Автор: Денис Аветисян
Новый подход к сжатию видео использует предварительное обучение для точного восстановления кадров и повышения стабильности при генерации видеопотока.
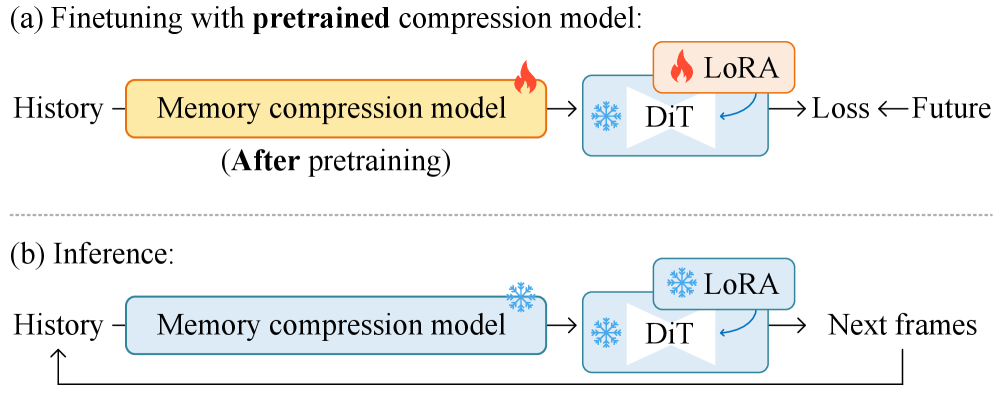
Предлагается фреймворк предварительного обучения для моделей сжатия видео, ориентированный на высококачественное извлечение кадров и снижение вычислительных затрат при авторегрессивной генерации.
Сохранение детализации при сжатии видеоданных остается сложной задачей, особенно при работе с длинными последовательностями. В данной работе, посвященной ‘Pretraining Frame Preservation in Autoregressive Video Memory Compression’, предлагается новый подход к сжатию видео, основанный на предварительном обучении нейронной сети с акцентом на сохранение высокочастотных деталей отдельных кадров. Это позволяет эффективно сжимать длинные видео в короткие контексты, обеспечивая при этом возможность восстановления кадров с минимальными потерями качества и снижая вычислительные затраты при авторегрессивном моделировании видео. Какие архитектурные решения и стратегии обучения могут еще больше повысить эффективность и масштабируемость данного подхода для задач генерации и анализа видео?
Вызов Контекста в Генерации Видео
Авторегрессивная генерация видео демонстрирует значительный потенциал в создании динамических изображений, однако сталкивается с серьезной проблемой поддержания согласованности на протяжении всей длительности ролика. Суть заключается в том, что каждый новый кадр генерируется на основе предыдущих, что требует от модели учета всей предшествующей информации. Неспособность эффективно обрабатывать и сохранять эту “память” о прошлых кадрах приводит к визуальным несостыковкам, нереалистичным переходам и общей фрагментированности генерируемого видеоряда. По сути, модель часто “забывает” о деталях, заданных в начале, и не может последовательно развивать визуальную историю, что существенно ограничивает её применение для создания длинных и сложных видео.
Для создания связного и реалистичного видео необходимо учитывать обширный объем предшествующих данных — так называемый контекст. Однако, эта задача сопряжена со значительными вычислительными трудностями. По мере увеличения длины рассматриваемого контекста, требуются экспоненциально возрастающие ресурсы памяти и вычислительной мощности. Это связано с тем, что модели, обрабатывающие видео, должны одновременно анализировать и сопоставлять информацию из все более отдаленных моментов времени, чтобы обеспечить согласованность и логичность происходящего на экране. Сложность заключается в эффективном управлении этими огромными объемами данных и поддержании качества генерируемого видео при увеличении длительности рассматриваемого временного интервала.
При увеличении длины контекста, необходимого для генерации связного видео, часто наблюдается снижение качества проработки деталей, что препятствует созданию реалистичного изображения. Данное явление обусловлено сложностью сохранения информации на протяжении длительных последовательностей. Представленная разработка направлена на решение этой проблемы путем балансировки между длиной контекста и качеством сохраняемых деталей. Подход позволяет достичь оптимального сочетания, обеспечивая создание длинных видеофрагментов с сохранением высокой степени реалистичности и связности повествования, что особенно важно для практических применений в области создания контента и визуальных эффектов.

Кодирование Памяти: Сжатие Прошлого
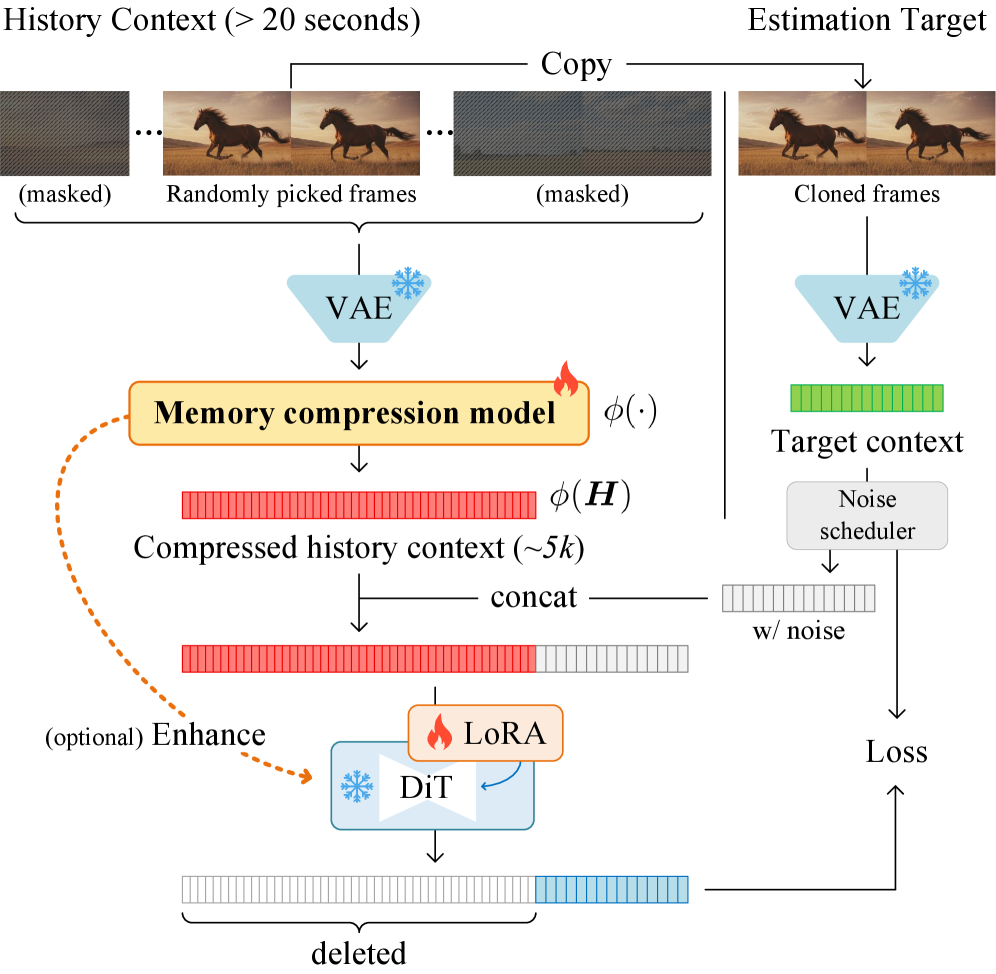
Компонент «Кодировщик памяти» выполняет функцию критически важного звена, преобразуя последовательность видеокадров в компактное, но информативное представление. Этот процесс включает в себя сжатие данных, позволяющее эффективно хранить и обрабатывать информацию о прошлом видео. Полученное представление служит основой для последующего использования в задачах генерации и анализа видео, обеспечивая сохранение ключевых визуальных признаков при значительном уменьшении объема данных. Эффективность кодирования напрямую влияет на производительность системы и качество генерируемых результатов.
Кодирование видеоданных в системе осуществляется с использованием эффективных методов сжатия, направленных на минимизацию объема хранимой информации. В частности, применяется вариационный автоэнкодер (VAE) для обучения компактному представлению видеокадров. Для дальнейшего снижения объема данных используется разреженность (Sparsity), когда отбрасываются незначимые элементы представления. Кроме того, применяется метод объединения токенов (Token Merging), который группирует схожие элементы в единые символы, что позволяет уменьшить размер закодированного видеопотока и повысить эффективность хранения и обработки данных.
Предварительное обучение (pretraining) модуля кодирования памяти осуществляется на обширных наборах данных для повышения его способности извлекать релевантные признаки из видеопоследовательностей. В рамках нашей архитектуры особое внимание уделяется достижению высокой точности извлечения ключевых кадров на этапе предварительного обучения, что позволяет эффективно моделировать долгосрочные зависимости во временных рядах. Последующая тонкая настройка (fine-tuning) оптимизирует работу модуля для конкретных задач генерации, адаптируя извлеченные признаки к специфическим требованиям целевого приложения и повышая качество генерируемых видеоматериалов.
Эффективные Механизмы Внимания для Использования Контекста
Помимо стандартных методов сжатия, совершенствование механизмов внимания значительно повышает эффективность обработки контекста. Архитектуры ‘FlashAttention’ и ‘Linear Attention’ обеспечивают существенный прирост пропускной способности за счет оптимизации вычислений внимания. ‘FlashAttention’ использует тайловый подход и переупорядочивание вычислений для снижения требований к памяти и ускорения обработки, в то время как ‘Linear Attention’ упрощает вычисления внимания, снижая сложность с O(N^2) до O(N), где N — длина последовательности. Это позволяет обрабатывать более длинные последовательности и повышает общую скорость работы модели.
Механизм перекрестного внимания (Cross-Attention) обеспечивает эффективный обмен информацией между закодированной историей (последовательностью предыдущих кадров) и текущим генерируемым кадром. Этот процесс позволяет модели учитывать релевантные аспекты из прошлого, улучшая согласованность и качество генерируемого контента. В отличие от самовнимания, которое оперирует внутри одной последовательности, перекрестное внимание устанавливает связи между двумя различными последовательностями данных, что критически важно для задач, требующих учета контекста из прошлого для формирования текущего выхода.
Подход с использованием «скользящего окна» изменяет способ использования длины контекста, обеспечивая баланс между вычислительными затратами и доступом к релевантным данным из прошлого. Вместо обработки всей истории, алгоритм рассматривает только фиксированный фрагмент, перемещающийся во времени. Как показано на рис. 5, данный метод демонстрирует улучшения в показателях PSNR и SSIM по сравнению с базовыми архитектурами, что свидетельствует о повышении качества генерируемого контента при сохранении приемлемой вычислительной сложности. Эффективность подхода обусловлена снижением требований к памяти и ускорением вычислений, связанных с механизмом внимания.

Архитектуры для Генерации Длинных Видео
Архитектуры, такие как ‘WAN’ и ‘HunyuanVideo’, активно используют принципы авторегрессионной генерации видео, что позволяет значительно повысить согласованность изображения на протяжении всей длительности ролика. В отличие от традиционных подходов, где каждый кадр генерируется независимо, данные модели предсказывают последующие кадры, опираясь на предыдущие, формируя тем самым непрерывную и логичную визуальную последовательность. Этот подход позволяет избежать распространенных артефактов и несоответствий, часто встречающихся в сгенерированных видео, и обеспечивает более реалистичное и правдоподобное отображение динамических сцен. Результатом является видеоматериал, в котором объекты и окружение сохраняют свою идентичность и взаимосвязь на протяжении всего времени, обеспечивая целостность повествования и общее качество изображения.
Для достижения большей реалистичности и связности генерируемого видео, современные архитектуры используют комплексный подход к анализу движения и визуальной согласованности. Модель RAFT, специализирующаяся на оценке оптического потока, позволяет точно отслеживать перемещение объектов в кадре, обеспечивая плавность и естественность движений. Параллельно, ViCLIP, опираясь на сопоставление изображения и текста, гарантирует, что визуальный контент соответствует заданным параметрам и сохраняет целостность на протяжении всего видео. Комбинация этих технологий позволяет создавать видеоматериалы, в которых движения выглядят убедительно, а визуальные элементы — последовательно и логично, значительно повышая общее качество и восприятие сгенерированного контента.
В современных архитектурах генерации длинных видео особое внимание уделяется предварительному планированию. Использование так называемых “раскадровок” (Storyboards) направляет процесс генерации, обеспечивая структурированность повествования и визуальную связность. Исследования показывают, что предложенная схема демонстрирует логичные показатели по метрикам согласованности, касающимся детализации одежды и объектов, превосходя базовую комбинацию Wan+Qwen. Подтверждение эффективности получено также в ходе оценки пользователями, где предложенный подход показал более высокие результаты по шкале ELO, что свидетельствует о заметном улучшении воспринимаемого качества и когерентности генерируемых видео.

Исследование демонстрирует стремление к математической чистоте в области сжатия видео, что находит отражение в предложенном фреймворке предварительного обучения. Авторы, стремясь к улучшению долгосрочной согласованности и снижению вычислительных затрат, фактически ищут доказательство корректности алгоритма, а не просто его работоспособность на тестовых данных. Как заметил Дэвид Марр: «Вычислительная теория разума требует, чтобы мы объяснили когнитивные способности в терминах вычислительных процессов». Этот подход перекликается с принципом поиска оптимального баланса между длиной контекста и качеством сжатия, стремясь к элегантному и доказуемо эффективному решению в области авторегрессивной генерации видео.
Куда Ведет Этот Путь?
Представленный подход к сохранению кадров в процессе предварительного обучения, несомненно, демонстрирует элегантность в стремлении к последовательности во времени. Однако, истинное испытание для любой модели — не способность воспроизвести тестовый набор данных, а предсказать неизвестное. Очевидным ограничением остается зависимость от объема контекста; сжатие информации неизбежно ведет к потере деталей, а любое приближение — к погрешности. Вопрос в том, насколько допустима эта погрешность, и где пролегает граница между эффективностью и искажением.
Дальнейшие исследования, вероятно, будут сосредоточены на поиске баланса между длиной контекста и качеством реконструкции. Интересным направлением представляется интеграция принципов диффузионных моделей не только для генерации, но и для более эффективного сжатия информации о контексте. Необходимо также учитывать вычислительные издержки, связанные с поиском релевантных кадров; оптимизация этого процесса — задача нетривиальная, но необходимая для практического применения.
В конечном итоге, ценность данной работы определяется не только достигнутыми результатами, но и открытием новых вопросов. До тех пор, пока алгоритм не будет доказуемо корректен, а не просто «работать на тестах», поиск совершенной модели видеокомпрессии останется увлекательной, но бесконечной задачей.
Оригинал статьи: https://arxiv.org/pdf/2512.23851.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Биосети в руках ИИ: Автоматизация системной фармакологии
- Квантовая Физика и Безопасность: Анализ Последних Новостей
- Трансформация нейросетей: от плотных моделей к разреженным экспертам без обучения
- Эхо чёрных дыр: как квантовая гравитация меняет гравитационные волны
- Сияние фотонов: новый уровень точности в предсказаниях столкновений частиц
- Оптические Тензорные Ядра: Путь к Масштабируемым Вычислениям
- Укрощение Бесконечности: Алгебраические Инструменты для Кватернионов и За их Пределами
- Луна раскрывает свои секреты: Искусственный интеллект восстанавливает древнюю формулу
- Разреженность как ключ к скорости: Новая архитектура для мультимодальных моделей
- Квантовый горизонт: взгляд изнутри
2026-01-01 08:21