Автор: Денис Аветисян
Новое исследование сравнивает эффективность моделей, напрямую обрабатывающих аудио, с традиционными системами распознавания речи для автоматического перевода.
Комплексная оценка моделей SpeechLLM показала, что каскадные системы пока обеспечивают более высокое качество и надежность перевода речи в различных условиях и на разных тестовых наборах.
Несмотря на активное развитие больших языковых моделей (LLM), вопрос об эффективности прямой интеграции речи в эти модели для задач перевода остается открытым. В работе ‘Hearing to Translate: The Effectiveness of Speech Modality Integration into LLMs’ представлен всесторонний анализ пяти передовых SpeechLLM, сопоставленный с шестнадцатью каскадными системами, использующими современные модели распознавания речи и многоязыковые LLM. Полученные результаты демонстрируют, что, несмотря на перспективность, каскадные системы пока обеспечивают более стабильное качество и надежность перевода речи, чем современные SpeechLLM. Какие архитектурные и алгоритмические решения позволят в полной мере реализовать потенциал прямой интеграции речи в LLM и превзойти существующие подходы?
Взлом Языка: Вызовы Многоязычной Коммуникации
Эффективная глобальная коммуникация все больше зависит от точности и скорости машинного перевода, однако современные системы испытывают значительные трудности в передаче тонких смысловых оттенков и при работе с длинными текстами. Несмотря на прогресс в области искусственного интеллекта, сложные идиомы, культурные нюансы и контекстуальные зависимости часто теряются при автоматическом переводе, приводя к неточностям и искажениям смысла. Это особенно заметно при переводе художественной литературы, юридических документов или технической документации, где важна каждая деталь. Сложность заключается в том, что язык не является просто набором слов, а представляет собой сложную систему, зависящую от множества факторов, которые трудно алгоритмизировать и воспроизвести в машинной среде. Поэтому, несмотря на значительные инвестиции и усилия, создание системы машинного перевода, способной полностью заменить квалифицированного переводчика, остается сложной задачей.
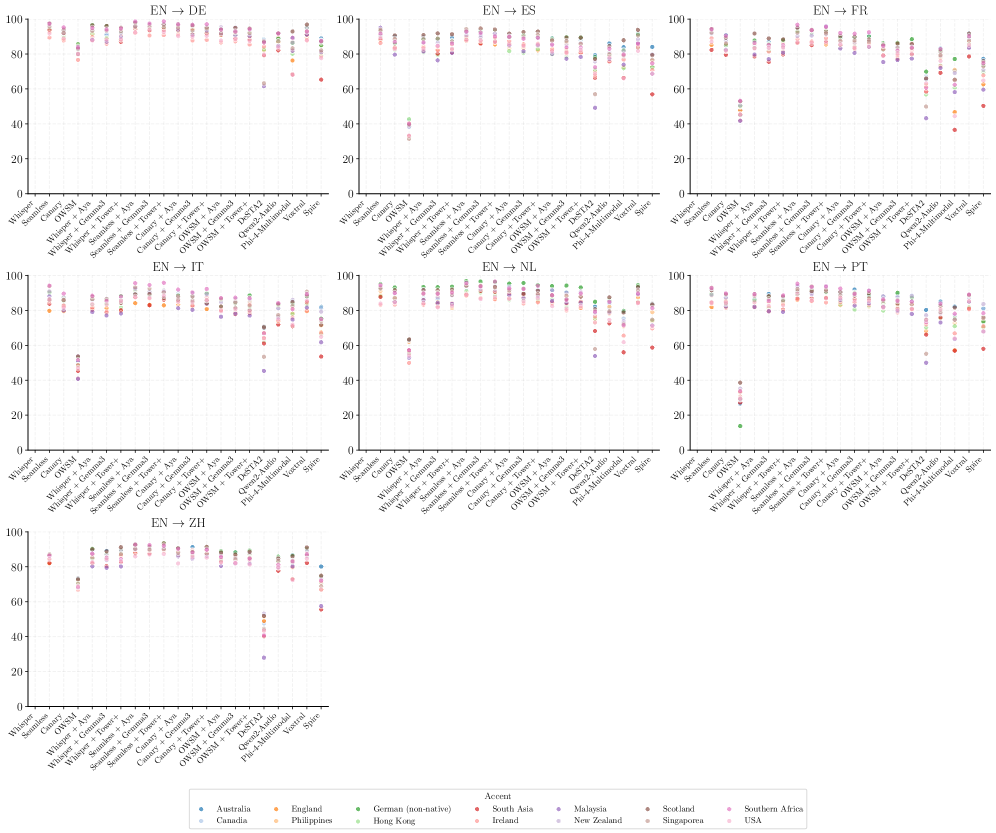
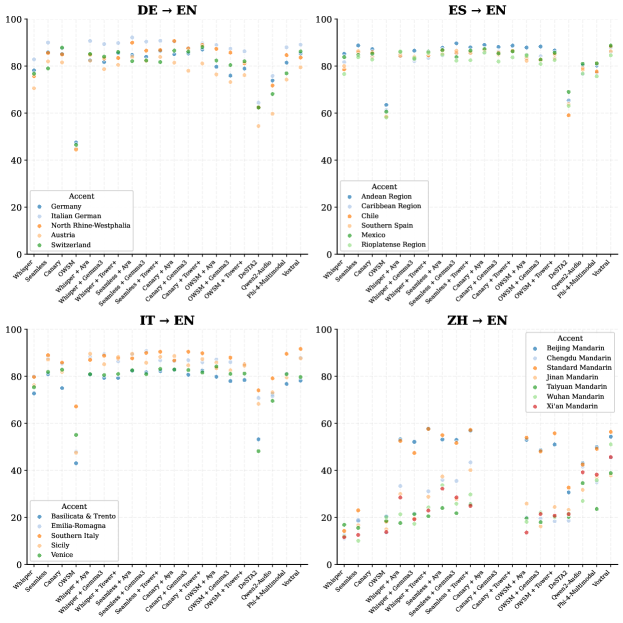
Несмотря на сложность архитектуры, каскадные системы перевода в настоящее время демонстрируют наивысшее качество обработки текста, оцениваемое примерно в 40-50 баллов по метрике $xCOMETSQE{}^{\text{QE}_{\text{{S}}}} $. Данный показатель стабильно превосходит результаты, достигнутые моделями SpeechLLMs и системами прямого перевода. Каскадный подход, подразумевающий последовательное выполнение нескольких этапов обработки — от распознавания речи до генерации перевода — позволяет более точно учитывать контекст и нюансы языка, что критически важно для достижения высокого качества перевода, особенно в длинных текстах и сложных тематических областях. Таким образом, каскадные системы остаются золотым стандартом в области машинного перевода, несмотря на появление новых, более инновационных архитектур.
Стремление к действительно бесшовной речевой трансляции требует отказа от последовательной обработки данных и перехода к сквозному обучению. Существующие системы, как правило, разбивают процесс на отдельные этапы — распознавание речи, машинный перевод, синтез речи — что создает задержки и снижает точность передачи смысла. Несмотря на то, что текущие модели сквозного обучения пока уступают по качеству традиционным каскадным системам, оцениваемым в $40-50$ по метрике xCOMETSQE{}^{\text{QE}_{\text{{S}}}} , разработка архитектур, способных обрабатывать речь напрямую, без промежуточных этапов, представляется ключевым направлением для достижения естественной и оперативной коммуникации между людьми, говорящими на разных языках. Исследования в этой области направлены на создание моделей, способных улавливать нюансы речи и передавать их в реальном времени, преодолевая разрыв в производительности и приближая будущее глобального общения.
SpeechLLMs: Унифицированный Подход к Речевому Переводу
Решение SpeechLLM представляет собой принципиально новый подход к автоматическому переводу речи, объединяя этапы обработки звукового сигнала и перевода в единую нейронную сеть. Традиционно, системы машинного перевода речи использовали каскадную архитектуру, где сначала выполнялось распознавание речи, а затем — перевод полученного текста. SpeechLLM отказывается от этого разделения, позволяя модели напрямую преобразовывать аудиопоток в целевой язык. Это упрощает архитектуру, потенциально снижает задержку и позволяет модели учитывать контекст на всех этапах обработки, что может привести к повышению качества перевода. В отличие от многоступенчатых систем, SpeechLLM обучается как единое целое, оптимизируя все компоненты для достижения наилучшей производительности в задаче перевода речи.
Модели, такие как DeSTA2, Qwen2-Audio и Voxtral, используют возможности больших языковых моделей (LLM), включая Whisper и LLaMA 3, для одновременного выполнения распознавания речи и перевода. В отличие от традиционных каскадных систем, где эти этапы выполняются последовательно, SpeechLLM интегрируют оба процесса в единую нейронную сеть. Это достигается путем обучения LLM на больших объемах параллельных аудио- и текстовых данных, что позволяет модели напрямую преобразовывать речевой сигнал в текст на целевом языке. Использование LLM позволяет моделям учитывать контекст и семантику речи, улучшая точность и беглость перевода.
Несмотря на перспективность подхода SpeechLLM, текущие результаты оценки качества перевода с использованием метрики $xCOMETSQE{}^{\text{QE}_{\text{{S}}}}$ составляют приблизительно 30-40 баллов. Это значение пока что ниже показателей, достигаемых традиционными каскадными системами автоматического перевода, которые состоят из отдельных модулей распознавания речи и машинного перевода. Разница в оценках указывает на то, что, несмотря на преимущества единой архитектуры, SpeechLLM пока не достигли сопоставимой точности и плавности перевода, характерных для более зрелых, многокомпонентных систем.
Модель Voxtral в настоящее время обеспечивает наибольшую длину контекста среди SpeechLLM, позволяя обрабатывать до 40 минут (32 тысячи токенов) аудиозаписи. Однако, несмотря на это преимущество, сохранение качества транскрипции и перевода на протяжении всего этого длительного периода остается сложной задачей. Наблюдается снижение точности и появление ошибок по мере увеличения продолжительности обрабатываемого аудио, что требует дальнейшей оптимизации архитектуры и методов обучения для обеспечения стабильно высокого качества на протяжении всей длительности аудиозаписи.
Масштабирование для Длинных Аудиозаписей: Преодоление Ключевых Ограничений
Обработка длинных аудиозаписей представляет собой сложную задачу для SpeechLLM из-за вычислительных ограничений и проблемы затухания градиента. Вычислительные затраты на обработку длинных последовательностей значительно возрастают, требуя больше памяти и времени обработки. Проблема затухания градиента, возникающая при обучении глубоких нейронных сетей, усугубляется при работе с длинными последовательностями, поскольку градиенты, используемые для обновления весов модели, экспоненциально уменьшаются по мере распространения по сети, что препятствует эффективному обучению и ухудшает качество обработки дальних зависимостей в аудиосигнале. Это ограничивает способность моделей эффективно извлекать и обрабатывать информацию из длинных аудиозаписей, что приводит к снижению производительности.
Архитектуры, такие как OWSM, используют неавторегрессивный подход к обработке аудио, что позволяет эффективно обрабатывать расширенные аудиосегменты. В отличие от традиционных авторегрессивных моделей, которые последовательно генерируют выходные данные, неавторегрессивные модели обрабатывают весь аудиовход параллельно. Это значительно снижает вычислительные затраты и время обработки, особенно для длинных аудиозаписей. Неавторегрессивный подход также помогает смягчить проблему затухания градиента, которая часто возникает при обучении авторегрессивных моделей на больших объемах данных, обеспечивая более стабильное и эффективное обучение для обработки продолжительного аудиоконтента.
Модели DeSTA2 и Qwen2-Audio демонстрируют заметный провал в производительности при обработке длинных аудиозаписей. Показатель $\Delta$length, равный приблизительно 91-94, указывает на существенное снижение качества синтеза по сравнению с каскадными системами, у которых данный показатель близок к нулю. Это свидетельствует о том, что при увеличении длительности аудио, модели DeSTA2 и Qwen2-Audio значительно уступают в сохранении качества генерируемого звука, что делает их менее эффективными для задач, требующих обработки продолжительного аудиоконтента.
Современные разработки в архитектуре моделей и методах обучения, в частности, используемые в Spire и Phi-4-Multimodal, демонстрируют увеличение способности SpeechLLM к обработке продолжительных аудиозаписей. Эти усовершенствования включают оптимизацию структуры нейронных сетей для более эффективного удержания информации на больших временных промежутках, а также применение новых стратегий обучения, направленных на снижение проблемы затухания градиента и повышение устойчивости модели к накоплению ошибок при обработке длинных последовательностей. Результатом является повышение качества транскрибации и понимания речи в продолжительных аудиоматериалах, приближающее производительность SpeechLLM к показателям каскадных систем.
Реальное Влияние и Будущие Направления
Прогресс в области SpeechLLM, включающий такие модели, как Canary, Aya Expanse и Tower+, открывает новые возможности для практического применения. Эти разработки способствуют созданию систем для проведения многоязычных конференций в реальном времени, автоматизированного создания субтитров и инструментов, обеспечивающих коммуникацию для людей с ограниченными возможностями. В частности, модели, подобные Tower+, позволяют создавать более точные и доступные инструменты перевода речи, что значительно расширяет возможности общения между людьми, говорящими на разных языках. Внедрение подобных технологий обещает упростить международное сотрудничество, повысить доступность информации и способствовать более инклюзивному обществу.
Автоматизированные метрики, такие как xCOMET и MetricX, играют ключевую роль в объективной оценке производительности систем речевого перевода. В отличие от субъективных оценок, основанных на восприятии человека, эти инструменты предоставляют количественные данные, позволяющие точно измерить качество перевода по различным параметрам, включая точность, беглость и семантическую адекватность. Использование таких метрик значительно ускоряет процесс разработки и совершенствования моделей, позволяя исследователям выявлять слабые места и эффективно оптимизировать алгоритмы. Более того, автоматизированные оценки обеспечивают воспроизводимость результатов и позволяют сравнивать различные системы речевого перевода в стандартизированных условиях, что необходимо для дальнейшего прогресса в этой области. Без объективных критериев оценки, сложно определить, какие улучшения действительно приводят к повышению качества перевода, и как наиболее эффективно направить усилия разработчиков.
Исследования показали, что модели, использующие архитектуру Tower+, демонстрируют значительно меньшую гендерную предвзятость в сравнении с другими системами автоматического перевода речи. В то время как значения показателей гендерной предвзятости для большинства моделей варьировались от -1 до +3, Tower+ показал значения, близкие к нулю, что свидетельствует о более нейтральном отношении к гендерным различиям. Это особенно важно, поскольку предвзятость в автоматическом переводе может приводить к искажению смысла и увековечиванию стереотипов, а снижение этой предвзятости является ключевым шагом к созданию более справедливых и инклюзивных технологий коммуникации.
Прямой перевод речи, воплощенный в подходах, таких как Direct ST, представляет собой упрощенное решение, обходящее промежуточный этап транскрипции в текст. Вместо последовательного преобразования аудио в текст, а затем текста в другой язык, Direct ST осуществляет перевод непосредственно из аудиосигнала, что потенциально снижает задержку и повышает точность. Этот подход позволяет избежать ошибок, возникающих при автоматическом распознавании речи, особенно в сложных акустических условиях или при наличии акцентов. Исследования показывают, что прямое преобразование может значительно улучшить скорость и качество перевода в реальном времени, открывая новые возможности для мгновенного общения между людьми, говорящими на разных языках, и автоматизации многоязычных сервисов.
Перспективы развития речевых моделей, таких как Canary, Aya Expanse и Tower+, неразрывно связаны с тремя ключевыми направлениями исследований. Прежде всего, усилия направлены на повышение устойчивости систем к шумам, акцентам и различным стилям речи, что позволит им надежно функционировать в реальных условиях. Параллельно ведется работа по снижению вычислительных затрат, необходимых для работы этих моделей, что сделает их более доступными и применимыми на устройствах с ограниченными ресурсами. Наконец, расширение языкового охвата, включение в него большего числа языков и диалектов, является необходимым шагом для реализации потенциала действительно бесшовной многоязычной коммуникации, стирающей границы между людьми и культурами. Решение этих задач откроет путь к созданию инструментов, способных не только переводить речь, но и понимать нюансы, контекст и эмоции, делая общение между носителями разных языков по-настоящему естественным и эффективным.

Исследование демонстрирует, что, несмотря на перспективность SpeechLLM, каскадные системы пока превосходят их в качестве и надёжности перевода речи. Этот факт подтверждает, что понимание системы, её компонентов и взаимодействия между ними, является ключевым фактором для достижения оптимальных результатов. Тим Бернерс-Ли однажды сказал: «Власть над данными — это власть над реальностью». В данном контексте, контроль над обработкой и преобразованием звукового сигнала, а также над алгоритмами перевода, позволяет создавать более эффективные и точные системы. Анализ, представленный в работе, подчеркивает необходимость дальнейшего изучения и оптимизации каждого этапа обработки, чтобы приблизиться к созданию универсальной модели, способной к полноценному пониманию и переводу речи.
Куда же дальше?
Представленные результаты, как и следовало ожидать, лишь обнажают глубину проблемы, а не предлагают окончательное решение. Утверждение о превосходстве каскадных систем над интегрированными SpeechLLM — это не триумф одного подхода над другим, а скорее констатация факта: мы всё ещё не до конца понимаем, как эффективно соединить слуховое восприятие и лингвистическую обработку. Попытки «втиснуть» распознавание речи в существующие языковые модели — это, по сути, работа с симптомами, а не с первопричиной.
Более перспективным представляется не слепое наращивание параметров, а фундаментальное переосмысление архитектуры. Необходимо исследовать, как изначально спроектировать модель, способную одновременно воспринимать и интерпретировать акустический сигнал, избегая промежуточных этапов и связанных с ними потерь информации. В конечном счете, вопрос не в том, чтобы «научить» модель переводить речь, а в том, чтобы создать систему, способную понимать её, как это делает человек.
Очевидно, что существующие оценочные метрики не отражают всей сложности задачи. Они измеряют лишь поверхностное сходство между переведенным текстом и эталонным, игнорируя нюансы смысла и контекста. Разработка более тонких и объективных методов оценки, способных учитывать эти факторы, является критически важной для дальнейшего прогресса. Иначе, мы рискуем лишь оптимизировать систему под конкретные метрики, не приближаясь к истинному пониманию.
Оригинал статьи: https://arxiv.org/pdf/2512.16378.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Язык тела под присмотром ИИ: архитектура и гарантии
- Разбираемся с разреженными автокодировщиками: Действительно ли они учатся?
- Согласие роя: когда разум распределён, а ошибки прощены.
- Квантовый импульс для несбалансированных данных
- Видеовопросы и память: Искусственный интеллект на грани
- Искусственный интеллект в разговоре: что обсуждают друг с другом AI?
- Умная экономия: Как сжать ИИ без потери качества
- Безопасность генерации изображений: новый вектор управления
- Редактирование изображений по запросу: новый уровень точности
- Очарование в огненном вихре: Динамика очарованных кварков в столкновениях тяжелых ионов
2025-12-19 17:18