Автор: Денис Аветисян
Новый комплексный инструмент позволяет оценить устойчивость мультимодальных искусственных интеллектов к обходу защитных механизмов и вредоносным запросам.
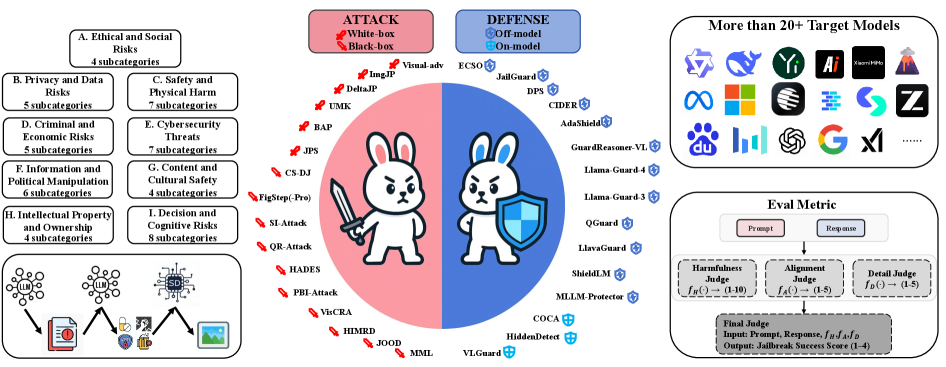
Представлен OmniSafeBench-MM — унифицированный набор данных, инструментов для атак и защиты, а также протокол многомерной оценки безопасности мультимодальных больших языковых моделей.
Несмотря на значительные успехи в разработке мультимодальных больших языковых моделей, их уязвимость к обходу механизмов безопасности и провоцированию вредоносного поведения остается серьезной проблемой. В данной работе представлена платформа ‘OmniSafeBench-MM: A Unified Benchmark and Toolbox for Multimodal Jailbreak Attack-Defense Evaluation’ — комплексный инструмент для оценки безопасности таких моделей от атак, использующих различные модальности. Платформа включает в себя разнообразный набор атак, стратегий защиты и детальную классификацию рисков, что позволяет проводить стандартизированную и всестороннюю оценку. Способна ли эта унифицированная платформа стать основой для разработки более надежных и безопасных мультимодальных систем искусственного интеллекта?
Угроза нарастает: Уязвимость MLLM к атакам обхода ограничений
Мультимодальные большие языковые модели (MLLM) демонстрируют впечатляющий прогресс в обработке информации, объединяя текстовые и визуальные данные для выполнения сложных задач. Однако, наряду с возрастающей мощностью, возникает и уязвимость к так называемым «атакам обхода ограничений» — методам, направленным на преодоление встроенных механизмов безопасности. Эти атаки используют тонкие манипуляции с входными данными, сочетая текст и изображения, чтобы заставить модель генерировать контент, который обычно был бы заблокирован из-за его потенциальной опасности или нежелательности. Успешные атаки демонстрируют, что даже самые передовые MLLM могут быть обмануты, что подчеркивает необходимость разработки более надежных и устойчивых систем защиты от несанкционированного использования и потенциального вреда.
Многомодальные большие языковые модели (MLLM) оказываются уязвимыми перед атаками, обходящими встроенные механизмы безопасности. Исследования показывают, что злоумышленники используют особенности обработки информации, поступающей как в текстовом, так и в визуальном формате, чтобы заставить модель генерировать контент, который в обычных условиях был бы заблокирован. В частности, продемонстрировано, что в отношении Gemini-2.5 подобные атаки достигают высокой эффективности — с вероятностью успеха более 50.7%. Это указывает на существенный риск неконтролируемого создания и распространения вредоносных материалов, а также подчеркивает необходимость разработки более надежных методов защиты для многомодальных систем искусственного интеллекта.

Дифференциация Атак: Подходы «Белого Ящика» и «Черного Ящика»
Атаки, направленные на обход ограничений многомодальных больших языковых моделей (MLLM), классифицируются по уровню доступа к их внутреннему устройству на два основных типа: атаки “белого ящика” и “черного ящика”. Атаки “белого ящика” предполагают знание внутренней архитектуры и параметров модели, что позволяет злоумышленнику целенаправленно конструировать входные данные, способные обойти защитные механизмы. В отличие от них, атаки “черного ящика” не требуют доступа к внутренним компонентам MLLM; они основаны на наблюдении выходных данных модели в ответ на различные входные стимулы и использовании методов проб и ошибок для выявления уязвимостей. Различие в доступе к внутренним данным определяет стратегии, используемые в каждом типе атак, и влияет на их сложность и эффективность.
Атаки на многомодальные большие языковые модели (MLLM) классифицируются по уровню доступа к внутренним механизмам модели. В случае атак «белого ящика», таких как Visual-Adv и ImgJP, злоумышленник обладает информацией о структуре и параметрах модели, что позволяет целенаправленно создавать входные данные, приводящие к нежелательному поведению. В отличие от этого, атаки «черного ящика», например, FigStep, не требуют знания внутренней структуры модели. Они основаны на отправке различных входных данных и анализе выходных результатов, что представляет собой процесс проб и ошибок для выявления уязвимостей и обхода защитных механизмов.
Межмодальные атаки представляют собой сложный класс атак «черного ящика», использующих взаимодействие между изображениями и текстом для обхода систем защиты. В отличие от атак, воздействующих только на один тип входных данных, межмодальные атаки манипулируют как визуальным, так и текстовым контентом, стремясь вызвать желаемое, несанкционированное поведение от мультимодальной большой языковой модели (MLLM). Такие атаки могут включать добавление едва заметных изменений в изображение, сопровождаемых специально сформулированным текстовым запросом, или наоборот — изменение текстового описания изображения для обхода фильтров безопасности. Эффективность межмодальных атак обусловлена тем, что они эксплуатируют уязвимости в механизмах согласования и интерпретации данных между различными модальностями в MLLM, что затрудняет их обнаружение и предотвращение традиционными методами защиты.
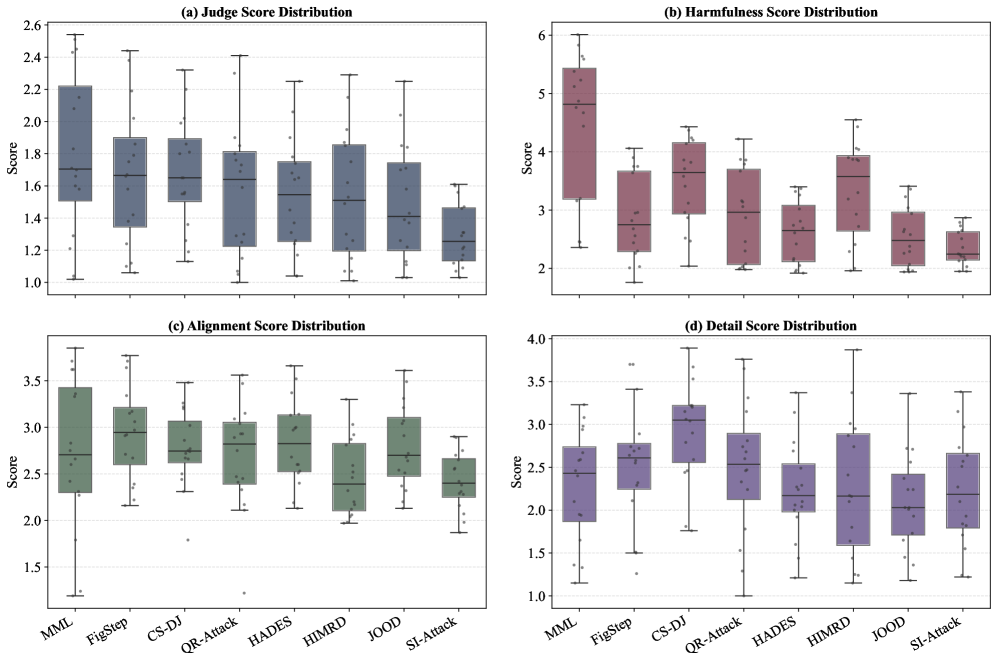
Стандартизация Оценки Безопасности: Представляем OmniSafeBench-MM
Для всесторонней оценки безопасности многомодальных больших языковых моделей (MLLM) необходим стандартизированный набор тестов, способный оценить их устойчивость к разнообразным атакам. Отсутствие единого критерия оценки затрудняет объективное сравнение различных моделей и методов защиты. Существующие подходы часто фокусируются только на успешности атаки (Attack Success Rate), игнорируя другие важные аспекты безопасности, такие как вредоносность генерируемого контента, соответствие ответам заданным инструкциям и детализация предоставляемой информации. Стандартизированный набор тестов позволяет проводить систематическую оценку уязвимостей MLLM перед различными типами атак, выявлять слабые места и оценивать эффективность применяемых защитных механизмов.
OmniSafeBench-MM представляет собой унифицированную платформу, объединяющую наборы данных, векторы атак и методы защиты для всесторонней оценки безопасности мультимодальных больших языковых моделей (MLLM). Ключевой особенностью является трехмерный протокол оценки безопасности, включающий метрики “Вредность” (Harmfulness), оценивающую потенциальный негативный эффект от генерируемого контента; “Соответствие” (Alignment), определяющее соответствие ответов заданным этическим принципам и инструкциям; и “Детализация” (Detail), измеряющую информативность и полноту ответа. Такая структура позволяет проводить комплексный анализ, выявляя слабые места MLLM и сравнивая эффективность различных стратегий защиты в условиях разнообразных угроз.
OmniSafeBench-MM предоставляет возможность проведения строгих сравнительных тестов различных механизмов защиты, включая защиты, реализуемые непосредственно в модели, такие как CoCa. Оценка уязвимостей многомодальных больших языковых моделей (MLLM) осуществляется не только на основе показателя успешности атак (Attack Success Rate — ASR), но и с использованием метрик Harmfulness (вредность), Alignment (соответствие) и Detail (детальность). Примечательно, что средние значения оценки Detail, как правило, не превышают 2.6, что обуславливает повышенные требования к безопасности и строгость критериев оценки в рамках данного бенчмарка.
Расширение Поверхности Атак: UMK и За Его Пределами
Несмотря на внедрение надежных систем защиты, поверхность атак многомодальных больших языковых моделей (MLLM) остается обширной. Исследования, подобные атаке UMK, наглядно демонстрируют возможность сложной межмодальной манипуляции, когда злоумышленник может влиять на поведение модели, используя специально подобранные комбинации текста и изображений. Эта уязвимость подчеркивает, что даже хорошо защищенные системы могут быть обмануты, если атака использует взаимодействие между различными типами входных данных. В отличие от традиционных атак, ориентированных на текстовые данные, межмодальные манипуляции эксплуатируют особенности обработки информации разными модальностями, создавая новые векторы для атак и требуя разработки принципиально новых методов защиты.
Постоянное развитие методов атак на многомодальные большие языковые модели (MLLM) требует непрерывных исследований и усовершенствования как стратегий нападения, так и методов защиты. Простое реагирование на существующие уязвимости недостаточно, поскольку злоумышленники оперативно адаптируются и разрабатывают новые, более изощренные подходы. Необходимы проактивные исследования, направленные на предвидение потенциальных векторов атак и разработку надежных контрмер, включая новые архитектуры моделей, методы обучения и системы обнаружения угроз. Эффективная защита требует не только устранения известных уязвимостей, но и постоянного поиска новых способов манипулирования моделями и разработки соответствующих защитных механизмов, что делает эту область динамичной и требующей постоянного внимания со стороны исследователей и разработчиков.
Понимание уязвимостей многомодальных больших языковых моделей (MLLM) является ключевым фактором для их ответственной разработки и внедрения. Тщательный анализ потенциальных рисков позволяет предотвратить злоупотребления, которые могут привести к нежелательным последствиям в различных сферах жизни. Необходимо учитывать, что MLLM способны генерировать контент, влияющий на общественное мнение, принимать решения в автоматизированных системах и даже управлять критически важной инфраструктурой. Игнорирование уязвимостей может привести к распространению дезинформации, манипуляциям, нарушениям конфиденциальности и другим негативным явлениям. Поэтому, глубокое понимание этих недостатков и разработка эффективных механизмов защиты необходимы для обеспечения того, чтобы MLLM приносили пользу обществу, а не представляли угрозу.

Исследование, представленное в данной работе, демонстрирует стремление к созданию строгой и всесторонней системы оценки безопасности многомодальных больших языковых моделей. Авторы подчеркивают необходимость стандартизации процесса выявления уязвимостей к «jailbreak» атакам, что особенно актуально в контексте растущей сложности и многогранности современных ИИ-систем. Как однажды заметила Грейс Хоппер: «Лучший способ предсказать будущее — это создать его». Данный подход к разработке OmniSafeBench-MM не просто диагностирует существующие недостатки, но и активно формирует более безопасное и надежное будущее для многомодальных моделей, предлагая четкий протокол оценки и инструменты для разработки эффективных защитных механизмов. Стремление к созданию доказуемой безопасности, а не полагание на эмпирические тесты, отражает математическую чистоту, которой стремится данное исследование.
Что дальше?
Представленная работа, хотя и представляет собой значительный шаг к стандартизации оценки безопасности многомодальных больших языковых моделей, лишь обнажает глубину нерешенных проблем. Достижение “безопасности” — это не просто накопление защитных механизмов, а фундаментальное понимание того, как модели интерпретируют и реагируют на сложные запросы, особенно когда информация поступает из различных модальностей. Существующие метрики, несомненно, полезны, но они склонны к упрощению, игнорируя нюансы контекста и потенциальные непредвиденные последствия.
Будущие исследования должны сосредоточиться на разработке формальных методов верификации, позволяющих доказать корректность защитных механизмов, а не просто эмпирически подтверждать их эффективность на ограниченном наборе тестов. Крайне важно уйти от принципа «работает на тестах» к принципу «доказуемо корректно». Более того, необходимо учитывать, что атаки неизбежно будут развиваться, и любые защитные меры, основанные на эвристиках, обречены на временность.
В конечном счете, истинный прогресс в этой области потребует не только технических инноваций, но и философского переосмысления понятия «безопасность» в контексте искусственного интеллекта. Стремление к абсолютной безопасности — это иллюзия; гораздо более разумно стремиться к созданию систем, которые способны обнаруживать и смягчать риски, а не пытаться их полностью устранить. Элегантность решения заключается в его минималистичности и математической чистоте, а не в сложности и избыточности.
Оригинал статьи: https://arxiv.org/pdf/2512.06589.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Карта ошибок: Анатомия сбоев больших языковых моделей
- Ядерный синтез и Искусственный Интеллект: Новый подход к проектированию реакторов
- Надежность ускорителей: от замысла до реализации
- Квантовые нейросети для реалистичной 3D-визуализации
- Мощное моделирование жидкости: новый подход к методу решетчатых уравнений Больцмана
- Нейросеть предсказывает сродство антител к COVID-19
- Память как у живого мозга: новый подход к локальному AI
- Искусственный интеллект на службе материалов: от открытий до инноваций
- Кто несет ответственность за ИИ: новый взгляд на причинно-следственные связи
- Квантовый транспорт в сложных системах: новый подход к моделированию
2025-12-09 21:42