Автор: Денис Аветисян
Исследователи представили модель N3D-VLM, способную понимать и рассуждать о трехмерном пространстве, объединяя возможности компьютерного зрения и обработки естественного языка.
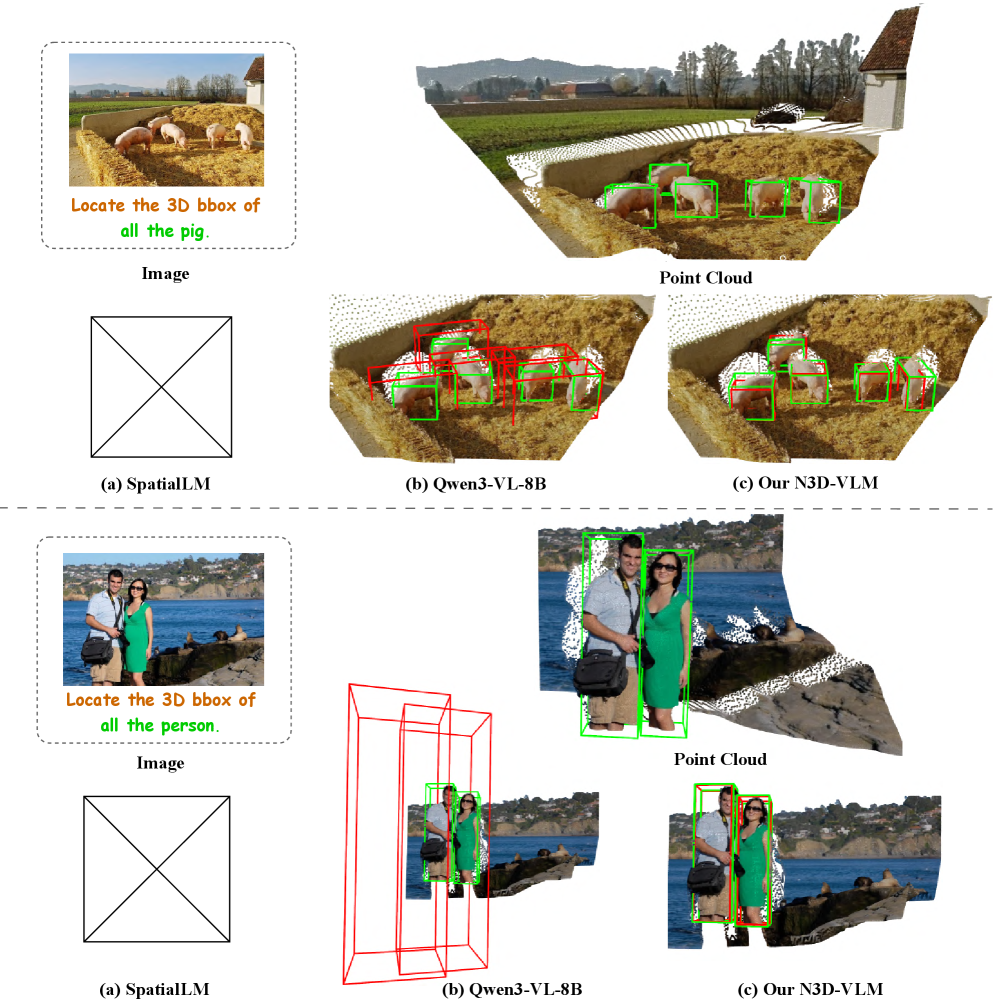
N3D-VLM использует 3D-локализацию объектов и цепочку рассуждений для достижения более точного понимания пространственных взаимосвязей.
Современные мультимодальные модели, несмотря на успехи в обработке 2D-изображений, испытывают трудности с пониманием трехмерного пространства и пространственных взаимосвязей. В данной работе, представленной под названием ‘N3D-VLM: Native 3D Grounding Enables Accurate Spatial Reasoning in Vision-Language Models’, предлагается новый унифицированный фреймворк, интегрирующий нативное восприятие 3D-объектов и 3D-анализ, что обеспечивает точное определение местоположения объектов в 3D-пространстве и интерпретируемое понимание пространственных отношений. Разработанный подход не только достигает передовых результатов в задачах 3D-определения местоположения, но и превосходит существующие методы в задачах 3D-пространственного рассуждения. Сможет ли предложенная архитектура N3D-VLM стать основой для создания действительно «видящих» и разумных систем искусственного интеллекта?
Преодолевая Ограничения Двумерного Восприятия
Традиционные модели, объединяющие зрение и язык, зачастую испытывают трудности при анализе сложных трехмерных пространственных отношений. Это связано с тем, что они, как правило, обрабатывают изображения как двухмерные проекции, теряя ценную информацию о глубине и взаимном расположении объектов. В результате, модели могут ошибочно интерпретировать сцены, неверно определяя, например, что находится «над», «под», «перед» или «за» другими объектами. Такое ограничение существенно снижает их эффективность в задачах, требующих детального понимания трехмерного мира, таких как навигация роботов, анализ медицинских изображений или визуальное распознавание объектов в реальном времени. Неспособность к точному трехмерному рассуждению препятствует созданию по-настоящему интеллектуальных систем, способных к полноценному взаимодействию с окружающим пространством.
Существующие подходы к обработке изображений и языка часто опираются на двумерные представления, что приводит к потере критически важной информации о глубине и пространственном расположении объектов. В результате, модели испытывают трудности с точным пониманием сложных сцен и взаимосвязей между объектами в трехмерном пространстве. Преобразование трехмерного мира в двухмерное изображение неизбежно ведет к искажению информации о расстоянии и относительной позиции объектов, что затрудняет выполнение задач, требующих точного пространственного рассуждения, таких как навигация робота или интерпретация медицинских изображений. Неспособность учитывать глубину ограничивает возможности моделей в задачах, требующих понимания пространственных отношений, например, определение, находится ли один объект перед другим или расположен ли он выше или ниже.

N3D-VLM: Архитектура, Ориентированная на Трехмерное Пространство
N3D-VLM представляет собой унифицированную архитектуру, объединяющую задачи локализации объектов в 3D-пространстве и лингвистического рассуждения. В отличие от традиционных моделей, которые обрабатывают изображения и текст раздельно, N3D-VLM осуществляет совместный анализ визуальной информации и текстовых запросов для определения местоположения объектов в трехмерном пространстве. Это достигается путем представления объектов в виде 3D-ограничивающих рамок (bounding boxes), что позволяет модели не только идентифицировать объекты, но и определять их координаты и размеры в пространстве. Такая интеграция позволяет решать более сложные задачи, требующие понимания пространственных взаимосвязей между объектами, например, ответы на вопросы, касающиеся относительного положения объектов или их взаимодействия в 3D-сцене.
Модель N3D-VLM использует 3D ограничивающие рамки (bounding boxes) для точной локализации объектов в трехмерном пространстве и механизм рассуждений «chain-of-thought» (CoT) для обеспечения прозрачности и интерпретируемости пространственного понимания. Вместо простого предсказания ответов, CoT позволяет модели последовательно генерировать логические шаги, объясняющие, как она пришла к определенному выводу относительно положения и взаимосвязи объектов в сцене. Это обеспечивает не только более высокую точность, но и возможность анализа процесса принятия решений моделью, что критически важно для приложений, требующих надежности и объяснимости, например, в робототехнике или автономном вождении.
В основе N3D-VLM лежит мощная предобученная модель Qwen2.5-VL, что обеспечивает высокую производительность и масштабируемость системы. Использование Qwen2.5-VL в качестве основы позволяет N3D-VLM эффективно использовать накопленные знания и возможности обработки визуальной и языковой информации. Это существенно снижает потребность в обучении с нуля и позволяет быстрее адаптировать модель к новым задачам, связанным с 3D-анализом и пониманием сцен. В результате, N3D-VLM демонстрирует улучшенные показатели в задачах, требующих как визуального восприятия, так и логического вывода, благодаря синергии между архитектурой N3D и возможностями Qwen2.5-VL.

N3D-Bench: Объективная Оценка Трехмерного Рассуждения
Модель N3D-VLM прошла тщательное тестирование на N3D-Bench, специализированном бенчмарке, предназначенном для оценки навыков 3D пространственного мышления. N3D-Bench содержит набор задач, требующих от модели понимания трехмерных сцен и взаимосвязей между объектами в них. Использование данного бенчмарка позволяет объективно оценить способность N3D-VLM к решению задач, связанных с восприятием и анализом трехмерного пространства, и сравнить её производительность с другими моделями в данной области. Бенчмарк включает в себя разнообразные сценарии и типы объектов, обеспечивая всестороннюю оценку возможностей модели.
Модель N3D-VLM продемонстрировала точность в 92.1% на бенчмарке N3D-Bench, что значительно превосходит результаты модели Qwen3-VL и устанавливает новый стандарт производительности в области 3D пространственного рассуждения. Данный показатель подтверждает превосходство N3D-VLM в решении задач, требующих анализа и понимания трехмерных сцен, и позволяет рассматривать её как передовое решение в данной области. Полученные результаты свидетельствуют о высокой эффективности архитектуры и стратегии обучения, используемых в N3D-VLM.
При оценке на SpatialRGPT-Bench, модель N3D-VLM достигла точности 78.0%, что превосходит результаты базовых моделей. Данный результат демонстрирует повышение точности модели благодаря использованию привязки к реальным данным (grounding), что указывает на улучшенное понимание и интерпретацию пространственных взаимосвязей в контексте заданного окружения. Повышенная точность на данном бенчмарке подтверждает эффективность подхода к обучению модели, позволяющего эффективно решать задачи, требующие анализа и понимания трехмерного пространства.
Обучение N3D-VLM проводилось на наборе данных, содержащем 2,78 миллиона аннотаций для 3D-обнаружения объектов. Это значительно превосходит объемы существующих публичных наборов данных, таких как Omni3D, насчитывающий около 234 тысяч аннотаций, и DetAny3D, содержащий примерно 450 тысяч аннотаций. Более крупный обучающий набор данных позволяет модели N3D-VLM лучше обобщать и демонстрировать повышенную точность в задачах 3D-обнаружения.

Расширяя Горизонты: Влияние и Перспективы Развития
Точное понимание трехмерных сцен, демонстрируемое моделью N3D-VLM, открывает широкие перспективы для развития различных областей. В робототехнике это позволяет создавать системы, способные автономно ориентироваться и взаимодействовать с окружающим миром, избегая препятствий и выполняя сложные задачи. В сфере дополненной реальности, N3D-VLM способствует созданию более реалистичных и интерактивных приложений, где виртуальные объекты органично вписываются в реальное пространство. Кроме того, модель играет важную роль в развитии систем внутренней навигации, обеспечивая точное позиционирование и маршрутизацию в помещениях, что особенно актуально для автоматизированных транспортных средств и сервисных роботов. Развитие подобных технологий значительно повысит эффективность и удобство взаимодействия человека с окружающим миром.
Обучение модели N3D-VLM демонстрирует значительную зависимость от масштаба и разнообразия используемых данных. Использование крупномасштабных наборов данных, таких как OpenImages, COCO и Objects365, позволило добиться существенного улучшения в понимании трехмерных сцен. Разнообразие представленных в этих наборах объектов, условий освещения и перспектив играет ключевую роль в обобщающей способности модели, позволяя ей корректно интерпретировать изображения, не встречавшиеся ранее. Подчеркивается, что расширение наборов данных и включение в них большего количества сценариев и объектов является важным направлением для дальнейшего повышения точности и надежности систем компьютерного зрения, работающих с трехмерными данными.
В дальнейшем исследования будут направлены на совершенствование методов оценки глубины и расширение способности модели к рассуждениям в более сложных ситуациях. Ученые планируют внедрить усовершенствованные алгоритмы, позволяющие точнее восстанавливать трехмерную структуру сцены даже при наличии шумов и неполной информации. Особое внимание уделяется обучению модели пониманию взаимосвязей между объектами и их пространственному контексту, что необходимо для решения задач, требующих логического вывода и прогнозирования. Разработка способности к адаптации к новым, ранее не встречавшимся сценариям, станет ключевым шагом к созданию по-настоящему интеллектуальной системы, способной эффективно функционировать в реальном мире.
Для более глубокой оценки корректности рассуждений модели N3D-VLM планируется внедрение передовых методов оценки, в частности, с использованием возможностей GPT-4o. Традиционные метрики часто оказываются недостаточными для выявления тонких логических ошибок или неполноты понимания сцены. GPT-4o, обладая развитыми способностями к обработке естественного языка и пониманию контекста, позволяет проводить более нюансированную оценку, выявляя не только фактические ошибки, но и недостатки в логических выводах модели. Такой подход позволит не просто констатировать наличие или отсутствие ответа, но и оценить качество рассуждений, что критически важно для повышения надежности и безопасности систем, использующих данную технологию в таких областях, как робототехника и дополненная реальность.

Исследование демонстрирует, что без чёткого определения пространственных взаимосвязей объектов, любое решение в области обработки изображений и языка — лишь шум. Модель N3D-VLM, представленная в статье, подтверждает этот принцип, интегрируя 3D-обнаружение и логические цепочки рассуждений для достижения точного понимания 3D-пространства. Как отмечал Ян ЛеКун: «Искусственный интеллект — это не волшебство, а математика». Данный подход, акцентирующий внимание на математической точности и доказуемости алгоритмов, позволяет N3D-VLM превосходить существующие модели в задачах, требующих сложного 3D-рассуждения и локализации объектов.
Что дальше?
Представленная работа, хоть и демонстрирует впечатляющий прогресс в области пространственного мышления моделей «зрение-язык», не решает фундаментальной проблемы: достоверности. Успех N3D-VLM зиждется на корреляции между языковым описанием и трехмерной реконструкцией сцены, но эта корреляция не является доказательством истинного понимания. Модель оперирует символами, а не сущностями, и её «рассуждения» — это, по сути, изощренное сопоставление паттернов. Истинная элегантность проявится лишь тогда, когда модель сможет не просто локализовать объект, но и предсказать его поведение, основываясь на физических законах и причинно-следственных связях.
Очевидным направлением для дальнейших исследований представляется разработка методов, позволяющих верифицировать «знания» модели. Необходимо отойти от оценки по результатам тестов и перейти к формальной верификации корректности алгоритмов, подобно тому, как это делается в математике. Создание синтетических данных, безусловно, полезно, но оно лишь отодвигает проблему, не решая её. Настоящий вызов — создание моделей, способных к самообучению на реальных, неструктурированных данных, и способных к генерации новых, логически обоснованных утверждений.
И, наконец, стоит задуматься о природе самого «пространственного мышления». Является ли оно лишь сложной формой обработки информации, или же в нем задействованы принципы, лежащие за пределами современной вычислительной парадигмы? Ответ на этот вопрос, возможно, потребует пересмотра фундаментальных представлений о природе интеллекта и сознания.
Оригинал статьи: https://arxiv.org/pdf/2512.16561.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Язык тела под присмотром ИИ: архитектура и гарантии
- Разбираемся с разреженными автокодировщиками: Действительно ли они учатся?
- Согласие роя: когда разум распределён, а ошибки прощены.
- Квантовый импульс для несбалансированных данных
- Видеовопросы и память: Искусственный интеллект на грани
- Искусственный интеллект в разговоре: что обсуждают друг с другом AI?
- Умная экономия: Как сжать ИИ без потери качества
- Безопасность генерации изображений: новый вектор управления
- Редактирование изображений по запросу: новый уровень точности
- Очарование в огненном вихре: Динамика очарованных кварков в столкновениях тяжелых ионов
2025-12-19 15:43