Автор: Денис Аветисян
Исследователи предлагают инновационный метод динамической маршрутизации, позволяющий оптимизировать вычисления в остаточных нейронных сетях без потери точности.
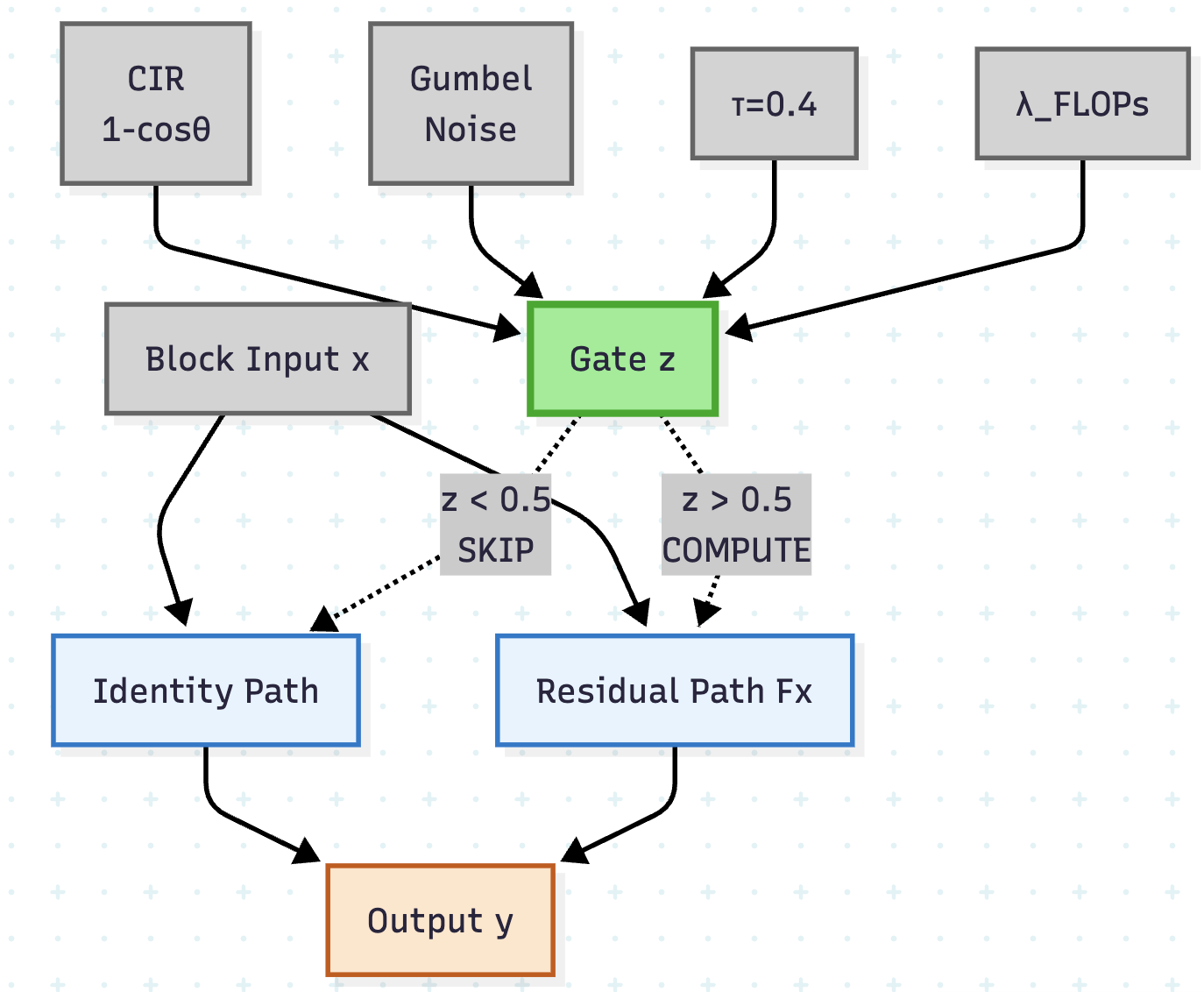
CosineGate использует геометрическую избыточность и меру косинусного несоответствия для подавления ненужных вычислений и снижения нагрузки на процессор.
Современные глубокие остаточные сети зачастую выполняют избыточные вычисления, оценивая все остаточные блоки для каждого входного сигнала, даже когда достаточно простого тождественного отображения. В данной работе, представленной под названием ‘CosineGate: Semantic Dynamic Routing via Cosine Incompatibility in Residual Networks’, предлагается архитектура CosineGate — механизм динамической маршрутизации, использующий косинусное несовпадение между тождественным и остаточным представлениями для подавления ненужных вычислений. Ключевым результатом является демонстрация возможности значительного снижения вычислительных затрат без потери точности, основанного на геометрической мере несовместимости признаков. Сможет ли подобный подход к динамической маршрутизации способствовать созданию более эффективных и энергосберегающих нейронных сетей?
Эффективность глубокого обучения: узкие места и пути оптимизации
Современные модели глубокого обучения, несмотря на свою впечатляющую производительность, зачастую требуют значительных вычислительных ресурсов. Эта потребность в вычислительной мощности становится серьезным препятствием для их развертывания на периферийных устройствах, таких как смартфоны или встроенные системы. Ограниченность ресурсов этих устройств, включая энергию и процессорную мощность, делает невозможным эффективное функционирование сложных нейронных сетей, разработанных для работы на мощных серверах. В результате, многие потенциально полезные приложения, требующие обработки данных в реальном времени непосредственно на устройстве, остаются недоступными или работают с неприемлемой задержкой. Поиск способов снижения вычислительных затрат без существенной потери точности является ключевой задачей для развития искусственного интеллекта и расширения сферы его применения.
Вычислительные издержки современных глубоких нейронных сетей часто обусловлены избыточностью операций внутри остаточных блоков, особенно в глубоких архитектурах. Исследования показывают, что в процессе прямого и обратного распространения сигнала многие нейроны и связи в этих блоках выполняют несущественные вычисления, не внося значимого вклада в конечный результат. По сути, сеть тратит ресурсы на обработку информации, которая уже была учтена или не является релевантной для текущей задачи. Эта избыточность увеличивает потребность в вычислительной мощности и памяти, ограничивая возможности развертывания моделей на устройствах с ограниченными ресурсами, таких как мобильные телефоны или встроенные системы. Оптимизация этих блоков с целью сокращения избыточных вычислений является ключевой задачей для повышения эффективности и масштабируемости глубокого обучения.
Вдохновленные принципами работы мозга, исследователи предлагают переход к динамическим методам вычислений в глубоком обучении. В отличие от традиционных моделей, выполняющих одни и те же вычисления для каждого входного сигнала, динамический подход предполагает избирательное выделение ресурсов на обработку наиболее релевантной информации. Это достигается путем адаптивного изменения структуры вычислений в реальном времени, позволяя сети концентрироваться на ключевых признаках и игнорировать несущественные детали. Подобная избирательность, характерная для нейронных сетей мозга, потенциально может значительно снизить вычислительную нагрузку и энергопотребление, открывая возможности для развертывания сложных моделей на устройствах с ограниченными ресурсами, таких как мобильные телефоны и встроенные системы.
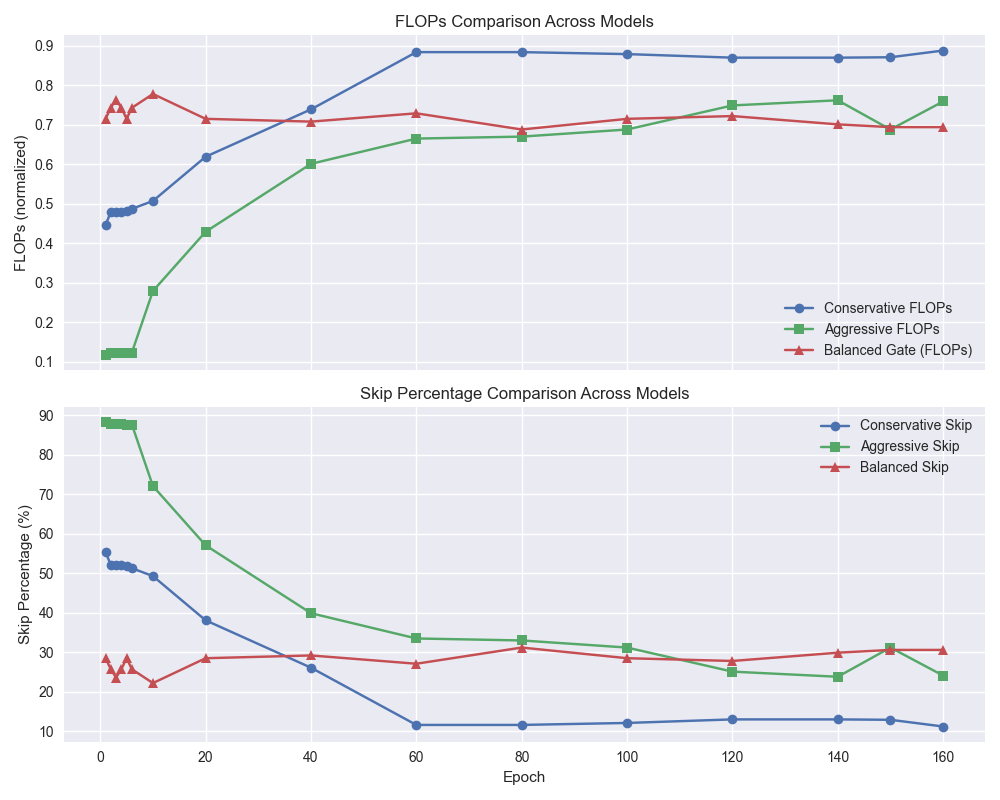
CosineGate: Динамическая маршрутизация для эффективных вычислений
Механизм динамической маршрутизации CosineGate реализуется путем выборочного пропуска или вычисления остаточных блоков на основе направленной разницы между входными и остаточными преобразованиями. В отличие от традиционных остаточных связей, где все блоки всегда вычисляются, CosineGate оценивает сходство направлений входного сигнала и выхода остаточного блока. Если направленная разница незначительна, блок пропускается, что снижает вычислительную нагрузку. Оценка направленной разницы выполняется для каждого блока, позволяя сети адаптироваться к различным входным данным и динамически регулировать использование ресурсов. Это обеспечивает более эффективное использование вычислительных ресурсов, особенно в глубоких нейронных сетях.
Коэффициент Косинусной Несовместимости (Cosine Incompatibility Ratio) является ключевой метрикой, определяющей степень избыточности между входным сигналом и преобразованием остаточного блока. Он рассчитывается как косинус угла между векторами входного сигнала и остаточного преобразования, что позволяет количественно оценить их направленное различие. Значение, близкое к 1, указывает на высокую степень совместимости и необходимость вычисления остаточного блока, в то время как значение, близкое к -1, сигнализирует о высокой степени несовместимости и возможности пропустить блок для экономии вычислительных ресурсов. Именно этот коэффициент служит основой для принятия решения о маршрутизации сигнала, определяя, какие остаточные блоки следует активировать, а какие — пропускать, обеспечивая адаптивное распределение вычислительной мощности.
Механизм адаптивного распределения вычислительных ресурсов в CosineGate позволяет сети динамически перенаправлять поток данных, избегая избыточных вычислений в малоинформативных путях. Это достигается путем оценки степени информативности каждого остаточного блока и выборочного пропуска или выполнения операций в зависимости от этой оценки. В результате, сеть концентрируется на обработке наиболее значимых преобразований, что приводит к снижению вычислительной сложности и повышению эффективности использования ресурсов, особенно при работе с избыточными или повторяющимися данными. Такой подход позволяет оптимизировать производительность модели без существенной потери точности.

Реализация и обучение с использованием Gumbel-Softmax
Для обеспечения сквозного обучения динамического механизма переключения используется релаксация Gumbel-Softmax, которая аппроксимирует дискретные решения о переключении непрерывной, дифференцируемой функцией. Традиционно, переключение между различными путями в нейронной сети является дискретным процессом, что препятствует распространению градиентов и, следовательно, обучению. Gumbel-Softmax позволяет заменить дискретный выбор непрерывным распределением, полученным путем добавления шума Gumbel к логитам и последующим применением функции softmax. Это создает дифференцируемую аппроксимацию, позволяющую вычислять градиенты через операцию переключения и эффективно обучать всю сеть методом обратного распространения ошибки. В результате достигается возможность оптимизации параметров сети, управляющих динамическим механизмом переключения, напрямую на основе целевой функции.
Использование Gumbel-Softmax обеспечивает эффективное распространение градиента в процессе обучения сети. Традиционные дискретные решения о переключении (gating) препятствуют обратному распространению ошибки из-за отсутствия дифференцируемости. Gumbel-Softmax аппроксимирует эти дискретные решения непрерывной функцией, что позволяет вычислять градиенты и обновлять веса сети. Это, в свою очередь, позволяет сети изучать оптимальные стратегии управления потоком информации, максимизируя производительность и эффективность модели. \nabla L может быть вычислен и использован для обучения параметров сети, что невозможно при использовании жестких дискретных переключателей.
Для повышения стабильности обучения и улучшения производительности модели используются методы регуляризации FLOPs (Floating-point Operations) и Consistency Regularization. Регуляризация FLOPs направлена на минимизацию вычислительной сложности модели путем штрафования избыточных операций с плавающей точкой. Consistency Regularization, в свою очередь, способствует повышению устойчивости обучения за счет поощрения согласованности предсказаний модели при небольших возмущениях входных данных. L_{consistency} = \mathbb{E}_{x, \epsilon}[||f(x) - f(x + \epsilon)||^2], где f(x) — предсказание модели, а ε — случайное возмущение. Совместное применение этих методов позволяет добиться более надежного и эффективного обучения динамического механизма управления.
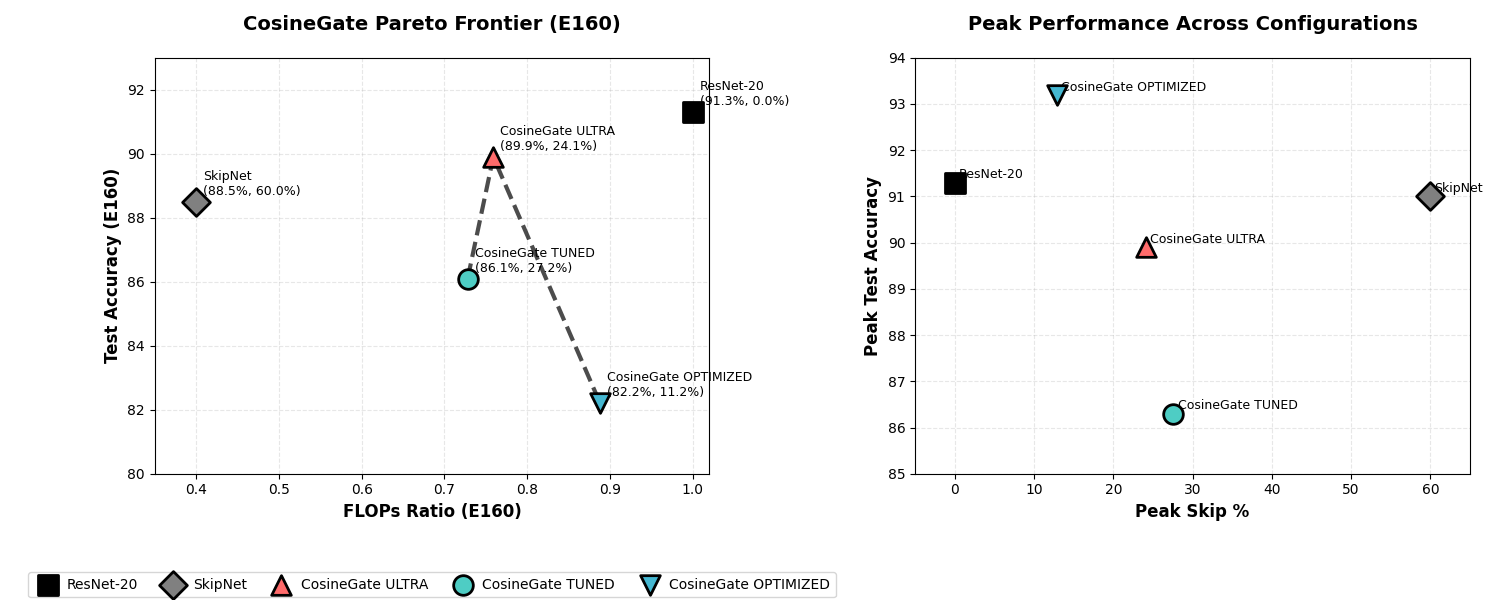
Эмпирические результаты и выигрыш в производительности
Экспериментальные оценки на широко используемых наборах данных, таких как MNIST и CIFAR-10, продемонстрировали, что архитектура CosineGate достигает сопоставимых, а в некоторых случаях и превосходящих результатов по сравнению с традиционными сверточными нейронными сетями, включая ResNet-20. Данные результаты подтверждают эффективность предложенного подхода к динамической маршрутизации, позволяя CosineGate эффективно обрабатывать изображения и достигать высокой точности классификации. Это указывает на потенциал CosineGate в качестве конкурентоспособной альтернативы существующим архитектурам глубокого обучения, особенно в задачах, требующих высокой производительности и эффективности вычислений.
В ходе экспериментов с набором данных CIFAR-10 архитектура CosineGate продемонстрировала впечатляющую точность в 93.2% по показателю Top-1. Этот результат значительно превосходит аналогичный показатель, достигнутый традиционной архитектурой ResNet-20, который составил 91.3%. Полученное превосходство в точности подтверждает эффективность предложенного подхода к построению нейронных сетей и указывает на потенциал CosineGate для решения сложных задач компьютерного зрения, требующих высокой степени распознавания образов.
Исследования показали, что разработанный метод динамической маршрутизации значительно снижает вычислительные затраты без потери точности. На датасете CIFAR-10 удалось добиться уменьшения количества операций с плавающей точкой (FLOPs) на 28.5%, сохранив при этом высокую точность классификации. Еще более заметный эффект наблюдается на датасете MNIST, где снижение FLOPs составило 37% при точности Top-1 в 99.5%. Такое уменьшение вычислительной сложности открывает возможности для применения данной архитектуры на устройствах с ограниченными ресурсами и для ускорения процесса обучения, делая ее привлекательной для широкого спектра задач машинного зрения.
Перспективы: к нейро-вдохновленным архитектурам
Механизм CosineGate предоставляет перспективную основу для расширения принципов динамической маршрутизации на более сложные архитектуры глубокого обучения, такие как ConvNeXt и Vision Transformers. В отличие от традиционных подходов, использующих фиксированные пути активаций, CosineGate позволяет сети адаптировать потоки информации в реальном времени, основываясь на сходстве между входными данными и весами нейронов. Это достигается за счет использования косинусного сходства для определения степени активации каждого нейрона, что обеспечивает более гибкую и эффективную обработку информации. Интеграция CosineGate в современные архитектуры может привести к повышению точности, снижению вычислительных затрат и улучшению способности к обобщению, приближая искусственные нейронные сети к принципам работы биологического мозга.
Дальнейшие исследования в области автоматического поиска архитектур нейронных сетей (Neural Architecture Search) могут эффективно использовать CosineGate в качестве фундаментального строительного блока. Этот подход позволяет создавать высокопроизводительные и адаптивные нейронные сети, поскольку CosineGate обеспечивает динамическую маршрутизацию информации, имитирующую принципы работы мозга. Использование CosineGate в качестве базового компонента позволяет алгоритмам поиска архитектур исследовать более широкий спектр конфигураций, оптимизируя не только точность, но и вычислительную эффективность. Такой подход открывает перспективы для создания нейронных сетей, способных адаптироваться к изменяющимся условиям и решать сложные задачи с минимальными затратами ресурсов, приближая искусственный интеллект к принципам нейронной организации биологических систем.
Данная работа вносит вклад в расширяющуюся область исследований, стремящихся преодолеть разрыв между искусственным интеллектом и удивительными вычислительными возможностями мозга. Исследователи все чаще обращаются к принципам нейронной организации для создания более эффективных и адаптивных алгоритмов. Подобный подход позволяет не только улучшить производительность существующих моделей, но и разработать принципиально новые архитектуры, способные к обучению и обобщению, приближенные к биологическим системам. Стремление к нейро-вдохновленным решениям открывает перспективы для создания искусственного интеллекта, способного к более гибкому и контекстуальному мышлению, что является ключевым шагом на пути к созданию действительно интеллектуальных машин.
Исследование демонстрирует стремление к устранению избыточности в архитектуре нейронных сетей. Подход CosineGate, основанный на выявлении геометрической избыточности и подавлении ненужных вычислений, соответствует принципу, что совершенство достигается не добавлением, а удалением. Как однажды заметил Пол Эрдеш: «Математика — это искусство делать вещи простыми». Эта фраза отражает суть представленной работы, стремящейся к лаконичности и эффективности без потери точности, что особенно актуально в контексте neuromorphic computing и sparse computation. Упрощение модели посредством динамической маршрутизации, как показано в статье, — это не ограничение, а доказательство глубокого понимания принципов работы residual networks.
Куда Далее?
Предложенный механизм CosineGate, безусловно, демонстрирует потенциал в снижении вычислительной нагрузки, эксплуатируя избыточность, присущую остаточным сетям. Однако, истинная сложность не в устранении лишних операций, а в определении того, что является «лишним». Геометрическая избыточность — лишь одна грань, и вопрос о том, как эффективно идентифицировать и использовать иные формы избыточности в более широком классе архитектур, остаётся открытым. Упрощение — это не всегда приближение к истине.
Перспективы, связанные с нейроморфными вычислениями и разреженными вычислениями, кажутся логичными, но требуют осторожного подхода. Нельзя забывать, что эффективность — это не самоцель. Погоня за сокращением FLOPs часто приводит к усложнению самой модели, что нивелирует все преимущества. Ясность — это минимальная форма любви; и эта ясность должна быть отражена в структуре самой сети.
Будущие исследования должны сосредоточиться на адаптивности механизма к различным типам данных и задачам. Простое снижение вычислительной нагрузки без сохранения или улучшения точности — пустая трата усилий. Истинное совершенство достигается не когда нечего добавить, а когда нечего убрать, и этот процесс требует глубокого понимания внутренней структуры данных и самой сети.
Оригинал статьи: https://arxiv.org/pdf/2512.22206.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Эхо чёрных дыр: как квантовая гравитация меняет гравитационные волны
- Укрощение Бесконечности: Алгебраические Инструменты для Кватернионов и За их Пределами
- Трансформация нейросетей: от плотных моделей к разреженным экспертам без обучения
- Квантовая Физика и Безопасность: Анализ Последних Новостей
- Биосети в руках ИИ: Автоматизация системной фармакологии
- Сияние фотонов: новый уровень точности в предсказаниях столкновений частиц
- Неупорядоченные системы с неэрмитовыми эффектами
- Оптические Тензорные Ядра: Путь к Масштабируемым Вычислениям
- Квантовые сети связи: оптимизация расписания для спутниковой передачи
- Квантовый Беспорядок и Наша Готовность к Нему
2026-01-01 04:53