Автор: Денис Аветисян
Новое исследование показывает, что использование больших языковых моделей для извлечения медицинской информации на итальянском языке может быть не таким эффективным, как традиционные методы.
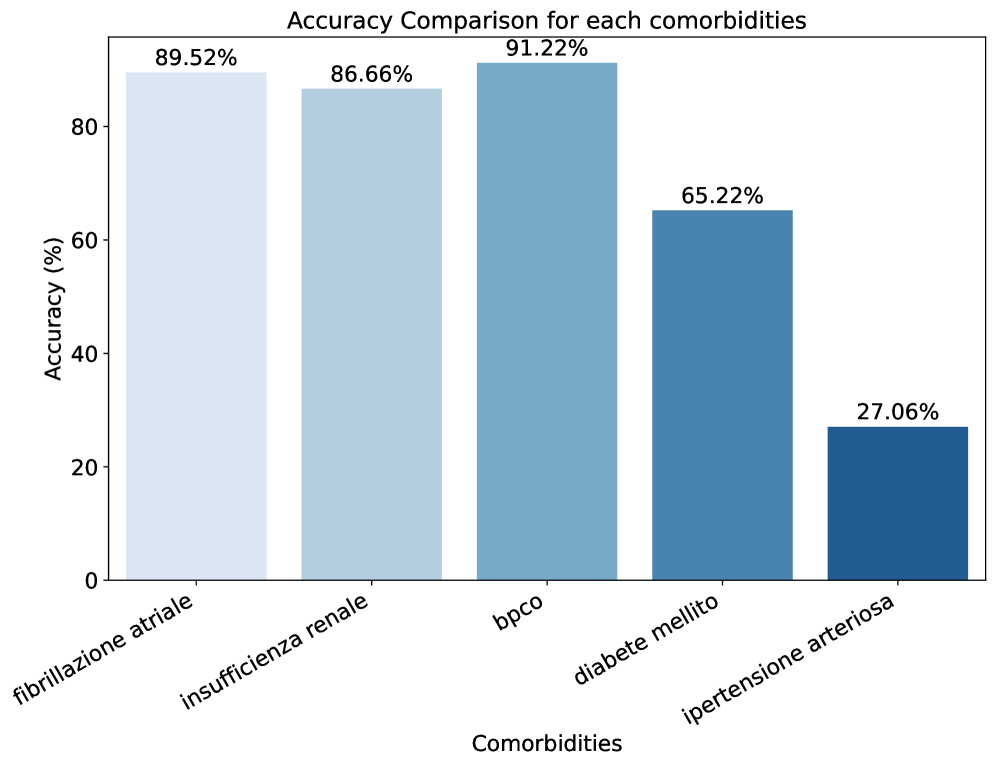
Оценка возможностей современных нейросетей в задаче извлечения сопутствующих заболеваний из итальянских электронных медицинских карт без предварительной адаптации.
Несмотря на стремительное развитие больших языковых моделей (LLM), вопрос об их реальной многоязычности и надежности остается открытым. В статье «Are LLMs Truly Multilingual? Exploring Zero-Shot Multilingual Capability of LLMs for Information Retrieval: An Italian Healthcare Use Case» исследуется способность открытых многоязычных LLM извлекать информацию из электронных медицинских карт на итальянском языке в условиях нулевой адаптации. Полученные результаты демонстрируют, что текущие LLM не всегда могут заменить традиционные методы, такие как регулярные выражения, при извлечении сопутствующих заболеваний из итальянских медицинских записей. Смогут ли будущие языковые модели преодолеть эти ограничения и обеспечить надежную многоязычную обработку информации в критически важных областях, таких как здравоохранение?
Раскрытие Информационного Потенциала Неструктурированных Медицинских Данных
Электронные медицинские записи представляют собой ценный источник клинической информации, однако значительная её часть заключена в неструктурированном текстовом формате. Врачи и другие специалисты здравоохранения регулярно фиксируют наблюдения, анамнез и результаты обследований в виде повествовательных отчетов, заметок и заключений. Эта информация, хотя и богата деталями, требует специальных методов обработки для извлечения полезных сведений. Традиционные способы анализа данных, ориентированные на структурированные поля, оказываются неэффективными при работе с таким объемом неформализованного текста, что затрудняет автоматизацию процессов и получение оперативной поддержки принятия клинических решений. Поэтому разработка и внедрение технологий, способных эффективно извлекать и анализировать информацию из неструктурированных медицинских записей, является ключевой задачей современной медицинской информатики.
Традиционные методы анализа медицинских записей, основанные на ручном просмотре или простых алгоритмах поиска ключевых слов, часто оказываются неэффективными при извлечении значимых сопутствующих заболеваний. Сложность клинической терминологии, вариативность формулировок и контекстуальная зависимость информации приводят к высокой вероятности ошибок и упущений. Это, в свою очередь, затрудняет создание надежных систем поддержки принятия решений, которые могли бы учитывать полный спектр заболеваний пациента и обеспечивать более точную диагностику и персонализированное лечение. Неспособность эффективно обрабатывать данные о сопутствующих заболеваниях ограничивает возможности для выявления групп риска, прогнозирования осложнений и оптимизации стратегий лечения, что в конечном итоге влияет на качество медицинской помощи.
Использование Больших Языковых Моделей для Выявления Сопутствующих Заболеваний
Большие языковые модели (БЯМ) предоставляют эффективный подход к извлечению информации, благодаря своей способности анализировать и понимать сложный язык, используемый в клинической практике. В отличие от традиционных методов, основанных на ручных правилах или ограниченных словарях, БЯМ используют глубокое обучение для обработки естественного языка, что позволяет им распознавать нюансы, синонимы и контекст в медицинских текстах. Они способны обрабатывать неструктурированные данные, такие как клинические заметки, отчеты о выписках и результаты исследований, извлекая релевантную информацию, такую как симптомы, диагнозы, лекарства и процедуры, с высокой точностью и скоростью. Основываясь на огромных объемах текстовых данных, БЯМ демонстрируют способность к обобщению и адаптации к различным стилям и форматам клинической документации.
Извлечение сопутствующих заболеваний, осуществляемое с помощью больших языковых моделей, позволяет автоматически выявлять одновременно присутствующие у пациента медицинские состояния на основе анализа медицинских записей. Этот процесс включает в себя анализ неструктурированного текста, такого как истории болезни, выписки и результаты обследований, для определения наличия нескольких заболеваний у одного пациента. Модели идентифицируют упоминания различных заболеваний и их взаимосвязи, что позволяет создать более полную картину состояния здоровья пациента и улучшить качество медицинской помощи. Автоматизация этого процесса снижает нагрузку на медицинский персонал и повышает точность выявления сопутствующих заболеваний, что особенно важно для пациентов с комплексными заболеваниями.
Эффективность извлечения информации о сопутствующих заболеваниях с использованием больших языковых моделей напрямую зависит от качества промпт-инжиниринга. Разработка и оптимизация запросов, подаваемых модели, критически важна для обеспечения точности и минимизации ошибок. В частности, четкое определение целевых сущностей, использование контекстуальных подсказок и предоставление примеров желаемого формата вывода позволяют модели более эффективно идентифицировать и извлекать релевантную информацию из клинических записей. Недостаточно продуманные запросы могут привести к неполным или неточным результатам, снижая ценность автоматизированного извлечения данных о сопутствующих заболеваниях.

Построение Надежного Конвейера Данных и Оценочной Базы
Для организации эффективной обработки клинических данных из разнородных источников используется ETL-процесс (Extract, Transform, Load), реализованный на языке Python. Этот процесс включает извлечение данных из различных источников, их преобразование в единый формат и очистку от неточностей, а также загрузку в централизованное хранилище данных. Python выбран в качестве основного языка реализации благодаря наличию широкого спектра библиотек для работы с данными, таких как pandas, NumPy и специализированных инструментов для работы с медицинскими данными, что обеспечивает гибкость и масштабируемость ETL-процесса. Автоматизация ETL-процесса позволяет обеспечить своевременное обновление данных и снизить вероятность ошибок, связанных с ручной обработкой.
Для обеспечения целостности и доступности клинических данных используется система управления базами данных Oracle. Oracle обеспечивает надежное хранение, индексацию и управление большими объемами структурированной информации, необходимой для обучения и оценки моделей извлечения сопутствующих заболеваний. Использование Oracle позволяет реализовать строгий контроль доступа, резервное копирование и восстановление данных, а также обеспечивает масштабируемость для поддержки растущих объемов информации и одновременного доступа множества пользователей и приложений. Это критически важно для поддержания качества данных и обеспечения воспроизводимости результатов анализа.
Ручная аннотация данных является основой для оценки точности моделей извлечения сопутствующих заболеваний. Создание эталонного набора данных, размеченного экспертами, позволяет объективно сравнить производительность различных подходов, включая методы на основе регулярных выражений и больших языковых моделей (LLM). Точность оценки напрямую зависит от качества и объема ручной аннотации, поскольку она служит «золотым стандартом», с которым сопоставляются результаты работы моделей. В рамках данного проекта, ручная разметка используется для количественной оценки эффективности извлечения сопутствующих заболеваний и определения оптимальной конфигурации моделей для достижения максимальной точности и надежности.
При оценке точности извлечения сопутствующих заболеваний, методы, основанные на больших языковых моделях (LLM), демонстрируют вариативность результатов. В качестве базового уровня используется сопоставление с помощью регулярных выражений, обеспечивающее точность в 92% на исследуемом наборе данных. Модель Mistral 7B показывает сопоставимую точность — от 80% до 94% в зависимости от конкретного сопутствующего заболевания. Модель OpenLLama 7B превосходит OpenLLama 3B, достигая точности более 70%, однако остается ниже базового уровня, заданного регулярными выражениями. Модель OpenLLama 3B демонстрирует крайне низкую точность, менее 10%.
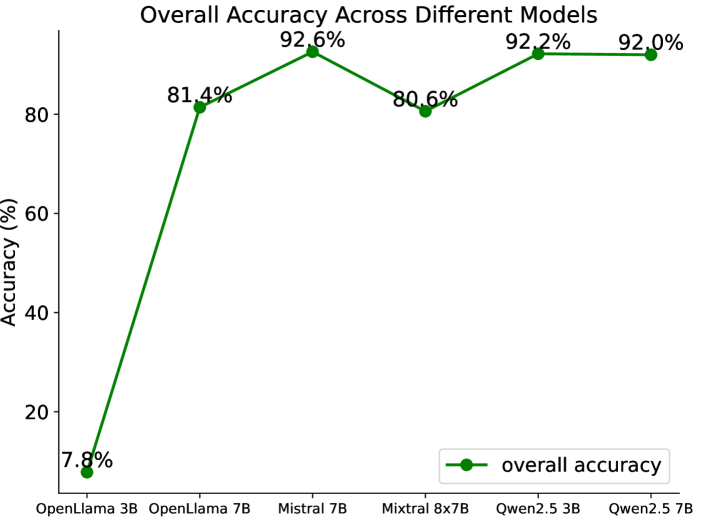
Усиление Приватности и Масштабируемости с Использованием Открытых LLM
Открытые большие языковые модели (LLM) предоставляют беспрецедентный уровень прозрачности и контроля над обработкой данных, что существенно повышает конфиденциальность. В отличие от проприетарных решений, исходный код этих моделей доступен для изучения, модификации и аудита, позволяя организациям полностью понимать, как обрабатываются их данные. Это особенно важно в секторах, где конфиденциальность данных имеет первостепенное значение, таких как здравоохранение и финансы. Возможность полного контроля над процессом обработки позволяет организациям адаптировать модели к своим конкретным потребностям и требованиям безопасности, минимизируя риски, связанные с утечкой или несанкционированным доступом к данным. Такой подход способствует укреплению доверия пользователей и соответствию строгим нормативным требованиям в области защиты персональных данных.
Развертывание моделей больших языковых моделей (LLM) с открытым исходным кодом непосредственно на локальных серверах предоставляет значительные преимущества в области безопасности данных и конфиденциальности. В отличие от использования облачных API, где данные передаются третьим сторонам для обработки, локальное развертывание позволяет организациям полностью контролировать жизненный цикл данных. Это особенно важно для отраслей, работающих с конфиденциальной информацией, таких как здравоохранение и финансы, где соблюдение нормативных требований является приоритетом. Полный контроль над инфраструктурой обработки данных снижает риски, связанные с утечкой данных, несанкционированным доступом и зависимостью от внешних поставщиков. Таким образом, переход к локальным LLM является стратегическим шагом для повышения безопасности и укрепления доверия к системам обработки информации.
Для эффективного извлечения сопутствующих заболеваний из больших баз данных пациентов, требующих анализа миллионов медицинских записей, критически важны вычислительные ресурсы высокой производительности. Объем и сложность обработки естественного языка (NLP) в сочетании с необходимостью поддержания высокой точности и скорости анализа, предъявляют значительные требования к инфраструктуре. Без доступа к мощным серверам, большим объемам оперативной памяти и оптимизированным алгоритмам параллельной обработки данных, задача анализа становится непрактичной и требует неприемлемо большого времени. Использование таких ресурсов позволяет не только ускорить процесс извлечения информации, но и масштабировать его для охвата более широких групп пациентов, что является ключевым для проведения эпидемиологических исследований и улучшения качества медицинской помощи.
Исследования показали, что, несмотря на многообещающие перспективы обучения с нулевым примером (zero-shot learning), даже наиболее эффективная большая языковая модель, Mistral 7B, не превосходит по точности традиционный подход, основанный на регулярных выражениях, в задаче извлечения сопутствующих заболеваний. Данный результат указывает на необходимость проведения дополнительных исследований, направленных на повышение точности больших языковых моделей в данной области. Улучшение алгоритмов обучения и адаптация моделей к специфике медицинских данных представляются ключевыми направлениями для достижения более высоких результатов и раскрытия потенциала больших языковых моделей в анализе клинической информации.
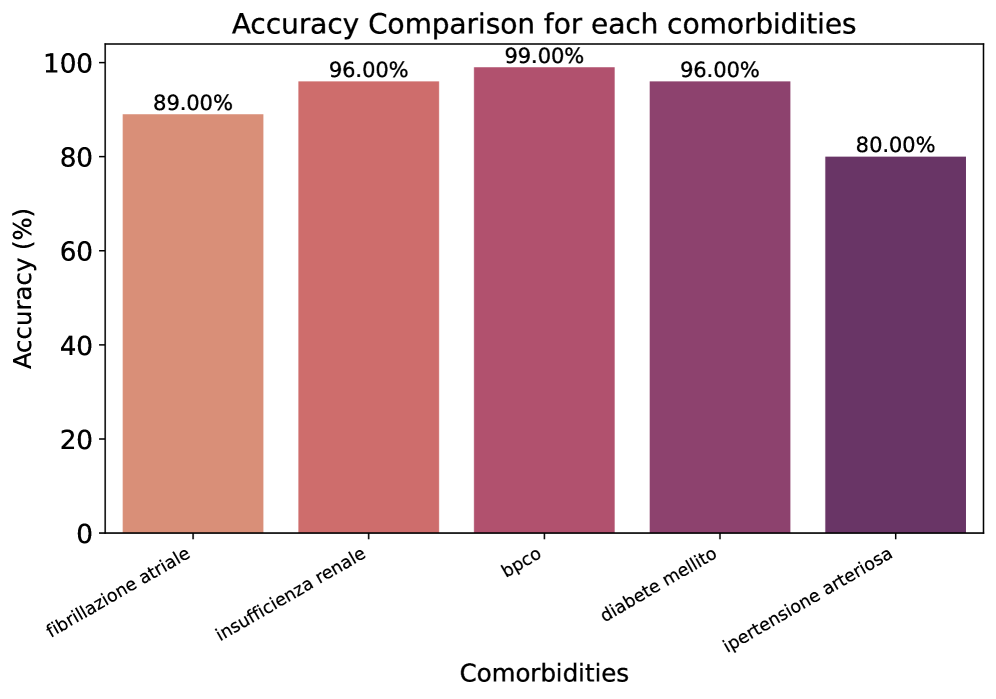
Исследование, посвященное извлечению сопутствующих заболеваний из итальянских электронных медицинских карт, выявляет важную закономерность. Подобно тому, как математик стремится к устойчивости решения при N, стремящемся к бесконечности, данная работа подчеркивает необходимость надежных, предсказуемых методов в критически важных областях. Современные большие языковые модели, несмотря на свою впечатляющую способность к обобщению, демонстрируют нестабильность в задачах извлечения информации, уступая проверенным временем регулярным выражениям. Тим Бернерс-Ли однажды заметил: «Данные должны быть свободны». Однако свобода данных не гарантирует их точности или надежности обработки. Представленное исследование подтверждает, что даже самые передовые алгоритмы нуждаются в строгой проверке и корректной реализации, чтобы гарантировать устойчивость и предсказуемость результатов, особенно когда речь идет о здоровье человека.
Куда Ведет Эта Дорога?
Представленное исследование, демонстрируя несостоятельность наивной экстраполяции возможностей больших языковых моделей в задачу извлечения коморбидностей из итальянских медицинских записей, поднимает фундаментальный вопрос о природе «понимания» в контексте искусственного интеллекта. Безусловно, элегантность регулярных выражений, построенных на строгой логике и доказанной корректности, представляется предпочтительнее расплывчатой вероятностной модели, склонной к галлюцинациям и непредсказуемым ошибкам. Однако, игнорировать потенциал языковых моделей было бы неразумно; проблема заключается не в самом инструменте, а в его некорректном применении.
Будущие исследования должны сосредоточиться не на «улучшении» существующих моделей для решения неадекватных задач, а на разработке гибридных подходов. Комбинация детерминированных алгоритмов, таких как регулярные выражения, с вероятностными моделями, способными улавливать тонкие нюансы языка, представляется более перспективным направлением. Важно помнить, что истинная красота алгоритма проявляется не в трюках, а в непротиворечивости его границ и предсказуемости.
В конечном счете, задача состоит не в создании искусственного интеллекта, имитирующего человеческое понимание, а в разработке надежных и верифицируемых инструментов для решения конкретных задач. Иллюзии о «многоязычности» и «общем интеллекте» должны уступить место строгой математической формализации и доказательной базе.
Оригинал статьи: https://arxiv.org/pdf/2512.04834.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Надежность ускорителей: от замысла до реализации
- Ядерный синтез и Искусственный Интеллект: Новый подход к проектированию реакторов
- Карта ошибок: Анатомия сбоев больших языковых моделей
- Квантовые нейросети для реалистичной 3D-визуализации
- Квантовые вычисления: от Y2K к Q-Дню и дальше
- Понимание видео: новый вызов для искусственного интеллекта
- Квантовые вычисления: Ускорение решения линейных уравнений с помощью машинного обучения
- Визуальная навигация по множеству изображений: новый подход с использованием больших языковых моделей
- Когда Больше – Не Значит Лучше: О Ловушках Улучшения Рассуждений Искусственного Интеллекта
- Самообучающийся интеллект для выявления причинно-следственных связей
2025-12-08 05:09