Автор: Денис Аветисян
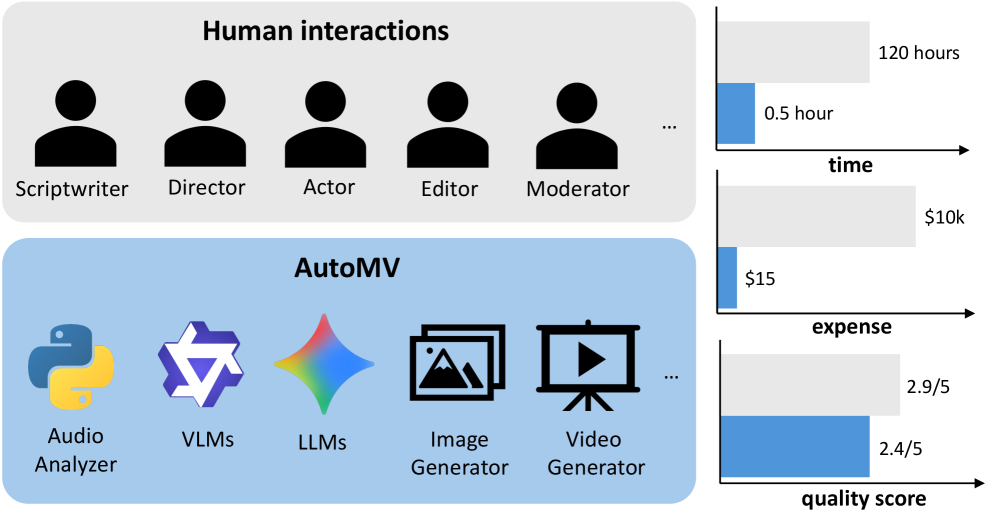
Новая система AutoMV позволяет автоматически создавать полноценные музыкальные клипы, сопоставимые по качеству с работами профессиональных режиссеров.
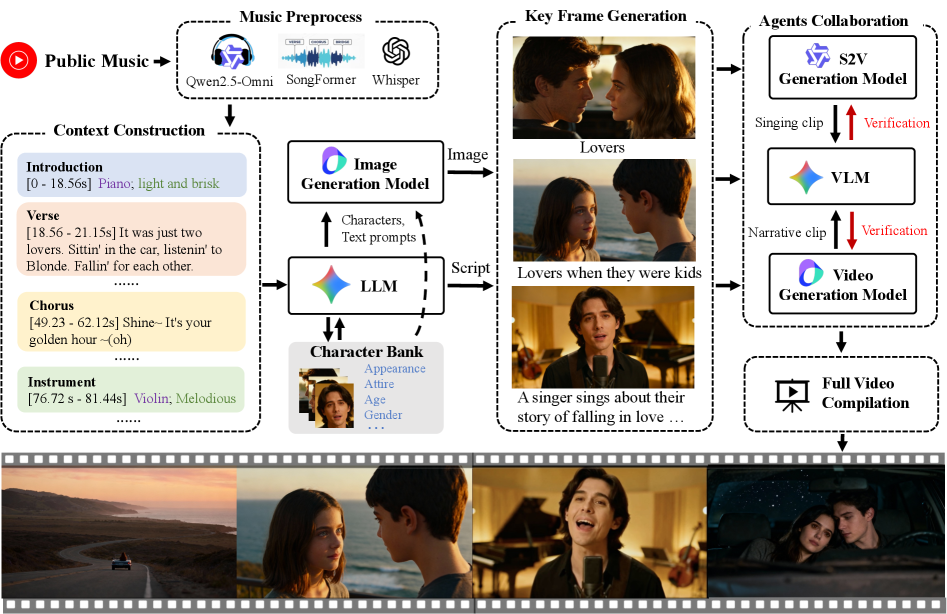
Представлена многоагентная система для автоматической генерации длинных видеороликов на основе музыкального сопровождения, демонстрирующая превосходство над существующими решениями.
Создание полноформатных музыкальных видеороликов автоматически представляет собой сложную задачу, поскольку существующие подходы, как правило, генерируют разрозненные фрагменты, не синхронизированные с музыкальной структурой. В данной работе представлена система AutoMV: An Automatic Multi-Agent System for Music Video Generation, использующая многоагентный подход для автоматического создания связных музыкальных видеороликов непосредственно из аудиодорожки. Система демонстрирует результаты, сопоставимые с профессионально созданными видеороликами и значительно превосходящие существующие автоматизированные методы. Возможно ли дальнейшее повышение качества автоматически генерируемого контента за счет интеграции более сложных мультимодальных моделей и совершенствования алгоритмов оценки?
За пределами коротких роликов: вызовы длинного формата
Современные инструменты для автоматической генерации музыкальных видео, такие как OpenArt и Revid.ai, зачастую сталкиваются с существенными трудностями при создании связного контента продолжительного формата. В то время как генерация коротких роликов демонстрирует неплохие результаты, попытки создать полноценное музыкальное видео, длящееся несколько минут, часто приводят к фрагментарности и потере логической связи между отдельными кадрами. Эта проблема обусловлена сложностью поддержания визуальной когерентности на протяжении длительного времени, когда необходимо не просто последовательно накладывать клипы, а формировать единое повествование, соответствующее музыкальной структуре и эмоциональному посылу композиции. В результате, даже при использовании передовых алгоритмов, длительные видеоролики, сгенерированные этими инструментами, демонстрируют более низкие показатели согласованности визуального ряда с музыкой, что негативно сказывается на общем восприятии и эстетическом удовольствии от просмотра.
Для создания захватывающих многоминутных видеосюжетов недостаточно простого склеивания отдельных клипов. Эффективное повествование требует целостного планирования, где каждый визуальный элемент органично вписывается в общую структуру и музыкальное сопровождение. Исследователи отмечают, что традиционные методы, фокусирующиеся на последовательном соединении коротких фрагментов, не способны обеспечить последовательность и логичность на протяжении всего видеоряда. Вместо этого, необходимо разработать системы, способные учитывать динамику музыкального произведения, эмоциональный тон и сюжетную линию, чтобы визуальный ряд не просто соответствовал музыке, но и усиливал её воздействие, создавая единое, гармоничное произведение искусства. Такой подход предполагает предварительное моделирование сцен, определение ключевых визуальных моментов и их синхронизацию с музыкальными акцентами, что позволяет избежать хаотичности и обеспечить зрительское восприятие как логичное и увлекательное путешествие.
Существующие методы генерации видеоматериалов зачастую демонстрируют ограниченную способность к последовательному сопоставлению визуального контента со сложной структурой музыкального сопровождения во времени. Это несоответствие приводит к снижению показателей ImageBind — метрики, оценивающей мультимодальную согласованность видео и аудио. В результате, сгенерированные ролики, несмотря на отдельные привлекательные кадры, часто кажутся фрагментированными и лишены целостности повествования, что существенно отличает их от профессионально смонтированных видеоматериалов, где визуальные элементы органично дополняют и усиливают музыкальное произведение. Неспособность поддерживать долгосрочную согласованность между визуальным рядом и музыкальной композицией является ключевым препятствием на пути к созданию действительно захватывающих и продолжительных видеороликов.

AutoMV: Многоагентный конвейер целостного создания
AutoMV использует многоагентный конвейер, в котором специализированные агенты отвечают за отдельные аспекты создания музыкального видео. Такая архитектура позволяет разделить сложный процесс на управляемые модули, каждый из которых оптимизирован для конкретной задачи — от планирования сцен и генерации визуальных сценариев до непосредственного создания видеоклипов. Разделение ответственности между агентами повышает эффективность и масштабируемость системы, обеспечивая возможность параллельной обработки различных этапов производства и более точного контроля над конечным результатом. Каждый агент функционирует как независимый компонент, взаимодействующий с другими для достижения общей цели — создания целостного музыкального видео.
Агент Gemini Director выполняет планирование границ кадров и генерирует визуальные сценарии непосредственно на основе музыкального сопровождения и текста песни, обеспечивая контроль над творческим процессом. Этот агент анализирует музыкальную структуру, темп и лирическое содержание для определения оптимальных моментов для смены кадров и визуальных акцентов. В результате формируется детальный сценарий, описывающий последовательность кадров, их продолжительность и предполагаемые визуальные элементы, служащий основой для последующей генерации видеоматериалов. Использование музыки и лирики в качестве входных данных позволяет агенту создавать визуальные решения, тесно связанные с содержанием и эмоциональным посылом произведения.
Интеграция генерации видео из текста позволяет преобразовывать визуальный сценарий, сформированный агентом-режиссером, в конкретные видеофрагменты, служащие основой для повествования. Этот процесс предполагает использование моделей преобразования текста в видео, которые интерпретируют текстовые описания сцен, объектов и действий, содержащихся в сценарии, и генерируют соответствующие визуальные элементы. Полученные видеофрагменты затем объединяются в последовательность, формируя базовую структуру музыкального видеоклипа и обеспечивая визуальное воплощение музыкального произведения и лирики.
Модульный подход в AutoMV позволяет проводить целенаправленную оптимизацию каждого компонента конвейера создания музыкальных видео. Разделение процесса на отдельные агенты — планирование сцен, генерацию визуальных сценариев и синтез видеоклипов — обеспечивает возможность улучшения производительности и художественного качества каждого этапа независимо. Такая декомпозиция позволяет применять специализированные методы оптимизации для каждой задачи, что в конечном итоге приводит к повышению общей эффективности системы и приближению качества генерируемых видео к уровню, достижимому при ручном создании человеком.
Обеспечение достоверности: согласованность и физический реализм
Агент Gemini Verifier осуществляет оценку сгенерированных видеоклипов на предмет физической правдоподобности, предотвращая появление нереалистичных или резко отличающихся от нормы движений. Этот процесс включает в себя анализ траекторий движения объектов, ускорения и других физических параметров для выявления несоответствий законам физики. В частности, агент проверяет согласованность движений с гравитацией, инерцией и другими фундаментальными принципами, что позволяет избежать визуальных артефактов и повысить общее качество и реалистичность генерируемого контента. Выявление и устранение таких несоответствий критически важно для создания убедительных и правдоподобных видеоматериалов.
Поддержание согласованности персонажей является критически важным фактором для обеспечения связности повествования, и активно обеспечивается на протяжении всего процесса генерации видео. Система AutoMV использует алгоритмы отслеживания и анализа визуальных характеристик персонажей — включая внешность, позу и анимацию — для гарантии, что персонаж остается узнаваемым и ведет себя логично от кадра к кадру. В процессе генерации регулярно проводятся проверки на соответствие визуального представления персонажа его заданным характеристикам и предыдущим действиям, что позволяет избежать внезапных изменений внешности или поведения, способных нарушить целостность повествования. Это достигается путем применения специализированных моделей, обученных на больших наборах данных, что обеспечивает высокую точность и надежность в поддержании визуальной идентичности персонажей.
Для проверки согласованности между аудио, видео и текстовыми запросами используется модель ImageBind. Этот подход позволяет оценивать мультимодальную когерентность генерируемого контента, обеспечивая соответствие визуальных и звуковых элементов заданным текстовым инструкциям. В результате применения ImageBind для верификации, AutoMV демонстрирует более высокие оценки ImageBind по сравнению с базовыми методами, что свидетельствует о повышенном уровне согласованности между различными модальностями генерируемого видео.
Процесс верификации, включающий оценку физической правдоподобности и соответствия мультимодальных данных, направлен на обеспечение реалистичности и целостности генерируемых AutoMV видео. Это достигается путем проверки соответствия движений физическим законам и согласованности между визуальным рядом, аудио и текстовым описанием. В результате, генерируемый контент не только демонстрирует творческий подход, но и воспринимается пользователем как правдоподобный и убедительный, что повышает общее качество и вовлеченность.
Объективная оценка и будущее автоматизированного повествования
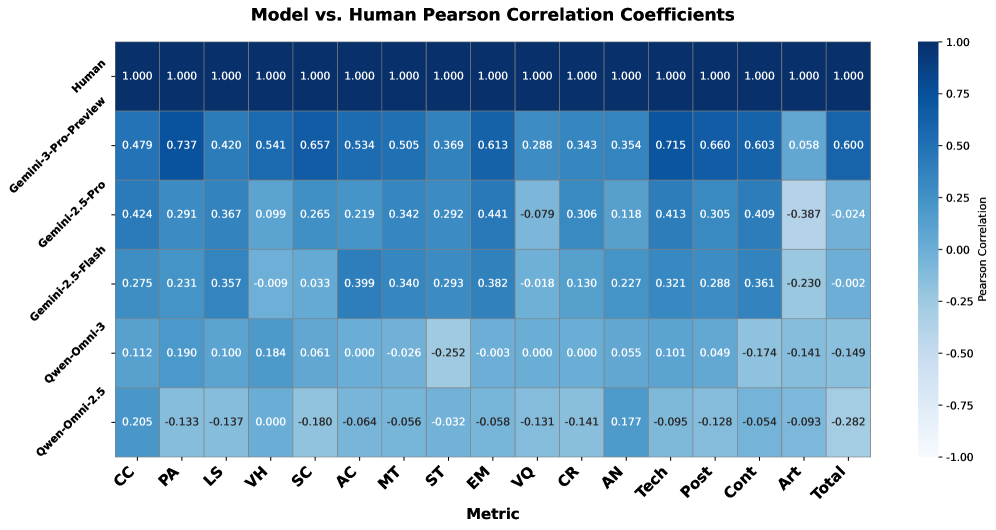
Для объективной оценки сгенерированных системой AutoMV музыкальных видеороликов была разработана система судейства на основе большой языковой модели (LLM). Эта модель анализирует видео, оценивая соответствие визуального ряда музыкальному сопровождению — так называемое выравнивание “музыка-видео” — а также общую эстетическую привлекательность ролика. В отличие от субъективных оценок, LLM обеспечивает последовательную и непредвзятую метрику, позволяющую точно измерить качество генерируемого контента. Такой подход позволяет количественно оценить прогресс в области автоматизированного создания видео и сравнить различные алгоритмы, открывая новые возможности для развития автоматического создания контента.
Автоматизированная оценка, разработанная для системы AutoMV, представляет собой последовательный и непредвзятый инструмент для анализа эффективности генерируемых музыкальных видеороликов. В отличие от субъективных оценок, основанных на человеческом восприятии, данный метод использует чёткие критерии для измерения соответствия видео музыкальному сопровождению и общего эстетического качества. Результаты исследований демонстрируют, что оценки, полученные с помощью этого автоматизированного подхода, приближаются к оценкам, которые выставляют люди эксперты, что указывает на высокую степень реалистичности и привлекательности созданного контента. Это позволяет объективно сравнивать различные подходы к автоматической генерации видео и эффективно оптимизировать алгоритмы для достижения наилучших результатов, приближая возможность создания полностью автоматизированных систем повествования.
Система AutoMV превзошла существующие коммерческие инструменты в области автоматического создания видеоконтента, демонстрируя впечатляющий потенциал многоагентных систем в сфере креативной генерации. Данное достижение указывает на перспективность подхода, при котором взаимодействие нескольких специализированных агентов позволяет создавать сложные и эстетически привлекательные произведения. В отличие от традиционных методов, AutoMV не просто автоматизирует рутинные задачи, но и обеспечивает новый уровень творческой свободы и гибкости, открывая возможности для генерации разнообразного и оригинального контента. Успех системы подчеркивает, что многоагентные системы способны не только имитировать, но и расширять границы человеческого творчества в области визуального искусства и повествования.
Данное исследование открывает перспективы для создания полностью автоматизированных систем повествования, способных генерировать захватывающие и развернутые истории в различных медиаформатах. Разработанный подход демонстрирует, что искусственный интеллект способен не только создавать отдельные элементы контента, такие как музыкальные видео, но и объединять их в последовательное и осмысленное повествование. Это означает, что в будущем возможно создание автоматизированных систем, которые смогут самостоятельно разрабатывать сюжеты, создавать визуальные образы и музыкальное сопровождение, генерируя полноценные истории для фильмов, игр, виртуальной реальности и других медиа. Такие системы, используя принципы многоагентного взаимодействия и объективной оценки качества, способны преодолеть ограничения существующих инструментов и предложить новые возможности для творчества и развлечений.
Разработка AutoMV демонстрирует стремление к упрощению сложного процесса создания музыкальных видео. Система, основанная на взаимодействии множества агентов, избегает излишней детализации, фокусируясь на достижении когерентности и соответствия аудиовизуальному контенту. Это соответствует убеждению, что истинное мастерство заключается не в добавлении сложности, а в ее устранении. Тим Бернерс-Ли однажды заметил: «Веб должен быть для всех, и он должен быть доступным для всех». Аналогично, AutoMV стремится сделать создание видеоконтента доступным и понятным, избегая ненужных усложнений в алгоритмах и процессах. Подобный подход подчеркивает, что эффективность достигается через ясность и лаконичность, а не через избыточность.
Что дальше?
Представленная работа демонстрирует возможность автоматической генерации длинных видеороликов, что, однако, не отменяет фундаментальной проблемы: оценка соответствия аудио и видео. Абстракции стареют, принципы — нет. Текущие метрики, основанные на LLM, представляют собой лишь прокси, удобные, но далекие от истинного восприятия. Каждая сложность требует алиби. Необходимо разработать более надежные, объективные способы измерения аудио-визуальной согласованности, учитывающие не только поверхностное соответствие, но и эмоциональное воздействие.
Система, основанная на многоагентном подходе, показала свою эффективность, но её масштабируемость и адаптивность к различным музыкальным жанрам остаются открытыми вопросами. Автоматизация контента — это не просто замена человеческого труда, а создание новых возможностей для самовыражения. Следующим шагом видится не столько повышение реалистичности генерируемых видео, сколько предоставление пользователю инструментов для тонкой настройки и контроля над творческим процессом.
В конечном итоге, задача заключается не в создании идеального генератора видеороликов, а в понимании того, как музыка и визуальные образы взаимодействуют друг с другом, и как эти взаимодействия могут быть воспроизведены с помощью искусственного интеллекта. Сложность — это тщеславие. Ясность — милосердие. Необходимо сосредоточиться на принципах, а не на деталях.
Оригинал статьи: https://arxiv.org/pdf/2512.12196.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые вычисления для молекул: оптимизация ресурсов
- Сила в Модели: Ограничения Оптимизации в Математических Задачах
- Искусственный интеллект и закон: гармония неизбежна
- Стиль сквозь века: математика искусства
- Диалоги с Искусственным Интеллектом: Как Проверить Надежность?
- QR-разложение для экстремальных матриц: новый взгляд на GPU
- Квантовая устойчивость к ошибкам: новый взгляд на исправление вставок и удалений
- Оптимизация процессов: симбиоз классических и квантовых вычислений
- Молекулярный интеллект: проверка химического мышления
- Квантовый поиск без колебаний: новый подход к алгоритму Гровера
2025-12-17 03:03