Автор: Денис Аветисян
Новый метод защиты конфиденциальности изображений, основанный на принципах диффузионных моделей, предотвращает несанкционированное редактирование без потери качества.

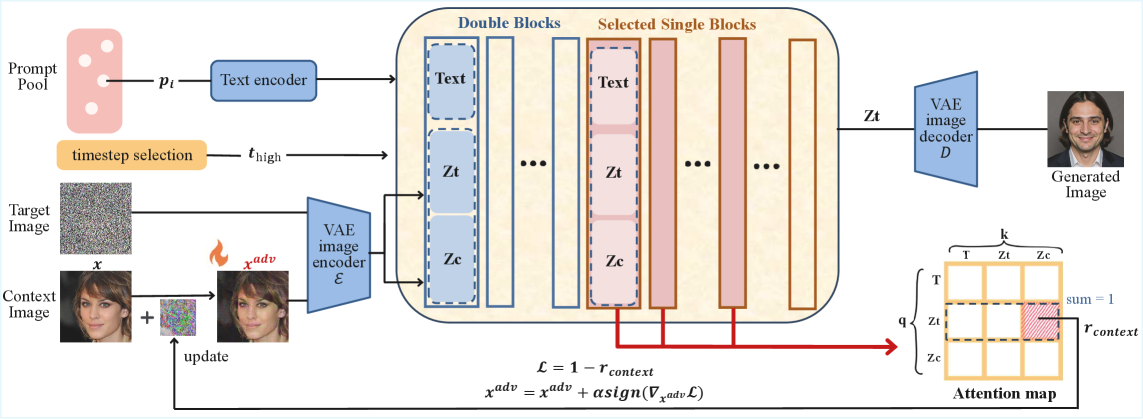
Исследование предлагает механизм ‘Отделения Контекста’ (DeContext), нарушающий мультимодальное внимание в диффузионных трансформаторах для защиты от атак и сохранения приватности.
Современные диффузионные модели демонстрируют впечатляющую способность к редактированию изображений, однако эта же мощь создает серьезные риски для конфиденциальности пользователей. В работе ‘DeContext as Defense: Safe Image Editing in Diffusion Transformers’ предложен новый метод защиты, основанный на нарушении потока контекстной информации в архитектуре DiT посредством целенаправленных возмущений в слоях мультимодального внимания. Предлагаемый подход, названный DeContext, эффективно отключает связь между входным изображением и нежелательными изменениями, сохраняя при этом визуальное качество. Возможно ли дальнейшее совершенствование этой стратегии для обеспечения надежной защиты от несанкционированного редактирования изображений в различных сценариях применения?
Шёпот Хаоса: Открытие Новой Эры Редактирования Изображений
Современные диффузионные модели совершили революцию в области редактирования изображений, предоставив беспрецедентные возможности для манипулирования визуальным контентом. Однако, эта мощь несет в себе и определенные риски. В процессе генерации и редактирования, модели могут вносить нежелательные, непреднамеренные изменения, искажая исходное изображение или создавая артефакты. Это особенно актуально при работе со сложными сценами или при внесении незначительных корректировок, когда даже небольшие отклонения от исходных данных могут привести к заметным и нежелательным результатам. В связи с этим, разработка методов контроля и оценки качества редактирования изображений, обеспечивающих сохранение целостности и реалистичности визуального контента, становится критически важной задачей.
Архитектуры DiT, использующие возможности обучения в контексте, стали ключевым элементом в современных достижениях в области редактирования изображений. В отличие от традиционных подходов, требующих переобучения модели для каждой новой задачи, DiT позволяет манипулировать изображениями, предоставляя модели лишь несколько примеров желаемых изменений непосредственно в процессе обработки. Этот подход, вдохновленный принципами работы больших языковых моделей, позволяет модели «понимать» задачу из контекста, а не из предварительно заданных параметров. Благодаря этому, DiT демонстрирует впечатляющую гибкость и эффективность в широком спектре задач, от стилизации изображений до сложных манипуляций с объектами на фотографии, открывая новые возможности для творческого и практического применения технологий редактирования изображений.
Несмотря на впечатляющие возможности контекстного редактирования изображений, основанные на диффузионных моделях, возникает и обратная сторона медали — уязвимость к злонамеренным изменениям. Исследования показывают, что тщательно подобранный контекст, используемый для управления процессом редактирования, может быть использован для внедрения скрытых манипуляций, незаметных для неспециалиста. Злоумышленники способны, не изменяя напрямую пиксели, влиять на интерпретацию изображения моделью, вызывая нежелательные и даже вредоносные изменения, которые могут распространяться вместе с отредактированной копией. Эта проблема особенно актуальна в контексте распространения дезинформации и поддельных новостей, где даже незначительные визуальные манипуляции могут иметь серьезные последствия.
Оценка достоверности и сохранения идентичности отредактированных изображений становится первостепенной задачей в эпоху мощных инструментов манипулирования. Поскольку диффузионные модели и архитектуры, основанные на DiT, позволяют достигать беспрецедентного уровня редактирования, возрастает риск незаметных, но существенных изменений, способных исказить реальность или нарушить целостность визуальной информации. Крайне важно разработать надежные метрики и методы оценки, позволяющие точно определять, насколько измененное изображение соответствует исходному по содержанию и сохраняет ли оно личность или узнаваемые характеристики объектов на нем. Это требует не только анализа пиксельных различий, но и учета семантического содержания, контекста и визуального восприятия, чтобы гарантировать, что отредактированное изображение остается правдивым и не вводит в заблуждение.
Оценка Верности и Идентичности Изображений: Критерии и Метрики
Комплексная оценка качества изображений требует использования набора метрик, измеряющих как воспринимаемое визуальное качество, так и сохранение идентичности объекта на изображении. Оценка визуального качества включает в себя такие показатели, как четкость, контрастность и реалистичность, в то время как оценка идентичности фокусируется на способности системы распознавания лиц или объектов правильно идентифицировать объект после внесения изменений. Использование нескольких метрик позволяет получить более полное представление о влиянии редактирования или защиты изображения, учитывая как эстетические, так и функциональные аспекты.
Для оценки общего качества изображения используются метрики, такие как FID (Fréchet Inception Distance), BRISQUE (Blind/Referenceless Image Spatial Quality Evaluator) и SER-FQA (Spatial-Spectral Entropy for Robust Quality Assessment). Эти метрики измеряют различные аспекты визуального восприятия, включая четкость, реалистичность и наличие артефактов. В то же время, для количественной оценки сохранения идентичности объекта на изображении применяются метрики ArcFace, RetinaFace и CLIP Image Similarity. ArcFace и RetinaFace фокусируются на точности распознавания лиц, оценивая сходство эмбеддингов лиц, в то время как CLIP Image Similarity измеряет семантическое сходство между изображениями, определяя, насколько хорошо они соответствуют текстовому описанию. Сочетание этих метрик позволяет комплексно оценить как визуальную достоверность, так и сохранность идентичности объекта после применения различных преобразований или атак.
Оценка метрик качества и сохранения идентичности изображений проводится с использованием стандартных наборов данных, таких как CelebA-HQ и VGGFace2, для обеспечения обобщаемости результатов. CelebA-HQ содержит большое количество высококачественных изображений лиц, что позволяет оценить производительность алгоритмов в условиях разнообразия поз, выражений и освещения. VGGFace2, в свою очередь, представляет собой еще более крупный набор данных с изображениями лиц, обеспечивающий более надежную оценку способности алгоритмов распознавать и сохранять идентичность лиц при различных изменениях. Использование этих наборов данных позволяет сравнивать различные методы редактирования и защиты изображений в контролируемых условиях и получать результаты, применимые к широкому спектру сценариев.
Установление надежных базовых показателей с использованием метрик, таких как FID, BRISQUE, SER-FQA, ArcFace, RetinaFace и CLIP Image Similarity, является критически важным для объективного сравнения различных методов редактирования изображений и механизмов защиты от атак. Точные базовые значения позволяют количественно оценить эффективность новых алгоритмов, выявлять улучшения в качестве и сохранении идентичности, а также стандартизировать процесс оценки. Отсутствие надежных базовых показателей затрудняет интерпретацию результатов и препятствует прогрессу в области обработки изображений и компьютерного зрения, поскольку не позволяет однозначно определить, является ли наблюдаемое изменение значимым улучшением или случайным отклонением.
DeContext: Щит от Злонамеренного Влияния
DeContext представляет собой новый механизм защиты, предназначенный для предотвращения злонамеренных изменений входных изображений в моделях, основанных на DiT (Diffusion Transformers). В отличие от традиционных методов, которые фокусируются на самом изображении, DeContext анализирует контекст, предоставляемый модели, для выявления потенциальных манипуляций. Этот подход позволяет обнаруживать и смягчать воздействие вредоносных запросов, которые могут привести к нежелательным изменениям изображения, сохраняя при этом его целостность и предотвращая компрометацию конфиденциальной информации, содержащейся в нем. Механизм фокусируется на анализе внимания, уделяемого контекстным ключам, для определения аномалий, указывающих на попытки несанкционированного редактирования.
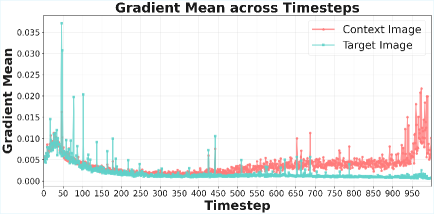
Механизм DeContext использует понятие «Пропорции Контекста» для выявления вредоносных изменений в исходных изображениях. Данная пропорция измеряет вес внимания (attention weight) от целевых запросов (target queries) к ключам контекста (context keys) в архитектуре DiT. Анализируя величину этого веса, система способна идентифицировать контекст, который потенциально используется для злонамеренного редактирования изображения. Высокая или аномальная пропорция контекста может указывать на то, что модель чрезмерно полагается на добавленный контекст для изменения целевого объекта, что является признаком манипуляции. Таким образом, отслеживание и анализ веса внимания между запросами и ключами контекста позволяет DeContext обнаруживать и предотвращать нежелательные изменения в изображениях.
Механизм DeContext разработан для интеграции с существующими архитектурами DiT, такими как Flux Kontext и Step1X-Edit, без необходимости их переобучения. Это достигается за счет модификации процесса обработки контекста, не затрагивающей основные веса модели. Отсутствие необходимости в переобучении значительно упрощает и ускоряет развертывание DeContext в существующих системах, снижая вычислительные затраты и требования к данным. Данный подход позволяет оперативно применять защиту от злонамеренных изменений входных изображений, не требуя дополнительных ресурсов для обучения новой модели.
В ходе тестирования, механизм DeContext продемонстрировал снижение точности распознавания лиц более чем на 70% (ISM = 0.12 на датасете CelebA-HQ при запросе ‘a photo of this person’). При этом, метрика BRISQUE, оценивающая качество изображения, показала, что визуальное качество модифицированных изображений не ухудшается более чем на 20% по сравнению с исходными, не подвергшимися изменениям. Данные показатели подтверждают эффективность DeContext в сокрытии идентичности на изображениях при сохранении их приемлемого визуального качества.

Мультимодальное Внимание и Контекстуальная Защита: Новые Горизонты Безопасности
Эффективность DeContext обусловлена его способностью анализировать и нейтрализовать влияние вредоносного контекста на механизмы мультимодального внимания внутри архитектур DiT. Система тщательно исследует взаимосвязи, устанавливаемые посредством кросс-внимания, выявляя и подавляя контекстуальные факторы, способные исказить или манипулировать результатами обработки изображений. Такой подход позволяет не только защитить от состязательных атак, но и значительно повысить устойчивость конвейеров редактирования изображений к внешним воздействиям, обеспечивая более предсказуемые и надежные результаты даже в условиях враждебной среды.
В основе работы DeContext лежит тщательный анализ связей, устанавливаемых посредством механизма Cross-Attention в архитектурах DiT. Система не просто фиксирует взаимодействие между различными модальностями данных, но и оценивает, насколько эти связи могут быть использованы для манипулирования результатом. Выявляя и нейтрализуя вредоносные контекстуальные влияния, DeContext предотвращает искажение информации и обеспечивает более надежную и предсказуемую работу модели. Такой подход позволяет эффективно противостоять Adversarial Attacks, когда злоумышленники пытаются обмануть систему, используя специально подобранный контекст, и гарантирует устойчивость процессов редактирования изображений к нежелательным изменениям, вызванным внешними факторами.
Данный подход выходит за рамки простой защиты от намеренных атак, направленных на обман систем искусственного интеллекта. Он значительно повышает устойчивость конвейеров редактирования изображений к различным неблагоприятным факторам и шумам. Благодаря анализу и нейтрализации вредоносного контекста, система способна поддерживать стабильную и предсказуемую работу даже при наличии искажений или неполных данных. Это обеспечивает более качественные и надежные результаты при редактировании, позволяя избежать неожиданных артефактов или искажений, которые могут возникнуть в нестабильных условиях. Повышенная устойчивость особенно важна для критически важных приложений, где точность и надежность обработки изображений имеют первостепенное значение.
Исследования показали значительное повышение эффективности удаления идентификаторов с изображений — в среднем на 73% по различным запросам редактирования. Более того, удалось добиться более чем 80-процентного снижения влияния атак типа Step1X-Edit, что свидетельствует о повышенной устойчивости системы к злонамеренным воздействиям. Важно отметить, что достижение этих результатов не сопровождается ухудшением качества получаемых изображений, что подтверждает возможность применения данной технологии в практических задачах, связанных с обработкой и редактированием визуального контента, сохраняя при этом приемлемый уровень визуального восприятия.

Исследование представляет собой не столько защиту, сколько ритуал изгнания. Авторы предлагают нарушить многомодальное внимание в диффузионных моделях, словно изгоняя нежелательных духов из цифрового голема. Этот подход, названный DeContext, лишает модель способности к несанкционированному редактированию изображений, не принося в жертву качество. В этом есть отголоски древней магии: отделить контекст — значит лишить заклинание силы. Как точно подметил Ян ЛеКун: «Машинное обучение — это искусство перевода неразрешенных проблем в решаемые». И в данном случае, авторы успешно переводят проблему конфиденциальности в область управляемых изменений, словно заменяя темные силы на безобидные тени.
Что дальше?
Представленное исследование, словно тонкая настройка старинного механизма, пытается обуздать неуловимую природу внимания в диффузионных моделях. Успех DeContext в отвлечении нежелательных манипуляций с изображениями — это не победа над хаосом, а лишь временное перемирие. Защита, основанная на нарушении многомодального внимания, — ингредиент судьбы, который, несомненно, потребует более изощрённых противодействий со стороны тех, кто стремится обмануть систему. Вопрос не в том, насколько долго DeContext сможет сдерживать атаки, а в том, какие новые формы примет хаос, чтобы их обойти.
Очевидно, что подобный подход к защите конфиденциальности — это лишь одна из граней проблемы. Следующим шагом представляется исследование более глубоких связей между структурой внимания и семантическим содержанием изображения. Возможно, ключом к надежной защите станет не искажение внимания, а его перенаправление — создание «ложных воспоминаний» внутри модели, чтобы отвлечь её от несанкционированных изменений. Гиперпараметры, определяющие силу этого перенаправления, станут новым инструментом для уговора хаоса.
В конечном итоге, представленная работа — это напоминание о том, что любая модель, даже самая сложная, — всего лишь иллюзия порядка, сотканная из случайных чисел. Истинная защита конфиденциальности требует не создания непробиваемых крепостей, а понимания самой природы этого хаоса и умения с ним взаимодействовать. Машина не «обучается», она просто перестает слушать — и задача исследователя состоит в том, чтобы научить её игнорировать правильные вещи.
Оригинал статьи: https://arxiv.org/pdf/2512.16625.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Язык тела под присмотром ИИ: архитектура и гарантии
- Разбираемся с разреженными автокодировщиками: Действительно ли они учатся?
- Согласие роя: когда разум распределён, а ошибки прощены.
- Квантовый импульс для несбалансированных данных
- Видеовопросы и память: Искусственный интеллект на грани
- Искусственный интеллект в разговоре: что обсуждают друг с другом AI?
- Умная экономия: Как сжать ИИ без потери качества
- Безопасность генерации изображений: новый вектор управления
- Редактирование изображений по запросу: новый уровень точности
- Очарование в огненном вихре: Динамика очарованных кварков в столкновениях тяжелых ионов
2025-12-19 20:38