Автор: Денис Аветисян
Исследователи представили EcomBench — комплексную платформу для оценки возможностей языковых моделей в решении задач онлайн-торговли.
EcomBench — это новый бенчмарк, предназначенный для всесторонней оценки языковых агентов в реалистичных сценариях электронной коммерции, с акцентом на аутентичность, профессионализм, полноту и динамичность.
Несмотря на значительный прогресс в развитии агентов на основе больших языковых моделей, их оценка в реальных условиях, особенно в динамичных коммерческих сценариях, остается сложной задачей. В настоящей работе представлена EcomBench: Towards Holistic Evaluation of Foundation Agents in E-commerce — новая комплексная платформа для оценки возможностей таких агентов в аутентичных e-commerce средах. EcomBench, основанная на реальных запросах пользователей и тщательно аннотированная экспертами, позволяет оценить ключевые способности агентов, включая глубокий поиск информации, многоступенчатое рассуждение и интеграцию знаний из разных источников. Способна ли эта платформа стать надежным инструментом для разработки и совершенствования интеллектуальных помощников в сфере электронной коммерции?
Понимание ограничений: Разрыв в логических рассуждениях в электронной коммерции
Несмотря на впечатляющую вычислительную мощность, современные большие языковые модели (LLM) испытывают трудности при решении задач, требующих многоступенчатого логического мышления, характерного для электронной коммерции. В отличие от простых запросов, реальные сценарии покупок часто включают в себя понимание скрытых намерений пользователя, сопоставление различных характеристик товаров, учет контекста предыдущих взаимодействий и принятие решений на основе неполной или противоречивой информации. LLM, обученные на больших объемах текстовых данных, часто демонстрируют поверхностное понимание языка, неспособное к глубокому анализу и построению сложных умозаключений, что существенно ограничивает их применение в задачах, требующих не просто выдачи релевантных ответов, а полноценного моделирования когнитивных процессов покупателя.
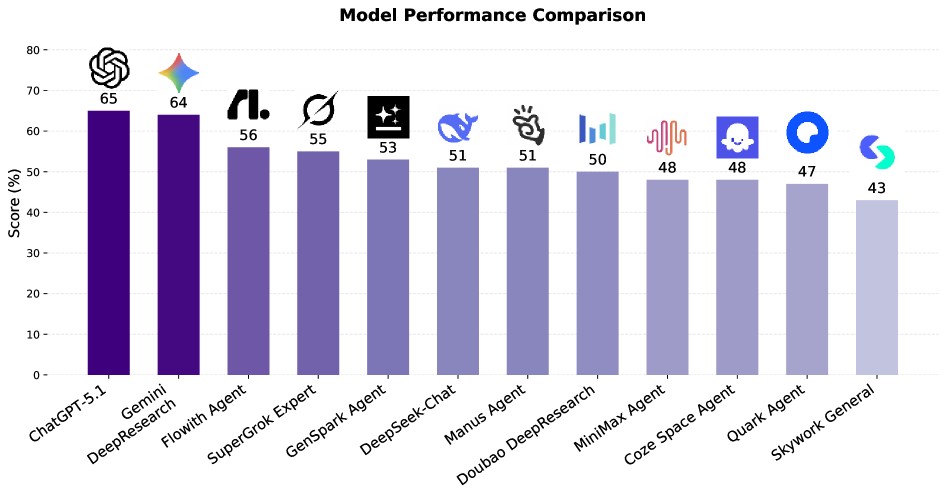
Существующие оценочные тесты для больших языковых моделей (LLM) зачастую не отражают реальную сложность и многогранность взаимодействия пользователей с интернет-магазинами, что приводит к завышенным показателям эффективности. Несмотря на впечатляющие результаты, достигающие 46-90% в зависимости от сложности задачи, эти цифры могут быть обманчивы. Исследования показывают, что модели демонстрируют высокую производительность на упрощенных, лабораторных примерах, но испытывают трудности при обработке неоднозначных запросов, требующих понимания контекста, учета предыдущих действий пользователя и способности к логическому выводу в условиях неполной информации. Такое несоответствие между результатами тестов и реальной производительностью подчеркивает необходимость разработки более аутентичных и сложных бенчмарков, способных адекватно оценивать способность LLM решать практические задачи в сфере электронной коммерции.
EcomBench: Новый стандарт оценки для электронной коммерции
EcomBench — это новый эталон, разработанный для строгой оценки возможностей агентов в аутентичных сценариях электронной коммерции. В отличие от существующих синтетических тестов, EcomBench использует реальные данные о товарах, запросах пользователей и взаимодействиях с платформами онлайн-торговли. Это позволяет оценить способность агентов выполнять сложные задачи, такие как поиск товаров по нечетким запросам, сравнение характеристик, ответы на вопросы о продуктах и обработка различных типов пользовательских намерений в контексте реальных транзакций. Оценка проводится на основе автоматизированных метрик, измеряющих точность, полноту и релевантность ответов агентов, что обеспечивает объективную и воспроизводимую оценку их производительности.
Принципы, лежащие в основе EcomBench — достоверность (Authenticity), профессионализм (Professionalism), всеохватность (Comprehensiveness) и динамичность (Dynamism) — обеспечивают высокую релевантность оцениваемых задач и минимизируют риск загрязнения данных. Достоверность достигается использованием реальных сценариев электронной коммерции, включая аутентичные описания товаров и запросы пользователей. Профессионализм подразумевает оценку ответов агентов с точки зрения соответствия принятым стандартам обслуживания клиентов. Всеохватность охватывает широкий спектр задач, включая поиск товаров, ответы на вопросы, решение проблем и оформление заказов. Динамичность реализуется за счет регулярного обновления данных и сценариев, что предотвращает запоминание ответов и стимулирует развитие действительно интеллектуальных агентов.
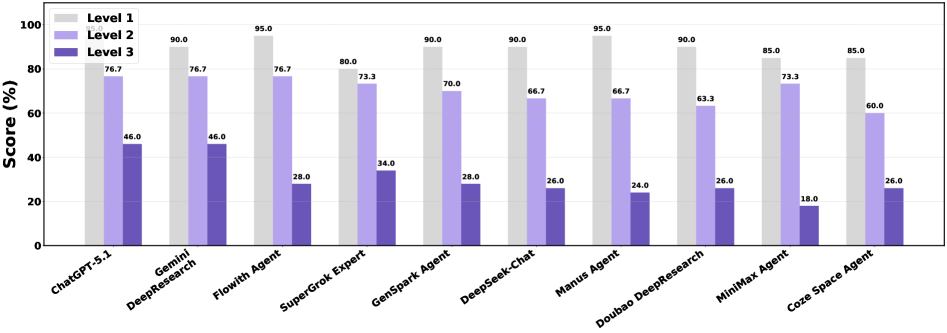
Бенчмарк EcomBench использует многоуровневую систему сложности задач для оценки производительности агентов в различных сценариях. Результаты показывают значительное снижение точности по мере увеличения сложности: модели демонстрируют 80-95% точности на задачах первого уровня, однако для большинства моделей точность опускается ниже 35% на задачах третьего уровня. Такая структура позволяет выявить ограничения существующих моделей в обработке более сложных и реалистичных запросов, характерных для электронной коммерции.

Методология: Обеспечение надежности оценки
В процессе создания EcomBench применяется методология курации данных с участием экспертов (Human-in-the-Loop Data Curation). Это предполагает, что вопросы и задачи, представленные в бенчмарке, не генерируются автоматически, а проходят проверку и доработку со стороны специалистов в области электронной коммерции. Данный подход обеспечивает высокую релевантность и качество задач, отражающих реальные сценарии взаимодействия с интернет-магазинами и специфику предметной области. Эксперты оценивают вопросы на предмет корректности, однозначности и практической значимости, что позволяет исключить нерелевантные или некорректно сформулированные задания и обеспечить надежность оценки производительности моделей.
Иерархия инструментов EcomBench, основанная на больших языковых моделях (LLM), предназначена для отбора сложных задач, требующих от агентов многоступенчатого логического вывода. Эта иерархия структурирована таким образом, чтобы автоматически идентифицировать задачи, которые не могут быть решены простым извлечением информации или прямым сопоставлением, а нуждаются в последовательном применении различных инструментов и логических операций для достижения корректного результата. LLM анализирует сложность задачи и определяет, какие инструменты из доступного набора необходимо использовать и в какой последовательности, чтобы обеспечить успешное выполнение агентом. Такой подход позволяет оценить способность агентов к сложному планированию и решению проблем в контексте электронной коммерции.
Оценка результатов в EcomBench упрощена благодаря системе, основанной на больших языковых моделях (LLM), которая присваивает бинарный балл — 0 или 1 — для определения корректности ответа. Такой подход позволяет значительно ускорить процесс оценки, избегая необходимости в многоступенчатой ручной проверке и субъективных интерпретациях. Система LLM анализирует ответ агента и сравнивает его с эталонным решением, выдавая однозначный результат, что обеспечивает высокую эффективность и масштабируемость оценки качества работы агентов в сложных задачах электронной коммерции.
Расширение границ: Влияние на развитие интеллектуальных агентов
EcomBench представляет собой ключевую платформу для оценки и развития агентных фреймворков, таких как ReAct, позволяя расширить границы возможностей выполнения сложных задач. Эта среда тестирования специально разработана для моделирования реальных сценариев электронной коммерции, требующих от агентов не только понимания запросов, но и способности планировать последовательность действий для достижения поставленной цели. Используя EcomBench, исследователи могут эффективно оценивать способность различных моделей к поиску информации, рассуждению и взаимодействию с внешними инструментами, выявляя слабые места и стимулируя прогресс в области создания действительно автономных и эффективных интеллектуальных агентов, способных решать практические задачи в динамичной среде онлайн-торговли.
Существующие бенчмарки, такие как GPQA и FutureX, представляют собой ценные инструменты для оценки определенных аспектов логического мышления и общих знаний. Однако, они не всегда охватывают специфические сложности, возникающие в реальных коммерческих сценариях. EcomBench призван восполнить этот пробел, предлагая комплексную платформу для тестирования агентов в контексте электронной коммерции. В отличие от общих тестов, EcomBench фокусируется на практических задачах, с которыми сталкиваются пользователи при онлайн-покупках — от поиска конкретного товара до решения проблем с доставкой. Такой подход позволяет более точно оценить способность агентов решать реальные задачи и адаптироваться к динамичной среде электронной коммерции, что делает его важным дополнением к существующим методам оценки.
Строгая оценка, предоставляемая EcomBench, позволяет выявить слабые места в технологиях Retrieval-Augmented Generation и других методах, основанных на больших языковых моделях. Например, такие передовые системы, как ChatGPT-5.1 и Gemini DeepResearch, демонстрируют впечатляющую точность — более 90% — при решении задач первого уровня сложности. Однако, при переходе к задачам третьего уровня, требующим более глубокого понимания контекста и сложных рассуждений, их эффективность существенно снижается, достигая лишь 46%. Этот контраст подчеркивает необходимость дальнейшей оптимизации алгоритмов и моделей для обеспечения стабильно высокого уровня производительности в реальных, сложных сценариях электронной коммерции.
Будущее электронной коммерции: Путь к интеллектуальным системам
Принцип динамичности является ключевым аспектом поддержания актуальности EcomBench. Регулярное обновление вопросов и задач в бенчмарке позволяет отражать постоянно меняющиеся тенденции рынка электронной коммерции и новые вызовы, с которыми сталкиваются AI-агенты. Этот подход гарантирует, что оценка производительности AI не устаревает и остается релевантной для текущих реалий. Благодаря постоянной адаптации к новым продуктам, рекламным акциям и потребительским предпочтениям, EcomBench служит надежным инструментом для отслеживания прогресса в области AI для электронной коммерции и стимулирует разработку более эффективных и приспособляемых агентов, способных успешно функционировать в быстро меняющейся онлайн-среде.
Постоянное совершенствование эталонного набора данных EcomBench, в сочетании с прогрессом в области агентных фреймворков, открывает путь к беспрецедентному уровню автоматизации и персонализации в электронной коммерции. Разработчики стремятся к созданию интеллектуальных агентов, способных не только отвечать на вопросы покупателей, но и предвидеть их потребности, предлагая релевантные товары и услуги в нужный момент. Улучшение EcomBench позволяет более точно оценивать и совершенствовать эти агенты, обеспечивая их адаптацию к постоянно меняющимся требованиям рынка и предпочтениям потребителей. В результате, ожидается значительное повышение эффективности онлайн-покупок, сокращение времени на поиск товаров и увеличение удовлетворенности клиентов благодаря индивидуальному подходу и проактивной помощи.
Разработанный оценочный комплекс служит мощным стимулом для создания искусственных интеллектуальных агентов, способных обеспечить бесперебойную поддержку клиентов на всех этапах совершения покупки. Эти агенты, используя передовые алгоритмы и машинное обучение, могут не только отвечать на вопросы и предоставлять информацию о товарах, но и активно участвовать в процессе выбора, предлагая персонализированные рекомендации, сравнивая альтернативные варианты и даже оформляя заказы от имени пользователя. В перспективе, подобная автоматизация позволит значительно улучшить пользовательский опыт, повысить лояльность клиентов и оптимизировать процессы в сфере электронной коммерции, предоставляя покупателям индивидуальный подход и максимально удобное обслуживание.
Представленный труд демонстрирует стремление к созданию комплексной системы оценки, что находит отклик в словах Дональда Дэвиса: «Простота — высшая степень совершенства». EcomBench, как новый эталон для оценки агентов в электронной коммерции, подчеркивает важность не только функциональности, но и аутентичности, профессионализма и динамичности взаимодействия. Авторы, стремясь к объективной оценке возможностей больших языковых моделей, создают инструмент, который позволяет отсеять избыточность и выявить истинную ценность решения. В конечном итоге, подобный подход к оценке способствует созданию более эффективных и полезных агентов для электронной коммерции, где ясность и точность взаимодействия имеют первостепенное значение.
Что дальше?
Представленная работа, стремясь к всесторонней оценке агентов на базе больших языковых моделей в сфере электронной коммерции, неизбежно обнажает границы применимости существующих метрик. Стремление к «аутентичности», «профессионализму» и «полноте» — благородная цель, но ее реализация, выраженная в числовых оценках, всегда будет упрощением. Каждый комментарий к коду — это признание недоверия к нему, и каждое число — след недоверия к сложности реального взаимодействия. Необходимо признать, что подлинная динамичность, отражающая капризы потребителя и изменчивость рынка, не поддается полной формализации.
Будущие исследования должны сместить фокус с оценки отдельных «способностей» агентов на анализ их способности к адаптации и самокоррекции в условиях неопределенности. Искусственное создание «иерархии инструментов» — лишь временное решение, маскирующее отсутствие глубокого понимания контекста. Совершенство достигается не когда нечего добавить, а когда нечего убрать — когда агент способен к минимально необходимому действию, а не к демонстрации всего спектра возможностей.
Задача заключается не в создании «идеального агента», а в разработке систем, которые признают собственные ограничения и умеют вовремя обратиться за помощью — к человеку или к другим, более специализированным системам. Истинная оценка, следовательно, должна быть направлена на выявление этих границ и обеспечение прозрачности процесса принятия решений, а не на достижение иллюзии всезнания.
Оригинал статьи: https://arxiv.org/pdf/2512.08868.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Карта ошибок: Анатомия сбоев больших языковых моделей
- Надежность ускорителей: от замысла до реализации
- Квантовые нейросети для реалистичной 3D-визуализации
- Искусство синтеза: Новая модель для объединения текста и изображений
- Накапливая опыт: мультимодальные агенты, которые учатся на ходу
- Квантовые Загадки: От Теории к Реальности
- Оптимизация запросов: Новый подход для сложных рабочих процессов
- Диффузия и обучение с подкреплением: новый подход к масштабированию
- Квантовые алгоритмы против нейросетей: есть ли смысл в переходе?
- Диалоги с Искусственным Интеллектом: Как Проверить Надежность?
2025-12-11 05:33