Автор: Денис Аветисян
Исследователи представили JavisGPT, модель, способную одновременно анализировать и генерировать видео и звук, обеспечивая их синхронизацию и реалистичность.
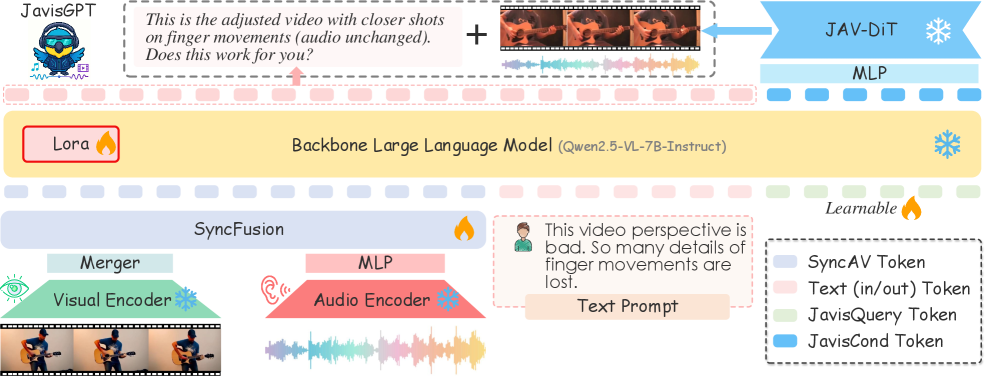
JavisGPT — это мультимодальная большая языковая модель, использующая архитектуру Diffusion Transformer и инструктивное обучение для достижения передовых результатов в задачах понимания и генерации синхронизированного аудио-визуального контента.
Несмотря на значительный прогресс в области мультимодального искусственного интеллекта, совместное понимание и генерация синхронизированного звука и видео остаются сложной задачей. В данной работе представлена модель JavisGPT: A Unified Multi-modal LLM for Sounding-Video Comprehension and Generation, — первая унифицированная большая мультимодальная языковая модель, способная комплексно обрабатывать аудио-визуальную информацию. Модель демонстрирует превосходные результаты в задачах понимания и генерации синхронизированных аудио-визуальных данных, благодаря архитектуре, включающей модуль SyncFusion и обучение на новом наборе данных JavisInst-Omni. Какие перспективы открывает JavisGPT для создания более реалистичных и интерактивных мультимедийных приложений?
Синхронизация как Абсолют: Вызовы Мультимодального Понимания
Существующие мультимодальные модели зачастую испытывают трудности с точной синхронизацией аудио и видео, что приводит к фрагментированному восприятию контента. Неспособность адекватно улавливать и воспроизводить временные зависимости между звуком и изображением проявляется в рассинхронизации губ, несовпадении звуковых эффектов с визуальными событиями и общей несвязности происходящего. Это особенно заметно в сложных сценах, где требуется одновременное понимание нескольких аудиовизуальных элементов. В результате, даже при высоком качестве отдельных модальностей, итоговый пользовательский опыт оказывается испорченным из-за отсутствия целостности и когерентности, что ограничивает возможности применения подобных моделей в задачах, требующих безупречной синхронизации, таких как виртуальная реальность или создание контента для людей с нарушениями слуха и зрения.
Достижение высокоточной синхронизации аудио и видео требует тонкого моделирования временных зависимостей, что представляет собой значительную проблему для современных архитектур. Существующие системы часто не способны улавливать сложные взаимосвязи между звуком и изображением во времени, что приводит к рассинхронизации и снижению качества восприятия. Особенно сложной задачей является моделирование нелинейных временных задержек и изменений скорости, когда звуковые и визуальные события происходят не одновременно или с разной скоростью. Для решения этой проблемы необходимы новые подходы, способные учитывать контекстную информацию и динамически адаптироваться к изменениям во временной структуре аудиовизуального потока, позволяя создавать более реалистичные и правдоподобные мультимедийные впечатления.
Ограниченность моделей, способных не только понимать, но и генерировать синхронизированный аудиовизуальный контент, существенно сдерживает развитие передовых приложений в сферах виртуальной реальности и создания доступных медиа. В виртуальной среде это проявляется в нереалистичности взаимодействия объектов и персонажей, где несоответствие звука и изображения разрушает эффект погружения. В области доступных медиа, таких как автоматическое создание аудиодескрипций для слабовидящих, отсутствие подобных моделей препятствует формированию полноценного и естественного восприятия визуальной информации. Разработка алгоритмов, способных создавать согласованные аудиовизуальные последовательности, открывает перспективы для создания более инклюзивных и реалистичных цифровых впечатлений, значительно расширяя возможности взаимодействия человека с технологиями.
JavisGPT: Унифицированная Мультимодальная Основа
JavisGPT представляет собой унифицированную мультимодальную большую языковую модель (MLLM), в основе которой лежит архитектура Qwen2.5-VL. Данная архитектура обеспечивает надежное понимание как визуальной, так и текстовой информации, позволяя модели эффективно обрабатывать и интерпретировать данные, поступающие из различных модальностей. Использование Qwen2.5-VL в качестве основы позволяет JavisGPT достигать высокой производительности в задачах, требующих комплексного анализа и сопоставления визуального и текстового контента, например, в задачах визуального вопросно-ответного поиска и генерации описаний изображений.
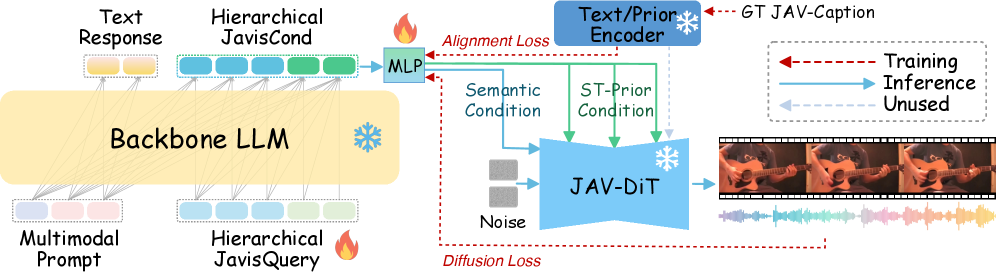
Ядро системы JavisGPT представлено моделью JavisDiT — предварительно обученным генератором DiT (Diffusion Transformer), предназначенным для синтеза высококачественного аудиовизуального контента. JavisDiT использует архитектуру Diffusion Transformer для последовательного преобразования входных данных в аудио- и видеопотоки. Предварительное обучение модели проводилось на обширном наборе данных, включающем аудио- и видеоматериалы различного типа, что позволяет ей генерировать реалистичный и когерентный мультимедийный контент. Использование DiT обеспечивает эффективное моделирование сложных зависимостей между аудио- и видеоданными, что является ключевым фактором для достижения высокого качества синтеза.
Для повышения синхронизации между сгенерированными аудио- и видеопотоками в JavisDiT интегрированы запросы пространственно-временных приоритетов (Spatiotemporal Prior Queries). Данный механизм позволяет учитывать корреляции между визуальными и звуковыми элементами, обеспечивая согласованность и реалистичность мультимодального контента. Запросы формируются на основе анализа пространственных характеристик видео (например, положения объектов) и временных характеристик аудио (например, ритма и интонации), что позволяет модели более точно соотносить звуковые события с соответствующими визуальными проявлениями. Это достигается за счет использования специализированных слоев внимания, которые динамически взвешивают вклад различных пространственно-временных признаков при генерации контента.
Трехэтапный Конвейер Обучения для Синхронизированной Генерации
Обучение JavisGPT осуществляется посредством трехэтапного конвейера, включающего предварительное обучение, тонкую настройку и обучение с подкреплением по инструкциям. Эта методология позволяет модели последовательно осваивать общие языковые навыки на этапе предварительного обучения, адаптировать их к конкретным задачам на этапе тонкой настройки и, наконец, оптимизировать взаимодействие с пользователем и следование инструкциям на заключительном этапе. Такой подход обеспечивает надежную и универсальную производительность модели в широком спектре задач, связанных с аудиовизуальным пониманием и генерацией.
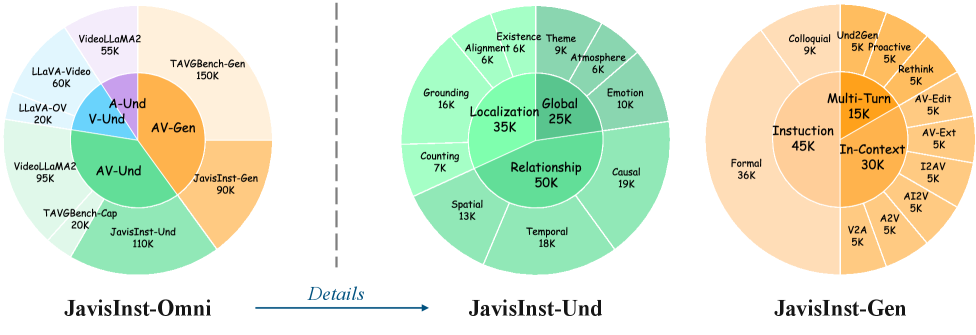
Обучение JavisGPT использует масштабный датасет JavisInst-Omni, включающий в себя разнообразные аудиовизуальные сценарии для понимания и генерации контента. Датасет охватывает широкий спектр задач, включая распознавание речи, анализ видео, генерацию субтитров, ответы на вопросы по визуальному контенту и синтез речи с учетом визуального контекста. Разнообразие сценариев в JavisInst-Omni обеспечивает модели возможность обобщения и адаптации к новым, ранее не встречавшимся ситуациям, повышая ее надежность и эффективность в различных приложениях.
Для оптимизации производительности и снижения вычислительных затрат в процессе обучения JavisGPT используется адаптация LoRA (Low-Rank Adaptation). Этот метод предполагает замораживание предварительно обученных весов модели и обучение небольшого количества низкоранговых матриц, добавляемых к существующим слоям. Это значительно уменьшает количество обучаемых параметров — вместо обновления всех весов модели, обновляются только параметры этих дополнительных матриц, что приводит к снижению требований к памяти и вычислительным ресурсам при сохранении высокой производительности и возможности адаптации модели к новым задачам. Эффективность LoRA обусловлена тем, что обновления в низкоранговом пространстве часто оказываются достаточными для достижения необходимой адаптации модели.
За Гранью Генерации: Влияние и Перспективы Развития
Возможность генерации идеально синхронизированного аудио и видео открывает захватывающие перспективы в сферах виртуальной и дополненной реальности, а также в создании доступных медиа для людей с ограниченными возможностями. Представьте себе виртуальные миры, где звук и изображение сливаются в единое целое, создавая беспрецедентный уровень погружения и реализма. В дополненной реальности это позволит создавать более убедительные и интерактивные наложения на окружающую действительность. Но, пожалуй, наиболее значимым является потенциал для создания медиаконтента, адаптированного для людей с нарушениями зрения или слуха, где идеальная синхронизация аудио и видео может существенно улучшить восприятие и понимание информации, делая цифровой мир более инклюзивным и доступным для всех.
Модель JavisGPT преодолевает ключевое ограничение предыдущих мультимодальных систем благодаря явному моделированию пространственно-временной синхронизации с помощью SyncFusion. В отличие от предшественников, которые часто испытывают трудности с точным сопоставлением аудио и видео, JavisGPT обеспечивает согласованность этих модальностей, что критически важно для создания реалистичных и захватывающих впечатлений. Этот подход позволяет системе понимать и генерировать контент, в котором звук и изображение идеально скоординированы во времени и пространстве, открывая новые возможности в таких областях, как виртуальная и дополненная реальность, а также создание доступных медиа для людей с ограниченными возможностями восприятия.
Интеграция BEATs (Bidirectional Encoder Representations from Audio Transformers) значительно повышает качество аудиосоставляющей генерируемого контента. Данная технология позволяет модели JavisGPT создавать более детализированные и реалистичные звуковые ландшафты, что особенно важно для мультимодальных приложений. В отличие от предыдущих подходов, BEATs обеспечивает глубокое понимание структуры звука и его контекста, что позволяет генерировать аудио, точно синхронизированное с видео и соответствующее происходящим событиям. Такой подход не только улучшает общее восприятие контента, но и открывает новые возможности для создания иммерсивных впечатлений в виртуальной и дополненной реальности, а также для разработки более доступных медиаформатов, учитывающих потребности людей с ограниченными возможностями.

Исследование, представленное в данной работе, демонстрирует стремление к созданию алгоритмов, обладающих не только функциональностью, но и внутренней согласованностью. Модель JavisGPT, способная к совместному пониманию и генерации аудио и видео, подчеркивает важность синхронизации различных модальностей данных. Как однажды заметил Дэвид Марр: «Представление должно быть достаточно богатым, чтобы поддерживать все необходимые вычисления». Именно такое богатое представление, позволяющее модели JavisGPT успешно решать задачи синхронизации аудио и видео, является ключевым элементом её архитектуры. Подобный подход к разработке алгоритмов, основанный на математической чистоте и непротиворечивости, отвечает принципам истинной элегантности кода, где корректность решения является первостепенной задачей.
Что дальше?
Представленная работа, безусловно, демонстрирует впечатляющие возможности в области совместного понимания и генерации аудиовизуального контента. Однако, если решение кажется магией — а синхронизация звука и видео порой именно ею кажется — значит, не выявлен фундаментальный инвариант, обеспечивающий устойчивость модели к малейшим отклонениям. Достижение истинной элегантности требует не просто «работы на тестах», но и математической доказуемости корректности алгоритма.
Очевидным направлением для дальнейших исследований представляется углублённое изучение принципов причинности в мультимодальных данных. Модель пока демонстрирует способность к синхронизации, но недостаточно — к пониманию причинно-следственных связей между звуком и изображением. Устойчивость к «шуму» и артефактам, несомненно, требует более строгих математических формулировок и, возможно, новых архитектурных решений.
В конечном счете, истинный прогресс в данной области возможен лишь при переходе от эмпирической оптимизации к формальной верификации. Необходимо стремиться к созданию моделей, чья работа предсказуема и объяснима, а не просто демонстрирует высокие показатели на ограниченном наборе данных. Иначе, мы рискуем создать сложный, но непрозрачный «черный ящик», чьи ошибки будут столь же загадочны, сколь и его успехи.
Оригинал статьи: https://arxiv.org/pdf/2512.22905.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Когда мнения расходятся: как модели принимают решения при конфликте данных
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Шёпот языков: как дрессировать цифрового голема для забытых наречий.
- Взгляд в будущее: как теория динамических систем преобразит анализ временных рядов
- Обучение декодированию квантовых кодов LDPC: новый подход
- Сеть, управляемая интеллектом: новые возможности для экспериментов
- Ускорение генерации текста: новый подход к спекулятивному декодированию
- Внимание к квантовой теории поля: нейросети и трансформеры
- Визуальный интеллект: обучение рассуждению через головоломки
- Искусственный интеллект в роли астрофизика: эксперимент с задачами
2026-01-01 03:14