Автор: Денис Аветисян
Исследователи разработали метод, использующий анализ графов причинно-следственных связей для более точной локализации проблем в больших кодовых базах.

Представлен GraphLocator — система, использующая большие языковые модели и анализ графов для выявления первопричин ошибок в программном обеспечении.
Задача локализации проблем в программном обеспечении, заключающаяся в выявлении участков кода, требующих изменений по текстовому описанию дефекта, осложняется семантическим разрывом между естественным языком и кодом. В работе ‘GraphLocator: Graph-guided Causal Reasoning for Issue Localization’ предложен подход GraphLocator, использующий графовое представление причинно-следственных связей между подзадачами и кодовыми сущностями для преодоления несоответствий между симптомами и первопричинами, а также для решения проблем, связанных с зависимостью между различными частями кода. Эксперименты на реальных наборах данных продемонстрировали, что GraphLocator значительно превосходит существующие методы, обеспечивая улучшение точности локализации на 19.49% по recall и на 11.89% по precision. Сможет ли данное графовое представление причинно-следственных связей стать основой для более интеллектуальных систем автоматизированного исправления ошибок в программном обеспечении?
Вызовы локализации проблем в коде
В современных программных разработках, особенно при работе со сложными кодовыми базами, локализация проблем становится серьезным вызовом. Тонкости в описаниях ошибок, часто не отражающие истинную причину, в сочетании с огромным объемом кода, приводят к значительным задержкам в обнаружении и исправлении дефектов. Разработчики сталкиваются с растущим уровнем разочарования, поскольку поиск источника ошибки может превратиться в трудоемкий и неэффективный процесс. Это, в свою очередь, негативно сказывается на сроках выпуска новых версий программного обеспечения и может привести к потере конкурентоспособности. Таким образом, повышение эффективности локализации проблем является критически важной задачей для современной индустрии разработки.
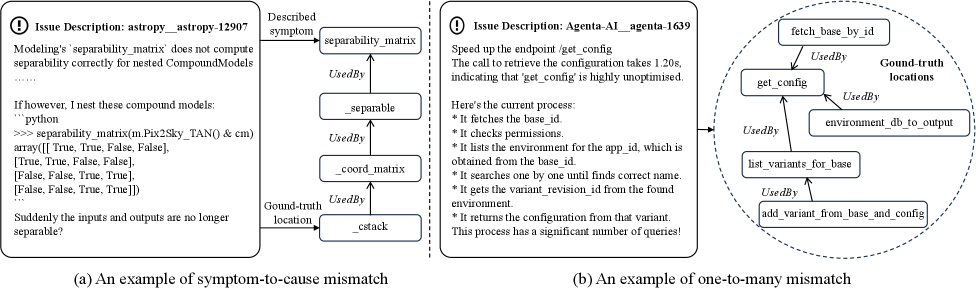
Существенная сложность локализации проблем в коде заключается в точном сопоставлении высокоуровневых описаний неисправностей с лежащими в их основе причинами, которые зачастую скрыты несоответствием между симптомами и первопричиной. Разработчики сталкиваются с ситуацией, когда наблюдаемое проявление ошибки не указывает напрямую на место её возникновения, требуя глубокого анализа и отладки. Это несоответствие усугубляется сложностью современных программных систем, где даже незначительное изменение в одной части кода может привести к неожиданным последствиям в другой. Поэтому, эффективная локализация требует не просто обнаружения симптомов, но и способности проследить цепочку событий, приводящих к ошибке, чтобы выявить истинную причину и устранить её.
Часто встречается ситуация, когда одно сообщение об ошибке требует внесения изменений сразу в несколько взаимосвязанных частей кодовой базы. Это явление, известное как несоответствие “один ко многим”, значительно усложняет процесс локализации проблемы. Ошибка, проявляющаяся на высоком уровне, может быть вызвана взаимодействием нескольких компонентов, и исправление в одной области может потребовать последующей корректировки в других. Такая взаимозависимость усложняет отслеживание влияния изменений и повышает риск внесения новых ошибок при попытке исправить исходную. В результате, разработчики сталкиваются с увеличением времени, необходимого для исправления ошибок, и повышенной сложностью в обеспечении стабильности программного обеспечения.
Эволюция подходов на основе больших языковых моделей
Первоначальные подходы к локализации проблем на основе больших языковых моделей (LLM) использовали семантическое сопоставление на основе векторных представлений (embeddings) между описанием проблемы и исходным кодом. Этот метод заключался в преобразовании как описания проблемы, так и фрагментов кода в векторные представления в многомерном пространстве, после чего выявлялись наиболее близкие по смыслу фрагменты кода к описанию проблемы. По сравнению с предыдущими подходами, основанными на точном совпадении ключевых слов или регулярных выражениях, данный метод обеспечил существенное улучшение точности локализации благодаря способности учитывать семантическую близость и контекст, что позволило выявлять проблемы, связанные с кодом, даже при отсутствии явных совпадений в тексте.
Первоначальные методы локализации проблем, основанные на больших языковых моделях (LLM), были дополнены процедурными рабочими процессами, которые направляют LLM через предопределенные иерархические шаги. В отличие от простого сопоставления семантических представлений, процедурные рабочие процессы структурируют процесс анализа, разбивая задачу на последовательность конкретных операций. Например, LLM может быть запрошен сначала на идентификацию релевантных файлов, затем на анализ этих файлов на предмет потенциальных ошибок, и, наконец, на предоставление конкретных предложений по исправлению. Такая структурированность повышает надежность и воспроизводимость результатов, а также позволяет более эффективно использовать ресурсы LLM за счет сужения области поиска.
Дальнейшая эволюция подходов к локализации проблем привела к появлению агентных рабочих процессов, в которых большие языковые модели (LLM) рассматриваются как автономные агенты, способные использовать инструменты и осуществлять поиск. В отличие от предыдущих методов, основанных на фиксированных процедурах или семантическом сопоставлении, агентные системы позволяют LLM самостоятельно определять последовательность действий для выявления источника ошибки. Это достигается путем интеграции LLM с различными инструментами, такими как отладчики, системы контроля версий и анализаторы кода, позволяя им активно исследовать кодовую базу и собирать необходимую информацию для точной локализации проблемы. Такой подход обеспечивает более гибкое и надежное выявление проблем, особенно в сложных и больших проектах.
Графовые подходы: структурирование понимания кода
Графовые подходы моделируют кодовую базу как сеть, состоящую из сущностей кода (функций, классов, модулей) и связей между ними, представляющих зависимости. В этой модели каждый элемент кода представлен узлом графа, а зависимости, такие как вызовы функций, наследование или импорты, — ребрами. Такое представление позволяет формализовать структуру проекта, выявлять ключевые компоненты и их взаимосвязи, а также анализировать влияние изменений в коде. Графовая структура обеспечивает возможность количественной оценки сложности проекта и упрощает навигацию по кодовой базе, поскольку отражает не только синтаксические, но и семантические связи между элементами кода.
Интеграция структурной информации о кодовой базе в агентивные рабочие процессы значительно повышает способность больших языковых моделей (LLM) к навигации и пониманию сложных проектов. Вместо последовательного анализа исходного кода, LLM, использующие графовые представления, могут эффективно определять зависимости между компонентами, выявлять ключевые модули и понимать архитектуру системы. Это позволяет модели более точно отвечать на запросы, связанные с кодом, выполнять рефакторинг, обнаруживать ошибки и предлагать улучшения, поскольку она оперирует не только текстом кода, но и его внутренней структурой и связями между элементами.
Структура иерархических зависимостей репозитория, часто называемая ‘Repository Dependency Fractal Structure’, представляет собой способ моделирования взаимосвязей между компонентами кода, такими как модули, классы и функции. Она строится на основе анализа импортов, вызовов функций и других типов зависимостей, позволяя представить репозиторий как древовидную структуру, где каждый узел соответствует компоненту, а связи отражают зависимости между ними. Эта фрактальная структура позволяет LLM эффективно ориентироваться в кодовой базе, выявлять ключевые компоненты и понимать влияние изменений в одном модуле на другие, что критически важно для задач рефакторинга, отладки и анализа кода.
GraphLocator: причинно-следственное обоснование для глубокого решения проблем
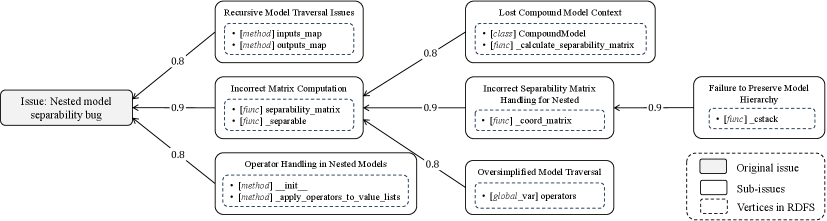
GraphLocator использует ‘Граф причинно-следственных связей’ (Causal Issue Graph) для представления многошаговых зависимостей между подзадачами и элементами кода. Этот граф позволяет модели LLM отслеживать цепочку событий, приводящих к проблеме, выявляя первопричину путем анализа взаимосвязей между различными компонентами системы. Каждая вершина графа представляет собой либо конкретную подзадачу, возникшую в процессе работы, либо элемент кода, ответственный за ее выполнение, а ребра отражают причинно-следственные связи между ними. Построение и анализ такого графа позволяет LLM не просто находить место возникновения ошибки, но и понимать, почему она произошла, что значительно повышает эффективность решения проблем.
Подход GraphLocator объединяет преимущества структурного анализа на основе графов с продвинутыми техниками рассуждений, такими как абдуктивное и причинно-следственное. Структурное представление в виде графа позволяет моделировать взаимосвязи между отдельными подзадачами и элементами кода, что необходимо для отслеживания цепочек причинно-следственных связей. Абдуктивное рассуждение используется для формирования наиболее вероятных объяснений наблюдаемых симптомов, а причинно-следственное рассуждение — для определения корневых причин, вызвавших проблему. Комбинация этих подходов позволяет GraphLocator не просто находить проблемные участки кода, но и понимать, почему они вызвали сбой, обеспечивая более точную и эффективную локализацию.
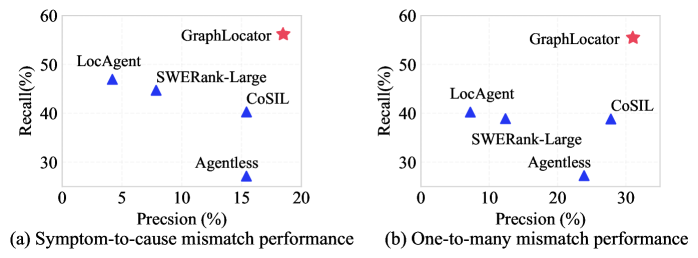
GraphLocator использует метод динамического разделения сложной проблемы на более мелкие, управляемые подзадачи. Этот подход позволяет повысить точность и эффективность локализации неисправностей. В ходе тестирования GraphLocator продемонстрировал значительное улучшение показателей по сравнению с существующими методами: средний прирост точности восстановления функций (function-level recall) составил +19.49%, а точность (precision) — +11.89%.
Подтверждение и будущие направления
В настоящее время эффективность подходов, подобных GraphLocator, активно подтверждается на стандартных наборах данных, таких как ‘SWE-bench Lite’, ‘LocBench’ и ‘Multi-SWE-bench’. Проведенные тесты демонстрируют существенное повышение точности локализации дефектов в программном коде. В частности, GraphLocator достиг показателя F1-Score в 30.67% на наборе ‘SWE-bench Lite’, что свидетельствует о значительном прогрессе в автоматизированном поиске проблем в коде и потенциале для существенного облегчения работы разработчиков.
Создание стандартизированных наборов данных, таких как SWE-bench Lite, LocBench и Multi-SWE-bench, представляет собой ключевой шаг в развитии методов локализации ошибок в программном обеспечении. Эти наборы данных обеспечивают общую платформу для объективного сравнения различных подходов, позволяя исследователям и разработчикам точно оценивать эффективность новых алгоритмов и отслеживать прогресс в этой области. Возможность проведения количественного анализа на единой базе данных значительно ускоряет процесс совершенствования инструментов, направленных на автоматизацию поиска и устранения дефектов в коде, и способствует более быстрому внедрению инноваций в практику разработки программного обеспечения.
Дальнейшие исследования направлены на расширение возможностей этих методов для работы с еще более масштабными и сложными кодовыми базами, что представляет собой значительную техническую задачу. Особое внимание уделяется разработке способов интеграции этих инструментов непосредственно в существующие рабочие процессы разработчиков. Цель состоит в том, чтобы сделать локализацию ошибок не просто более точной, но и более удобной и бесшовной для повседневной практики программирования. Это включает в себя изучение возможностей автоматической интеграции с системами контроля версий, средами разработки и инструментами непрерывной интеграции, что позволит значительно повысить производительность и качество программного обеспечения.
Исследование, представленное в данной работе, демонстрирует стремление к созданию систем, способных достойно стареть в условиях сложной кодовой базы. Подход GraphLocator, использующий причинно-следственный граф для локализации проблем, отражает понимание того, что симптомы и причины могут быть разделены, а компоненты кода — взаимозависимы. Кен Томпсон однажды заметил: «Все системы стареют — вопрос лишь в том, делают ли они достойно». Эта фраза перекликается с идеей, лежащей в основе GraphLocator, — стремлением создать инструмент, который помогает поддерживать «здоровье» программного обеспечения на протяжении всего его жизненного цикла, даже когда оно сталкивается с неизбежными изменениями и усложнениями. GraphLocator, по сути, предлагает способ замедлить процесс «старения» системы, обеспечивая более эффективную диагностику и устранение проблем.
Куда Ведет Дорога?
Представленная работа, конструируя причинно-следственный граф проблем, делает шаг к преодолению поверхностного сопоставления симптомов и первопричин. Однако, архитектура без истории хрупка и скоротечна. Создание графа, несомненно, требует времени, но истинная ценность заключается не в скорости его построения, а в понимании тех допущений и упрощений, которые неизбежно в него заложены. Каждая задержка — цена понимания. Необходимо признать, что сложная взаимосвязь компонентов программного обеспечения может порождать петли обратной связи и нелинейные эффекты, которые текущий подход, вероятно, не в полной мере учитывает.
Следующим этапом представляется исследование методов автоматического обнаружения и интеграции исторических данных о внесённых изменениях, паттернах ошибок и контексте разработки. Учет «эволюции» причинно-следственного графа, его адаптации к изменениям кода, — задача нетривиальная, но перспективная. Иначе, мы рискуем получить статичную модель, не способную отразить динамику реальных программных систем.
В конечном счете, ценность подобных исследований не в достижении абсолютной точности локализации проблем, а в создании инструментов, позволяющих разработчикам глубже понимать логику и структуру программного обеспечения. Все системы стареют — вопрос лишь в том, делают ли они это достойно. Именно эта «достойная старость» — способность адаптироваться, обучаться и сохранять функциональность — должна стать ориентиром для будущих исследований.
Оригинал статьи: https://arxiv.org/pdf/2512.22469.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Когда мнения расходятся: как модели принимают решения при конфликте данных
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Шёпот языков: как дрессировать цифрового голема для забытых наречий.
- Взгляд в будущее: как теория динамических систем преобразит анализ временных рядов
- Наука больших команд и широких горизонтов
- Белки-хамелеоны: Пределы предсказания гибкости структуры
- Переключение намагниченности в квантовых антиферромагнетиках: новые горизонты для терагерцовой спинтроники
- Оптимизация больших языковых моделей: новый подход к снижению требований к ресурсам
- Самоуправляемая защита ИИ: Экосистема PBSAI
- Очарование в огненном вихре: Динамика очарованных кварков в столкновениях тяжелых ионов
2025-12-31 12:05