Автор: Денис Аветисян
Новый метод позволяет создавать высококачественную замену лиц в видео, сохраняя естественность и плавность картинки даже в длинных роликах.

Исследование представляет LivingSwap — систему для замены лиц, использующую референсные видео, ключевые кадры и диффузионные модели для достижения высокой реалистичности и временной согласованности.
Несмотря на значительный прогресс в области видеофейковых технологий, сохранение реалистичности и временной согласованности при замене лица в длинных видео остается сложной задачей. В работе, озаглавленной ‘Preserving Source Video Realism: High-Fidelity Face Swapping for Cinematic Quality’, представлена новая методика LivingSwap, использующая референсные видео и ключевые кадры для высококачественной замены лица. Данный подход позволяет добиться бесшовной интеграции целевого лица, сохраняя при этом оригинальные выражения, освещение и движение исходного видео. Возможно ли дальнейшее развитие LivingSwap для автоматизации и упрощения сложных процессов видеопроизводства, требующих высокой степени реализма?
Пределы Существующих Техник Замены Лиц
Традиционные методы замены лиц, основанные на генеративно-состязательных сетях (GAN), часто сталкиваются с проблемой обеспечения временной согласованности в видеоматериалах. Это означает, что при замене лица в последовательности кадров, полученное видео может содержать заметные артефакты и несоответствия, такие как внезапные изменения освещения, неестественные движения или искажения черт лица, переходящие от кадра к кадру. Причина кроется в том, что GAN-модели, как правило, обрабатывают каждый кадр независимо, не учитывая динамику и взаимосвязь между ними. В результате, даже если отдельный кадр выглядит реалистично, последовательность кадров может восприниматься как неестественная и прерывистая, что снижает общее качество и достоверность сгенерированного видео. Такие недостатки существенно ограничивают применение GAN в задачах, требующих высокой степени реализма и плавности, например, при создании реалистичных дипфейков или в кинематографе.
Несмотря на значительное улучшение качества генерации видео с помощью диффузионных моделей, существующие подходы часто сталкиваются с ограничениями в детализации. В частности, для управления процессом реконструкции лица обычно используются лишь небольшое количество опорных точек — так называемые ключевые точки лицевых ориентиров. Такое разреженное условие, хотя и позволяет в целом сохранить структуру лица, препятствует воссозданию тонких деталей, таких как текстура кожи, мимические морщины или индивидуальные особенности. В результате, сгенерированное изображение может выглядеть размытым или неестественным, требуя дополнительной ручной доработки для достижения реалистичного результата. Более плотное и информативное управление процессом диффузии представляется ключевым фактором для преодоления этих ограничений и получения высококачественных видео с реалистичной заменой лиц.
Существующие методы замены лиц зачастую требуют значительных вычислительных ресурсов, что ограничивает их применение в реальных условиях и делает процесс трудоемким. Сложные сцены, например, с изменяющимся освещением или частичной окклюзией лица, представляют особую проблему для большинства алгоритмов, приводя к артефактам и нереалистичным результатам. Это влечет за собой необходимость существенной ручной постобработки и корректировки, увеличивая временные и финансовые затраты. В отличие от этого, предлагаемое решение направлено на оптимизацию вычислительной эффективности и повышение устойчивости к сложным сценариям, минимизируя потребность в ручном вмешательстве и обеспечивая более плавный и реалистичный результат.

LivingSwap: Руководящая Видео-Замена Лиц
В LivingSwap реализован новый подход к генерации на основе руководящего видео, который использует исходное видео непосредственно в качестве входных данных для реконструкции с высокой точностью. В отличие от традиционных методов, требующих промежуточной обработки или создания дополнительных данных, система напрямую использует временную и пространственную информацию из исходного видео. Это позволяет значительно повысить реалистичность и детализацию реконструируемого видео, сохраняя динамику и особенности оригинала. Использование исходного видео в качестве прямого входа позволяет системе учитывать сложные зависимости между кадрами, что критически важно для достижения высокого качества реконструкции и снижения артефактов.
В основе LivingSwap лежит архитектура Diffusion Transformer (DiT), представляющая собой расширение диффузионных моделей на базе UNet. В DiT добавлены мощные трансформаторные блоки, которые обеспечивают более гибкое моделирование данных по сравнению со стандартными UNet. Данная интеграция позволяет системе эффективно обрабатывать сложные зависимости во временных последовательностях видео, улучшая качество реконструкции и обеспечивая более реалистичный результат обмена лицами. Трансформаторы позволяют моделировать глобальные зависимости между кадрами, что особенно важно для поддержания консистентности и естественности видео.
Система LivingSwap использует VAE (Variational Autoencoder) энкодер для эффективного представления видеоданных в латентном пространстве. Это позволяет значительно снизить вычислительные затраты и ускорить обработку видеоматериалов. В результате, применение VAE энкодера сокращает объем ручной постобработки в 40 раз по сравнению с традиционными методами, что существенно повышает производительность и экономит время специалистов, работающих с видео.
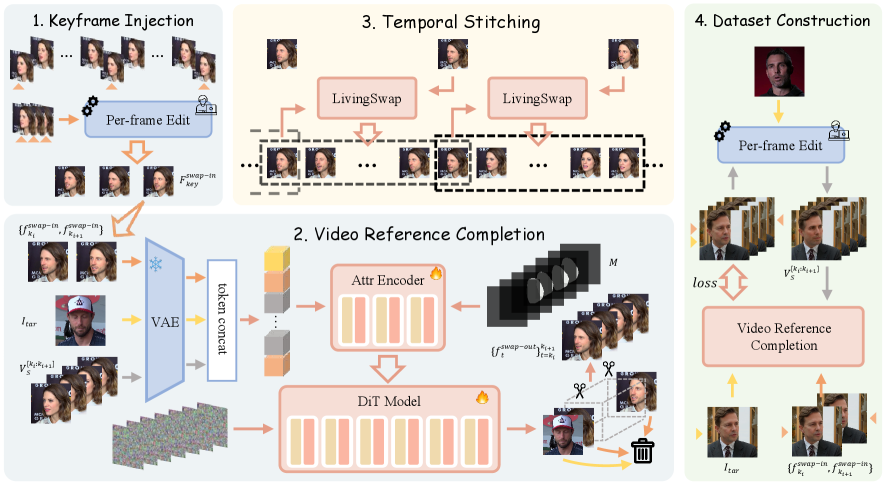
Ключевые Техники в LivingSwap: Сохранение Верности
Для обеспечения сохранения идентичности на протяжении длинных видеопоследовательностей, LivingSwap использует метод Keyframe Identity Injection. Данная технология предполагает введение ключевых кадров, содержащих информацию об исходном облике объекта, непосредственно в процесс генерации новых кадров. Это позволяет системе поддерживать визуальную консистентность и избегать резких изменений внешности объекта на протяжении всего видео, даже при значительных изменениях позы или освещения. Внедрение информации о ключевых кадрах осуществляется на ранних этапах процесса диффузии, что обеспечивает более точное и стабильное представление идентичности объекта в результирующем видеопотоке.
Для достижения реалистичной реконструкции видео, LivingSwap использует метод завершения видео-ссылок (Video Reference Completion). Этот метод напрямую использует детали исходного видео в качестве основы для генерации новых кадров. Вместо создания контента с нуля, система идентифицирует релевантные фрагменты из исходного видео и интегрирует их в реконструированное изображение. Это позволяет сохранять визуальную консистентность и повышает степень реализма результирующего видео, поскольку новые кадры базируются на фактических деталях, присутствующих в исходном материале. Процесс подразумевает анализ исходного видео для выявления и использования текстур, освещения и других визуальных элементов.
В LivingSwap для обеспечения плавных переходов между кадрами и минимизации визуальных артефактов используется техника временной склейки (Temporal Stitching). Этот процесс предполагает аккуратное смешивание соседних отредактированных кадров, с учетом информации о движении и структуре видео. Алгоритм анализирует граничные области каждого кадра и выполняет сглаживание, чтобы избежать резких переходов и обеспечить визуальную непрерывность. Временная склейка особенно важна при работе с длинными видеопоследовательностями, где даже небольшие несоответствия могут привести к заметным визуальным дефектам. Эффективность метода заключается в адаптивном подходе к смешиванию, учитывающем сложность сцены и характер движения объектов.
Атрибутный энкодер в LivingSwap выполняет функцию дополнительной проработки процесса, внедряя информацию об атрибутах в основу диффузионной модели. Это позволяет детализировать и повысить реалистичность реконструируемого видеоматериала за счет учета дополнительных параметров, таких как текстура, освещение и другие визуальные характеристики, что приводит к более качественному и правдоподобному результату. Внедрение атрибутивной информации расширяет возможности диффузионной модели по генерации детализированных и визуально богатых кадров.

Валидация и Сравнительная Эффективность
Система LivingSwap подверглась всесторонней оценке с использованием CineFaceBench — сложного набора данных, предназначенного для реалистичного тестирования алгоритмов замены лиц в видео. Этот набор включает в себя 152 221 видеофрагмент, в общей сложности превышающий 300 часов видеоматериала. Использование столь обширного и разнообразного набора данных позволило тщательно проверить способность системы генерировать правдоподобные и высококачественные результаты в различных сценариях, что является ключевым для оценки эффективности алгоритмов замены лиц в реальных условиях.
Система LivingSwap продемонстрировала превосходство над существующими методами, основанными на заполнении пропусков, такими как HiFiVFS и FaceAdapter. В ходе всесторонних испытаний на бенчмарке CineFaceBench, включающем более 300 часов видеоматериала, LivingSwap достигла более высокой точности и реалистичности генерируемых изображений. Особенно заметно улучшение в передаче мельчайших деталей и естественности движений, что позволило системе установить новый стандарт в области видео-фейс-свопинга и занять лидирующие позиции по результатам тестирования на CineFaceBench. Это свидетельствует о значительном прогрессе в создании правдоподобных и визуально безупречных видеороликов с измененными лицами.
Для обучения системы LivingSwap использовался специально разработанный парный набор данных Face2Face, предназначенный для высококачественного обмена лицами в видеоматериале. Этот набор данных обеспечивает точное соответствие между исходным и целевым лицами, что критически важно для реалистичного результата. Кроме того, для генерации ключевых кадров, определяющих последовательность изменений лица, была задействована система Inswapper. Такое сочетание специализированного набора данных и эффективной системы генерации ключевых кадров позволило добиться значительного улучшения качества и стабильности процесса обмена лицами в видео.
Применение Rectified Flow (RF) в качестве целевой функции при обучении позволило значительно улучшить качество генерируемого видео. В отличие от традиционных подходов, ориентированных на дискретные кадры, Rectified Flow рассматривает видео как непрерывный поток, что позволяет более точно моделировать динамику движения и изменения лица. Эта методика учитывает оптический поток между кадрами, обеспечивая плавные и реалистичные переходы, минимизируя визуальные артефакты и дрожание. Использование RF в качестве функции потерь способствует более стабильному и когерентному во времени синтезу видео, что особенно важно для сложных сцен и динамичных выражений лица, обеспечивая более высокую степень фотореализма и визуального комфорта для зрителя.

Исследование, представленное в статье, фокусируется на достижении реалистичной замены лиц в видео, что требует строгой последовательности во времени и высокой точности деталей. Данная работа стремится воспроизвести закономерности естественного движения и мимики, что является сложной задачей, требующей глубокого понимания визуальных данных. Как однажды заметил Ян Лекун: «Машинное обучение — это искусство создания алгоритмов, которые могут учиться на данных». Эта фраза отражает суть подхода LivingSwap, который использует диффузионные модели и ключевые кадры для обучения алгоритма генерации реалистичных замен лиц. Если закономерность нельзя воспроизвести или объяснить, её не существует — и LivingSwap демонстрирует впечатляющую способность воспроизводить сложные визуальные закономерности в видео.
Куда же это всё ведёт?
Представленная работа, безусловно, демонстрирует значительный прогресс в области видео-фейс-свопинга, но, как и любое приближение к иллюзии реальности, обнажает новые грани нерешенных проблем. Хотя достигнута впечатляющая временная согласованность и сохранение деталей, вопрос о полной неразличимости сгенерированного видео от оригинала остается открытым. В конечном счете, визуальные данные — это лишь проекция, и всегда найдется наблюдатель, способный уловить тончайшие несоответствия.
Перспективы развития очевидны: дальнейшее углубление в архитектуры диффузионных моделей, возможно, с использованием более сложных механизмов внимания, позволит преодолеть текущие ограничения в обработке динамичных сцен и сложных выражений лица. Интересно исследовать возможности интеграции с технологиями нейро-рендеринга для достижения фотореалистичного качества. Однако, необходимо помнить, что технологический прогресс сам по себе не гарантирует этического использования; вопросы аутентичности и манипуляции информацией требуют постоянного внимания.
В конечном счете, задача не в том, чтобы создать идеальную иллюзию, а в том, чтобы понять, что именно делает реальность реальной. Каждое новое изображение — это вызов для понимания, а не просто входная модель. И в этом заключается парадокс: чем ближе мы подходим к созданию иллюзии, тем острее осознаём хрупкость и субъективность восприятия.
Оригинал статьи: https://arxiv.org/pdf/2512.07951.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Ядерный синтез и Искусственный Интеллект: Новый подход к проектированию реакторов
- Карта ошибок: Анатомия сбоев больших языковых моделей
- Надежность ускорителей: от замысла до реализации
- Квантовые нейросети для реалистичной 3D-визуализации
- Диагностика заболеваний печени: новый подход с использованием искусственного интеллекта
- Квантовые точки и литий танталат: новый путь к фотонным микросхемам
- Квантовый скачок или технологический тупик? Анализ новостей о квантовых технологиях
- Шёпот хаоса в унифицированном представлении: Ming-Flash-Omni и алхимия мульмодальности.
- Распознавание антинуклеарных антител: обучение на собственном темпе
- Упорядоченный разум: Как языковые модели учатся справляться с длинными текстами
2025-12-10 11:06