Автор: Денис Аветисян
Новый бенчмарк VTCBench позволяет оценить способность современных моделей, работающих с изображениями и текстом, к пониманию длинных контекстов, сжатых с помощью методов визуального и текстового сжатия.
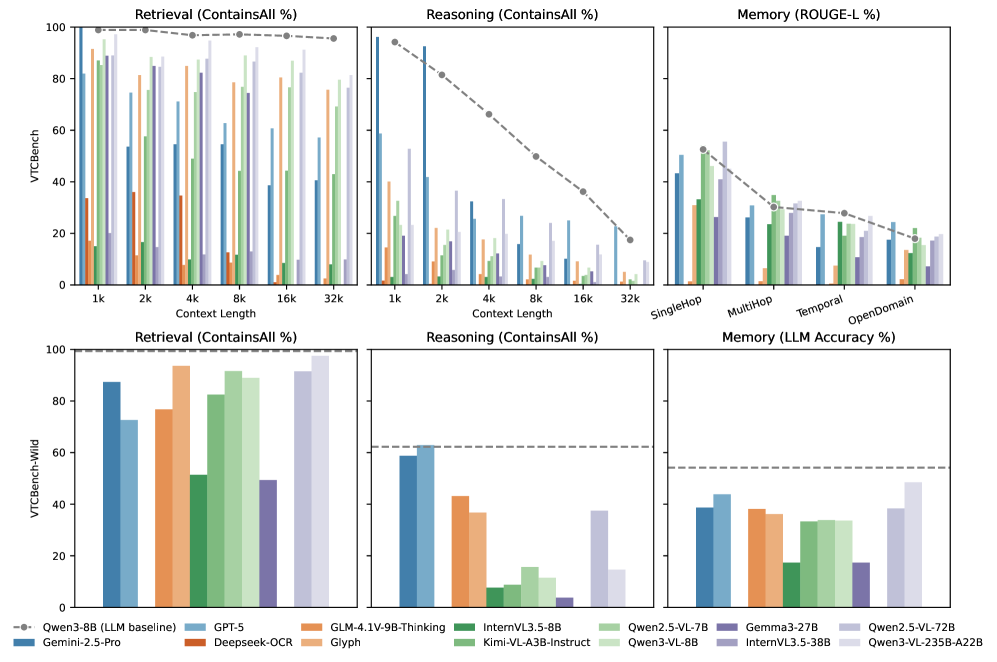
Исследование выявляет значительные ограничения в способности моделей к рассуждению и сохранению информации в сжатых визуальных контекстах, используя бенчмарк VTCBench.
Несмотря на прогресс в расширении контекстного окна больших языковых моделей, обработка длинных последовательностей остается сложной задачей. В данной работе представлена платформа VTCBench: Can Vision-Language Models Understand Long Context with Vision-Text Compression?, предназначенная для систематической оценки возможностей моделей «зрение-язык» в понимании сжатых визуальных представлений текста. Результаты показывают, что существующие модели, несмотря на способность декодировать визуальную информацию, демонстрируют ограниченные возможности в удержании долгосрочных зависимостей и логических связей в сжатых контекстах. Какие архитектурные и методологические решения необходимы для создания более эффективных и масштабируемых моделей «зрение-язык», способных эффективно использовать сжатые визуальные представления длинных текстов?
Преодолевая границы контекста: вызовы масштабирования визуально-языковых моделей
Современные мультимодальные модели, объединяющие зрение и язык, становятся все более важными для решения широкого спектра задач, от автоматического описания изображений до понимания сложных визуальных историй. Однако, их способность обрабатывать длинные последовательности данных ограничена из-за квадратичной сложности механизма внимания. Это означает, что вычислительные затраты и потребление памяти растут пропорционально квадрату длины входной последовательности, что делает обработку длинных видео, книг с иллюстрациями или детализированных сцен практически невозможной. В результате, модели испытывают трудности с установлением долгосрочных связей между элементами визуального и текстового контента, что существенно снижает их эффективность при решении задач, требующих глубокого понимания контекста и логических умозаключений.
Традиционные методы обработки визуально-языковых моделей сталкиваются с серьезным препятствием при работе с расширенными последовательностями данных. Вычислительная сложность, растущая в квадратичной зависимости от длины последовательности, делает анализ длинных текстов и изображений непомерно затратным по ресурсам. Это ограничение существенно снижает способность моделей к глубокому пониманию и логическому выводу, необходимому для задач, требующих анализа сложных визуальных и текстовых повествований. По мере увеличения объема данных, требуемых для обучения и обработки, проблема вычислительной сложности становится все более актуальной, препятствуя дальнейшему развитию и внедрению этих моделей в практические приложения.
Ограничения в обработке длинных последовательностей существенно влияют на способность визуально-языковых моделей (VLM) к глубокому пониманию сложных повествований, сочетающих визуальную и текстовую информацию. Хотя современные VLM стремятся к сжатию входных данных, существующие методы, такие как VTC (Visual Transformer with Context), достигают лишь коэффициента сжатия в 2.0. Это демонстрирует определенный прогресс, но одновременно подчеркивает существенные ограничения, препятствующие эффективной обработке и анализу объемных визуальных сцен и связанных с ними текстовых описаний. Таким образом, способность к полноценному осмыслению сложных повествований остается критической областью для дальнейших исследований и усовершенствования архитектур VLM.
Визуальная компрессия текста: новый взгляд на эффективность
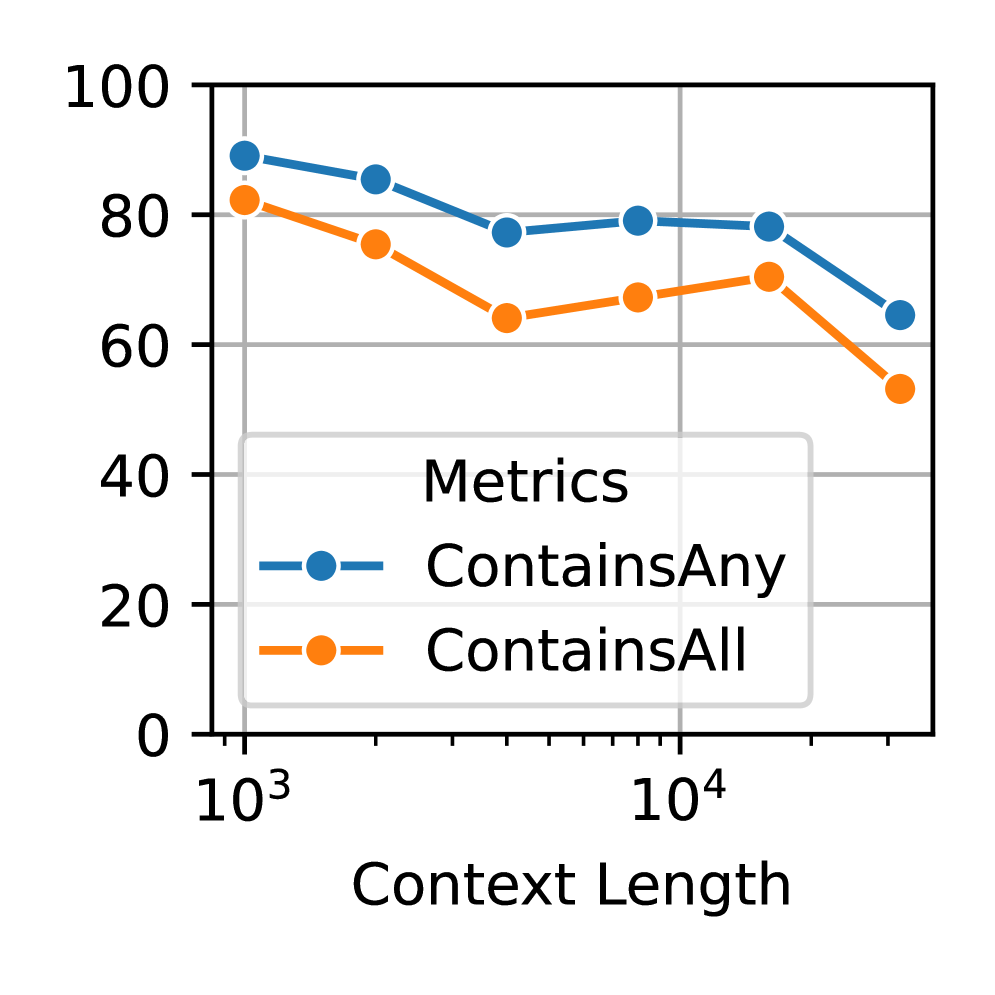
Компрессия Визуального Текста (ВТК) решает проблему масштабируемости больших языковых моделей (LLM) путем преобразования длинных текстовых последовательностей в компактные изображения. Этот подход позволяет значительно снизить количество токенов, необходимых для представления информации, что напрямую влияет на вычислительные затраты и скорость обработки. Вместо обработки последовательности токенов, модель обрабатывает изображение, что позволяет уменьшить объем памяти, требуемой для хранения и обработки данных. Эффективность ВТК заключается в замене линейного представления текста на двумерное, что позволяет упаковать больше информации в меньшем пространстве. Снижение количества токенов является ключевым фактором для работы с большими объемами данных и для повышения производительности LLM в задачах, требующих обработки длинных контекстов.
Процесс Vision-Text Compression (VTC) начинается с токенизации текста, представляющей собой разбиение входной последовательности на отдельные единицы — токены. Эта процедура необходима для последующего преобразования текстовой информации в визуальный формат. Токенизация позволяет структурировать текст, выделяя значимые элементы и подготавливая его к кодированию в пиксельные данные. Использование токенов, а не исходного текста, позволяет значительно уменьшить объем информации, передаваемой в модель, что и обеспечивает сжатие. Количество токенов, полученных в результате разбиения, напрямую влияет на размер результирующего изображения и, следовательно, на степень компрессии.
Технология Vision-Text Compression (VTC) не ограничивается простой компрессией данных; она принципиально меняет способ обработки информации визуальными языковыми моделями (VLM). Преобразуя текст в компактные изображения, VTC потенциально позволяет повысить эффективность и улучшить возможности логического вывода. При коэффициенте сжатия 2.0, VTC демонстрирует ограничения в поддержании долгосрочного рассуждения, уступая в этом аспекте традиционным текстовым языковым моделям (LLM). Это связано с тем, что процесс преобразования текста в визуальный формат может приводить к потере части контекстной информации, необходимой для сложных умозаключений.

VTCBench: систематическая оценка возможностей работы с длинным контекстом
VTCBench представляет собой специализированный бенчмарк, разработанный для систематической оценки возможностей визуальных языковых моделей (VLM) в обработке длинного контекста с использованием парадигмы VTC (Visual-Textual Chain). Этот бенчмарк позволяет проводить количественную оценку эффективности VLM в задачах, требующих анализа и интеграции информации из визуальных и текстовых источников в рамках расширенного контекста. В отличие от существующих бенчмарков, VTCBench фокусируется именно на оценке способности модели сохранять и использовать информацию на протяжении длинных последовательностей визуального и текстового контента, что критически важно для приложений, требующих глубокого понимания и рассуждений на основе больших объемов данных.
В рамках VTCBench, количественные метрики оценки играют ключевую роль в объективном измерении прироста производительности, достигаемого за счет сжатия контекста. Для оценки используются такие показатели, как точность (accuracy) и F1-мера, позволяющие сравнивать эффективность различных методов сжатия и моделей визуально-языковых моделей (VLM) при обработке длинных контекстов. Эти метрики позволяют не только оценить общую производительность, но и выявить конкретные области, в которых сжатие контекста наиболее эффективно, и определить оптимальные параметры для достижения наилучшего баланса между сжатием и сохранением информации. Объективная оценка с использованием количественных метрик необходима для надежного сравнения различных подходов и подтверждения фактических улучшений, вносимых методами сжатия в производительность VLM.
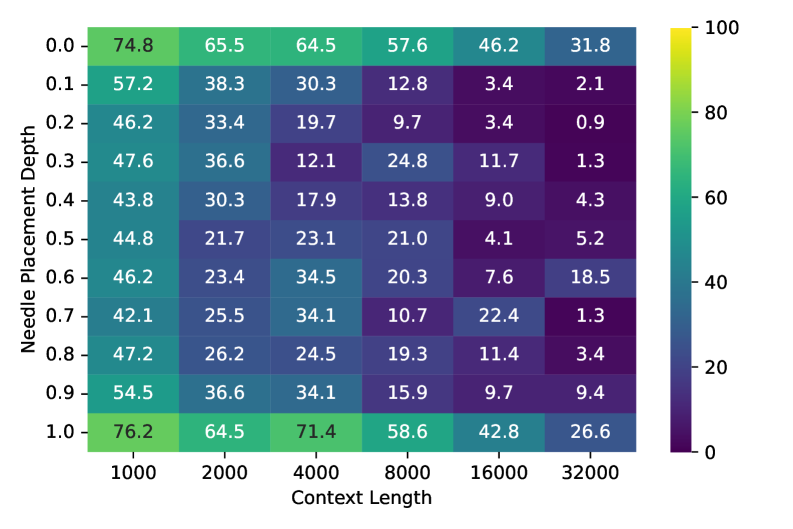
В ходе систематического тестирования в сложных сценариях, VTCBench показал, что модель Qwen3-VL-235B достигает точности 97.16% в задаче VTC-Retrieval при длине контекста 1k. Однако, при увеличении длины контекста, точность снижается до 50-60%. Данное снижение указывает на существенное ухудшение производительности по сравнению с текстовыми LLM, демонстрируя проблему масштабируемости визуально-языковых моделей при работе с длинными последовательностями данных.
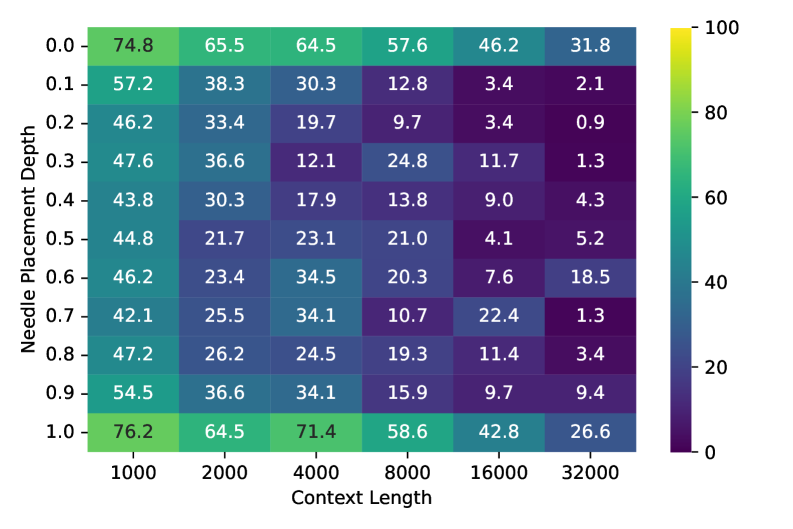
Визуальные энкодеры и архитектуры моделей: оптимизация для работы с длинным контекстом
В современных визуальных языковых моделях (VLM) для обработки визуальных представлений, полученных посредством визуального кодирования токенов (VTC), используются различные визуальные энкодеры. Среди наиболее распространенных можно выделить архитектуры NaViT, Siglip, InternViT и MoonViT. Каждый из этих энкодеров имеет свои особенности в структуре и методах обработки изображений, что позволяет адаптировать VLM к различным задачам и типам визуальных данных. Использование разнообразных энкодеров обеспечивает гибкость и возможность оптимизации производительности модели в зависимости от специфики решаемой задачи и доступных вычислительных ресурсов.
Архитектура Mixture of Experts (MoE) позволяет повысить производительность больших многомодальных моделей (VLM) за счет использования нескольких специализированных моделей, работающих параллельно. Вместо одной большой модели, MoE распределяет нагрузку между экспертами, каждый из которых обучен для обработки определенного подмножества входных данных или задач. Это приводит к повышению эффективности, поскольку не все параметры модели активируются для каждого входного примера, и к увеличению емкости модели без пропорционального увеличения вычислительных затрат. Механизмы маршрутизации определяют, какие эксперты должны обрабатывать конкретный вход, обеспечивая динамическую специализацию и улучшенную производительность при обработке длинных контекстов.
Оптимальный выбор визуального энкодера и архитектуры модели играет решающую роль в максимизации преимуществ визуального кодирования токенов (VTC) и достижении передовых результатов в задачах понимания длинного контекста. Однако, даже при использовании оптимизированных архитектур, точность на задаче VTC-Retrieval снижается с 97.16% до 81.34% при увеличении длины контекста с 1k до 32k токенов. Данное снижение демонстрирует существующие ограничения парадигмы VTC при обработке очень длинных последовательностей визуальной информации, что указывает на необходимость дальнейших исследований в области масштабируемых методов визуального кодирования и обработки длинного контекста.
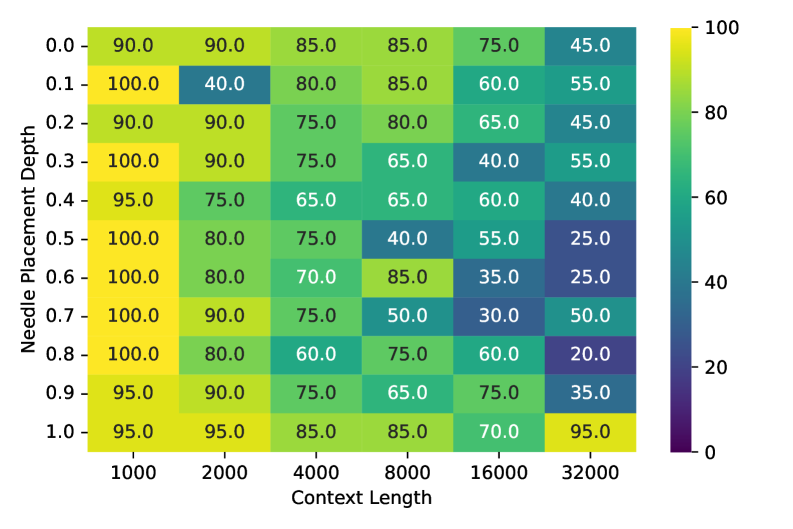
Будущее моделей с длинным контекстом: широкие перспективы и возможности
Улучшенное понимание длинного контекста открывает перед мультимодальными моделями новые возможности в решении сложных задач. Способность обрабатывать обширные последовательности визуальной и текстовой информации позволяет им успешно справляться с детальным повествованием на основе изображений, где необходимо учитывать взаимосвязь между кадрами и событиями. Не менее важна эта возможность при анализе сложных документов, требующих извлечения информации из различных источников и понимания ее контекста. Кроме того, модели, способные удерживать большой контекст, демонстрируют значительный прогресс в многоходовых диалогах, поддерживая последовательность и релевантность ответов на протяжении всей беседы. Такой подход позволяет создавать более интеллектуальные и полезные системы, способные к глубокому пониманию и взаимодействию с миром.
Визуально-языковые модели (VLM) с развитыми возможностями обработки длинного контекста обещают революционные изменения в различных сферах. В образовании они смогут анализировать сложные учебные материалы, включая диаграммы и иллюстрации, предоставляя персонализированные объяснения и ответы на вопросы. В здравоохранении такие модели смогут обрабатывать медицинские изображения и текстовые отчеты, помогая врачам в диагностике и планировании лечения. Особый потенциал открывается в сфере креативного контента, где VLM смогут генерировать подробные сценарии, визуализировать сложные идеи и создавать уникальные мультимедийные проекты, опираясь на обширный контекст и понимание визуальной информации. Способность к комплексному анализу и синтезу данных, основанная на обработке длинных последовательностей, делает эти модели незаменимым инструментом для решения задач, требующих глубокого понимания и творческого подхода.
Сочетание визуального контекстного кодирования (VTC), оптимизированных архитектур и специализированных бенчмарков, таких как VTCBench, открывает путь к созданию нового поколения интеллектуальных моделей, объединяющих зрение и язык. Однако, несмотря на значительный прогресс, существующие модели все еще демонстрируют отставание в производительности по сравнению с текстовыми языковыми моделями, особенно при работе с длинными последовательностями визуальной информации. Это указывает на необходимость дальнейших исследований, направленных на преодоление выявленного разрыва, совершенствование механизмов обработки визуального контекста и разработку более эффективных методов обучения, способных раскрыть весь потенциал мультимодального анализа данных.
Представленный труд демонстрирует, что даже самые передовые визуально-языковые модели испытывают трудности при работе с длинными контекстами, особенно когда визуальная информация сжата. Это подчеркивает необходимость разработки более эффективных методов моделирования длинного контекста, чтобы обеспечить надежное пространственное рассуждение. Как заметил Джеффри Хинтон: «Искусственный интеллект — это как ребенок: он учится, наблюдая и подражая». В данном исследовании, VTCBench выступает как своего рода “наблюдение” за способностями моделей к пониманию, выявляя пробелы в их развитии и стимулируя поиск более элегантных и гармоничных решений в области визуально-языкового моделирования. Акцент на сжатии визуальной информации — это не просто техническая деталь, а способ проверки способности модели к абстракции и обобщению, что является признаком истинного понимания.
Куда же дальше?
Представленный VTCBench обнажил неожиданную дисгармонию в оркестре визуально-языковых моделей. Оказывается, способность “видеть” и “говорить” не гарантирует понимания симфонии длинного контекста. Сжатие визуальной информации, как и любая элегантная форма, требует точности исполнения. Модели демонстрируют, что даже незначительная фальшь в передаче деталей способна разрушить целостность восприятия. И дело не просто в размере “окна внимания”, но в умении извлекать суть, словно опытный дирижёр, улавливающий нюансы в каждой ноте.
Необходимо признать: существующие подходы, вероятно, упираются в фундаментальные ограничения архитектур. Увеличение контекстного окна само по себе не является панацеей; требуется переосмысление механизмов внимания и памяти. Будущие исследования должны сосредоточиться на разработке моделей, способных не просто хранить информацию, но и активно структурировать её, выявлять ключевые связи и отбрасывать несущественное, подобно художнику, отсекающему лишние детали для создания выразительного портрета.
В конечном итоге, задача состоит не в создании моделей, имитирующих интеллект, а в построении систем, способных к глубокому и осмысленному восприятию мира. Каждая деталь важна, даже если её не замечают сразу. Истинная гармония достигается лишь тогда, когда форма и функция сливаются воедино, создавая единое, цельное произведение.
Оригинал статьи: https://arxiv.org/pdf/2512.15649.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Укрощение Бесконечности: Алгебраические Инструменты для Кватернионов и За их Пределами
- Эхо чёрных дыр: как квантовая гравитация меняет гравитационные волны
- Сияние фотонов: новый уровень точности в предсказаниях столкновений частиц
- Квантовые вычисления на службе беспроводной связи
- Квантовая Физика и Безопасность: Анализ Последних Новостей
- Биосети в руках ИИ: Автоматизация системной фармакологии
- Трансформация нейросетей: от плотных моделей к разреженным экспертам без обучения
- Квантовый Беспорядок и Наша Готовность к Нему
- Оживляя движение: новый подход к генерации траекторий
- Искусственный интеллект проектирует белки: новый горизонт биоинженерии
2025-12-19 05:23