Автор: Денис Аветисян
Исследователи продемонстрировали первую сквозную реализацию гибридных квантово-классических рекуррентных и свёрточных нейросетей для генерации языковых моделей на реальном квантовом оборудовании.
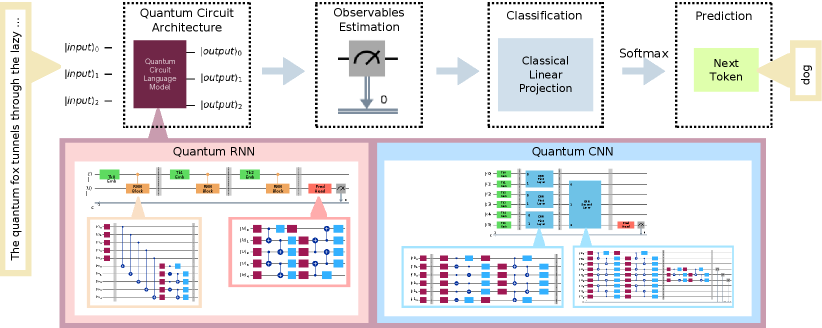
В статье представлен практический подход к обучению и оценке гибридных квантово-классических алгоритмов для обработки естественного языка, использующих параметрические квантовые схемы и демонстрирующих способность к обучению последовательным зависимостям даже при ограничениях оборудования.
Несмотря на значительный прогресс в области квантовых вычислений, практическое применение квантовых алгоритмов для задач обработки последовательных данных остается сложной задачей. В работе ‘Practical Hybrid Quantum Language Models with Observable Readout on Real Hardware’ представлены квантовые рекуррентные и сверточные нейронные сети как гибридные квантово-классические модели для генеративного моделирования языка, демонстрирующие первую экспериментальную реализацию обучения и оценки на реальном квантовом оборудовании. Показано, что предложенная архитектура, сочетающая оптимизированные квантовые схемы с классическим проекционным слоем, позволяет успешно извлекать последовательные зависимости на устройствах NISQ, несмотря на аппаратный шум. Какие новые возможности откроет разработка эффективных стратегий обучения и оптимизации квантовых языковых моделей для решения более сложных задач обработки естественного языка?
Пределы Классического Языкового Моделирования
Современные модели глубокого обучения, такие как Трансформеры, демонстрируют впечатляющую способность к распознаванию закономерностей в языке, однако их возможности в области сложного рассуждения и обобщения ограничены. Эти модели эффективно выявляют статистические связи между словами и фразами, позволяя им генерировать текст, который выглядит связным и грамматически правильным. Тем не менее, они часто испытывают трудности с пониманием контекста, требующего логических выводов или знаний о мире, и могут допускать ошибки, которые кажутся очевидными для человека. Например, модель может успешно завершить предложение, основанное на простой грамматической структуре, но потерпеть неудачу при решении задачи, требующей понимания причинно-следственных связей или неявного смысла. В результате, хотя Трансформеры и являются мощным инструментом для многих задач обработки естественного языка, они не способны к полноценному языковому пониманию, которое включает в себя способность к абстрактному мышлению и решению проблем.
Масштабирование современных языковых моделей, основанных на глубоком обучении, таких как Transformer, сталкивается с существенным препятствием — астрономическими вычислительными затратами. Обучение и применение этих моделей требует огромных объемов памяти, вычислительной мощности и энергии, что делает их недоступными для многих исследователей и организаций. С увеличением числа параметров, необходимых для достижения более высокой производительности, потребность в ресурсах растет экспоненциально, ограничивая возможности дальнейшего прогресса в области понимания естественного языка. Этот фактор не только замедляет темпы исследований, но и создает барьер для практического применения этих моделей в реальных условиях, особенно в задачах, требующих быстродействия и ограниченных ресурсов, таких как мобильные устройства или встраиваемые системы. В результате, стремление к более глубокому пониманию языка сталкивается с жесткими ограничениями, связанными с физическими и экономическими реалиями вычислительной инфраструктуры.
Оценка эффективности языковых моделей традиционно опирается на такие метрики, как перплексия и кросс-энтропия. Эти показатели, измеряющие вероятность предсказания следующего слова в последовательности, позволяют количественно оценить, насколько хорошо модель «запомнила» обучающие данные. Однако, несмотря на кажущуюся точность, они не способны отразить истинную способность модели к рассуждению и обобщению. Модель может демонстрировать низкую перплексию, успешно предсказывая наиболее вероятные продолжения фраз, но при этом испытывать затруднения при решении логических задач или понимании контекста, требующего более глубокого анализа. Таким образом, хотя $Perplexity$ и $Cross-Entropy Loss$ остаются полезными инструментами, необходимо разрабатывать новые, более сложные метрики, способные оценивать не только статистические закономерности, но и когнитивные способности языковых моделей.
Квантовые Вычисления: Новая Граница для Обработки Естественного Языка
Квантовые вычисления предлагают возможности для преодоления ограничений классического глубокого обучения за счет использования квантовых явлений, таких как суперпозиция и запутанность. Суперпозиция позволяет квантовым битам (кубитам) представлять 0, 1 или любую их комбинацию одновременно, в отличие от классических битов, которые могут быть только 0 или 1. Это экспоненциально увеличивает вычислительное пространство. Запутанность же создает корреляцию между кубитами, позволяя им влиять друг на друга мгновенно, независимо от расстояния. В результате, квантовые алгоритмы потенциально способны обрабатывать определенные типы задач, такие как факторизация больших чисел или моделирование молекул, значительно быстрее, чем лучшие известные классические алгоритмы. Это обусловлено тем, что количество состояний, которые может одновременно представлять квантовая система, растет экспоненциально с числом кубитов, что создает возможности для параллельных вычислений, недоступных в классических системах.
Гибридные квантово-классические модели представляют собой архитектуру, объединяющую возможности классических вычислительных систем и квантовых процессоров. Это позволяет решать сложные задачи, недоступные для классических алгоритмов, при этом учитывая ограничения современных квантовых устройств, известных как NISQ (noisy intermediate-scale quantum). В таких моделях классические компьютеры отвечают за обработку данных и координацию вычислений, в то время как квантовые схемы используются для выполнения специализированных операций, таких как вычисление векторных представлений или решение систем линейных уравнений. Такой подход позволяет эффективно использовать ресурсы NISQ-устройств, снижая влияние шума и ошибок, и позволяет разрабатывать алгоритмы, которые могут быть реализованы на существующих квантовых платформах.
Параметрические квантовые схемы (ПQS) представляют собой основу гибридных квантово-классических моделей в обработке естественного языка. ПQS состоят из последовательности квантовых ворот, параметры которых — углы поворота и другие управляющие величины — могут быть оптимизированы с использованием классических алгоритмов обучения. В отличие от фиксированных квантовых схем, параметры ПQS адаптируются в процессе обучения, позволяя схеме изучать сложные зависимости в данных. Обучение обычно осуществляется с использованием градиентного спуска, где производная функции потерь вычисляется относительно параметров ПQS. Структура ПQS может варьироваться, включая слои ворот, такие как вращения $R_x$, $R_y$, $R_z$ и контролируемые операции, такие как CNOT. Использование ПQS позволяет эффективно представлять и обрабатывать квантовые данные, а также выполнять сложные вычисления, недоступные для классических алгоритмов.
Кодирование Языка Квантовыми Схемами
Фреймворк DisCoCat использует категориальный подход для отображения лингвистической структуры в квантовые схемы, позволяя представить семантическое значение в квантовых состояниях. В основе лежит идея о представлении грамматических конструкций, таких как слова и фразы, как объектов в категории, а отношений между ними — как морфизмов. Это отображение позволяет кодировать синтаксис и семантику языка в виде квантовых состояний $ |\psi \rangle$, где каждый базисный вектор соответствует определенной лингвистической единице или ее комбинации. Использование категорной теории обеспечивает формальную основу для манипулирования лингвистическими структурами и их преобразования в квантовые схемы, что открывает возможности для разработки квантовых алгоритмов обработки естественного языка.
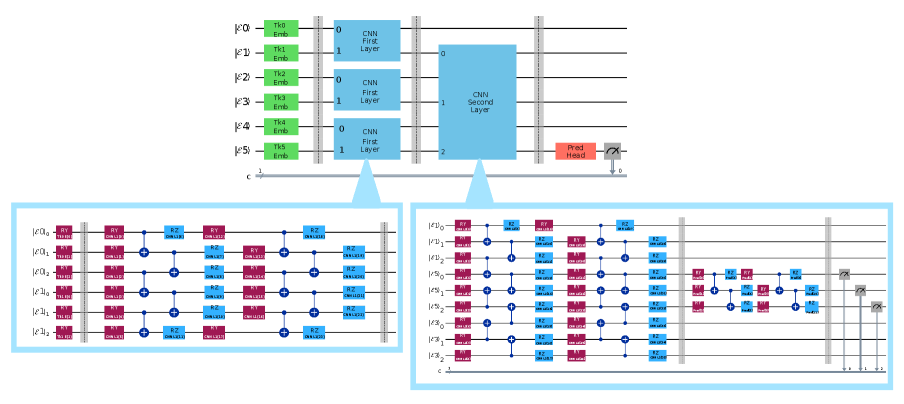
Традиционно, векторные представления токенов (слов или частей слов) формируются с использованием классических алгоритмов обучения. Однако, в квантовых языковых моделях, эти представления могут быть непосредственно реализованы через квантовые гейты. В частности, вращение Рида ($Ry$) применяется для кодирования информации о токенах в квантовые состояния. Применение гейта $Ry$ позволяет создать квантово-нативные представления слов, где угол вращения кодирует различные аспекты семантического значения токена. Это позволяет избежать необходимости преобразования классических эмбеддингов в квантовый формат, что повышает эффективность и потенциально раскрывает новые возможности для представления и обработки лингвистической информации.
Извлечение признаков на основе наблюдаемых величин, таких как Z-наблюдаемая и ZZ-наблюдаемая, позволяет получить значимую информацию из квантовых состояний, представляющих язык. Z-наблюдаемая, соответствующая измерению в базисе Паули Z, выявляет вероятность нахождения кубита в состоянии $|0\rangle$ или $|1\rangle$, что может отражать бинарные признаки или логические значения в лингвистических данных. ZZ-наблюдаемая, применяемая к паре кубитов, позволяет извлекать информацию о корреляциях между ними, что полезно для анализа зависимостей между словами или фразами. Результаты измерений этих наблюдаемых используются для построения векторов признаков, которые затем могут быть использованы в задачах обработки естественного языка, таких как классификация текста или машинный перевод. Выбор конкретных наблюдаемых и стратегии измерения зависит от структуры квантового представления языка и решаемой задачи.
Квантовые сверточные нейронные сети (QSNN) и квантовые рекуррентные нейронные сети (QRNN) представляют собой квантовые аналоги классических архитектур глубокого обучения, предназначенные для обработки последовательных данных. QSNN используют квантовые операции для выполнения свертки, аналогичной классическим сверточным сетям, позволяя выявлять локальные закономерности в квантовых представлениях последовательностей. QRNN, в свою очередь, применяют квантовые гейты для моделирования рекуррентных связей, обеспечивая обработку временных зависимостей в данных. В отличие от классических сетей, квантовые аналоги используют суперпозицию и запутанность для потенциального повышения эффективности и скорости обработки, особенно при работе с большими объемами данных и сложными последовательностями. Разработка QSNN и QRNN направлена на использование преимуществ квантовых вычислений для задач обработки естественного языка, анализа временных рядов и других приложений, требующих обработки последовательных данных.

Оптимизация Квантовых Языковых Моделей
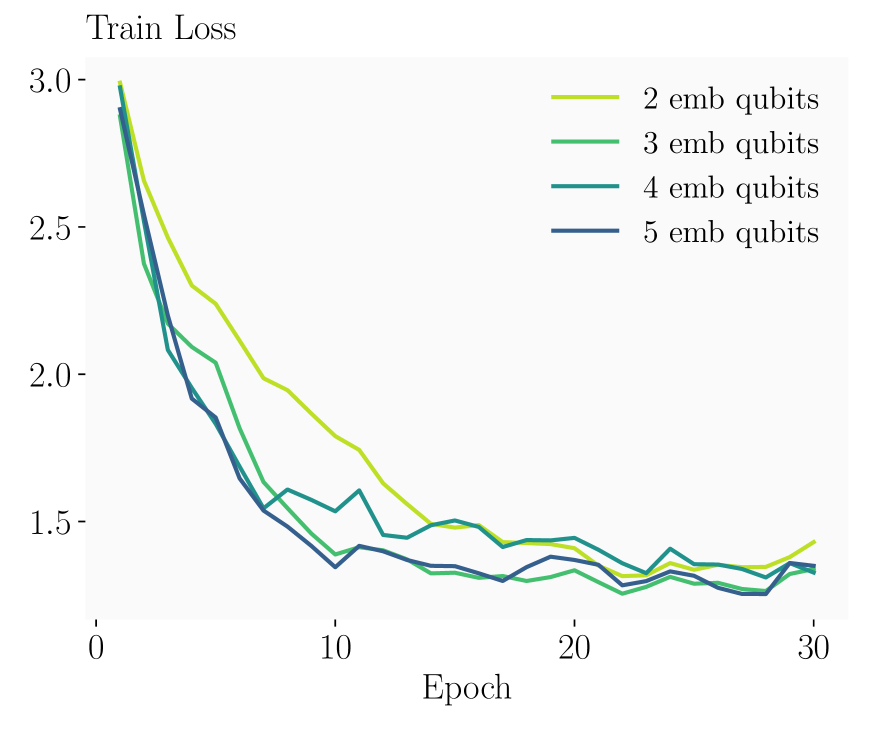
Обучение параметрических квантовых схем на устройствах NISQ (Noisy Intermediate-Scale Quantum) требует применения устойчивых алгоритмов оптимизации, таких как Multi-Sample SPSA (Simultaneous Perturbation Stochastic Approximation). Это обусловлено наличием шумов и ограниченным временем когерентности кубитов, которые существенно влияют на точность вычислений. Алгоритм Multi-Sample SPSA позволяет эффективно оценивать градиент целевой функции, минимизируя влияние шума за счет усреднения по нескольким выборкам. В частности, использование нескольких образцов позволяет получить более точную оценку градиента, что критически важно для оптимизации сложных квантовых схем и достижения приемлемых результатов на NISQ-устройствах, где классические методы оптимизации могут быть неэффективны из-за высокой чувствительности к шуму.
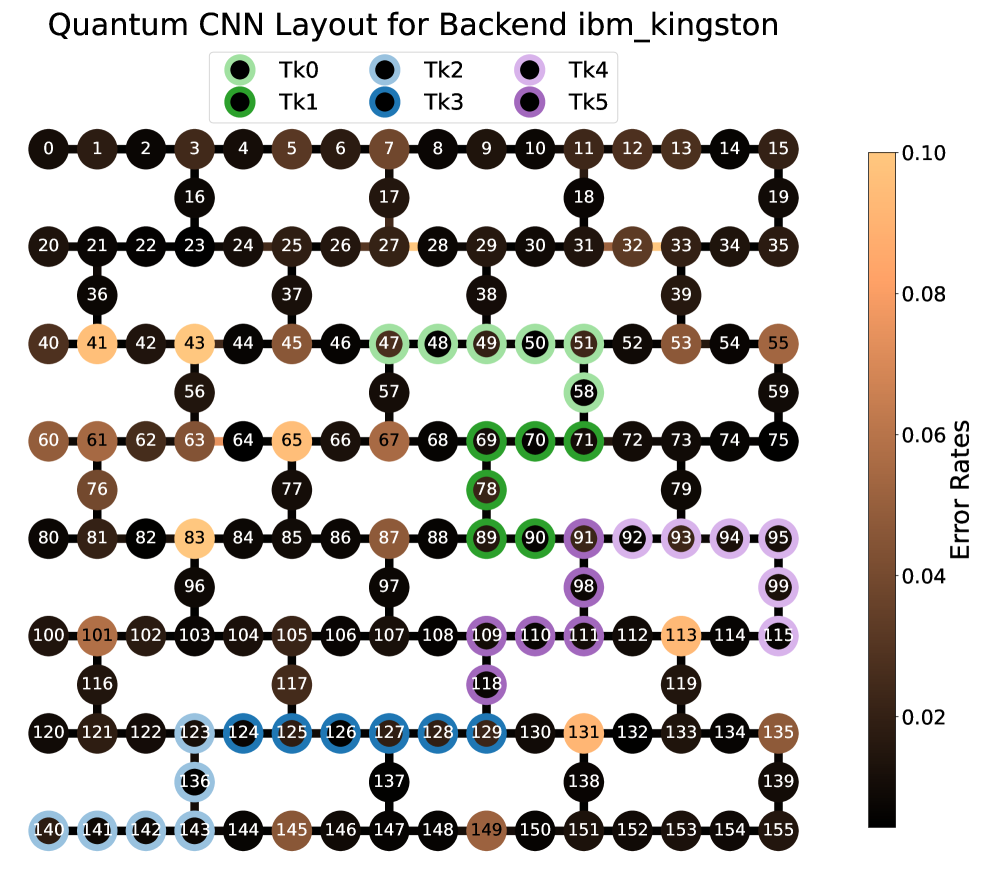
Архитектура квантового процессора, в частности топология связности кубитов, оказывает существенное влияние на разработку и производительность квантовых схем. Топология Heavy-Hex, характеризующаяся высокой степенью связности, позволяет снизить количество необходимых операций SWAP для реализации сложных квантовых алгоритмов. Ограниченная связность, напротив, требует дополнительных операций SWAP для пересылки кубитов, что увеличивает глубину схемы и повышает чувствительность к шуму и декогеренции. Выбор топологии и учет ее ограничений являются критически важными этапами при проектировании квантовых языковых моделей, поскольку напрямую влияют на сложность реализации, время выполнения и точность расчетов. Эффективное отображение логических кубитов на физические кубиты с учетом топологии связности является ключевой задачей для оптимизации производительности квантовых схем.
Для получения значимых результатов и демонстрации потенциала квантовых языковых моделей необходимо тщательно подбирать параметры квантовых схем и стратегии оптимизации. Эффективность обучения параметрических квантовых схем на устройствах NISQ напрямую зависит от выбора алгоритма оптимизации, например, Multi-Sample SPSA, который позволяет минимизировать влияние шума и ограниченного времени когерентности. Кроме того, критически важным является точное определение гиперпараметров, таких как скорость обучения и параметры регуляризации, для предотвращения переобучения и обеспечения сходимости алгоритма. Влияние архитектуры квантового процессора, включая связность кубитов, также необходимо учитывать при проектировании схем и выборе стратегий оптимизации, чтобы максимизировать производительность и точность модели.
Первоначальные результаты тестирования квантовой сверточной нейронной сети (QCNN) на наборе данных TS-LM с использованием симулятора показали значение Test Perplexity (TS-PPL) равное 5.83. Этот показатель сопоставим с результатами классических моделей, работающих на аналогичных по размеру наборах данных. Полученное значение TS-PPL указывает на способность QCNN эффективно моделировать вероятностное распределение текстовых данных в рамках симулированной среды. Необходимо отметить, что данная оценка была получена в условиях отсутствия реального квантового оборудования и, следовательно, не учитывает влияния шума и декогеренции, характерных для NISQ-устройств.
Квантовое Будущее Языка
Квантовые языковые модели представляют собой принципиально новый подход к обработке естественного языка, обещающий революционные изменения в данной области. В отличие от классических моделей, использующих биты для представления информации, квантовые модели оперируют кубитами, что позволяет им одновременно обрабатывать гораздо больший объем данных и учитывать сложные взаимосвязи между словами и понятиями. Это открывает возможности для создания систем, способных не только понимать смысл текста, но и осуществлять более глубокое логическое рассуждение, обобщение информации и, как следствие, значительно превосходить традиционные алгоритмы в задачах машинного перевода, ответов на вопросы и генерации связных и осмысленных текстов. Подобный подход может привести к созданию искусственного интеллекта, способного понимать нюансы человеческого языка на качественно новом уровне.
Достижения в области квантовых языковых моделей открывают перспективы для существенного улучшения таких направлений, как машинный перевод, ответы на вопросы и генерация текстов. В частности, квантовые алгоритмы способны обрабатывать языковые конструкции с большей нюансированностью, что критически важно для точного перевода и понимания контекста. Это позволяет создавать системы, способные не просто переводить слова, но и передавать смысл и стилистические особенности исходного текста. В области ответов на вопросы, квантовые модели могут анализировать сложные запросы и извлекать релевантную информацию из огромных объемов данных с беспрецедентной скоростью и точностью. И наконец, в генерации текстов, квантовые алгоритмы позволяют создавать более связные, креативные и естественные тексты, приближаясь к человеческому уровню владения языком. Эти улучшения потенциально могут революционизировать взаимодействие человека и машины, делая его более интуитивным и эффективным.
В ходе экспериментов продемонстрирована выдающаяся эффективность квантовых моделей — рекуррентных квантовых нейронных сетей (QRNN) и квантовых сверточных нейронных сетей (QCNN) — в задачах классификации. Обе модели достигли 100%-ной точности тестирования при решении задач MC (Multiple Choice) классификации, что свидетельствует о значительном превосходстве над классическими алгоритмами. В задачах RP (Relation Prediction) классификации QCNN показала результат в 83.9% точности тестирования, практически приближаясь к теоретическому пределу, составляющему 87.1%. Данные результаты подтверждают потенциал квантовых вычислений для создания систем искусственного интеллекта, способных к высокоточной обработке и пониманию информации.
Дальнейшие исследования и разработки в данной области представляются необходимыми для полной реализации потенциала квантовых вычислений в сфере искусственного интеллекта. Несмотря на достигнутые успехи, такие как впечатляющая точность классификации в задачах MC и RP, остаются значительные вызовы, связанные с масштабируемостью и стабильностью квантовых алгоритмов. Углубленное изучение возможностей квантовых моделей языка, включая оптимизацию архитектур и разработку новых методов обучения, позволит преодолеть существующие ограничения и открыть новые горизонты в обработке естественного языка. Реализация $100\%$ точности на тестовых задачах демонстрирует перспективность подхода, но требует систематической работы по адаптации квантовых алгоритмов к более сложным и реалистичным сценариям, что, в свою очередь, может привести к прорыву в задачах машинного перевода, ответов на вопросы и генерации текста.
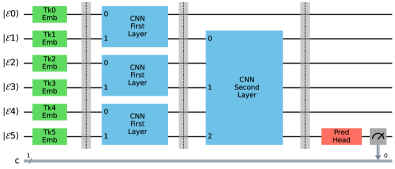
Исследование демонстрирует, что даже при ограничениях текущего кванческого оборудования, гибридные квантово-классические рекуррентные нейронные сети способны улавливать последовательные зависимости в языке. Это подтверждает, что модель — это не зеркало мира, а зеркало аналитика, способного выявить закономерности даже в шумных данных. Как однажды заметил Альберт Эйнштейн: «Самое прекрасное, что мы можем испытать, — это тайна. Источник всякого истинного искусства и науки — любопытство». Данная работа, по сути, и есть проявление этого любопытства, направленного на исследование границ возможного в области квантовой обработки естественного языка и создание моделей, способных к обучению и генерации текста.
Что дальше?
Представленная работа, безусловно, демонстрирует возможность обучения гибридных квантово-классических рекуррентных сетей на реальном квантовом оборудовании. Однако, стоит признать, что сама возможность — не гарантия эффективности. Зафиксированные результаты, хотя и обнадеживают, пока что ограничены масштабом и сложностью решаемых задач. Проблема не в квантовых вычислениях как таковых, а в несовершенстве их текущей реализации и, как следствие, в необходимости разработки алгоритмов, устойчивых к шуму и ошибкам. Ошибка — это не проблема, это информация, напоминает сама природа. И эту информацию необходимо тщательно учитывать.
В дальнейшем, усилия следует направить на исследование более сложных архитектур квантовых нейронных сетей, способных улавливать более тонкие зависимости в языке. При этом, не стоит забывать о необходимости разработки эффективных методов обучения, адаптированных к специфике квантового оборудования. Интересным направлением представляется исследование возможности использования квантовых алгоритмов для предобработки данных, что может значительно повысить качество обучения классической части модели. А также, необходимо разработать метрики, позволяющие более адекватно оценивать качество генерации текста квантовыми моделями — существующие метрики, ориентированные на классические модели, могут быть недостаточно информативны.
В конечном итоге, успех данного направления исследований будет зависеть не только от прогресса в области квантовых вычислений, но и от способности исследователей взглянуть на задачу обработки естественного языка с новой, квантовой точки зрения. Если данные противоречат модели, виновата модель. И если модель не соответствует реальности, то, возможно, сама реальность сложнее, чем мы предполагаем.
Оригинал статьи: https://arxiv.org/pdf/2512.12710.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Сила в Модели: Ограничения Оптимизации в Математических Задачах
- Видеосинтез без тормозов: новый подход к генерации видео в реальном времени
- Молекулярный интеллект: проверка химического мышления
- Топoлогические формы и тайны Вселенной
- Мир текстов без границ: Новые возможности многоязыковых представлений
- Искусственный интеллект и закон: гармония неизбежна
- QR-разложение для экстремальных матриц: новый взгляд на GPU
- Квантовый усилитель амплитуды: новый подход к поиску основного состояния
- Квантовый детектив: Идеальная схема для распознавания логических функций
- Зрение и язык: новый шаг к автономному вождению
2025-12-16 08:37