Автор: Денис Аветисян
Исследователи представили систему SCAIL, позволяющую создавать высококачественную анимацию персонажей, приближающуюся к студийному уровню.
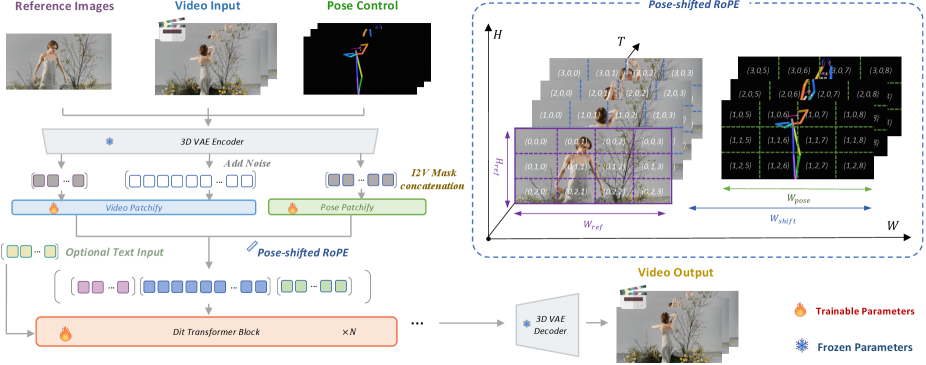
SCAIL использует диффузионные модели и трехмерные представления поз для улучшения точности и реалистичности движения.
Несмотря на значительный прогресс в области компьютерной графики, достижение студийного качества анимации персонажей остается сложной задачей, особенно при переносе движений и сохранении структурной целостности. В данной работе представлена система SCAIL: Towards Studio-Grade Character Animation via In-Context Learning of 3D-Consistent Pose Representations, использующая инновационное 3D-представление поз и механизм полноконтекстной инъекции в архитектуру диффузионной модели. Это позволяет добиться высокой точности и реалистичности анимации, сохраняя согласованность движений во времени. Открывает ли SCAIL новые перспективы для автоматизации процесса создания высококачественной анимации и снижения затрат на производство контента?
Преодолевая Ограничения: К Пониманию Выразительного 3D-Моделирования Человека
Существующие трехмерные модели человеческого тела, такие как SMPL, хоть и отличаются высокой эффективностью, испытывают трудности при воспроизведении сложных и нюансированных движений. Это ограничение существенно снижает их применимость в задачах, требующих реалистичной анимации, поскольку стандартные модели часто не способны адекватно отразить тонкости человеческой моторики — от естественных изгибов позвоночника при ходьбе до едва заметных микродвижений лица, выражающих эмоции. В результате, анимация, созданная на основе подобных моделей, может выглядеть неестественно и роботизированно, лишая персонажей жизненности и правдоподобия. Поэтому возникает необходимость в разработке более продвинутых моделей, способных учитывать весь спектр человеческих движений и передавать мельчайшие детали, необходимые для создания убедительной иллюзии реальности.
Традиционные методы представления позы человека, такие как использование углов и позиций отдельных суставов, часто оказываются недостаточными для точного воспроизведения сложной динамики всего тела. Эти подходы, как правило, не учитывают взаимосвязанные движения различных частей тела и не способны адекватно моделировать тонкие нюансы, возникающие при естественных движениях. В результате, созданные анимации могут выглядеть неестественно и нереалистично. Для преодоления этих ограничений необходимы решения, которые сочетают в себе высокую точность в захвате движений с достаточной гибкостью для моделирования широкого спектра человеческих поз и динамики. Современные исследования направлены на разработку методов, способных учитывать не только положение суставов, но и деформацию мягких тканей, а также влияние инерции и гравитации на движения, что позволяет создавать более правдоподобные и реалистичные 3D-модели человека.
Современные методы 3D-моделирования человеческого тела часто демонстрируют ограниченные возможности в генерализации и адаптации к ранее не встречавшимся движениям, что серьезно препятствует созданию правдоподобной анимации. Исследования показывают, что модели, обученные на определенном наборе движений, испытывают трудности при воспроизведении новых, нетипичных поз и динамики, особенно когда речь идет о сложных взаимодействиях или экспрессивных жестах. Эта проблема обусловлена сложностью полного охвата всего разнообразия человеческой моторики в процессе обучения, что приводит к неестественным или искаженным движениям при попытке генерации новых анимаций. Преодоление этого ограничения требует разработки более гибких и адаптивных моделей, способных экстраполировать знания и обобщать информацию для создания действительно реалистичных и убедительных персонажей в виртуальном пространстве.

SCAIL: Контекстно-Зависимая Анимация — Новая Архитектура
Предлагаемый фреймворк SCAIL использует новое 3D-представление позы персонажа, разработанное для преодоления ограничений существующих моделей анимации. Традиционные подходы часто сталкиваются с трудностями при захвате сложных взаимодействий и динамических изменений в позе, что приводит к неестественным движениям. SCAIL решает эту проблему, представляя позу не как набор углов, а как компактное и информативное 3D-представление, позволяющее модели более точно моделировать анатомию и кинематику персонажа. Это позволяет генерировать более реалистичные и правдоподобные анимации, учитывая как глобальную структуру движения, так и локальные детали позы.
Метод полной инъекции поз (Full-Context Pose Injection) в SCAIL позволяет модели учитывать всю последовательность движений при генерации анимации. Вместо обработки каждого кадра изолированно, модель получает информацию о предыдущих и последующих позах персонажа. Это достигается путем подачи полной последовательности поз в качестве контекста для каждого кадра, что позволяет ей предсказывать более когерентные и правдоподобные движения. В отличие от подходов, использующих только локальную историю или рекуррентные сети с ограниченной памятью, SCAIL эффективно использует всю доступную информацию о последовательности, минимизируя несогласованности и повышая реалистичность генерируемой анимации. Данный подход особенно важен для сложных движений, требующих долгосрочного планирования и поддержания согласованности на протяжении всей последовательности.
В основе SCAIL лежит архитектура Diffusion Transformer (DiT), объединяющая преимущества диффузионных моделей и трансформеров для генерации высококачественного видео. Диффузионные модели обеспечивают генерацию детализированных и реалистичных кадров за счет постепенного добавления шума и последующего его удаления, в то время как трансформеры позволяют эффективно моделировать долгосрочные зависимости во времени, что критически важно для когерентности движения. Использование DiT позволяет SCAIL генерировать видеоролики с высоким разрешением и плавными переходами, сохраняя при этом согласованность и реалистичность анимированных персонажей. Архитектура DiT также способствует эффективному обучению модели и снижает вычислительные затраты по сравнению с традиционными подходами к генерации видео.
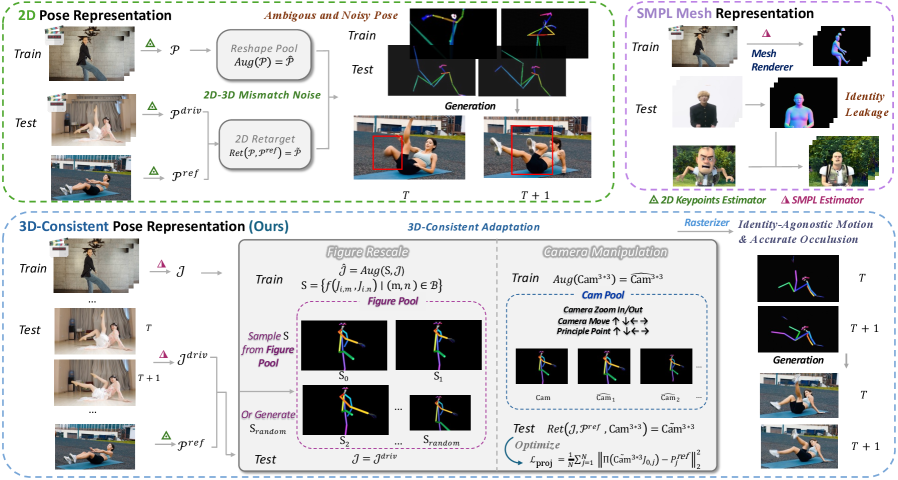
Эффективная Генерация Видео: Латентная Диффузия и Архитектура DiT
В основе SCAIL лежат модели латентной диффузии, обеспечивающие эффективную и высококачественную генерацию видео за счет работы в сжатом латентном пространстве. Вместо обработки непосредственно пикселей видео, модель оперирует с компактным представлением данных, полученным путем кодирования видео в латентное пространство с помощью автоэнкодера. Это значительно снижает вычислительные затраты и требования к памяти по сравнению с подходами, работающими непосредственно с пикселями, при сохранении высокого качества генерируемого видео. Сжатие данных позволяет модели фокусироваться на наиболее значимых признаках видео, что способствует более быстрой и эффективной генерации.
В архитектуре Diffusion Transformer, вращательное позиционное кодирование (RoPE) существенно повышает возможности моделирования и масштабируемость. В отличие от абсолютных позиционных кодировок, RoPE кодирует информацию о позиции посредством вращения векторов признаков, что позволяет модели эффективно обрабатывать длинные последовательности и лучше обобщать на новые данные. Это достигается за счет использования матрицы вращения, зависящей от позиции токена в последовательности. Применение RoPE приводит к улучшению воспроизведения движения в генерируемых видео, поскольку модель более точно учитывает временные зависимости между кадрами и сохраняет когерентность движения на протяжении всей последовательности. Эффективность RoPE особенно заметна при генерации видео с высокой скоростью движения или сложными траекториями объектов.
Механизм управления генерацией, известный как Classifier-Free Guidance (CFG), позволяет точно настраивать процесс создания видео. В основе CFG лежит идея одновременного обучения модели как с условием (например, текстовым описанием), так и без него. В процессе генерации, выходные данные модели, обученной без условия, смешиваются с выходными данными, обученными с условием, с использованием коэффициента масштабирования. Изменяя величину этого коэффициента, можно регулировать степень влияния условия на результат, обеспечивая более точный контроль над атрибутами генерируемого видео, такими как стиль, содержание и детализация. Таким образом, CFG позволяет пользователям получать видео, соответствующие конкретным требованиям, без необходимости сложной постобработки или переобучения модели.
Studio-Bench: Новый Эталон для Оценки Анимации и Многолюдные Сцены
Представлен Studio-Bench — новый эталонный набор данных, предназначенный для всесторонней оценки моделей анимации персонажей в условиях, приближенных к реальным производственным задачам. В отличие от существующих тестов, Studio-Bench делает акцент на сложности движений и способности моделей к обобщению, то есть к адаптации к новым, ранее не встречавшимся ситуациям. Набор данных включает в себя разнообразные сценарии и движения, требующие от алгоритмов не только реалистичной имитации, но и способности учитывать взаимодействие персонажей и окружающего пространства. Это позволяет более точно оценить, насколько хорошо модель сможет быть использована в практических приложениях, таких как создание фильмов, игр и виртуальной реальности, где требуется высокая степень реализма и адаптивности анимации.
Система SCAIL продемонстрировала значительный прогресс по сравнению с существующими методами в рамках эталонного теста Studio-Bench, достигнув передовых результатов по нескольким ключевым показателям. В ходе оценки, включавшей сложные движения и обобщение данных, SCAIL превзошла альтернативные подходы в точности воспроизведения анимации и реалистичности движений. Данный успех обусловлен инновационной архитектурой системы, позволяющей эффективно обрабатывать большие объемы данных и генерировать высококачественные анимационные последовательности, что подтверждается количественными метриками и визуальной оценкой экспертов в области компьютерной графики. Результаты свидетельствуют о потенциале SCAIL для применения в профессиональных рабочих процессах по созданию анимации.
В основе системы лежит комплексный подход к отслеживанию и сегментации объектов в многолюдных видео. Для точного определения границ каждого персонажа используются алгоритмы YOLO, позволяющие быстро и эффективно выявлять объекты на кадрах. Далее, для разделения масок и обеспечения реалистичной анимации, применяется модель GLM в сочетании с Samurai. Такой тандем позволяет системе не просто идентифицировать людей, но и учитывать их индивидуальные позы и движения, что особенно важно при создании сложных сцен с множеством взаимодействующих персонажей. Это, в свою очередь, значительно повышает достоверность и визуальное качество генерируемой анимации, приближая ее к уровню, достижимому в профессиональной кинематографии.

Исследование, представленное в данной работе, акцентирует внимание на важности последовательного представления трехмерной позы для достижения реалистичной анимации персонажей. Данный подход к анимации, использующий диффузионные модели и полное внедрение контекста, позволяет добиться высокой точности и естественности движений. Как отмечал Дэвид Марр: «Понимание системы — это исследование её закономерностей». Эта фраза особенно актуальна в контексте SCAIL, поскольку система стремится выявить и воспроизвести закономерности движения, что является ключевым аспектом для создания убедительной анимации. Использование 3D-представлений позволяет системе лучше понимать структуру движений, что, в свою очередь, повышает реализм и качество анимации.
Куда Ведут Эти Пути?
Представленная работа, безусловно, демонстрирует потенциал диффузионных моделей в создании реалистичной анимации. Однако, стоит признать, что воспроизводимость и объяснимость полученных результатов остаются критическими вопросами. Успешное воспроизведение требует не только доступа к обученным моделям, но и детального понимания влияния каждого параметра на конечный результат. Недостаточно просто получить «студийное качество» — необходимо понимать, как оно было достигнуто.
Перспективы дальнейших исследований лежат, вероятно, в области разработки более строгих метрик оценки анимации, выходящих за рамки субъективной оценки «реализма». Необходимо сосредоточиться на количественной оценке физической правдоподобности движений, сохранения объёма и согласованности персонажа. Интересным направлением представляется изучение возможности интеграции SCAIL с системами управления движением на основе физики, что позволит создавать анимацию, одновременно эстетически привлекательную и физически корректную.
В конечном итоге, задача состоит не в том, чтобы создать «искусственного художника», а в том, чтобы предоставить инструменты для расширения творческих возможностей человека. Иными словами, не замена аниматора, а его усиление. Понимание закономерностей, лежащих в основе успешной анимации, остаётся ключевым, и только строгий анализ данных, а не слепое доверие метрикам качества, позволит нам приблизиться к этой цели.
Оригинал статьи: https://arxiv.org/pdf/2512.05905.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Надежность ускорителей: от замысла до реализации
- Карта ошибок: Анатомия сбоев больших языковых моделей
- Квантовые нейросети для реалистичной 3D-визуализации
- Искусственный интеллект, действующий по цели: эволюция архитектуры
- Нейросеть предсказывает сродство антител к COVID-19
- Накапливая опыт: мультимодальные агенты, которые учатся на ходу
- Понимание видео: новый вызов для искусственного интеллекта
- От основ к интеллекту: как объединить машинное обучение и большие языковые модели
- Квантовые сети под контролем: новая библиотека для моделирования гибридных схем
- Визуальная навигация по множеству изображений: новый подход с использованием больших языковых моделей
2025-12-08 16:56