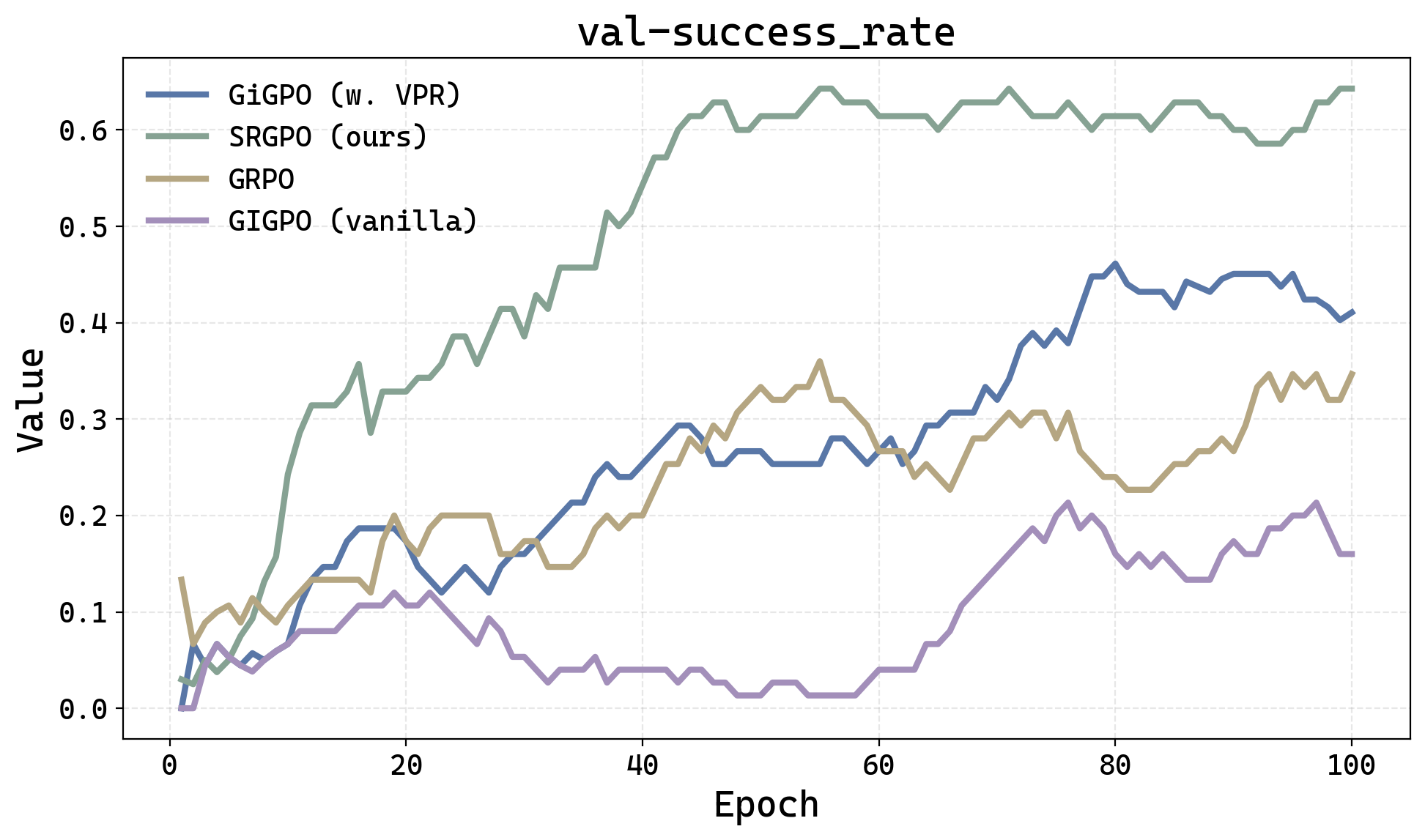
Подтверждение Эффективности: Результаты Экспериментов
Исследования, проведенные на платформе ‘EmbodiedBench Navigation’, демонстрируют значительное превосходство агента SeeNav, основанного на алгоритме SRGPO, над существующими аналогами. В ходе экспериментов достигнут впечатляющий прирост в 20 процентных пунктов успешности по сравнению с наиболее передовой на сегодняшний день коммерческой моделью. Этот результат указывает на существенный прогресс в области воплощенного искусственного интеллекта и подтверждает эффективность предложенного подхода к решению задач навигации в сложных средах. Достигнутое увеличение успешности свидетельствует о потенциале SeeNav-Agent для создания более интеллектуальных и надежных систем автономной навигации.
Комбинация двойных запросов и оптимизированного обучения с подкреплением демонстрирует значительное повышение успешности и эффективности проложенных маршрутов. В ходе экспериментов модель GPT4.1, дополненная визуальными подсказками (VP), достигла показателя успешности в 78%. Такой подход позволяет агенту лучше понимать окружающую среду и принимать более обоснованные решения при навигации, что существенно превосходит традиционные методы обучения. Эффективность данной стратегии обусловлена способностью модели одновременно анализировать визуальную информацию с различных точек зрения, что обеспечивает более полное представление о пространстве и позволяет строить оптимальные траектории движения.
Сравнительный анализ с использованием алгоритмов ‘group relative policy optimization’ и ‘proximal policy optimization’ подтвердил превосходство предложенного подхода. В ходе экспериментов модель Qwen2.5-VL-3B-Instruct, дополненная визуальными подсказками (VP) и стратегией SRGPO, продемонстрировала значительное улучшение результатов, превзойдя предыдущую самую эффективную открытую модель на 5,6 процентных пункта и достигнув показателя успешности в 62,3%. Полученные данные свидетельствуют о том, что комбинация оптимизированного обучения с подкреплением и эффективной обработки визуальной информации позволяет создавать более надежные и эффективные системы навигации в условиях реального мира.
Полученные результаты демонстрируют значительный потенциал SeeNav-Agent для развития области воплощенного искусственного интеллекта. Система, благодаря инновационному подходу к навигации, открывает новые возможности для создания более интеллектуальных систем, способных эффективно ориентироваться и взаимодействовать с физическим миром. Достигнутое превосходство над существующими моделями, как закрытыми, так и открытыми, указывает на перспективность дальнейших исследований в данной области и возможность применения SeeNav-Agent в широком спектре задач, включая робототехнику, автономные транспортные средства и системы помощи людям с ограниченными возможностями. Данный прогресс способствует созданию более надежных и адаптивных систем, способных решать сложные задачи навигации в реальных условиях.
Исследование, представленное в данной работе, демонстрирует стремление к созданию систем, способных к устойчивой навигации в сложных условиях. Подход, основанный на визуальном промптинге и оптимизации стратегии на каждом шаге, направлен на повышение надежности и адаптивности агента. Этот процесс напоминает философское убеждение, высказанное Полом Эрдешем: «Математика — это не только поиск истины, но и искусство делать это элегантно». Аналогично, SeeNav-Agent стремится не просто решить задачу навигации, но и сделать это эффективно, используя возможности современных моделей и алгоритмов обучения с подкреплением. Акцент на долгосрочной стабильности и адаптивности системы, особенно в контексте пространственного понимания, отражает важность создания устойчивых решений в области воплощенного искусственного интеллекта.
Что впереди?
Представленная работа, подобно любому инструменту, лишь временно отодвигает горизонт неизбежного. Улучшение восприятия и планирования посредством визуальных подсказок и оптимизации политики, безусловно, является шагом вперёд, но не решает фундаментальной проблемы: пространственное понимание, как и любое другое когнитивное свойство, подвержено энтропии. Версионирование моделей, оптимизация архитектур — это лишь формы памяти, попытки сохранить работоспособность системы перед лицом времени.
Очевидно, что акцент сместится в сторону более устойчивых представлений о пространстве, возможно, вдохновлённых принципами, лежащими в основе биологической навигации. Необходимо исследовать методы, позволяющие агентам не просто реагировать на текущий визуальный ввод, но и строить внутреннюю модель мира, способную к предсказанию и адаптации. Стрела времени всегда указывает на необходимость рефакторинга, и будущие исследования, вероятно, будут посвящены созданию систем, способных к самокоррекции и обучению на ошибках в реальном времени.
Остаётся открытым вопрос о масштабируемости предложенного подхода. Достаточно ли улучшения восприятия и планирования для достижения действительно общего искусственного интеллекта, или же требуется принципиально новый подход к моделированию когнитивных процессов? Ответ на этот вопрос, как и все ответы, будет найден лишь в процессе дальнейшего исследования, в непрерывном движении вперёд, несмотря на неизбежность старения любой системы.
Оригинал статьи: https://arxiv.org/pdf/2512.02631.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Устойчивое обучение языковых моделей: новый подход к контролю стратегии
- Сердце музыки: открытые модели для создания композиций
- Квантовый усилитель света на чипе: новый уровень эффективности
- Самообучающиеся системы: новый подход к созданию многоагентных взаимодействий
- Взгляд под капот: Анализ кода, сгенерированного нейросетями
- Квантовые системы в полуклассическом режиме: новый подход к моделированию
- 💸 Великобритания тратит 500 миллионов фунтов стерлингов на квантовые технологии – может быть, кот Шрёдингера только что разбогател?
- Искусственный интеллект и архитектура будущего: новый виток эволюции
- Искусственный интеллект: курс для жизни и общества
- Самостоятельность в эпоху ИИ: Как студенты учатся учиться с искусственным интеллектом
2025-12-07 19:00