Автор: Денис Аветисян
Ученые разработали метод, позволяющий создавать реалистичные 3D-модели тела человека на основе видеозаписи, без необходимости предварительного обучения нейронной сети.
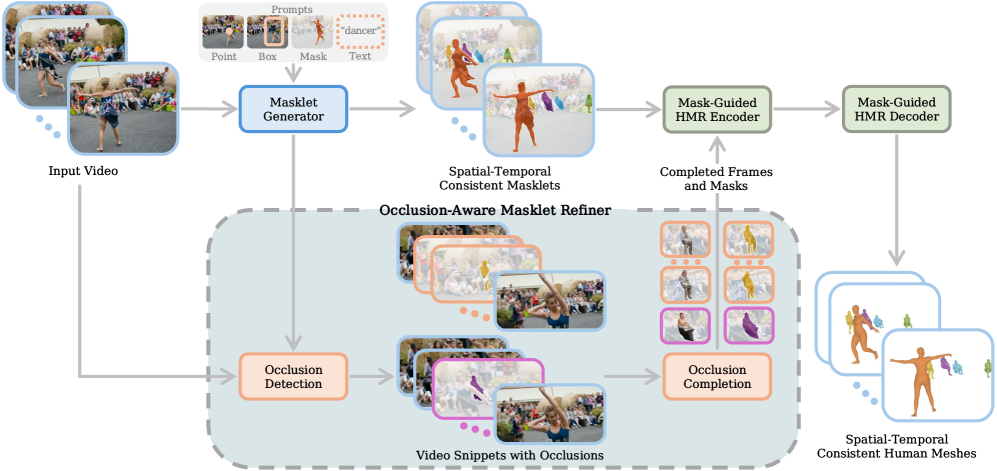
Представлен SAM-Body4D — фреймворк, использующий масклеты и алгоритмы для обеспечения временной согласованности и устойчивости 3D-реконструкции, даже при наличии перекрытий.
Восстановление трехмерной модели человеческого тела из видео остается сложной задачей, особенно при наличии перекрытий и быстро меняющихся поз. В данной работе представлена система SAM-Body4D: Training-Free 4D Human Body Mesh Recovery from Videos, предлагающая новый подход к решению этой проблемы без необходимости дополнительного обучения. Ключевой особенностью является использование масок (masklets) для отслеживания непрерывности пикселей и алгоритма уточнения, устойчивого к перекрытиям, что позволяет получать согласованные и робастные траектории трехмерных моделей. Не откроет ли это новые возможности для анализа движений человека и создания реалистичных виртуальных аватаров?
Трудности согласованности: Почему трехмерная реконструкция человека всё ещё далека от идеала
Восстановление трехмерной модели человеческого тела (HMR) играет ключевую роль в таких передовых областях, как дополненная и виртуальная реальность, а также в системах захвата движения. Однако, существующие методы сталкиваются с серьезными трудностями в поддержании временной согласованности между кадрами видеозаписи. Это проявляется в виде неестественной «дрожи» или нереалистичных движений, особенно в сложных ситуациях, когда часть тела временно скрыта или когда движение происходит с высокой скоростью. Неспособность обеспечить плавный и логичный переход между кадрами значительно снижает реалистичность и достоверность получаемых данных, ограничивая возможности применения HMR в требовательных приложениях.
Существующие методы оценки трехмерной позы человека зачастую демонстрируют неустойчивость и нереалистичность движений, особенно в сложных ситуациях. Проблема усугубляется при частичной видимости объекта, когда части тела оказываются скрыты другими объектами или сами собой, а также при быстрых движениях, когда алгоритмам сложно отследить плавный переход между кадрами. Это проявляется в виде заметного «дрожания» или неестественных рывков в реконструируемой анимации, что значительно снижает качество и достоверность данных, необходимых для приложений виртуальной и дополненной реальности, а также систем захвата движений. Подобные артефакты возникают из-за трудностей в поддержании согласованности между последовательными кадрами видео, что требует разработки новых подходов к отслеживанию и моделированию человеческих движений.
Для обеспечения устойчивой временной согласованности в задачах оценки позы человека, необходимо эффективно распространять информацию между последовательными кадрами видео, при этом учитывая неизбежные неоднозначности. Существующие методы часто сталкиваются с трудностями, когда видимость тела частично или полностью заблокирована, или когда движения происходят с высокой скоростью. В таких ситуациях, простое продолжение предыдущей позы может привести к неестественным или нереалистичным движениям. Поэтому, современные подходы стремятся разработать механизмы, позволяющие оценивать вероятность различных возможных поз в каждом кадре, учитывая как визуальные данные, так и кинематические ограничения человеческого тела. Успешная реализация таких механизмов требует сложного баланса между точностью оценки текущей позы и поддержанием плавности и реалистичности движения во времени, что является ключевой задачей в области компьютерного зрения и анимации.
Несмотря на то, что методы видео-сегментации объектов (VOS) демонстрируют высокую эффективность в отслеживании идентичности объектов на видео, их прямое применение к задаче оценки трехмерной позы человека сталкивается со значительными трудностями. В отличие от VOS, где необходимо лишь определить границы объекта, реконструкция трехмерной позы требует восстановления сложной структуры тела в пространстве, включая положение каждой части конечности и сустава. Простое отслеживание контуров недостаточно для преодоления неоднозначностей, возникающих при самопересечениях конечностей, окклюзиях и быстрых движениях. Таким образом, существующие алгоритмы VOS, разработанные для более простых задач сегментации, не способны эффективно справляться со сложностью и многообразием возможных конфигураций человеческого тела, что требует разработки специализированных подходов к обеспечению временной согласованности в оценке трехмерной позы.

SAM-Body4D: Элегантное решение проблемы временной согласованности
SAM-Body4D представляет собой безыскусную (не требующую обучения) систему для обеспечения временной согласованности в задачах Human Mesh Recovery (HMR). В основе подхода лежит использование “масклетов” — предложений масок, сохраняющих идентичность объекта (в данном случае, человека) — на протяжении последовательности видеокадров. Это позволяет системе отслеживать позу человека во времени, поддерживая её консистентность и избегая резких скачков или изменений, которые могут возникнуть при обработке каждого кадра независимо. Использование масклетов обеспечивает начальную точку для отслеживания, а последующие этапы системы уточняют эти маски и соответствующие оценки позы.
В основе системы SAM-Body4D лежит генератор масок (Masklet Generator), построенный на базе модели SAM 3. Этот генератор создает начальные маски, называемые «масклетами», которые представляют собой предложения, идентифицирующие положение тела человека в видеокадре. Использование SAM 3 позволяет получать высококачественные и точные маски, что является основой для последующего отслеживания и обеспечения временной согласованности оценки позы. Созданные масклеты служат отправной точкой для алгоритма Mask-Guided HMR, обеспечивая надежную инициализацию и снижая вычислительную сложность процесса.
В основе повышения эффективности SAM-Body4D лежит параллельная стратегия обработки на основе добавления отступов (Padding-based Parallel Strategy). Вместо последовательной обработки каждого кадра и каждого человека в видео, система обрабатывает несколько кадров и людей одновременно, используя добавленные отступы для обеспечения единообразия размера входных данных. Это позволяет значительно сократить время вычислений, обеспечивая ускорение в 2 раза по сравнению с традиционными методами последовательного HMR (Human Mesh Recovery). Такой подход особенно важен при обработке видеопотоков с большим количеством людей или высоким разрешением, где время обработки является критическим параметром.
Для обеспечения соответствия оцениваемой позы визуальной информации в каждом кадре, SAM-Body4D использует процесс Mask-Guided HMR (Human Mesh Recovery). Этот процесс уточняет исходные масклеты, полученные от Masklet Generator, посредством применения маски к результатам HMR. Фактически, маска выступает в качестве пространственного фильтра, ограничивающего область поиска и уточнения позы только теми пикселями, которые соответствуют обнаруженному человеку. Это позволяет снизить влияние шумов и неоднозначностей, повышая точность и стабильность оценки позы, особенно в сложных сценах или при наличии окклюзий. Уточнение позы на основе маски осуществляется итеративно, с последовательным улучшением соответствия между визуальными данными и реконструируемой 3D-моделью человека.

Устранение окклюзий: Как SAM-Body4D «видит» сквозь препятствия
SAM-Body4D использует модуль восстановления масок — Occlusion-Aware Masklet Refiner — для решения проблемы окклюзий. Этот модуль предназначен для восстановления недостающих областей в маскетах, что позволяет более точно определять границы тела и его частей, даже если они частично скрыты. Восстановление происходит путем анализа существующих пикселей маски и интеллектуального заполнения пропущенных фрагментов, что повышает надежность и точность оценки позы человека.
Для интеллектуального заполнения областей, скрытых из-за окклюзий, в SAM-Body4D используется Diffusion-VAS (Diffusion-Variational Autoencoder for Scene understanding). Diffusion-VAS представляет собой генеративную модель, обученную на данных о человеческих позах, которая позволяет восстанавливать недостающие части масклетов (masklets) на основе контекста видимых областей. Этот подход обеспечивает более точное и правдоподобное заполнение окклюдированных участков, улучшая качество и полноту масклетов и, следовательно, повышая надежность оценки позы.
Процесс уточнения маски при окклюзиях активируется при снижении значения Intersection over Union (IoU) ниже порога в 0.7. IoU, представляющий собой отношение площади пересечения предсказанной и истинной маски к площади их объединения, служит метрикой оценки степени перекрытия. Значение ниже 0.7 указывает на существенную окклюзию, когда большая часть объекта скрыта, что требует активации механизма восстановления маски для повышения точности оценки позы.
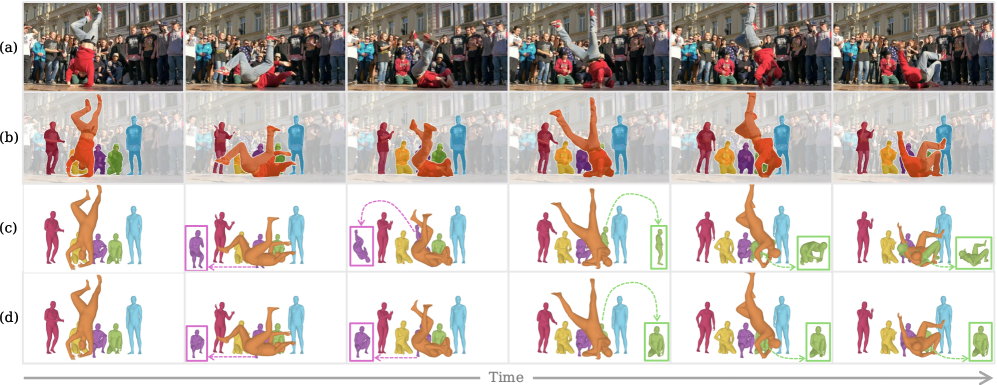
Эффективная обработка зон окклюзии в SAM-Body4D значительно повышает устойчивость и согласованность оценки позы, особенно в сложных сценариях. Устранение пропущенных участков масок позволяет более точно определять положение тела даже при частичной видимости, что критически важно для приложений, требующих надежной работы в условиях зашумленности или неполных данных. Повышенная устойчивость к окклюзиям достигается за счет использования Diffusion-VAS для интеллектуального заполнения скрытых областей, что минимизирует ошибки в определении позы и обеспечивает более предсказуемые результаты.
Взгляд в будущее: Потенциал и перспективы SAM-Body4D
Разработанная система SAM-Body4D представляет собой логичное развитие архитектуры SAM 3D Body, значительно расширяющее её функциональные возможности в контексте обработки видеоматериалов и обеспечения временной согласованности. В отличие от предшественников, новая платформа позволяет создавать реалистичные и плавные трехмерные модели человеческого тела не только на отдельных кадрах, но и в динамичных видеопоследовательностях. Достигается это за счет усовершенствованных алгоритмов отслеживания и экстраполяции движения, которые гарантируют, что воссоздаваемая модель сохраняет свою форму и положение во времени, избегая резких скачков или деформаций. Данный подход открывает новые перспективы для приложений, требующих точного и непрерывного представления человеческого тела в видео, таких как анализ движений, создание виртуальной реальности и разработка интерактивных развлекательных систем.
В отличие от существующих методов обеспечения временной согласованности, таких как VIBE и TRAM, SAM-Body4D выделяется своим подходом, не требующим предварительного обучения на больших объемах данных. Это значительно снижает вычислительные затраты и упрощает внедрение системы в различных приложениях. Традиционные методы часто нуждаются в обширных наборах данных с разметкой, что является трудоемким и дорогостоящим процессом. SAM-Body4D, напротив, позволяет достичь высокой точности и стабильности отслеживания движений человека во времени, используя лишь текущий кадр видео, что делает его более эффективным и доступным решением для широкого круга пользователей и разработчиков.
Ключевым преимуществом SAM-Body4D является его способность сохранять идентичность объекта на протяжении всей видеопоследовательности. Эта особенность имеет решающее значение для широкого спектра приложений, особенно в области захвата движения и дополненной/виртуальной реальности (AR/VR). В системах захвата движения постоянство идентификации позволяет точно отслеживать позы и движения человека во времени, избегая нежелательных скачков или искажений. В AR/VR, где реалистичное наложение виртуальных объектов на реальный мир имеет первостепенное значение, поддержание визуальной непрерывности персонажа является критически важным для создания иммерсивного и убедительного опыта. Без надежного отслеживания идентичности, виртуальный аватар может визуально «прыгать» или меняться, разрушая иллюзию присутствия и снижая общее качество взаимодействия.
Перспективы развития системы SAM-Body4D тесно связаны с её интеграцией в более сложные системы восприятия. Исследования направлены на объединение возможностей точного отслеживания тела в видео с алгоритмами обнаружения объектов и понимания сцены. Такое сочетание позволит не только восстанавливать трёхмерную позу человека, но и анализировать взаимодействие между человеком и окружающей средой, создавая основу для интеллектуальных приложений. Например, в робототехнике это позволит роботам более эффективно ориентироваться в пространстве и взаимодействовать с людьми, а в сферах дополненной и виртуальной реальности — создавать более реалистичные и контекстно-зависимые взаимодействия. Разработка подобных комплексных систем открывает путь к созданию действительно «умных» приложений, способных понимать и реагировать на сложные ситуации с участием человека.
Работа над SAM-Body4D напоминает вечную борьбу с энтропией. Авторы пытаются выжать максимум из существующих моделей, избегая дорогостоящего обучения с нуля. И это закономерно — ведь, как заметил Ян Лекун: «Простота — это высшая форма сложности». В данном случае, кажущаяся простота подхода — отказ от обучения — маскирует сложность реализации темпоральной консистентности и обработки окклюзий. Попытка получить устойчивую 3D-реконструкцию человеческого тела из видеопотока — это всегда компромисс между точностью, скоростью и робастностью. И рано или поздно, любой элегантный алгоритм столкнется с неизбежными артефактами и ошибками, которые предстоит исправлять в продакшене. Впрочем, это и есть суть работы — находить новые способы обхода ограничений и улучшения существующих решений.
Что дальше?
Представленная работа, безусловно, добавляет ещё один слой к бесконечной оптимизации восстановления 3D-мешей из видео. Отказ от обучения — ход, конечно, интересный, но давайте не будем забывать старую истину: каждая «революция» — это лишь новый способ упаковать старые проблемы. Окклюзии, временная согласованность… всё это лишь формулировки. Продакшен найдёт способ завалить систему непредсказуемыми движениями и освещением. Будут новые библиотеки, новые форматы видео, и старые уловки снова перестанут работать.
Очевидно, что фокус сместится на обработку неидеальных данных. Реальные видео — это не идеально освещенные сцены с одним человеком в кадре. Это трясущиеся камеры, плохой свет, несколько людей, перекрывающих друг друга… Вероятно, в ближайшем будущем мы увидим больше работ, направленных на робастное восстановление мешей в условиях, максимально приближенных к реальности. И, конечно, появится новая метрика, чтобы показать, насколько «реалистичной» стала реконструкция.
В конечном итоге, всё новое — это просто старое с худшей документацией. Или, возможно, просто с более сложной зависимостью от конкретной версии CUDA. Впрочем, это лишь детали. Главное, что у исследователей всегда будет работа.
Оригинал статьи: https://arxiv.org/pdf/2512.08406.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Карта ошибок: Анатомия сбоев больших языковых моделей
- Надежность ускорителей: от замысла до реализации
- Квантовые нейросети для реалистичной 3D-визуализации
- Nemotron Nano V2 VL: Зрение и язык в новом формате
- Знания в графах: как улучшить ответы больших языковых моделей
- Аналогии как ключ к генерации изображений
- Молекулярный интеллект: Искусственный разум на службе биологии
- Квантовый щит для искусственного интеллекта
- Оптимизация запросов: Новый подход для сложных рабочих процессов
- Упорядоченный разум: Как языковые модели учатся справляться с длинными текстами
2025-12-10 21:16