Автор: Денис Аветисян
Новый подход позволяет моделям генерировать видео, осознавая границы своей компетенции и предоставляя оценку достоверности результата.
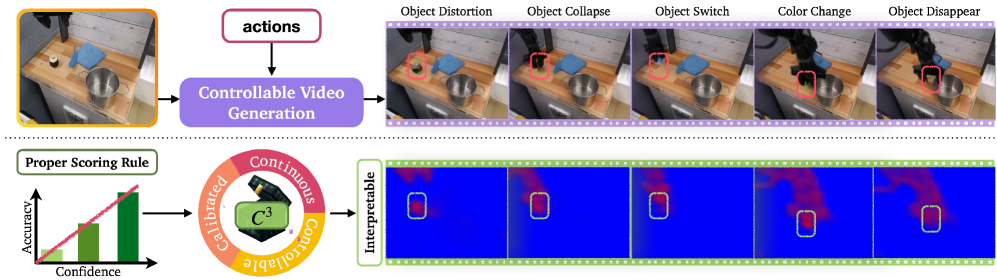
Исследование представляет метод C3C³ для обучения видеомоделей количественной оценке неопределенности и калибровке уверенности на уровне отдельных фрагментов изображения.
Несмотря на значительный прогресс в генерации видео, современные модели часто склонны к «галлюцинациям» — созданию нереалистичных сцен, что критично для задач, связанных с робототехникой и планированием. В данной работе, ‘World Models That Know When They Don’t Know: Controllable Video Generation with Calibrated Uncertainty’, предложен метод C3, позволяющий обучать видеомодели количественно оценивать собственную неопределенность и предоставлять откалиброванные прогнозы достоверности на уровне отдельных фрагментов изображения. Предложенный подход не только обеспечивает точную оценку уверенности в рамках обучающей выборки, но и позволяет обнаруживать ситуации, выходящие за ее пределы. Сможет ли такая калибровка уверенности значительно повысить надежность и безопасность систем, использующих генерируемое видео для принятия решений?
От пикселей к возможностям: Задача генерации видео
Недавние достижения в области генеративного моделирования открыли впечатляющие возможности для синтеза видео, однако достижение одновременно реалистичности и управляемости остается сложной задачей. Современные алгоритмы, несмотря на способность создавать визуально правдоподобные кадры, часто испытывают трудности с поддержанием согласованности повествования и разнообразия контента, особенно при воспроизведении сложных действий и взаимодействий. Добиться убедительного результата — это не просто сгенерировать отдельные кадры, но и обеспечить плавный переход между ними, логичную последовательность событий и соответствие заданным параметрам, что требует разработки новых подходов к представлению видеоданных и архитектуре генеративных моделей. Поиск баланса между качеством изображения, динамикой сцены и степенью контроля над процессом генерации остается ключевой проблемой в этой быстро развивающейся области.
Традиционные методы генерации видео часто сталкиваются с трудностями при обеспечении согласованности и разнообразия генерируемого контента, особенно когда речь идет о сложных действиях и взаимодействиях. Существующие подходы, как правило, испытывают проблемы с сохранением визуальной правдоподобности во времени — объекты могут внезапно меняться, нарушаться законы физики, или возникать нелогичные переходы между кадрами. Кроме того, часто наблюдается ограниченность в вариативности: генерируемые видеоролики могут быть однообразными и лишенными реалистичного разнообразия, присущего естественным движениям и поведению. Это связано с тем, что традиционные модели не всегда способны адекватно захватить и воспроизвести сложные временные зависимости, а также учитывать тонкие нюансы, определяющие реалистичность и убедительность видеоряда.
Для успешного решения задачи генерации видео необходима надежная репрезентация данных, позволяющая эффективно кодировать и декодировать визуальную информацию. Современные исследования фокусируются на разработке таких представлений, которые способны улавливать не только статичные объекты, но и сложные динамические взаимодействия между ними. Генеративная модель, способная обрабатывать эти репрезентации, должна учитывать тончайшие нюансы движения, освещения и текстур, чтобы создавать реалистичные и правдоподобные видеоролики. Особое внимание уделяется методам, позволяющим контролировать процесс генерации, задавая желаемые характеристики видео, такие как стиль, содержание и длительность, обеспечивая тем самым не просто синтез изображения, но и создание осмысленного визуального повествования.
Кодирование динамики видео: Сила латентных пространств
Представление видеоданных в низкоразмерном латентном пространстве значительно упрощает их обработку и манипулирование. Вместо работы с исходными данными, характеризующимися высокой размерностью (например, последовательностью пикселей в каждом кадре), видео кодируется в вектор меньшей размерности, сохраняя при этом наиболее существенные признаки. Такое сжатие позволяет снизить вычислительные затраты при анализе и генерации видео, а также обеспечивает возможность контролируемого изменения характеристик видеоконтента путем манипулирования векторами в латентном пространстве. Это особенно важно для задач, требующих высокой эффективности и точности, таких как сжатие видео, редактирование и создание нового контента на основе существующих данных. Размерность латентного пространства является ключевым параметром, определяющим баланс между степенью сжатия и сохранением информации.
Автоэнкодеры (VAE) эффективно сжимают видеоданные в пространство скрытых представлений, сохраняя при этом ключевые характеристики. Этот процесс достигается за счет обучения VAE кодировать видео в компактное, низкоразмерное представление, из которого затем происходит реконструкция исходного видео. Потеря информации минимизируется за счет использования вероятностного подхода, что позволяет VAE не только сжимать данные, но и генерировать новые, похожие видео. Снижение вычислительной нагрузки достигается за счет обработки данных в пространстве скрытых представлений, где размерность значительно ниже, чем у исходного видеопотока, что существенно ускоряет операции обработки и анализа видеоданных.
Сжатое представление видеоданных, полученное посредством понижения размерности, играет ключевую роль в выявлении и моделировании внутренней структуры видеоконтента. Это позволяет не просто хранить и обрабатывать видеоэффективнее, но и осуществлять целенаправленную генерацию новых фрагментов или модификацию существующих. В частности, выделение латентных признаков позволяет оперировать семантическими аспектами видео, такими как объекты, действия и сцены, что обеспечивает возможность контролируемого изменения и синтеза видеоматериалов на основе заданных параметров или целей. Использование латентного пространства облегчает задачи, требующие понимания и манипулирования содержанием видео, такие как редактирование, стилизация и создание новых визуальных эффектов.
За пределами генерации: Количественная оценка неопределенности и надежности
Основная проблема при внедрении моделей генерации видео заключается в оценке их надёжности, особенно при экстраполяции за пределы обучающих данных. Модели, обученные на ограниченном наборе данных, могут демонстрировать значительное снижение качества генерации при обработке входных данных, отличающихся от тех, на которых они были обучены. Это проявляется в виде артефактов, нереалистичных деталей или общей несогласованности в генерируемых видеокадрах. Оценка уверенности модели в своих предсказаниях становится критически важной, поскольку позволяет выявлять потенциально ненадёжные результаты и предотвращать их использование в критически важных приложениях. Неспособность корректно оценить надёжность генерации может привести к непредсказуемым последствиям и снизить доверие к технологии.
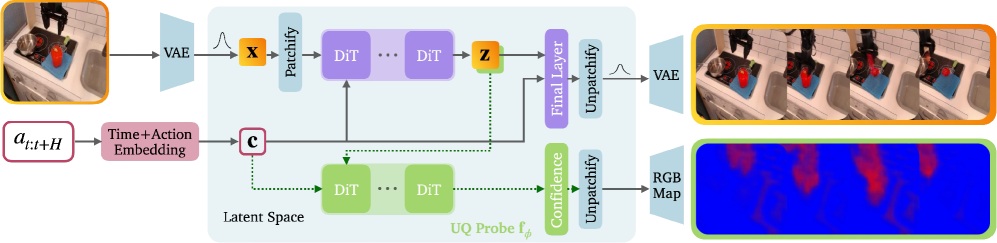
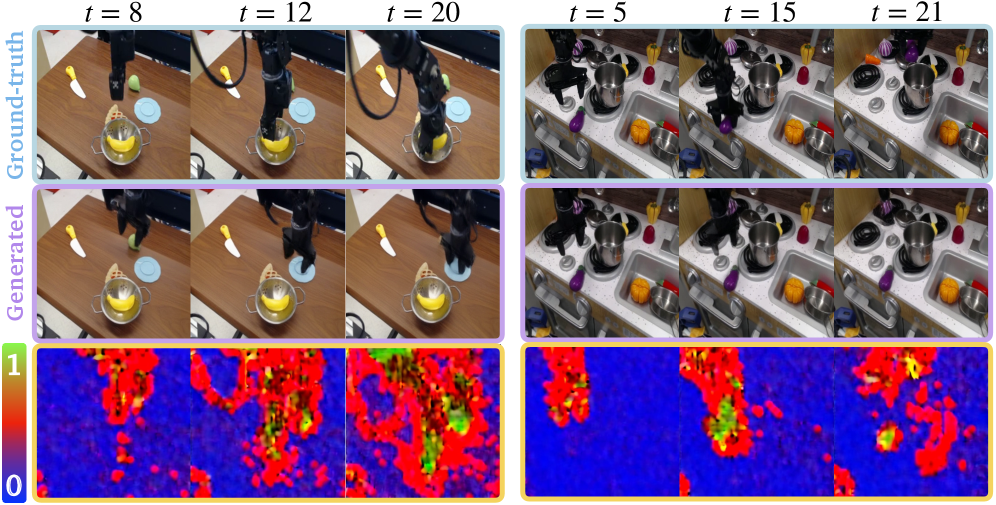
Метод C3C3 обеспечивает плотное предсказание достоверности (confidence prediction) на уровне субпатчей, что позволяет оценить неопределенность для каждого сгенерированного кадра видео. В отличие от подходов, оценивающих достоверность только для всего изображения или отдельных объектов, C3C3 предоставляет карту достоверности, где каждому субпатчу присваивается значение, отражающее уверенность модели в корректности сгенерированного содержимого в данной области. Это позволяет выявлять потенциально проблемные участки кадра и предоставлять более детальную информацию о надежности генерируемого видеопотока, что особенно важно при экстраполяции за пределы обучающих данных.
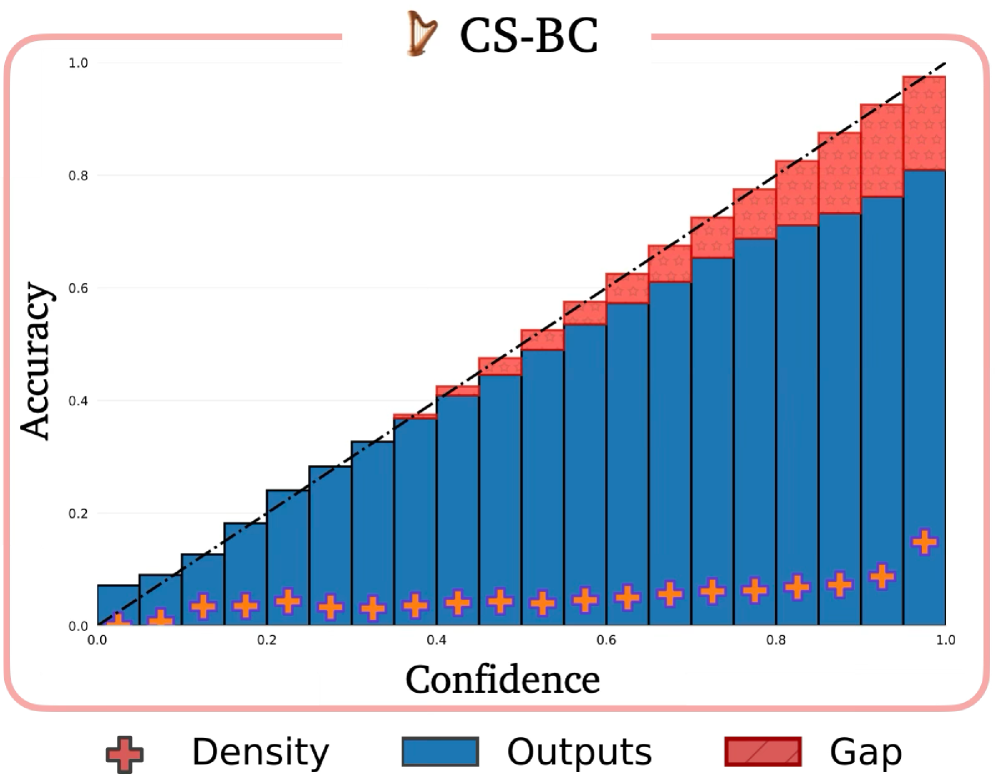
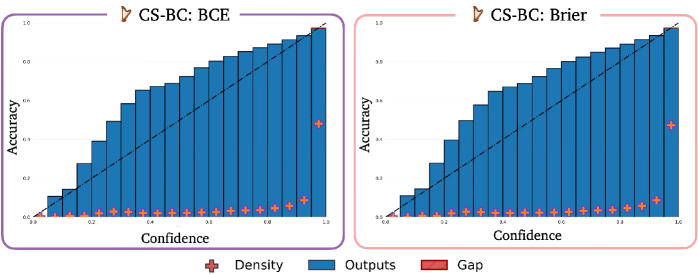
Функциональность оценки надежности генерируемых видео в C3C3 усилена за счет применения методов обнаружения данных, выходящих за пределы области обучения (OOD Detection). Эти методы позволяют модели идентифицировать и сигнализировать о потенциально недостоверных результатах, возникающих при генерации контента, существенно отличающегося от данных, использованных при обучении. Основой для реализации данной возможности является калибровка модели, обеспечивающая соответствие между предсказанной уверенностью и фактической точностью. Калибровка гарантирует, что предсказания с высокой уверенностью действительно являются более точными, а предсказания с низкой уверенностью указывают на повышенный риск ошибки.
При оценке работы модели $C3C3$ на наборе данных DROID были получены следующие результаты: ожидаемая ошибка калибровки (ECE) составила $7.28e-2$, а максимальная ошибка калибровки (MCE) — $1.74e-1$. Эти показатели демонстрируют, что предсказания уверенности модели хорошо откалиброваны, то есть вероятность, которую модель присваивает своим предсказаниям, соответствует фактической точности этих предсказаний. Низкие значения ECE и MCE указывают на надежность оценки уверенности, что является важным критерием для безопасного и ответственного использования модели генерации видео.
Точная оценка достоверности генерируемых видеоданных является критически важным аспектом для обеспечения безопасного и ответственного внедрения технологий генерации видео. Неспособность модели адекватно оценить свою уверенность в сгенерированном контенте может привести к распространению недостоверной или вводящей в заблуждение информации, особенно в ситуациях, когда модель сталкивается с данными, выходящими за рамки ее обучающей выборки. Разработка и применение методов, позволяющих количественно оценить и сигнализировать об уровне неопределенности в каждом сгенерированном кадре, необходимо для выявления потенциально ненадежных результатов и предотвращения их использования в критически важных приложениях, таких как автономное вождение или медицинская диагностика. Таким образом, надежная оценка достоверности становится неотъемлемой частью системы контроля качества и обеспечения безопасности при развертывании моделей генерации видео.
Калибровка уверенности: Обеспечение надежных предсказаний
Калибровка играет ключевую роль в создании надежных моделей машинного обучения, обеспечивая соответствие между прогнозируемой уверенностью и фактической точностью. Без калибровки модель может выдавать прогнозы с высокой уверенностью, которые, однако, оказываются неверными, что приводит к ошибочным решениям и снижению доверия к системе. Иными словами, калиброванная модель не только предсказывает результат, но и оценивает степень своей уверенности в этом предсказании, что позволяет пользователю или другой системе адекватно оценить надежность полученной информации. Особенно важно это в критических приложениях, где последствия неверных прогнозов могут быть серьезными, например, в медицине или автономном вождении. Поэтому, разработка методов калибровки является неотъемлемой частью построения действительно интеллектуальных и заслуживающих доверия систем.
Для обеспечения достоверности прогнозов и предотвращения излишней самоуверенности моделей, применяются так называемые “правильные оценочные правила” (Proper Scoring Rules). Эти правила, в частности, $Brier Score$, предоставляют строгий математический каркас для обучения моделей, позволяя им генерировать не просто прогнозы, но и соответствующие оценки достоверности этих прогнозов. Принцип их работы заключается в том, что модель штрафуется не только за неверный прогноз, но и за чрезмерно уверенную, но ошибочную оценку вероятности. Таким образом, обучение с использованием подобных правил стимулирует модель к более реалистичной и откалиброванной выдаче вероятностей, что критически важно для принятия обоснованных решений на основе машинного обучения.
Интеграция Diffusion Transformers с архитектурой C3C3 позволяет создавать не только визуально привлекательные видеоматериалы, но и видео, сопровождаемые надежно оцененной степенью неопределенности. В отличие от традиционных подходов, где фокус делается исключительно на качестве изображения, данная система способна количественно оценить, насколько достоверным является сгенерированное видео, предоставляя информацию об уверенности модели в каждом кадре. Это достигается благодаря применению методов калибровки, которые гарантируют соответствие между предсказанной уверенностью и фактической точностью, что критически важно для применения в областях, требующих высокой надежности и прозрачности, таких как автономное вождение или медицинская диагностика. Таким образом, система предоставляет не просто изображение, но и информацию о степени доверия к нему, значительно расширяя возможности применения генеративных моделей.
Исследования показали, что применение диффузионного форсинга приводит к увеличению ожидаемой калибровки ошибок (ECE) до $3.3 \times 10^{-1}$, что свидетельствует о снижении точности оценки уверенности модели. В отличие от этого, обучение модели без использования стоп-градиента демонстрирует лишь незначительное изменение ECE, составляющее $5 \times 10^{-3}$. Данные результаты указывают на то, что метод стоп-градиента оказывает существенное влияние на калибровку модели, позволяя ей более адекватно оценивать свою уверенность в прогнозах, в то время как диффузионное форсирование, при текущих настройках, негативно сказывается на этой характеристике.
Применение метода диффузионного форсинга демонстрирует потенциал для дальнейшего повышения калибровки моделей, что способствует увеличению их надежности. Данный подход позволяет уточнить оценки уверенности, генерируемые системой, приводя к более адекватной связи между предсказанной вероятностью и фактической точностью результата. Исследования показывают, что интеграция диффузионного форсинга не только улучшает калибровку, но и повышает общую устойчивость системы к различным входным данным и условиям, что критически важно для приложений, требующих высокой степени надежности и предсказуемости, например, в задачах принятия решений и автоматического анализа.
Исследование демонстрирует, что надежная генерация видео требует не только способности создавать реалистичные последовательности, но и умения оценивать собственную уверенность в результате. Модель C3C³, представленная в работе, подобна биологической системе, способной самооценивать точность своих прогнозов. Как отмечал Эндрю Ын: «Иногда лучшее, что можно сделать, — это признать, что ты чего-то не знаешь.» Эта цитата прекрасно отражает суть подхода, представленного в статье, где калибровка неопределенности позволяет модели сигнализировать о случаях, когда генерация может быть неточной, обеспечивая тем самым более надежный и контролируемый процесс синтеза видео. Понимание этой неопределенности является ключевым шагом к созданию действительно интеллектуальных систем.
Куда же это всё ведёт?
Представленная работа, демонстрируя возможность количественной оценки неопределённости в генеративных моделях видео, лишь приоткрывает дверь в сложный мир доверия к искусственному интеллекту. Необходимо признать, что простого предсказания «уверенности» недостаточно. Вопрос заключается не в том, что модель предсказывает, а в том, почему она это делает, и как эта логика соотносится с реальными закономерностями окружающего мира. Попытки достичь «калибровки» — это, по сути, поиск соответствия между субъективной оценкой модели и объективной реальностью, задача, граничащая с философской.
Очевидным направлением дальнейших исследований представляется развитие методов интерпретации этих оценок неопределённости. Способность модели указать на конкретные фрагменты изображения, вызывающие сомнения, — это первый шаг, но необходимо научиться понимать, что именно вызывает эти сомнения: недостаток данных, противоречивость информации или принципиальная невозможность предсказания. В конечном итоге, речь идет о создании моделей, способных не только генерировать видео, но и объяснять свои ошибки.
Следует также помнить, что оценка неопределённости — это лишь инструмент. Его ценность определяется способностью использовать эту информацию для улучшения процесса генерации, повышения устойчивости модели к шумам и, возможно, даже для создания систем, способных к самообучению и самокоррекции. Иначе говоря, необходимо стремиться не просто к количественной оценке, а к качественному пониманию.
Оригинал статьи: https://arxiv.org/pdf/2512.05927.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Ядерный синтез и Искусственный Интеллект: Новый подход к проектированию реакторов
- Надежность ускорителей: от замысла до реализации
- Карта ошибок: Анатомия сбоев больших языковых моделей
- Квантовые нейросети для реалистичной 3D-визуализации
- Понимание видео: новый вызов для искусственного интеллекта
- Оптимизация запросов: Новый подход для сложных рабочих процессов
- Искусственный интеллект, действующий по цели: эволюция архитектуры
- Шум и как он мешает квантовым вычислениям
- Молекулярный интеллект: Искусственный разум на службе биологии
- Квантовый щит для искусственного интеллекта
2025-12-08 18:44