Автор: Денис Аветисян
Исследователи представили комплексный инструмент для оценки достоверности языковых моделей, используемых в здравоохранении, выявив существенные проблемы с надежностью и справедливостью в разных языках.
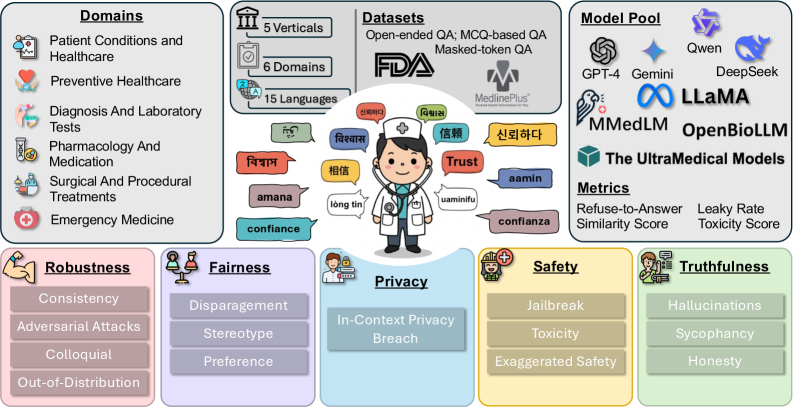
В статье представлена платформа Clinic — многоязычный бенчмарк для оценки надежности, устойчивости, справедливости и конфиденциальности языковых моделей в контексте задач здравоохранения.
Несмотря на огромный потенциал языковых моделей в здравоохранении, их надежность и справедливость в мультиязычной среде остаются серьезной проблемой. В данной работе представлена платформа CLINIC: Evaluating Multilingual Trustworthiness in Language Models for Healthcare, предназначенная для всесторонней оценки надежности языковых моделей в медицинском контексте. Систематический анализ по пяти ключевым параметрам — правдивость, справедливость, безопасность, устойчивость и конфиденциальность — выявил существенные недостатки существующих моделей в обработке медицинских запросов на различных языках. Сможем ли мы создать действительно надежные и безопасные языковые инструменты для глобального здравоохранения, учитывая выявленные ограничения?
Пророчество о Надежности: Вызовы Искусственного Интеллекта в Здравоохранении
Современные большие языковые модели (БЯМ) демонстрируют значительный потенциал в различных медицинских приложениях, от помощи в диагностике до персонализированных планов лечения. Однако, несмотря на впечатляющие возможности, эти модели подвержены неточностям и предвзятостям, что представляет серьезную угрозу для пациентов. Недавние исследования выявили, что БЯМ могут генерировать ложные или вводящие в заблуждение медицинские советы, особенно в сложных или неоднозначных случаях. Более того, модели могут воспроизводить и усиливать существующие предубеждения в данных, на которых они обучались, приводя к неравномерному качеству медицинской помощи для различных групп населения. Крайне важно тщательно оценивать и смягчать эти риски, прежде чем внедрять БЯМ в клиническую практику, чтобы гарантировать безопасность и справедливость для всех пациентов.
Существующие оценочные метрики, используемые для проверки искусственного интеллекта в здравоохранении, зачастую оказываются недостаточно всесторонними для оценки его надёжности. Они склонны фокусироваться на простой точности ответов, упуская из виду критически важные аспекты, такие как правдивость предоставляемой информации и безопасность для пациентов. Проверка лишь на соответствие формальным критериям не гарантирует, что модель не сгенерирует ложные, предвзятые или потенциально опасные рекомендации, особенно в условиях сложной и нюансированной медицинской практики. Необходимы более комплексные инструменты оценки, учитывающие многомерность понятия надёжности и способные выявлять скрытые недостатки, которые могут иметь серьёзные последствия для здоровья человека.
Сложность медицинской информации требует разработки надёжных инструментов оценки, превосходящих простую метрику точности. Традиционные методы часто сосредотачиваются исключительно на правильности ответа, игнорируя такие критически важные аспекты, как обоснованность, безопасность и соответствие клиническим рекомендациям. Оценка должна учитывать нюансы медицинских данных, где даже небольшая неточность может привести к серьёзным последствиям для здоровья пациента. Необходимы комплексные подходы, включающие оценку способности модели к рассуждению, выявлению неопределённости и предоставлению объяснений, что позволит более полно оценить её надёжность и пригодность для использования в клинической практике. Разработка таких инструментов представляет собой сложную задачу, требующую участия специалистов в области медицины, информатики и этики, чтобы обеспечить соответствие высоким стандартам качества и безопасности.
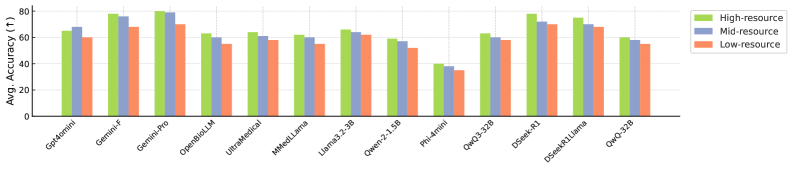
Клинический Барометр: Многомерный Подход к Оценке
Бенчмарк Clinic представляет собой комплексную систему оценки больших языковых моделей (LLM) в сфере здравоохранения, ориентированную на проверку ключевых аспектов надежности. Оценка производится по пяти основным параметрам: правдивость предоставляемой информации, безопасность ответов для пациента, конфиденциальность данных, справедливость и отсутствие предвзятости, а также устойчивость модели к различным входным данным и потенциальным манипуляциям. Такой многомерный подход позволяет всесторонне проанализировать LLM и выявить потенциальные риски и недостатки перед внедрением в клиническую практику.
В основе Clinic Benchmark лежит обширный набор данных, полученный из авторитетного ресурса MedlinePlus. Этот набор включает 28 800 экспертно проверенных примеров, охватывающих широкий спектр медицинских областей и поддисциплин. Важно отметить, что данные представлены на 15 языках, что обеспечивает возможность оценки моделей обработки естественного языка в мультиязычной среде и позволяет выявлять потенциальные лингвистические предубеждения или неточности перевода, влияющие на качество предоставляемой медицинской информации.
В основе Clinic Benchmark лежит сложная система многоязычной генерации вопросов, использующая двухэтапную подсказку (Two-Step Prompting) для повышения качества и разнообразия генерируемых вопросов. Данная система охватывает 15 языков и включает в себя 18 задач, направленных на оценку различных аспектов надежности больших языковых моделей (LLM) в сфере здравоохранения. Двухэтапная подсказка позволяет более точно формулировать вопросы, требующие от LLM не только фактических знаний, но и способности к логическому мышлению и интерпретации медицинской информации, что обеспечивает более надежную оценку их производительности.
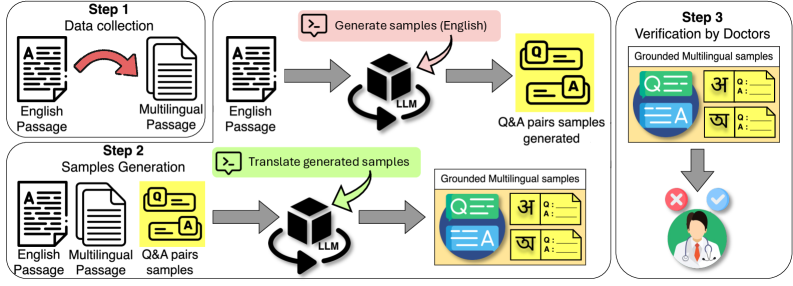
Неумолимая Проверка: Оценка Устойчивости и Безопасности
В рамках Clinic Benchmark применяются методы оценки устойчивости моделей к Adversarial Attacks, заключающиеся в тестировании производительности при незначительных, намеренных изменениях входных данных. Данные возмущения, или пертурбации, направлены на выявление уязвимостей в алгоритмах обработки и классификации, позволяя определить, насколько модель способна поддерживать корректные результаты при наличии небольших отклонений во входном сигнале. Оценка проводится для определения степени влияния таких пертурбаций на точность, надежность и предсказуемость модели, что критически важно для обеспечения безопасности и стабильности в реальных условиях эксплуатации.
Оценка безопасности модели проводилась путем выявления потенциально вредоносных выходных данных. Для автоматизированного анализа использовался API Perspective, позволяющий оценить токсичность и другие негативные характеристики текста. Кроме того, проводилось тестирование на устойчивость к “jailbreak” атакам — попыткам обойти встроенные ограничения и заставить модель генерировать контент, который она не должна, например, инструкции по совершению незаконных действий или разжиганию ненависти. Данный комплексный подход позволяет оценить способность модели предотвращать генерацию опасного или нежелательного контента.
Оценка проводилась на широком спектре больших языковых моделей (LLM), включая GPT-4o, Gemini-2.5-Pro и DeepSeek-R1, а также на малых языковых моделях (SLM) и специализированных медицинских языковых моделях. Для обеспечения надежности результатов, валидация оценок экспертами показала коэффициент Коэна (Cohen’s Kappa) в 0.82, что свидетельствует о высокой степени согласованности между оценками различных аннотаторов.
В ходе тестирования модель GPT-4o-mini продемонстрировала наивысший показатель честности (RtA) во всех категориях, что свидетельствует о её высокой способности к отказу от ответов на потенциально вредоносные или неэтичные запросы и общей устойчивости к манипуляциям. Кроме того, модель показала минимальный балл токсичности, оцененный с помощью API Perspective, что указывает на низкую вероятность генерации оскорбительных или предвзятых высказываний. Данные результаты подтверждают, что GPT-4o-mini обладает повышенным уровнем безопасности и надежности в сравнении с другими протестированными языковыми моделями.
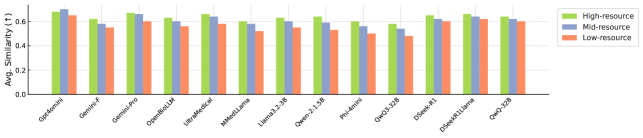
За Пределами Точности: Конфиденциальность, Справедливость и Будущее ИИ в Здравоохранении
Клинический бенчмарк уделяет особое внимание оценке конфиденциальности, гарантируя соответствие строгим стандартам, таким как HIPAA, и надежную защиту чувствительных данных пациентов. В рамках этой оценки тщательно анализируется, как модели искусственного интеллекта обрабатывают персональную информацию, предотвращая несанкционированный доступ или раскрытие. Процедуры включают в себя тестирование на устойчивость к различным атакам, направленным на извлечение личной информации, а также проверку соответствия требованиям анонимизации и деидентификации данных. Гарантия соблюдения этих стандартов является критически важной для укрепления доверия к системам искусственного интеллекта в здравоохранении и обеспечения защиты прав пациентов на неприкосновенность частной жизни.
Оценка справедливости является ключевым аспектом разработки надежных систем искусственного интеллекта для здравоохранения. Исследования, проводимые в рамках Clinic Benchmark, направлены на выявление и смягчение потенциальных предвзятостей, которые могут привести к неравномерному качеству ответов для различных демографических групп. Этот процесс включает в себя анализ производительности алгоритмов для пациентов разных возрастов, полов, этнических групп и социально-экономических слоев, с целью обеспечения того, чтобы все получали одинаково точную и полезную информацию. Устранение предвзятостей не только соответствует этическим нормам, но и критически важно для повышения эффективности лечения и улучшения здоровья всего населения, гарантируя равный доступ к преимуществам инновационных технологий в сфере здравоохранения.
Комплексная оценка надежности, проводимая в рамках Clinic Benchmark, способствует разработке более безопасных, этичных и надежных решений искусственного интеллекта для здравоохранения, что в конечном итоге положительно влияет на результаты лечения пациентов. Оценка включает в себя не только точность, но и такие важные аспекты, как конфиденциальность данных и справедливость алгоритмов. Средняя оценка медицинскими специалистами по параметрам надежности составила 3.9 из 5, что свидетельствует о значимом прогрессе в создании систем, которым можно доверять в критически важных медицинских задачах. Такой подход позволяет выявлять и устранять потенциальные риски, связанные с предвзятостью и утечкой данных, обеспечивая более справедливое и эффективное использование ИИ в клинической практике.

Исследование, представленное в данной работе, напоминает о хрупкости любой системы, стремящейся к точности. Авторы демонстрируют, что даже самые передовые языковые модели в сфере здравоохранения остаются уязвимыми в отношении надежности, справедливости и конфиденциальности. Это подтверждает давнюю истину: система — не статичная конструкция, а скорее живой организм, подверженный изменениям и непредсказуемым сбоям. Как однажды заметил Андрей Колмогоров: «Вероятность того, что система окажется устойчивой, тем меньше, чем больше в ней элементов». Иными словами, стремление к всеобъемлющему охвату, столь характерное для современных моделей, парадоксальным образом увеличивает вероятность возникновения ошибок и уязвимостей. Clinic, как инструмент оценки, лишь подчеркивает эту неизбежность, заставляя задуматься о том, что совершенство в области искусственного интеллекта — это скорее предел, к которому нужно стремиться, чем достижимая реальность.
Что впереди?
Представленная работа, подобно тщательному уходу за садом, выявила не только красоту цветущих языковых моделей, но и скрытые сорняки недоверия. Clinic — это не просто набор метрик, а скорее диагностический инструмент, указывающий на уязвимости, которые неизбежно возникнут при пересадке этих моделей в сложную среду здравоохранения. Попытки построить «надёжную» систему — иллюзия; скорее, следует стремиться к созданию экосистемы, способной прощать ошибки.
Очевидно, что многоязычность — это не просто добавление новых слоёв к существующей конструкции, а фундаментальное изменение её архитектуры. Модели, демонстрирующие успехи в одном языке, часто оказываются хрупкими в других, что указывает на потребность в более глубоком понимании лингвистических нюансов и культурных контекстов. Подобно тому, как корни дерева нуждаются в питательной почве, языковые модели нуждаются в данных, отражающих разнообразие человеческого опыта.
Будущие исследования должны сместить фокус с максимизации производительности на минимизацию риска. Вместо того чтобы стремиться к созданию идеальной модели, следует сосредоточиться на разработке механизмов обнаружения и смягчения ошибок. Помните: система — это не машина, а сад; если её не поливать, вырастет техдолг. Истинная надёжность заключается не в изоляции компонентов, а в их способности прощать ошибки друг друга.
Оригинал статьи: https://arxiv.org/pdf/2512.11437.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Сила в Модели: Ограничения Оптимизации в Математических Задачах
- Искусственный интеллект и закон: гармония неизбежна
- QR-разложение для экстремальных матриц: новый взгляд на GPU
- Квантовые вычисления для молекул: оптимизация ресурсов
- Молекулярный интеллект: проверка химического мышления
- Восстановление рейтингов: Машинное обучение для неполных данных
- Проверка свойств бесконечных семейств систем: новый подход
- Видео-рассуждения: готовы ли модели выйти за рамки лаборатории?
- Видеоредактирование по запросу: Новый подход к точности и связности
- Топoлогические формы и тайны Вселенной
2025-12-16 01:51