Автор: Денис Аветисян
Исследователи представили NL2Repo-Bench — инструмент для оценки способности искусственного интеллекта создавать полноценные Python-проекты по текстовым описаниям, выявив серьезные ограничения в способности к долгосрочному планированию.

NL2Repo-Bench — это эталонный набор данных для оценки генерации репозиториев кода на основе естественного языка, подчеркивающий трудности в автономной разработке программного обеспечения и требующий более продвинутых способностей к рассуждениям.
Несмотря на значительный прогресс в области кодирующих агентов, существующие бенчмарки не позволяют адекватно оценить их возможности при создании полноценных программных систем. В работе ‘NL2Repo-Bench: Towards Long-Horizon Repository Generation Evaluation of Coding Agents’ представлен новый бенчмарк, предназначенный для оценки способности агентов генерировать полные, устанавливаемые Python-библиотеки из текстовых описаний требований. Эксперименты показали, что даже самые современные модели демонстрируют низкую эффективность в задачах, требующих длительного планирования и последовательного выполнения действий, с результатами ниже 40% успешных тестов. Какие фундаментальные ограничения препятствуют созданию действительно автономных агентов, способных к разработке сложного программного обеспечения?
Вызовы долгосрочного планирования в разработке программного обеспечения
Традиционная разработка программного обеспечения исторически опирается на значительные трудозатраты и многократные итерации, что неизбежно приводит к возникновению ошибок и задержек в сроках реализации. Этот процесс, предполагающий ручное кодирование и тестирование на каждом этапе, становится особенно проблематичным при создании сложных приложений, где даже небольшие недочеты могут привести к серьезным последствиям. Постоянная необходимость в ручной проверке и исправлении ошибок не только замедляет разработку, но и увеличивает её стоимость, ограничивая возможности для инноваций и оперативного внедрения новых решений. В результате, компании часто сталкиваются с необходимостью пересмотра планов, увеличения бюджета и, в конечном итоге, снижения конкурентоспособности.
Современные программные приложения становятся все более сложными, требуя для своей реализации не просто написания отдельных фрагментов кода, а планирования и последовательного выполнения многоступенчатых проектов. Возникающая потребность в автоматизированных решениях обусловлена необходимостью справляться с задачами, требующими долгосрочного планирования — так называемыми “long-horizon” задачами. Речь идет о создании программного обеспечения, которое способно самостоятельно определять последовательность действий для достижения сложной цели, подобно тому, как человек разбивает большую задачу на более мелкие, управляемые шаги. Вместо ручного кодирования каждого этапа, автоматизированные системы должны уметь самостоятельно генерировать и выполнять код, обеспечивая при этом согласованность и корректность на протяжении всего процесса. Эта тенденция к автоматизации долгосрочного планирования и выполнения задач является ключевой для будущего разработки программного обеспечения.
Современные методы автоматической генерации кода часто сталкиваются с серьезными трудностями при создании сложных программных проектов, требующих последовательного выполнения множества шагов. Проблема заключается в поддержании внутренней согласованности и логической связности генерируемого кода на протяжении длительных последовательностей операций. По мере увеличения длины генерируемой программы, даже незначительные ошибки или несоответствия на ранних этапах могут накапливаться и приводить к серьезным нарушениям в работе всего приложения. Это ограничивает практическое применение существующих систем, поскольку они не способны надежно создавать крупные и сложные программные продукты, требующие долгосрочного планирования и последовательного исполнения множества взаимосвязанных задач. Неспособность сохранять когерентность и консистентность делает автоматическую генерацию кода для долгосрочных задач неэффективной и требует значительных усилий по ручной корректировке и отладке.
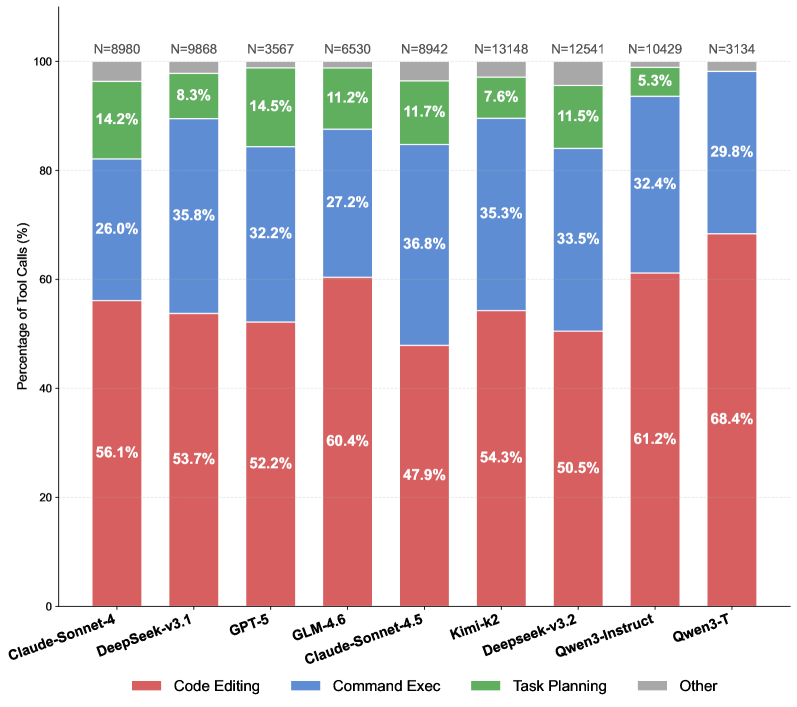
Агентное планирование как решение для синтеза кода
Предлагается автоматизация процесса создания программного обеспечения посредством использования «Кодирующих Агентов» — автономных систем, способных генерировать и отлаживать код. Эти агенты функционируют как независимые единицы, выполняющие полный цикл разработки, от написания исходного кода до выявления и исправления ошибок. В основе работы агентов лежит способность к самопрограммированию и адаптации к различным задачам, что позволяет им решать широкий спектр проблем без непосредственного вмешательства человека. Автономность и способность к самообучению делают кодирующих агентов перспективным инструментом для повышения эффективности и скорости разработки программного обеспечения.
Ключевым аспектом предложенного подхода является агентное планирование, позволяющее агенту самостоятельно формулировать цели разработки, декомпозировать их на последовательность подзадач и стратегически выполнять эти подзадачи. Этот процесс включает в себя не только определение необходимых шагов для достижения поставленной цели, но и динамическую адаптацию плана в зависимости от результатов выполнения отдельных подзадач и возникающих ограничений. Агентное планирование обеспечивает автономность агента в процессе разработки, позволяя ему самостоятельно принимать решения о порядке выполнения задач и выборе необходимых инструментов для их реализации, что существенно повышает эффективность автоматизированного синтеза кода.
Эффективное агентивное планирование требует надежного использования инструментов, позволяя агенту задействовать существующие утилиты для выполнения различных задач. В частности, это включает в себя автоматизированное управление зависимостями, например, с использованием менеджеров пакетов, таких как npm или pip, для установки необходимых библиотек и компонентов. Кроме того, критически важным является использование инструментов тестирования, позволяющих агенту верифицировать правильность сгенерированного кода и выявлять потенциальные ошибки до развертывания. Интеграция с системами контроля версий, такими как Git, также необходима для отслеживания изменений и обеспечения возможности отката к предыдущим версиям кода. Способность агента динамически выбирать и комбинировать эти инструменты значительно повышает его эффективность и надежность при синтезе программного обеспечения.
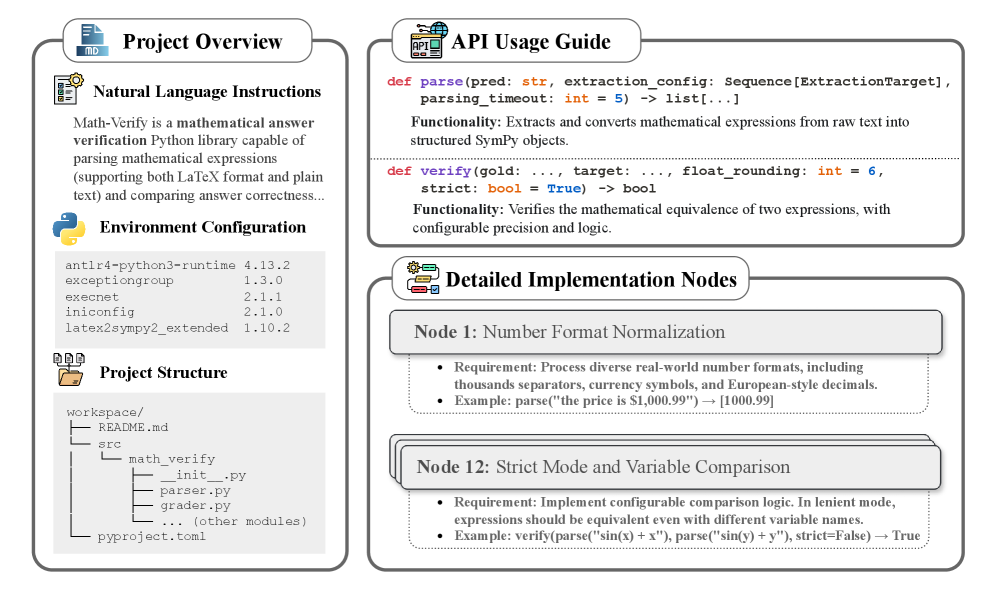
Валидация генерации репозиториев с помощью строгого тестирования
Для оценки возможностей наших кодирующих агентов мы разработали эталонный набор тестов ‘NL2Repo-Bench’, предназначенный для оценки генерации репозиториев в долгосрочной перспективе. Этот эталон использует исключительно описание на естественном языке в качестве входных данных, требуя от агента преобразования требований в функциональную кодовую базу. ‘NL2Repo-Bench’ позволяет проводить комплексную оценку способности агентов создавать полные, работоспособные репозитории на основе высокоуровневых спецификаций, а не просто генерировать отдельные фрагменты кода или решать узкоспециализированные задачи.
В основе бенчмарка NL2Repo-Bench лежит использование исключительно спецификации на естественном языке в качестве входных данных. Это предъявляет требование к агентам — автоматически преобразовывать текстовое описание требований в полностью функциональную кодовую базу, включающую все необходимые компоненты и обеспечивающую корректную работу. Такой подход позволяет оценить способность агента к комплексному пониманию задачи, проектированию архитектуры программного обеспечения и генерации кода без какой-либо дополнительной информации, кроме текстового описания.
Оценка современных передовых кодирующих агентов на бенчмарке NL2Repo-Bench показала средний процент успешного прохождения тестов всего 39.6%. Данный результат демонстрирует значительные трудности, возникающие при генерации полноценных репозиториев кода по текстовому описанию требований, и указывает на необходимость дальнейших исследований и усовершенствований в области автоматизированного создания программного обеспечения.
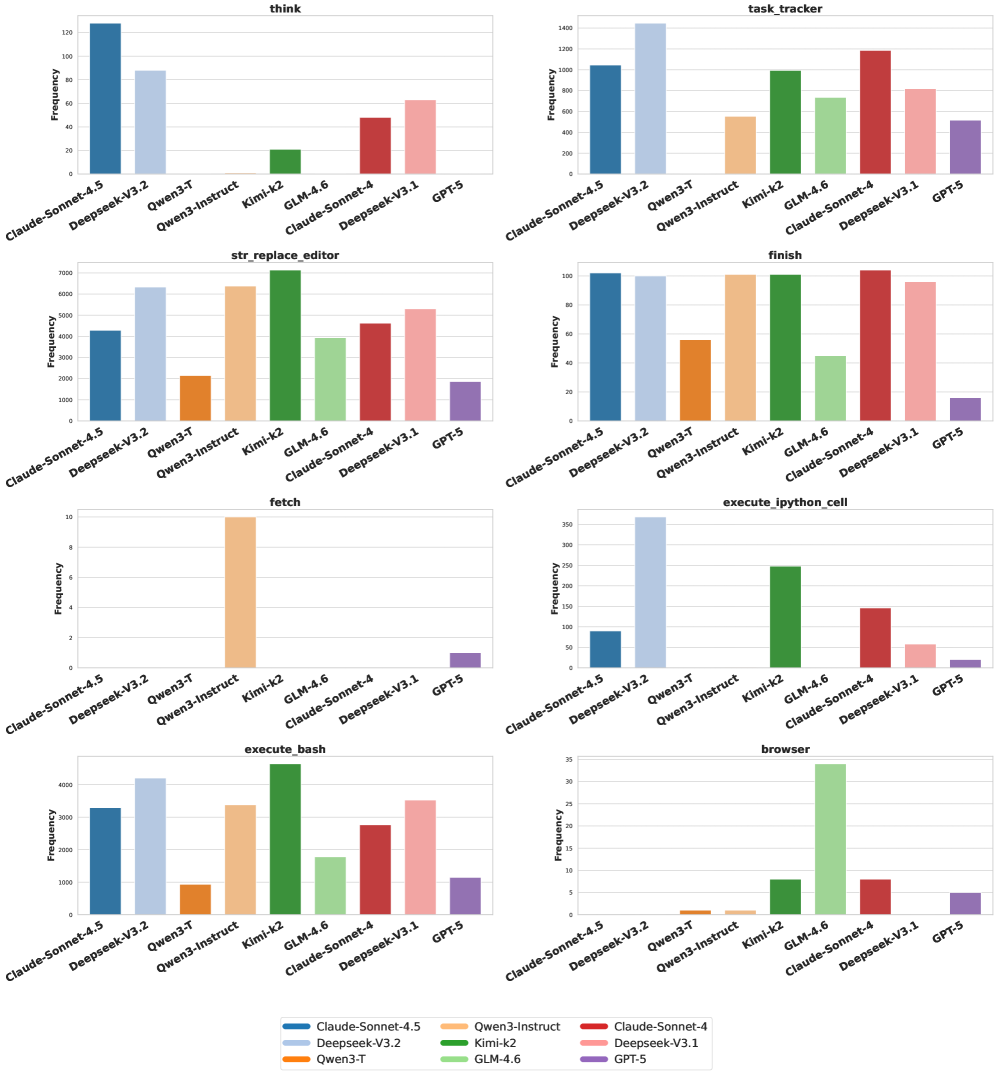
Обеспечение надежности: управление зависимостями и согласованность кода
Успешное генерирование репозитория программного обеспечения напрямую зависит от тщательного управления зависимостями. Это подразумевает не просто перечисление необходимых библиотек, но и точное определение их версий, совместимости между собой и с целевой средой выполнения. Некорректное указание или отсутствие какой-либо зависимости может привести к ошибкам компиляции, проблемам при выполнении и даже к полной неработоспособности проекта. В процессе генерации репозитория, системы должны автоматически выявлять все необходимые зависимости, разрешать конфликты версий и интегрировать их в проект таким образом, чтобы обеспечить его стабильность и воспроизводимость. Тщательное управление зависимостями является краеугольным камнем надежной разработки и позволяет избежать множества потенциальных проблем на этапах тестирования и развертывания.
Поддержание согласованности между файлами проекта является критически важным аспектом разработки программного обеспечения. Изменения, внесенные в один файл, могут непреднамеренно повлиять на другие, вызывая ошибки и непредсказуемое поведение системы. Для предотвращения подобных ситуаций необходимо тщательно отслеживать зависимости между файлами и обеспечивать, чтобы все модификации учитывали эти взаимосвязи. Автоматизированные инструменты статического анализа и системы контроля версий играют важную роль в выявлении и предотвращении расхождений, обеспечивая целостность и надежность кодовой базы. Несоблюдение принципов согласованности может привести к сложным отладочным процессам и увеличению вероятности появления скрытых дефектов, существенно снижая качество конечного продукта.
Исследования показали, что даже самые передовые языковые модели, такие как Claude-Sonnet-4.5, испытывают значительные трудности при полной реконструкции репозиториев кода — успешно выполнили лишь три из всех поставленных задач. Этот факт наглядно демонстрирует сложность процесса, требующего не только понимания синтаксиса, но и учета множества взаимосвязей между различными компонентами. Примечательно, что предоставление моделям доступа к полному набору тестов существенно повысило процент успешных реконструкций — с 39.6% до 59.4%. Данный результат подчеркивает критическую важность исчерпывающей информации о тестировании для обеспечения надежности и корректности воспроизводимых репозиториев, а также указывает на необходимость разработки более эффективных методов оценки и верификации.
Исследование демонстрирует, что создание полноценных репозиториев из естественного языка — задача, требующая от агентов не просто генерации кода, но и долгосрочного планирования и понимания взаимосвязей между компонентами. Подобный подход к оценке выявляет уязвимости в архитектуре существующих систем, где модульность без понимания контекста оказывается иллюзией контроля. Андрей Колмогоров однажды заметил: «Математика — это искусство находить закономерности в хаосе». В контексте NL2Repo-Bench, поиск закономерностей проявляется в способности агента последовательно строить сложную систему из отдельных элементов, обеспечивая её функциональность и целостность. Если система держится на костылях, значит, мы переусложнили её, и необходимо вернуться к более элегантному и понятному решению.
Что дальше?
Представленный анализ, фокусируясь на генерации полноценных репозиториев из естественного языка, обнажил фундаментальную сложность: долгосрочное рассуждение, необходимое для создания согласованного программного обеспечения, остаётся непостижимым для существующих систем. NL2Repo-Bench не просто выявляет недостатки, а скорее указывает на то, что оценка возможностей кодовых агентов требует переосмысления. Недостаточно проверять отдельные фрагменты кода; необходимо оценивать способность системы поддерживать целостность проекта на протяжении всего его жизненного цикла.
Будущие исследования должны сместить акцент с простого увеличения масштаба моделей на разработку принципиально новых подходов к представлению знаний и планированию. Иллюзия “автономной разработки” рискует заслонить собой необходимость чётких границ и понятных интерфейсов между человеком и машиной. Важно помнить, что элегантная система не возникает из сложности, а из ясности её структуры.
Возникает закономерный вопрос: не является ли погоня за полным автоматическим созданием репозиториев утопией? Возможно, истинная ценность кроется не в замене программиста, а в создании инструментов, которые расширяют его возможности, позволяя ему сосредотачиваться на более сложных и творческих задачах. В конечном итоге, устойчивость системы определяется не количеством строк кода, а качеством её архитектуры.
Оригинал статьи: https://arxiv.org/pdf/2512.12730.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Сила в Модели: Ограничения Оптимизации в Математических Задачах
- Молекулярный интеллект: проверка химического мышления
- Искусственный интеллект и закон: гармония неизбежна
- Квантовые вычисления для молекул: оптимизация ресурсов
- QR-разложение для экстремальных матриц: новый взгляд на GPU
- Моделирование биомолекул: новый импульс от нейросетей
- Видео по законам физики: новый подход к генерации реалистичных роликов
- Квантовый усилитель амплитуды: новый подход к поиску основного состояния
- Звук как помощник зрения: Новые горизонты генерации видео
- Квантовая синхронизация: новый взгляд на генератор Ван дер Поля
2025-12-16 16:52