Автор: Денис Аветисян
Новый подход позволяет создавать правдоподобные движения головы в 3D-анимации, синхронизированные с речью и учитывающие контекст диалога.

Предложена архитектура TIMAR, использующая каузальное моделирование на уровне реплик и диффузионные модели для генерации когерентных аудиовизуальных последовательностей.
Несмотря на важность невербальной коммуникации, существующие модели генерации 3D-анимации головы часто игнорируют причинно-следственные связи между репликами в диалоге. В данной работе, ‘Towards Seamless Interaction: Causal Turn-Level Modeling of Interactive 3D Conversational Head Dynamics’, предложен фреймворк TIMAR, моделирующий интерактивные диалоги как последовательность взаимосвязанных аудиовизуальных контекстов на уровне отдельных реплик. Это позволяет генерировать реалистичные и когерентные движения головы в 3D, учитывая как координацию, так и экспрессивность. Сможет ли подобный подход приблизить нас к созданию действительно убедительных виртуальных собеседников и роботов?
За пределами Статичных Моделей: Поиск Причинно-Следственной Связи
Существующие методы генерации 3D-моделей говорящих голов часто сталкиваются с проблемой временной согласованности и реалистичности взаимодействия, что приводит к ощущению отстраненности в виртуальном общении. Недостаточная способность сохранять последовательность движений и выражений во времени создает иллюзию неестественности, препятствуя установлению полноценного контакта с виртуальным собеседником. В результате, даже визуально правдоподобные модели могут казаться безжизненными и неспособными к адекватному реагированию на происходящее, что существенно снижает эффект присутствия и реалистичность виртуальной коммуникации. Эта проблема особенно актуальна в контексте развития метавселенных и виртуальной реальности, где правдоподобное взаимодействие с цифровыми аватарами является ключевым фактором для создания иммерсивного опыта.
Существующие системы генерации реалистичных говорящих голов, такие как DualTalk, часто сталкиваются с проблемой отсутствия причинно-следственной связи между репликами. Это означает, что сгенерированные ответы не всегда логически вытекают из предыдущего контекста беседы, что приводит к неестественным и прерывистым диалогам. В результате, подобные системы не способны обеспечить по-настоящему интерактивный опыт, поскольку сгенерированные выражения лица и артикуляция не отражают динамическое влияние предыдущих реплик на текущую речь. Отсутствие этой причинно-следственной связи ограничивает возможности создания убедительных виртуальных собеседников, способных поддерживать плавные и реалистичные разговоры.
Основная сложность в создании реалистичных “говорящих голов” заключается не только в воспроизведении произносимых слов, но и в моделировании того, как эти слова динамически влияют на последующие выражения лица и мимику в контексте беседы. Представленная разработка решает эту проблему, последовательно превосходя существующие системы, такие как DualTalk, по ключевым показателям: Fidelity (FD), Percentage of Fidelity (P-FD), среднеквадратичной ошибке (MSE), коэффициенту корреляции Пирсона (rPCC) и Structural Index Measure (SID). Данные результаты свидетельствуют о значительном улучшении реалистичности и когерентности генерируемых видео, позволяя добиться более правдоподобного и естественного взаимодействия в виртуальной среде.
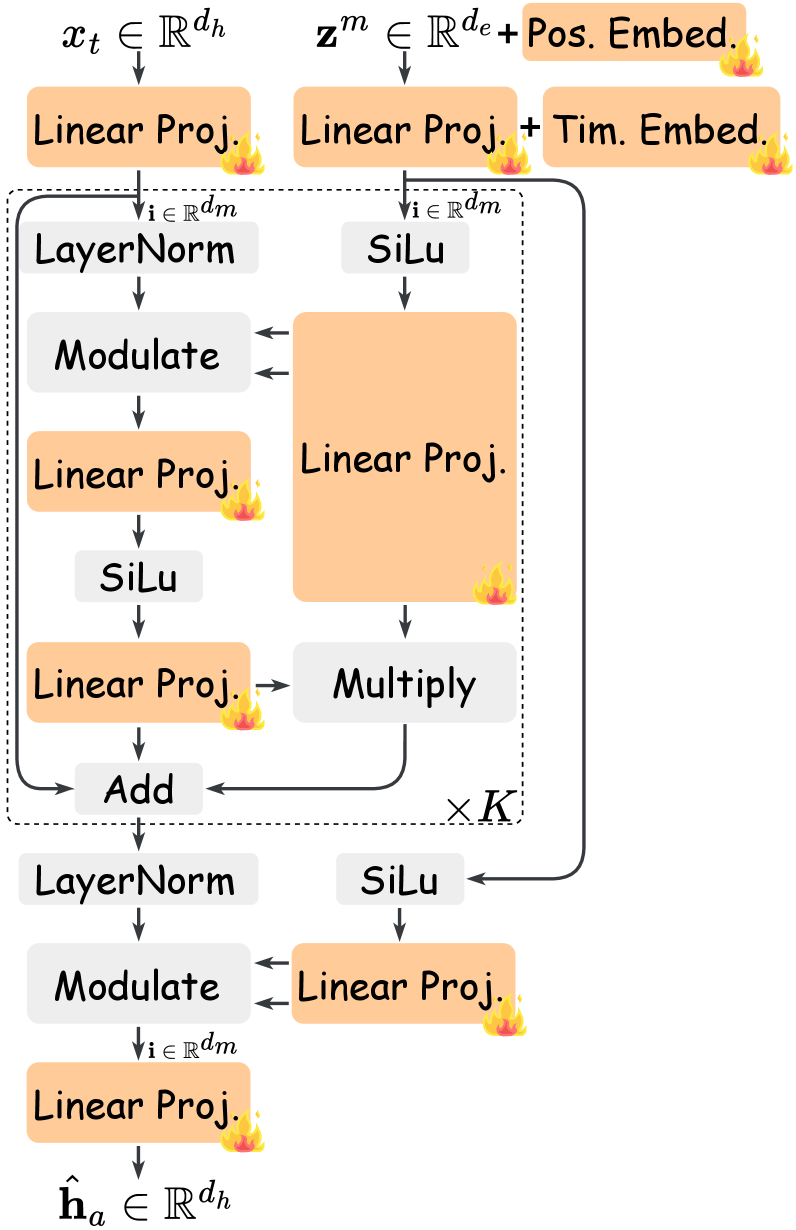
TIMAR: Причинно-Следственная Основа Интерактивных Голов
Метод TIMAR рассматривает генерацию 3D-моделей головы как задачу последовательного, причинно-следственного предсказания, разделенного на отдельные ходы (turn-wise). Такой подход позволяет осуществлять потоковую генерацию (streaming compatibility), поскольку каждый новый кадр генерируется на основе предыдущих, а не требует полной информации о всей последовательности. Причинная структура гарантирует, что генерация текущего кадра зависит только от предыдущих, что необходимо для создания реалистичных и когерентных ответов в интерактивных сценариях, предотвращая использование информации из «будущего» и обеспечивая временную согласованность. В рамках этой модели каждый ход рассматривается как независимая единица предсказания, что упрощает обучение и повышает эффективность генерации.
В основе TIMAR лежит механизм перемежающегося мультимодального слияния, объединяющий аудио- и визуальные токены от обоих участников диалога в единую последовательность. Данный процесс предполагает конкатенацию токенов, представляющих аудио- и видеоданные каждого говорящего, формируя непрерывный поток информации. Это позволяет модели учитывать как речевые, так и визуальные сигналы от обоих участников одновременно, что критически важно для понимания контекста и генерации реалистичных ответов. Входные данные преобразуются в дискретные токены, используя соответствующие кодеки для аудио и видео, что обеспечивает эффективную обработку и возможность масштабирования модели $TIMAR$.
Механизм внимания на уровне реплики (Turn-Level Causal Attention) в TIMAR обеспечивает как двунаправленное внимание внутри каждой реплики диалога, позволяя учитывать контекст как до, так и после текущего момента, так и строгие причинно-следственные ограничения между репликами. Это означает, что при обработке текущей реплики, модель имеет доступ только к информации из предыдущих реплик и текущей, исключая доступ к будущим данным. Такая архитектура критически важна для обеспечения когерентности и реалистичности взаимодействия, предотвращая «заглядывание в будущее» и обеспечивая последовательное формирование ответов на основе доступного контекста. Это достигается путем маскирования будущего контекста в матрице внимания, гарантируя, что каждое предсказание основано только на прошлых и текущих данных.

Диффузия Реализма: Генерация Естественных Движений Головы
В TIMAR используется облегченная диффузионная головка (Lightweight Diffusion Head), представляющая собой диффузионный декодер, моделирующий 3D-движения головы как непрерывный вероятностный процесс. Вместо дискретных кадров или ключевых поз, система генерирует движения, рассматривая их как выборку из вероятностного распределения. Это позволяет создавать более плавные и естественные движения, улавливая тонкие вариации, которые сложно смоделировать традиционными методами. Диффузионный подход позволяет учитывать неопределенность и случайность, присущие реальным движениям головы, обеспечивая более реалистичные результаты.
Диффузионная модель обеспечивает надежный механизм генерации высококачественных и реалистичных движений головы, обусловленных объединенным мультимодальным контекстом. Этот подход позволяет моделировать сложные и тонкие вариации движений, используя вероятностный процесс диффузии. В частности, модель учитывает информацию из различных источников, таких как аудио и визуальные данные, для создания согласованных и правдоподобных движений головы. Условная генерация, основанная на объединенном контексте, позволяет контролировать и направлять процесс генерации движений, обеспечивая соответствие движениям контексту и намерению.
Для функционирования диффузионной модели в TIMAR используются специализированные компоненты, преобразующие исходные данные в токенизированное представление. Речевой токенизатор (Speech Tokenizer) обрабатывает аудиозапись, выделяя и кодируя лингвистически значимые единицы. Параллельно, 3D Head Motion Encoder анализирует данные о движении головы, формируя векторное представление, отражающее позу и динамику. Оба этих процесса приводят к созданию дискретных токенов, которые служат входными данными для диффузионной модели, позволяя ей генерировать реалистичные движения головы на основе мультимодального контекста.
Обучение Когерентности: Освоение Контекстуального Ландшафта
Модель TIMAR обучается с использованием метода маскированных токенов (Masked Tokens), при котором часть входных данных намеренно скрывается. Этот подход заставляет модель прогнозировать пропущенную информацию, опираясь на контекст оставшихся токенов. В процессе обучения модель анализирует взаимосвязи между токенами, что способствует более глубокому пониманию контекстуальных зависимостей и повышает ее способность к генерации когерентных последовательностей. Эффективность метода заключается в том, что модель учится не просто запоминать данные, а активно извлекать и использовать информацию из окружающего контекста для восстановления пропущенных фрагментов.
Авторегрессионная генерация предполагает последовательный, поэтапный процесс создания данных, где каждый следующий элемент определяется на основе всех предыдущих. Такой подход обеспечивает временную согласованность генерируемых последовательностей, поскольку модель учитывает историю данных при предсказании следующих шагов. В контексте моделирования движения головы, это позволяет создавать реалистичную динамику, избегая резких и неестественных переходов, поскольку каждое новое положение головы логически вытекает из предыдущих положений и учитывает временные зависимости. Фактически, модель предсказывает следующий кадр, основываясь на всех предыдущих кадрах, и этот процесс повторяется для создания полной последовательности движения.
Механизм Classifier-Free Guidance позволяет точно настроить чувствительность модели к контекстным сигналам, что напрямую влияет на качество генерируемых движений головы. В отличие от традиционных методов, требующих отдельного классификатора для определения контекста, Classifier-Free Guidance использует единую модель, обученную как для предсказания движения, так и для оценки контекста. При генерации, модель получает как входные данные, так и «нулевой» контекст, что позволяет контролировать степень влияния контекстных сигналов на результат и, следовательно, улучшить реалистичность и соответствие сгенерированных движений головы заданному контексту. Регулировка веса контекстного сигнала позволяет добиться оптимального баланса между следованием контексту и сохранением естественности движений.
Будущее Интерактивных Агентов: К Правдоподобному Общению
Технология TIMAR представляет собой значительный прорыв в области генерации трехмерных говорящих голов, обеспечивая повышенную временную согласованность и реалистичность взаимодействия. В отличие от предыдущих решений, TIMAR позволяет создавать виртуальные образы, чья речь и мимика выглядят естественно и последовательно во времени, что крайне важно для убедительности. Ключевым преимуществом является возможность потоковой передачи данных в реальном времени, что делает технологию применимой в широком спектре задач, от видеоконференций и онлайн-игр до создания виртуальных ассистентов и интерактивных обучающих систем. Благодаря оптимизации алгоритмов, TIMAR обеспечивает плавную и реалистичную анимацию даже при ограниченных вычислительных ресурсах, открывая новые возможности для создания захватывающих и иммерсивных виртуальных опытов.
Технология TIMAR делает акцент на причинно-следственной связи в процессе генерации речи и мимики, что принципиально отличает её от предшественников. Вместо простого последовательного воспроизведения движений, система стремится к созданию правдоподобной взаимосвязи между речью и выражением лица. Это означает, что мимика персонажа не является случайной, а логически вытекает из содержания сказанного, имитируя естественные процессы человеческого общения. Такой подход позволяет создавать виртуальных агентов, способных поддерживать более убедительные и захватывающие диалоги, поскольку их поведение воспринимается как более осмысленное и последовательное. В результате, взаимодействие с такими агентами становится более комфортным и естественным для пользователя, открывая новые возможности в сферах виртуальной коммуникации, игр и вспомогательных технологий.
Технология TIMAR открывает новые горизонты в области виртуального общения, обещая более захватывающий и естественный опыт взаимодействия в различных сферах. В частности, она способна кардинально улучшить качество виртуальных встреч, делая их более реалистичными и продуктивными, а также углубить погружение в игровые миры, создавая более убедительных и эмоциональных персонажей. Кроме того, потенциал TIMAR огромен в области вспомогательных технологий, предоставляя более интуитивные и эффективные средства коммуникации для людей с ограниченными возможностями. Результаты сравнительных тестов демонстрируют значительное превосходство TIMAR над DualTalk: снижение показателей FD, P-FD и MSE, а также повышение значений rPCC и SID, что подтверждает существенные улучшения в реалистичности и правдоподобности генерируемых изображений и движений.
Исследование, представленное в данной работе, демонстрирует неизбежный компромисс между теоретической элегантностью и практической реализацией. Моделирование диалога как причинно-следственного процесса на уровне реплик, с чередованием аудио-визуальных токенов, — это попытка обуздать хаос взаимодействия. Однако, как показывает опыт, даже самая продуманная архитектура, основанная на причинности, рано или поздно столкнется с непредсказуемостью реальных данных. Эндрю Ын однажды заметил: «Мы не должны стремиться к идеальным моделям, а к моделям, которые достаточно хороши для решения конкретной задачи». И это абсолютно верно: в конечном итоге, важна не теоретическая чистота, а способность системы функционировать в условиях неконтролируемой энтропии.
Что дальше?
Представленная работа, безусловно, демонстрирует прогресс в создании более реалистичных 3D-моделей головы, имитирующих разговор. Однако, каждый новый уровень реализма лишь обнажает новые сложности. Моделирование “поворотов” в диалоге — это хорошо, но что насчёт невербальных сигналов, которые не укладываются в чёткие временные рамки? Каждая «идеальная» синхронизация аудио и видео — лишь временная иллюзия перед лицом хаоса реальных разговоров.
Очевидно, что проблема не ограничивается лишь генерацией движения. Производственная среда, рано или поздно, потребует масштабирования, интеграции с различными платформами и, что неизбежно, столкнётся с непредсказуемыми пользовательскими сценариями. Будущие исследования, вероятно, будут сосредоточены на робастности моделей к шуму, адаптации к различным акцентам и эмоциональным состояниям, и, конечно же, на снижении вычислительных затрат.
Всё, что можно задеплоить — однажды упадёт. Но, как минимум, эта модель умирает красиво. Следующим шагом, вероятно, станет попытка создать не просто реалистичную имитацию, а систему, способную понимать контекст и генерировать действительно осмысленные и адаптивные реакции. Задача сложная, но, как известно, красота в сложности.
Оригинал статьи: https://arxiv.org/pdf/2512.15340.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Укрощение Бесконечности: Алгебраические Инструменты для Кватернионов и За их Пределами
- Сияние фотонов: новый уровень точности в предсказаниях столкновений частиц
- Эхо чёрных дыр: как квантовая гравитация меняет гравитационные волны
- Трансформация нейросетей: от плотных моделей к разреженным экспертам без обучения
- Квантовая Физика и Безопасность: Анализ Последних Новостей
- Биосети в руках ИИ: Автоматизация системной фармакологии
- Неупорядоченные системы с неэрмитовыми эффектами
- Батарея под контролем: Искусственный интеллект на страже долговечности
- Квантовый поиск гравитационных волн: новый алгоритм для повышения точности
- Оптические Тензорные Ядра: Путь к Масштабируемым Вычислениям
2025-12-18 19:19