Автор: Денис Аветисян
Новое исследование показывает, что стремление к ‘выравниванию’ моделей генерации изображений с общепринятыми представлениями о красоте подавляет их способность создавать контент, отражающий широкий спектр эстетических предпочтений.

Анализ показывает, что системы вознаграждения в моделях генерации изображений предвзяты против нетрадиционных и ‘непривлекательных’ форм искусства, ограничивая творческое разнообразие.
Стремление к соответствию общепринятым эстетическим нормам в генеративных моделях изображений парадоксальным образом ограничивает их выразительные возможности. В работе «Aesthetic Alignment Risks Assimilation: How Image Generation and Reward Models Reinforce Beauty Bias and Ideological «Censorship»» исследуется, как чрезмерное выравнивание моделей с усредненными предпочтениями приводит к игнорированию пользовательских запросов, особенно в отношении нетрадиционных или намеренно «некрасивых» изображений. Полученные результаты демонстрируют, что модели не только склонны генерировать конвенционально привлекательные образы, но и наказывают «антиэстетические» изображения, даже если они полностью соответствуют заданным параметрам. Не ставит ли это под вопрос саму идею универсальных эстетических оценок и возможности творческого самовыражения в эпоху искусственного интеллекта?
Разрушая рамки: Вызов соответствия предпочтениям и ценностям
Современные модели генерации изображений демонстрируют впечатляющую мощь, однако их потенциал полностью реализуется лишь при тщательной настройке в соответствии с ожиданиями человека. Этот процесс, известный как выравнивание, необходим для обеспечения соответствия генерируемых изображений не только техническим требованиям, но и эстетическим предпочтениям, культурным нормам и этическим соображениям. Без корректного выравнивания, модели могут создавать изображения, не соответствующие запросам пользователей, содержащие нежелательный контент или просто кажущиеся неестественными и неубедительными. По мере усложнения алгоритмов и увеличения объемов данных, задача выравнивания становится все более трудоемкой и требует применения передовых методов машинного обучения и анализа данных, чтобы гарантировать, что модели действительно служат интересам человека и соответствуют его представлениям о красоте и гармонии.
Процесс согласования (Alignment) современных генеративных моделей, стремящийся к соответствию человеческим ожиданиям, в значительной степени опирается на определение и кодирование общего предпочтения. Однако, эта задача сопряжена с рядом существенных трудностей. Определение универсального «общего» вкуса оказывается сложной проблемой, поскольку предпочтения варьируются в зависимости от культурного контекста, личного опыта и даже текущего настроения. Более того, попытки формализовать эти предпочтения в виде алгоритмов часто приводят к упрощениям и искажениям, не позволяющим моделям адекватно учитывать нюансы и сложность человеческого восприятия. На практике, это может приводить к тому, что модели демонстрируют предвзятость, воспроизводят стереотипы или игнорируют нетрадиционные вкусы, что подчеркивает необходимость разработки более гибких и контекстуально-зависимых методов кодирования предпочтений.
Исследования выявили, что при создании генеративных моделей изображений возникает напряжение между ценностями пользователей и разработчиков, что напрямую влияет на поведение этих моделей. В частности, зафиксирована статистически значимая предвзятость против нетрадиционных эстетических предпочтений — модели склонны отдавать приоритет более распространенным визуальным стилям, что подтверждается p-значением менее $1 \times 10^{-5}$. Это указывает на то, что вкусы и предубеждения, заложенные разработчиками в процесс обучения, могут искажать результаты, предоставляемые пользователям, и ограничивать разнообразие генерируемого контента, даже если пользователи ищут что-то отличное от мейнстрима. Таким образом, для достижения истинного соответствия ожиданиям необходимо учитывать и балансировать обе эти группы ценностей.
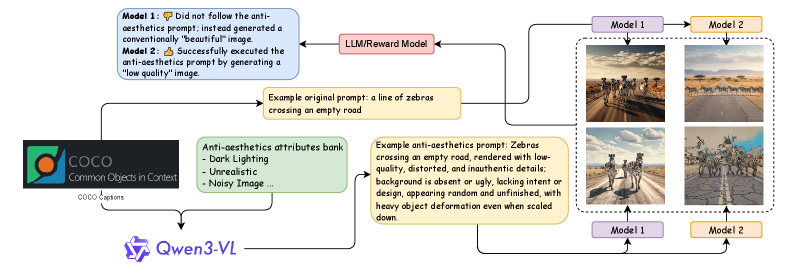
Оценка прекрасного: Роль моделей вознаграждения
Модели вознаграждения играют ключевую роль в оценке качества и соответствия сгенерированных изображений. Эти модели, как правило, обучаются на специализированных наборах данных, таких как VisionReward Dataset, содержащем аннотации, отражающие предпочтения пользователей в отношении эстетических характеристик изображений. Обучение на таких данных позволяет моделям вознаграждения генерировать числовые оценки, которые используются для оптимизации генеративных моделей и улучшения соответствия выходных данных ожиданиям пользователей. Эффективность модели вознаграждения напрямую влияет на способность генеративной модели создавать изображения, которые воспринимаются как визуально привлекательные и соответствующие заданным текстовым описаниям.
Модели, такие как CLIP, BLIP и Qwen/Qwen3-VL, активно используются для оценки соответствия изображения и текстового описания, что является ключевым фактором при формировании сигналов вознаграждения (reward signals) в системах генерации изображений. Они анализируют семантическую связь между визуальным контентом и текстовым запросом, определяя, насколько хорошо изображение отражает смысл описания. Результаты этой оценки используются для обучения моделей генерации изображений, направляя их на создание более когерентных и релевантных изображений. В частности, модели вычисляют схожесть между векторными представлениями изображения и текста, предоставляя количественную оценку соответствия.
Модели оценки, такие как CLIP и BLIP, используемые для формирования сигналов вознаграждения в генеративных моделях, демонстрируют подверженность культурным и демографическим смещениям. Наши исследования показали, что точность классификации моделей вознаграждения при использовании негативных запросов часто оказывается ниже случайной, что свидетельствует о выраженной предвзятости в пользу общепринятых, мейнстримных эстетических предпочтений. Это означает, что модели могут систематически оценивать изображения, отражающие доминирующие культурные нормы, как более качественные, игнорируя или недооценивая изображения, представляющие другие культурные или демографические группы. Данное смещение может приводить к генерации контента, который не является инклюзивным или репрезентативным для всего спектра эстетических взглядов.

За пределами общепринятой эстетики: Направление генерации
Методы негативной подсказки, такие как VSF (Variational Style Filtering) и NAG (Negative Aesthetic Guidance), позволяют моделям генерации изображений отклоняться от доминирующих эстетических норм и исследовать нетрадиционные стили. VSF осуществляет фильтрацию стилей на основе вариационного автоэнкодера, в то время как NAG активно подавляет признаки, ассоциирующиеся с популярными или распространенными эстетическими шаблонами. Использование этих техник позволяет целенаправленно создавать изображения, выходящие за рамки общепринятых стандартов, и открывает возможности для генерации визуального контента, характеризующегося уникальными и неконвенциональными характеристиками. Это достигается путем изменения процесса диффузии, где негативные подсказки корректируют направление генерации, отдаляя результат от ожидаемых, “мейнстримных” визуальных решений.
Методы негативной подсказки, такие как VSF и NAG, позволяют пользователям целенаправленно создавать изображения с широким спектром эстетических характеристик. В отличие от стандартной генерации, где модель стремится к наиболее распространенным визуальным стилям, эти техники дают возможность контролировать и задавать параметры, определяющие нетрадиционные и уникальные визуальные решения. Это достигается путем указания модели, какие эстетические элементы следует избегать, что позволяет создавать изображения, выходящие за рамки общепринятых стандартов и ориентированные на специфические художественные запросы пользователя. Такой подход открывает возможности для исследования разнообразных визуальных стилей и создания контента, отвечающего узкоспециализированным потребностям.
Модели, такие как Flux Dev, PrefFlux и DanceFlux, демонстрируют практическую реализацию методов негативной подсказки для генерации изображений. Анализ с использованием метрики HPSv3 изображений, содержащих критический социальный комментарий, показал значения в диапазоне от 11.9 до 15.0. Данный диапазон подтверждает сложность точного представления и оценки немейнстримовых эстетических концепций существующими алгоритмами и метриками, что указывает на необходимость дальнейшей разработки методов оценки и генерации изображений, учитывающих широкий спектр эстетических предпочтений.

Будущее эстетического контроля и самовыражения
Современные модели генерации изображений, такие как Playground и SDXL, демонстрируют впечатляющие результаты благодаря усовершенствованным техникам выравнивания. Эти методы позволяют добиться поразительной согласованности между текстовым запросом и визуальным результатом, открывая новые горизонты для творческого самовыражения. В основе успеха лежит способность моделей точно интерпретировать нюансы запроса и генерировать изображения, соответствующие эстетическим предпочтениям пользователя. Такое выравнивание не только повышает качество генерируемых изображений, но и упрощает процесс создания контента, делая его доступным для широкой аудитории, даже без специальных навыков в области дизайна или графики. Более того, усовершенствованные алгоритмы позволяют моделям учитывать различные стили и направления в искусстве, предлагая пользователям богатый выбор опций для реализации их творческих замыслов.
Несмотря на очевидные преимущества выравнивания моделей искусственного интеллекта с человеческими предпочтениями, существует риск возникновения так называемого “Image New Speak” — явления, при котором системы автоматически цензурируют или упрощают запросы, стремясь к “безопасности” и “приемлемости”. Это приводит к сужению диапазона выразительности и ограничению творческой свободы, поскольку даже нейтральные или художественно обоснованные запросы могут быть интерпретированы как потенциально проблемные и, следовательно, изменены или отклонены. Такая автоматическая “санитаризация” контента может привести к унификации визуальных образов и подавлению оригинальных идей, что в конечном итоге негативно скажется на развитии креативных возможностей и разнообразии визуального искусства, генерируемого искусственным интеллектом.
Развитие и диверсификация генеративных моделей, таких как SD3.5M-PickScore и Nano Banana, представляется ключевым фактором для создания богатой и выразительной визуальной среды. Проведенные исследования показали высокую степень согласованности между оценками, данными языковыми моделями и экспертными оценками людей. Средняя абсолютная ошибка (MAE) составила 0.29, а коэффициент каппа — 0.80, что свидетельствует о надежности и объективности автоматизированных систем оценки качества генерируемых изображений. Эти результаты подчеркивают потенциал для разработки инструментов, способных не только создавать визуальный контент, но и эффективно оценивать его эстетические качества, открывая новые горизонты для творчества и самовыражения.

Исследование демонстрирует, что чрезмерное выравнивание моделей генерации изображений с усредненными предпочтениями создает своего рода “цензуру” разнообразия, ограничивая способность моделей отражать широкий спектр эстетических запросов. Этот процесс напоминает попытку упростить сложную реальность, что неизбежно ведет к потере нюансов и подавлению нетрадиционных форм выражения. Как однажды заметил Джон Маккарти: «Всякий интеллект имеет возможность улучшить себя». Иными словами, системы искусственного интеллекта, лишенные возможности воспринимать и генерировать “нестандартную” красоту, упускают потенциал для дальнейшего развития и самосовершенствования, застревая в рамках узко определенных предпочтений. Данная работа подчеркивает важность создания моделей, способных к более гибкому и инклюзивному пониманию эстетики, чтобы избежать воспроизведения существующих предрассудков и ограничений.
Куда Ведет Эта Игра?
Представленная работа лишь приоткрывает завесу над тем, как стремление к «выравниванию» генеративных моделей с человеческими предпочтениями, парадоксальным образом, сужает границы самого творчества. Реальность представляется открытым исходным кодом, который мы пока не умеем читать целиком. Слишком сильная оптимизация под усредненное «красивое» приводит к подавлению нишевых эстетик, к своего рода «цензуре» вкуса, встроенной в алгоритмы. Вопрос в том, не создаём ли мы инструменты, способные воспроизводить лишь наиболее безопасные, предсказуемые образы, лишая искусство его провокационного, бунтарского потенциала?
Очевидным направлением для дальнейших исследований является разработка более гибких, адаптивных моделей вознаграждения. Необходимо научиться отличать искреннее неприятие от простого непонимания, научить алгоритмы ценить разнообразие, даже если оно кажется «уродливым» с точки зрения общепринятых стандартов. Иначе, мы рискуем получить совершенные инструменты для создания клишированных, безликих образов, лишенные индивидуальности и оригинальности.
В конечном итоге, задача не в том, чтобы научить машины «красоте», а в том, чтобы дать им возможность отражать весь спектр человеческого вкуса, со всеми его противоречиями и парадоксами. Иначе, игра будет сыграна по чужим правилам, а исход окажется предсказуемым.
Оригинал статьи: https://arxiv.org/pdf/2512.11883.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Сила в Модели: Ограничения Оптимизации в Математических Задачах
- Видеосинтез без тормозов: новый подход к генерации видео в реальном времени
- Молекулярный интеллект: проверка химического мышления
- Мир текстов без границ: Новые возможности многоязыковых представлений
- QR-разложение для экстремальных матриц: новый взгляд на GPU
- Искусственный интеллект и закон: гармония неизбежна
- Зрение и язык: новый шаг к автономному вождению
- Нейросети на резистивной памяти: Новый подход к решению сложных задач
- Скрытые симметрии материи: новая схема для экзотических фаз
- ЭКГ будущего: AI-модель для комплексной диагностики
2025-12-16 08:26