Автор: Денис Аветисян
Новая методика позволяет агентам на основе больших языковых моделей динамически совершенствовать свои запросы в процессе работы, что значительно улучшает их производительность и надежность.

В статье представлена система SCOPE, позволяющая агентам адаптировать запросы на основе анализа хода выполнения задач и синтеза инструкций.
Несмотря на растущую мощь языковых моделей, их агенты часто сталкиваются с трудностями в динамически меняющихся контекстах. В статье ‘SCOPE: Prompt Evolution for Enhancing Agent Effectiveness’ представлена новая методика, позволяющая агентам автоматически адаптировать свои запросы на основе анализа траекторий выполнения задач. Предложенный фреймворк SCOPE рассматривает управление контекстом как задачу онлайн-оптимизации, синтезируя руководящие принципы из опыта, что значительно повышает эффективность и надежность агентов. Возможно ли создание действительно самообучающихся агентов, способных решать сложные задачи без вмешательства человека?
Ограничения Современных LLM-Агентов: Когда Ошибки Становятся Препятствием
Несмотря на значительный прогресс в разработке LLM-агентов, они часто сталкиваются с так называемыми «корректирующими ошибками» — ситуациями, когда сообщения об ошибках интерпретируются как критические, требующие немедленной остановки работы, вместо того, чтобы восприниматься как полезные сигналы для корректировки действий. Агенты, столкнувшись с даже незначительной ошибкой, могут преждевременно прекратить выполнение задачи, не пытаясь найти и устранить проблему. Это связано с тем, что они склонны рассматривать любую ошибку как показатель неспособности выполнить задачу, а не как возможность для обучения и улучшения. В результате, даже незначительные технические неполадки могут приводить к полному провалу, ограничивая эффективность и надежность этих систем.
Особую обеспокоенность вызывают так называемые “ошибки улучшения”, когда агенты, даже при отсутствии каких-либо сбоев или ошибок, упускают возможности для оптимизации своей работы и повышения общей эффективности. Данное явление указывает на то, что современные языковые модели, хоть и способны успешно справляться с поставленными задачами, зачастую не проявляют инициативу в самостоятельном поиске путей для улучшения своих алгоритмов и стратегий. Вместо активного анализа контекста и выявления потенциальных улучшений, они ограничиваются выполнением текущих инструкций, что препятствует достижению максимальной производительности и снижает их адаптивность к изменяющимся условиям. Это указывает на необходимость разработки новых подходов к обучению и проектированию агентов, которые бы стимулировали их к проактивному поиску и реализации возможностей для самосовершенствования.
Неспособность современных LLM-агентов эффективно справляться с задачами часто объясняется их реактивным подходом к управлению контекстом. Вместо того, чтобы активно предвидеть потенциальные проблемы или возможности для улучшения, агент реагирует лишь на уже возникшие ошибки или отсутствие прогресса. Это означает, что агент не анализирует текущую ситуацию с целью выявления скрытых закономерностей или оптимизаций, а лишь выполняет поставленные задачи, пока не столкнется с препятствием. Такой подход ограничивает возможности агента по самосовершенствованию и адаптации к меняющимся условиям, приводя к упущенным возможностям для повышения производительности и, в конечном итоге, к «коррективным» и «улучшающим» неудачам, которые препятствуют достижению оптимальных результатов.

SCOPE: Саморазвивающаяся Оптимизация Контекста
Традиционные языковые модели часто используют статические “системные промпты” для определения контекста и направления поведения. Однако, SCOPE представляет собой новый подход к динамическому управлению контекстом, отказавшись от этой статической конфигурации. Вместо этого, SCOPE использует адаптивные механизмы, позволяющие модели изменять и оптимизировать контекст в процессе работы, реагируя на входные данные и текущие результаты. Это обеспечивает большую гибкость и эффективность по сравнению с жестко заданными промптами, позволяя модели лучше адаптироваться к различным задачам и ситуациям без необходимости ручной перенастройки.
Механизм “Perspective-Driven Exploration” в SCOPE предполагает одновременную эволюцию нескольких параллельных запросов (промптов). Этот подход позволяет исследовать различные стратегии решения задачи и обеспечивает более широкое покрытие возможных сценариев. Параллельное развитие промптов, каждое из которых представляет собой определенную перспективу или подход, увеличивает устойчивость системы к непредсказуемым входным данным и повышает вероятность нахождения оптимального решения, даже в сложных и неоднозначных ситуациях. Разнообразие перспектив минимизирует зависимость от единой стратегии и повышает общую надежность системы.
Двухпоточная маршрутизация (Dual-Stream Routing) в SCOPE обеспечивает эффективное управление поведением агента посредством балансировки между тактическими и стратегическими обновлениями. Тактические обновления направлены на немедленную коррекцию ошибок в ответах агента, осуществляясь в режиме реального времени на основе анализа текущего взаимодействия. Стратегические обновления, напротив, представляют собой проактивную оптимизацию, направленную на улучшение общей производительности и надежности агента в долгосрочной перспективе, путём адаптации и эволюции используемых подсказок (prompts). Разделение на эти два потока позволяет избежать конфликтов между немедленной коррекцией и долгосрочной оптимизацией, обеспечивая стабильное и предсказуемое поведение агента.

Проверка SCOPE на Продвинутых Бенчмарках: Результаты Говорят Сами За Себя
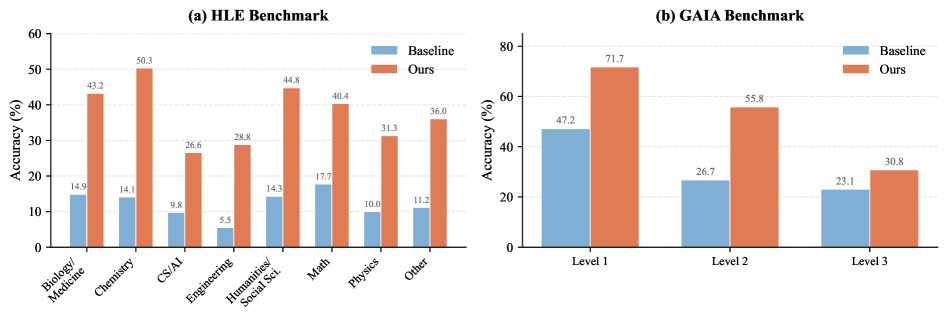
Применение ‘SCOPE’ демонстрирует значительное повышение производительности на бенчмарке ‘HLE’, что указывает на улучшенные возможности рассуждения в сложных сценариях. Результаты показывают увеличение успешности выполнения задач с 14.23% до 38.64%. Данный прирост свидетельствует об эффективности ‘SCOPE’ в решении задач, требующих логического вывода и анализа информации, что подтверждает его потенциал для улучшения производительности в различных областях искусственного интеллекта.
Фреймворк SCOPE продемонстрировал значительное улучшение результатов на бенчмарке GAIA, предназначенном для оценки способностей ИИ-ассистентов в решении задач, приближенных к реальным сценариям использования. Показатель успешного выполнения задач увеличился с 32.73% до 56.97%, что свидетельствует о существенном прогрессе в обработке и решении сложных, многоэтапных запросов, характерных для взаимодействия с виртуальными помощниками.
В ходе тестирования на бенчмарке ‘DeepSearch’ фреймворк ‘SCOPE’ продемонстрировал высокую эффективность в задачах, требующих синтеза информации и сложного поиска. Данный бенчмарк предназначен для оценки способности агентов к извлечению, анализу и объединению данных из различных источников, что подтверждает возможности ‘SCOPE’ в обработке комплексных запросов и предоставлении релевантных результатов. Успешное прохождение ‘DeepSearch’ указывает на потенциал фреймворка в сценариях, связанных с интеллектуальным поиском и анализом больших объемов информации.
Механизм синтеза руководств на основе трассировки (Trace-Based Guideline Synthesis) является ключевым компонентом обучения агента на основе предыдущих взаимодействий, обеспечивая непрерывное улучшение его стратегий. В ходе тестирования на бенчмарке GAIA, применение данного механизма позволило снизить количество ошибок на 253 (с 1714 до 1461) и количество таймаутов на 28 (с 255 до 227), что демонстрирует эффективность подхода к адаптации и повышению надежности агента при решении задач в реальных условиях.
За Пределами Текущих Возможностей: К Проактивным Агентам. Пора Задуматься о Будущем.
Интеграция фреймворка ‘SCOPE’ с методами, такими как ‘RAG’ (Retrieval-Augmented Generation), позволяет значительно расширить возможности языковых моделей-агентов. Вместо того чтобы полагаться исключительно на собственные знания, агенты получают доступ к внешним источникам информации, что критически важно для ответов на сложные и нюансированные запросы. Этот подход обеспечивает не только более точные и полные ответы, но и позволяет агентам эффективно работать с информацией, которая постоянно обновляется или выходит за рамки их первоначального обучения. Благодаря ‘RAG’, агенты способны извлекать релевантные фрагменты из больших объемов данных и использовать их для формирования обоснованных и контекстуально соответствующих ответов, что делает их значительно более полезными и надежными в различных приложениях.
Предложенная архитектура отличается способностью к обучению в процессе работы, что обеспечивается динамическим листом подсказок — ‘DC’. В отличие от систем, требующих переобучения для адаптации к новым данным или задачам, данная система непрерывно совершенствуется, накапливая и используя опыт, полученный во время взаимодействия. ‘DC’ функционирует как постоянно обновляемый свод знаний, позволяющий агенту оперативно корректировать свои действия и стратегии, повышая эффективность решения задач в изменяющейся среде. Такой подход открывает возможности для создания действительно проактивных агентов, способных не только реагировать на запросы, но и предвидеть потенциальные проблемы и оптимизировать процессы на основе накопленного опыта, что значительно расширяет границы их применения.
Предложенный подход выходит за рамки функционирования отдельных агентов, демонстрируя потенциал создания сложных рабочих процессов благодаря координации между ними. Ключевую роль в этом играет так называемый “Агент-планировщик”, который способен распределять задачи между специализированными агентами, такими как, например, “Агент-браузер”. Такая архитектура позволяет эффективно решать многоэтапные задачи, требующие доступа к внешней информации и её последующей обработки. “Агент-планировщик” формирует последовательность действий, делегируя конкретные этапы специализированным агентам, каждый из которых оптимизирован для выполнения определенной функции, что значительно повышает общую эффективность и гибкость системы.
Исследование представляет framework SCOPE, стремящийся к динамической эволюции промптов агентов. Этакий самообучающийся механизм, который, в теории, должен повысить надёжность системы. Однако, как показывает опыт, любая «самовосстанавливающаяся» система просто ещё не столкнулась с достаточным количеством критических ошибок. Как метко заметил Пол Эрдёш: «Документация — это форма коллективного самообмана». Потому что, в конечном итоге, даже самый элегантный алгоритм адаптации промптов не защитит от неизбежных багов, которые всегда найдут способ проявиться в продакшене. Если баг воспроизводится, это, по крайней мере, демонстрирует, что у нас стабильная система — в смысле, что мы можем его стабильно воспроизвести.
Что дальше?
Представленная работа, как и большинство «прорывных» решений, лишь отодвигает проблему, а не решает её. Автоматическая эволюция промптов — это, конечно, изящно, но кто-нибудь подумал о стоимости этого эволюционного процесса? Каждый новый шаг адаптации требует ресурсов, и весьма вероятно, что в реальных условиях система начнет оптимизировать не эффективность, а скорость падения. Если система стабильно падает, значит, хотя бы последовательна. В конце концов, мы не пишем код — мы просто оставляем комментарии будущим археологам, пытающимся понять, зачем мы всё это делали.
Наиболее вероятным направлением развития представляется не поиск идеального алгоритма эволюции, а разработка методов контроля и ограничения этой эволюции. Как остановить процесс, когда агент начинает «оптимизировать» задачу в абсурдном направлении? Как гарантировать, что «саморазвитие» не превратится в бесконечную рекурсию? «Cloud-native» агенты, автоматически адаптирующие промпты… звучит дорого и сложно. Как будто недостаточно было отлаживать существующий код.
В конечном счете, вопрос не в том, чтобы создать самообучающегося агента, а в том, чтобы понять, где заканчивается полезная адаптация и начинается хаос. И, вероятно, ответ на этот вопрос будет куда менее элегантным, чем сама идея автоматической эволюции промптов.
Оригинал статьи: https://arxiv.org/pdf/2512.15374.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Укрощение Бесконечности: Алгебраические Инструменты для Кватернионов и За их Пределами
- Эхо чёрных дыр: как квантовая гравитация меняет гравитационные волны
- Сияние фотонов: новый уровень точности в предсказаниях столкновений частиц
- Квантовая Физика и Безопасность: Анализ Последних Новостей
- Биосети в руках ИИ: Автоматизация системной фармакологии
- Трансформация нейросетей: от плотных моделей к разреженным экспертам без обучения
- Батарея под контролем: Искусственный интеллект на страже долговечности
- Квантовый поиск гравитационных волн: новый алгоритм для повышения точности
- Оптические Тензорные Ядра: Путь к Масштабируемым Вычислениям
- Квантовый скачок в многомасштабном моделировании
2025-12-18 22:46