Автор: Денис Аветисян
Новая схема квантовых вычислений на основе фотонных процессоров значительно ускоряет задачи классификации изображений, требуя при этом меньше данных для обучения.

Экспериментальная реализация квантового резервуарного вычисления с использованием бозонной выборки демонстрирует перспективные результаты в ускорении машинного обучения.
Несмотря на широкое применение машинного обучения, его потенциал в использовании квантовых ресурсов остается нереализованным. В работе «Photonic Quantum-Accelerated Machine Learning» представлен квантовый ускоритель для классических алгоритмов, использующий бозонную выборку для создания высокоразмерного квантового «отпечатка» в задаче резервуарного вычисления. Показано, что предложенная схема значительно ускоряет классификацию изображений, требуя при этом в двадцать раз меньше обучающих данных, что подтверждено экспериментально на квантовом фотонном процессоре. Открывает ли это путь к созданию квантовых алгоритмов машинного обучения, превосходящих классические аналоги в задачах обработки данных?
Пределы Классических Алгоритмов и Обещание Квантового Машинного Обучения
Традиционные алгоритмы машинного обучения, несмотря на свою эффективность в решении широкого спектра задач, сталкиваются с существенными ограничениями при работе с данными высокой размерности и сложностью. Проблема заключается в том, что количество необходимых вычислений для обработки таких данных экспоненциально возрастает с увеличением их объема, что приводит к замедлению обучения и увеличению вычислительных затрат. Например, при анализе изображений высокого разрешения или геномных данных, количество параметров, которые необходимо оценить, может достигать астрономических величин. Это создает серьезные препятствия для применения классических методов в таких областях, как обработка естественного языка, компьютерное зрение и анализ больших данных, где требуется выявление тонких закономерностей в сложных структурах. В результате, поиск новых подходов, способных эффективно обрабатывать и анализировать такие данные, становится критически важной задачей.
Квантовое машинное обучение (КМО) представляет собой перспективный подход к преодолению ограничений, присущих классическим алгоритмам, особенно при работе со сложными и многомерными данными. В основе КМО лежит использование уникальных квантовых явлений, таких как суперпозиция и запутанность. Суперпозиция позволяет квантовым битам, или кубитам, одновременно представлять 0 и 1, значительно расширяя вычислительные возможности по сравнению с классическими битами. Запутанность, в свою очередь, создает корреляцию между кубитами, позволяя им действовать согласованно даже на больших расстояниях. Использование этих явлений позволяет КМО потенциально решать задачи, недоступные для классических алгоритмов, например, в области распознавания образов, анализа данных и оптимизации, открывая новые горизонты в сфере искусственного интеллекта и машинного обучения.
Исследование архитектур квантового машинного обучения (КМО) является ключевым для решения задач, требующих экспоненциального ускорения вычислений или улучшения способности к обобщению данных. Традиционные алгоритмы часто сталкиваются с трудностями при обработке огромных объемов информации и выявлении сложных закономерностей. КМО, используя принципы квантовой суперпозиции и запутанности, потенциально способно преодолеть эти ограничения. Разработка новых квантовых схем и оптимизация существующих архитектур, таких как квантовые нейронные сети и квантовые машины опорных векторов, позволяет надеяться на значительное повышение эффективности в таких областях, как распознавание образов, анализ данных и моделирование сложных систем. Особенно перспективным представляется применение КМО в задачах, где классические алгоритмы требуют неприемлемо больших вычислительных ресурсов, например, при решении $NP$-полных задач или при обработке данных высокой размерности.
Квантовые Резервуарные Вычисления: Новый Подход к Обработке Информации
Вычислительное резервуарное моделирование (Reservoir Computing, RC) представляет собой разновидность рекуррентных нейронных сетей, характеризующуюся высокой эффективностью и простотой реализации. В отличие от традиционных рекуррентных сетей, где веса всех соединений обучаются, в RC только выходные веса подлежат обучению, а внутренние веса “резервуара” фиксированы и случайным образом инициализируются. Такой подход значительно снижает вычислительную сложность обучения и позволяет обрабатывать временные ряды и сложные данные с меньшими затратами ресурсов. Архитектура RC состоит из трех основных компонентов: входного слоя, динамичного “резервуара”, состоящего из рекуррентно связанных нейронов, и выходного слоя, преобразующего состояние резервуара в желаемый выходной сигнал. Простота обучения и способность эффективно работать с нелинейными данными делают RC привлекательным решением для различных задач, включая распознавание речи, прогнозирование временных рядов и обработку сигналов.
Квантовые вычисления резервуара (QRC) представляют собой расширение подхода вычислений резервуаром (RC), в котором в качестве “резервуара” используются квантовые системы. В отличие от классических RC, использующих динамику нелинейных систем, QRC использует принципы квантовой механики, такие как суперпозиция и запутанность, для создания высокоразмерного, динамичного состояния, которое служит основой для обработки информации. Потенциальное увеличение вычислительной мощности связано с экспоненциальным ростом гильбертова пространства, доступного для квантовых систем, что позволяет QRC эффективно обрабатывать и классифицировать сложные данные, особенно в задачах, где классические методы оказываются неэффективными. Использование квантовых систем в качестве резервуара позволяет потенциально реализовать более компактные и энергоэффективные вычислительные решения.
Квантовые вычисления резервуаров (QRC) позволяют обрабатывать сложные данные, используя естественную динамику квантовых систем, что значительно снижает потребность в трудоемком обучении. В отличие от традиционных нейронных сетей, требующих настройки весов для каждой задачи, QRC использует фиксированный, нетренируемый квантовый «резервуар». Входные данные отображаются на состояние этого резервуара, а затем считываются с помощью небольшого, легко обучаемого выходного слоя. Этот подход позволяет эффективно решать задачи классификации, прогнозирования временных рядов и распознавания образов, используя преимущества квантовой суперпозиции и запутанности для обработки информации без необходимости в масштабном процессе обучения, характерном для классических методов машинного обучения.
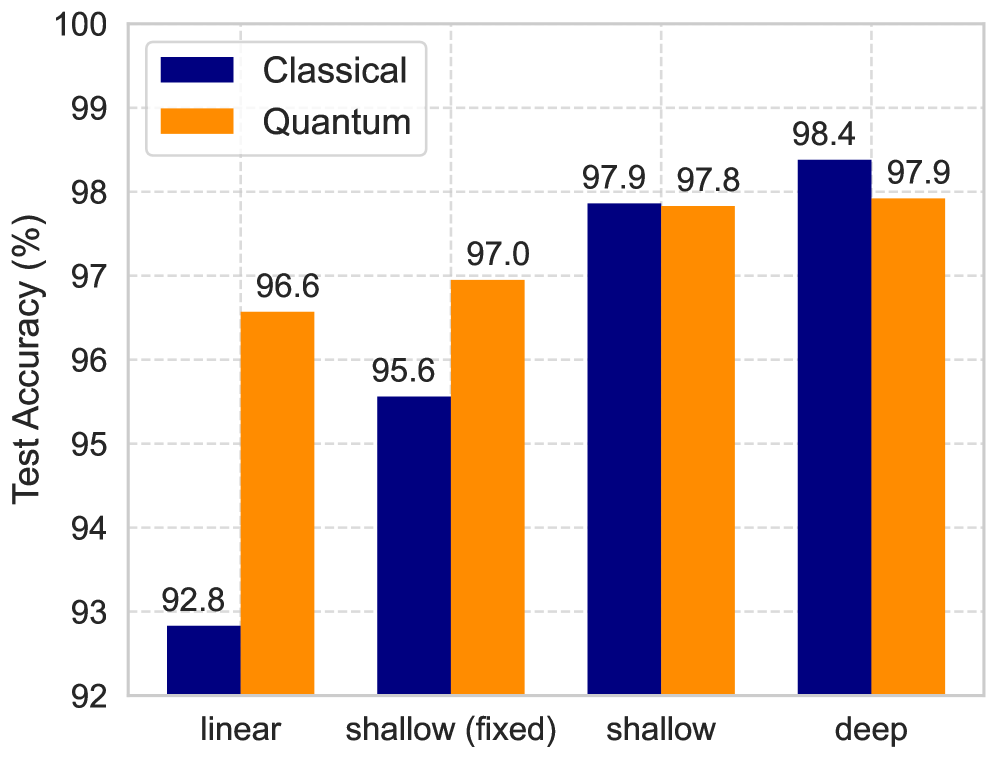
Реализация и Валидация: Квантово-Оптический Подход
Квантово-оптическое резервуарное вычисление (Quantum Optical Reservoir Computing) использует принципы квантовой оптики для создания резервуара, в котором обработка данных осуществляется посредством фотонных схем. В данной реализации входные данные кодируются в оптические сигналы, которые затем взаимодействуют с нелинейными оптическими элементами, формирующими высокоразмерное пространство состояний — резервуар. Выходные данные считываются из резервуара посредством линейных измерений, и полученные векторы признаков используются для решения задач классификации или регрессии. Использование фотонных схем обеспечивает высокую скорость обработки и возможность параллельной обработки данных, что является ключевым преимуществом данного подхода.
Реализация квантового оптического вычисления резервуара критически зависит от использования фундаментальных квантовых свойств. Неразличимость фотонов позволяет эффективно кодировать и обрабатывать информацию, используя суперпозицию состояний. Разрешение по числу фотонов обеспечивает точное определение количества фотонов в каждом состоянии, что необходимо для линейных вычислений. Подавление событий с множественными фотонами снижает шум и ошибки, возникающие из-за нелинейных взаимодействий, и гарантирует надежность вычислений. Эти свойства в совокупности обеспечивают высокую точность и эффективность обработки данных в квантовой системе.
Оценка производительности системы осуществлялась с использованием наборов данных MNIST, DIGITS и MedMNISTv2. В качестве метрики оценки применялся Macro F1 Score, обеспечивающий надежную оценку качества классификации. Результаты демонстрируют потенциальную возможность снижения количества обучающих изображений до 20 раз по сравнению с классическими линейными классификаторами, что указывает на повышенную эффективность и сниженные требования к объему данных для обучения.
Система демонстрирует общую эффективность, превышающую 90%, что указывает на высокую производительность преобразования входных данных. Согласно прогнозам, данная технология может быть внедрена в передовые коммерческие системы в течение 5 лет. Коэффициент пропускания (ηt) системы варьируется в диапазоне от 0.22 до 3.04%, что отражает долю фотонов, успешно прошедших через систему и участвующих в вычислениях. Данные показатели эффективности и пропускания являются ключевыми для оценки практической применимости и масштабируемости квантического оптического подхода к вычислениям.
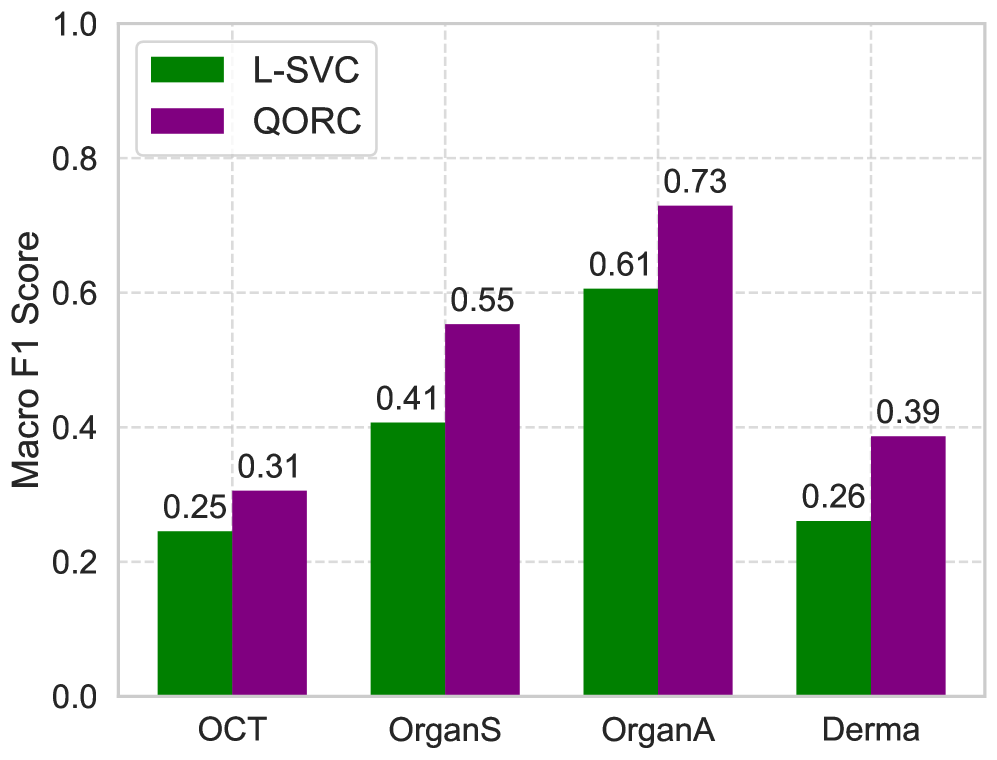
Улучшение Производительности: Оптимизация и Классическая Интеграция
Для повышения эффективности и снижения вычислительной сложности в системе QRC применяются методы классического машинного обучения, в частности, анализ главных компонент (PCA). Данный подход позволяет предварительно обработать данные, уменьшив их размерность без существенной потери информации. PCA выявляет наиболее значимые признаки в данных, проецируя их на пространство меньшей размерности, что не только ускоряет последующие вычисления, но и способствует снижению вероятности переобучения модели. В результате, система QRC получает более компактное и информативное представление данных, что положительно сказывается на скорости обучения и обобщающей способности, позволяя добиться лучших результатов при классификации и решении других задач.
Для точной настройки классических компонентов квантово-классической системы (QRC) используются современные фреймворки оптимизации гиперпараметров, такие как KerasTuner. Этот подход позволяет автоматически подбирать оптимальные значения параметров классических алгоритмов, например, количества слоев или нейронов в нейронных сетях, что существенно влияет на общую производительность системы. В ходе работы KerasTuner исследует различные комбинации гиперпараметров, используя методы, основанные на Bayesian optimization или Random Search, для минимизации целевой функции — в данном случае, ошибки классификации. Автоматизация процесса настройки значительно упрощает и ускоряет разработку QRC систем, позволяя добиться максимальной эффективности без необходимости ручного подбора параметров и длительных экспериментов.
Интеграция квантовых и классических ресурсов является ключевым фактором для достижения оптимальной производительности и масштабируемости в приложениях квантово-расчетных классификаторов (QRC). Проведенные численные моделирования и экспериментальные исследования демонстрируют высокую степень согласованности между результатами, о чем свидетельствует статистика Колмогорова-Смирнова (KS) равная $0.072 \pm 0.028$ и соответствующее значение p, равное $0.65 \pm 0.31$. Эти показатели подтверждают, что распределения, полученные с помощью квантово-классического подхода, статистически не отличаются от результатов, предсказанных моделью, что указывает на надежность и эффективность предложенной схемы интеграции. Таким образом, сочетание преимуществ квантовых вычислений с проверенными методами классической обработки данных открывает новые возможности для решения сложных задач классификации.
В ходе исследований было продемонстрировано, что разработанный подход позволяет добиться повышения точности тестирования до 20% по сравнению с базовыми классификаторами в ряде специфических сценариев. Данное улучшение достигается благодаря синергии между квантовыми и классическими алгоритмами, позволяющей более эффективно извлекать информацию из данных и строить более точные модели. В частности, в задачах, где требуется выделение сложных признаков или работа с зашумленными данными, предложенный метод демонстрирует значительное преимущество, открывая перспективы для его применения в различных областях, включая распознавание образов и анализ данных.
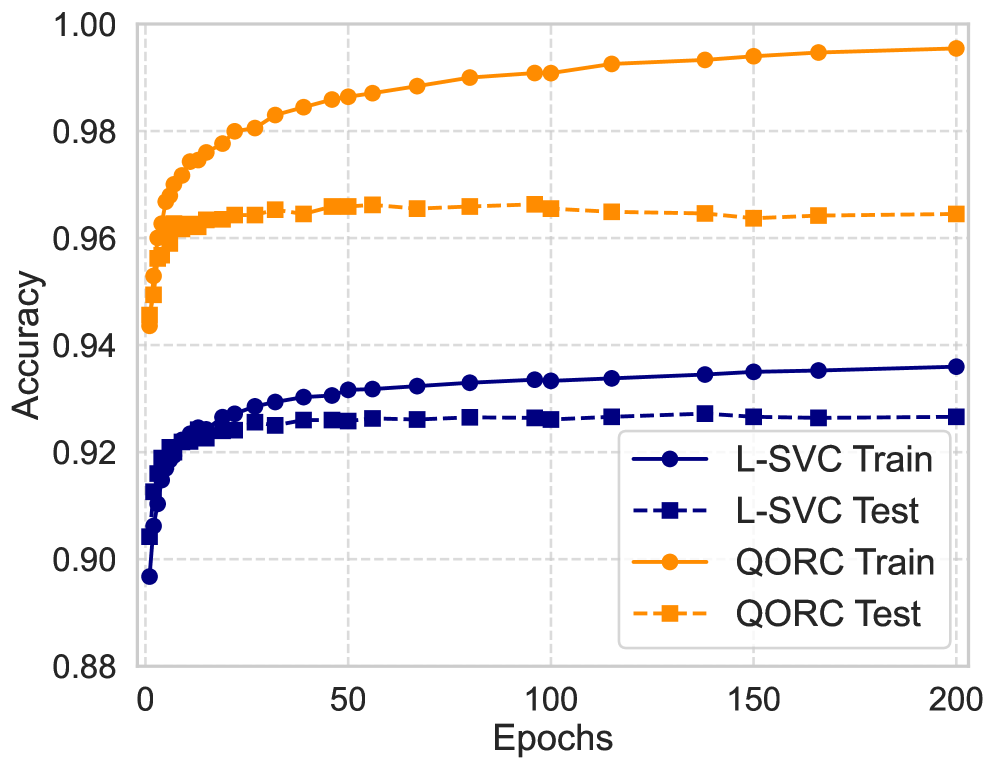
Исследование демонстрирует, что квантовое ускорение машинного обучения, основанное на резервуарных вычислениях и бозонной выборке, позволяет достичь значительных преимуществ в классификации изображений при меньшем объеме обучающих данных. Этот подход, верифицированный экспериментально на квантовом фотонном процессоре, подчеркивает важность поиска фундаментальных принципов, которые остаются устойчивыми при стремлении к бесконечности вычислительной сложности. Как однажды заметил Макс Планк: «Пусть N стремится к бесконечности — что останется устойчивым?». В данном контексте, устойчивость проявляется в способности квантовой системы эффективно обрабатывать информацию даже при увеличении сложности решаемой задачи, что открывает новые перспективы для развития алгоритмов машинного обучения.
Что дальше?
Представленная работа, несомненно, демонстрирует потенциал квантовых оптических резервуарных вычислений для ускорения задач классификации изображений. Однако, следует помнить, что ускорение, подтвержденное на ограниченном наборе данных и конкретной архитектуре, не является доказательством универсального квантового преимущества. Необходимо более строгое исследование масштабируемости предложенной схемы и ее устойчивости к шумам, которые неизбежно возникают в реальных квантовых системах.
Особенно важно обратить внимание на проблему выбора оптимальной функции потерь и алгоритма обучения. Простое сокращение количества требуемых обучающих изображений не является самоцелью, если это достигается за счет снижения точности классификации или увеличения вычислительной сложности обучения. Оптимизация без анализа — это самообман и ловушка для неосторожного разработчика. Следующим шагом видится разработка более элегантных и математически обоснованных методов обучения квантовых резервуарных компьютеров.
В конечном счете, истинная ценность данной работы заключается не в достигнутом ускорении, а в постановке принципиально новых вопросов. Достаточно ли простого уменьшения объема данных для обучения, или необходимо переосмыслить саму парадигму машинного обучения, чтобы в полной мере использовать возможности квантовых вычислений? Ответ на этот вопрос, вероятно, потребует не только дальнейших экспериментов, но и глубоких теоретических исследований.
Оригинал статьи: https://arxiv.org/pdf/2512.08318.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Надежность ускорителей: от замысла до реализации
- Карта ошибок: Анатомия сбоев больших языковых моделей
- Квантовые нейросети для реалистичной 3D-визуализации
- Искусственный интеллект, действующий по цели: эволюция архитектуры
- Нейросеть предсказывает сродство антител к COVID-19
- Накапливая опыт: мультимодальные агенты, которые учатся на ходу
- Понимание видео: новый вызов для искусственного интеллекта
- От основ к интеллекту: как объединить машинное обучение и большие языковые модели
- Квантовые сети под контролем: новая библиотека для моделирования гибридных схем
- Визуальная навигация по множеству изображений: новый подход с использованием больших языковых моделей
2025-12-10 14:51