Автор: Денис Аветисян
Новое исследование предлагает метод автоматического выявления и управления процессами рассуждений в больших языковых моделях.
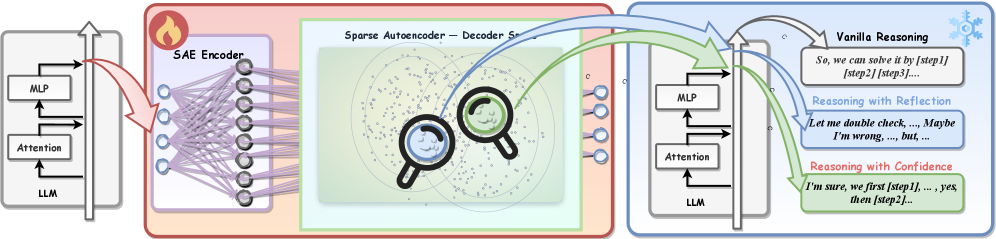
Представлен фреймворк RISE, использующий разреженные автокодировщики для обнаружения и манипулирования логическими цепочками в нейронных сетях без использования размеченных данных.
Несмотря на впечатляющие возможности современных больших языковых моделей (LLM) в решении задач рассуждения, механизмы, лежащие в основе этого процесса, остаются малоизученными. В работе ‘Fantastic Reasoning Behaviors and Where to Find Them: Unsupervised Discovery of the Reasoning Process’ предложен фреймворк RISE, использующий разреженные автокодировщики для обнаружения и управления векторами рассуждений, определяющими различные когнитивные стратегии. Это позволяет выявлять и контролировать такие аспекты рассуждений, как рефлексия и уверенность, без необходимости в ручной разметке данных. Способны ли мы, используя подобные подходы, не только интерпретировать, но и целенаправленно формировать процесс рассуждений в LLM, открывая новые горизонты для искусственного интеллекта?
Раскрытие Черного Ящика: Рассуждения в Больших Языковых Моделях
Современные большие языковые модели демонстрируют впечатляющие возможности в обработке и генерации текста, превосходя ожидания в решении сложных задач, таких как перевод, написание кода и ответы на вопросы. Однако, несмотря на внешнюю эффективность, механизмы, лежащие в основе этих способностей, остаются в значительной степени непрозрачными. Процесс принятия решений внутри этих моделей представляет собой своего рода “черный ящик”, где внутренние представления и логические шаги, приводящие к определенному ответу, трудно отследить и понять. Эта непрозрачность вызывает серьезные вопросы относительно надежности и предсказуемости поведения моделей, а также затрудняет выявление и исправление потенциальных ошибок или предвзятостей, скрытых внутри их сложной архитектуры.
Понимание механизмов, посредством которых большие языковые модели (БЯМ) приходят к определенным выводам, является ключевым фактором для повышения их надежности и вызываемого доверия. Неспособность проследить логическую цепочку рассуждений БЯМ может привести к необоснованным или ошибочным ответам, особенно в критически важных областях, таких как медицина или финансы. Исследование внутренних процессов принятия решений позволяет выявить потенциальные предвзятости, слабые места и нелогичности в работе моделей. В конечном итоге, прозрачность в отношении того, как БЯМ обосновывают свои ответы, необходима для обеспечения ответственного использования этих мощных инструментов и предотвращения нежелательных последствий, а также для построения более эффективных и безопасных систем искусственного интеллекта.
Существующие подходы к анализу больших языковых моделей (БЯМ) часто рассматривают их как единые, непрозрачные блоки, не позволяя выявить тонкие механизмы, лежащие в основе процесса мышления. Вместо детального изучения внутренних представлений и взаимодействий между различными компонентами модели, большинство исследований фокусируются на анализе входных данных и выходных результатов. Такой подход ограничивает возможность понимания того, как БЯМ приходят к определенным выводам, и не позволяет определить, какие конкретно факторы влияют на их рассуждения. Неспособность “разобрать” БЯМ на отдельные, анализируемые компоненты затрудняет выявление потенциальных ошибок, предвзятостей и уязвимостей, что является критически важным для повышения надежности и доверия к этим системам. Вместо этого необходимы методы, позволяющие исследовать внутренние состояния модели, отслеживать активации нейронов и выявлять закономерности в ее “мыслительном” процессе.
RISE: Раскрытие Скрытых Паттернов Рассуждений
Фреймворк RISE представляет собой неконтролируемый подход к выявлению детализированных моделей рассуждений внутри больших языковых моделей (LLM). В отличие от методов, требующих ручной разметки данных или предварительного определения типов рассуждений, RISE автоматически анализирует внутренние активации модели для обнаружения латентных векторов, соответствующих атомарным поведенческим компонентам. Это достигается путем использования разреженных автоэнкодеров (SAE), которые позволяют создать разделенное представление активаций, что, в свою очередь, облегчает идентификацию и визуализацию различных стратегий рассуждения, проявляющихся в процессе обработки информации моделью. Основная цель RISE — обеспечить возможность изучения и интерпретации внутренних механизмов LLM без предварительных знаний о конкретных поведенческих особенностях.
В рамках фреймворка RISE для анализа поведения больших языковых моделей (LLM) используются разреженные автоэнкодеры (SAE). SAE применяются к внутренним активациям модели с целью создания разделенного представления, в котором различные аспекты рассуждений представлены отдельными векторами. Разреженность автоэнкодера способствует выделению наиболее значимых признаков, а разделенное представление позволяет идентифицировать и изолировать скрытые векторы, соответствующие конкретным элементарным процессам рассуждения. Эти векторы, называемые векторами рассуждений, представляют собой направления в пространстве активаций, кодирующие отдельные аспекты логического вывода, анализа и синтеза информации.
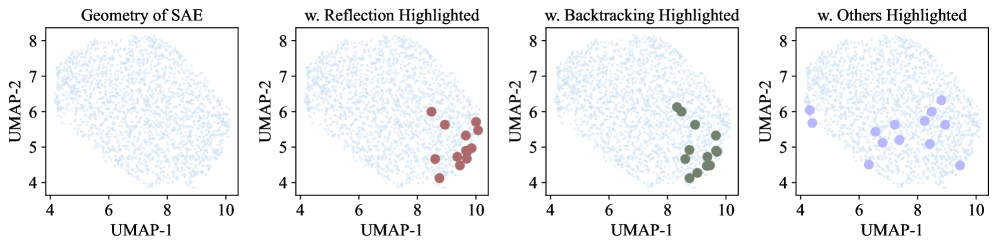
В основе фреймворка RISE лежит Линейная Гипотеза Представления (Linear Representation Hypothesis), предполагающая, что элементарные, атомарные паттерны рассуждений могут быть представлены как отдельные направления в пространстве внутренних активаций большой языковой модели (LLM). Это означает, что каждое конкретное рассуждение, например, определение логического следования или выявление противоречий, соответствует определенному вектору в многомерном пространстве активаций. По существу, активации, соответствующие определенному типу рассуждений, будут сколларированы вдоль определенной оси, что позволяет идентифицировать и изолировать эти паттерны, используя методы анализа, такие как UMAP и измерение энтропии. Эта гипотеза позволяет интерпретировать внутреннее представление модели как комбинацию базовых векторов, представляющих различные типы рассуждений.
Для визуализации и количественной оценки выявленных векторов рассуждений используется анализ с применением UMAP и энтропии. UMAP позволяет снизить размерность пространства активаций для последующей визуализации, а энтропия служит метрикой неопределенности модели при принятии решений. Количественная оценка разделения этих поведенческих концепций проводится с использованием метрики силуэта (Silhouette score), которая показала улучшение разделения в более глубоких слоях модели, что указывает на более четкое представление атомарных рассуждений на этих уровнях. Повышение значений силуэта коррелирует с большей уверенностью модели в своих выводах и лучшей дискриминацией между различными стратегиями рассуждения.
Управление Рассуждениями через Активационную Инженерию
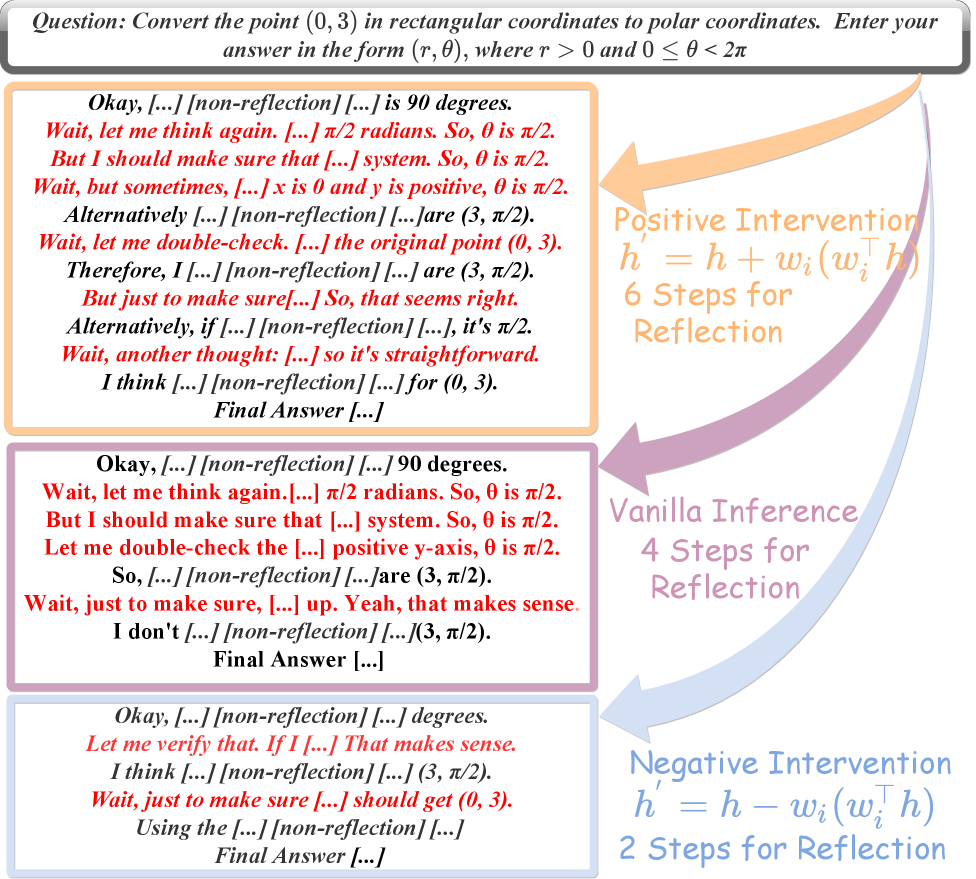
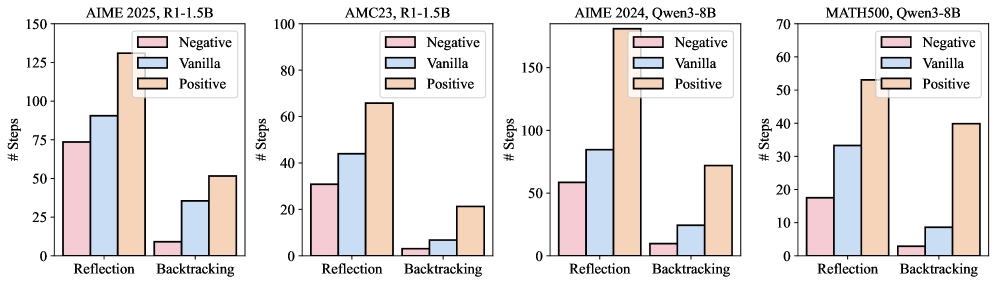
Эксперименты показали возможность целенаправленного изменения конкретных паттернов рассуждений модели посредством активационной инженерии. Этот подход предполагает манипулирование векторами активаций внутри нейронной сети для воздействия на процесс принятия решений. В частности, было продемонстрировано, что интервенции с векторами уверенности, направленные на снижение выраженности определенных стратегий, таких как рефлексия и отслеживание (backtracking), приводят к значительному уменьшению соответствующих шагов рассуждений. Например, вмешательство в процессы рефлексии при решении задач AIME25 позволило сократить количество шагов рефлексии с 90.53 до 33.77, а шагов отслеживания — с 35.50 до 5.93. Это подтверждает, что активационная инженерия является эффективным инструментом для управления и оптимизации поведения моделей в задачах, требующих сложных рассуждений.
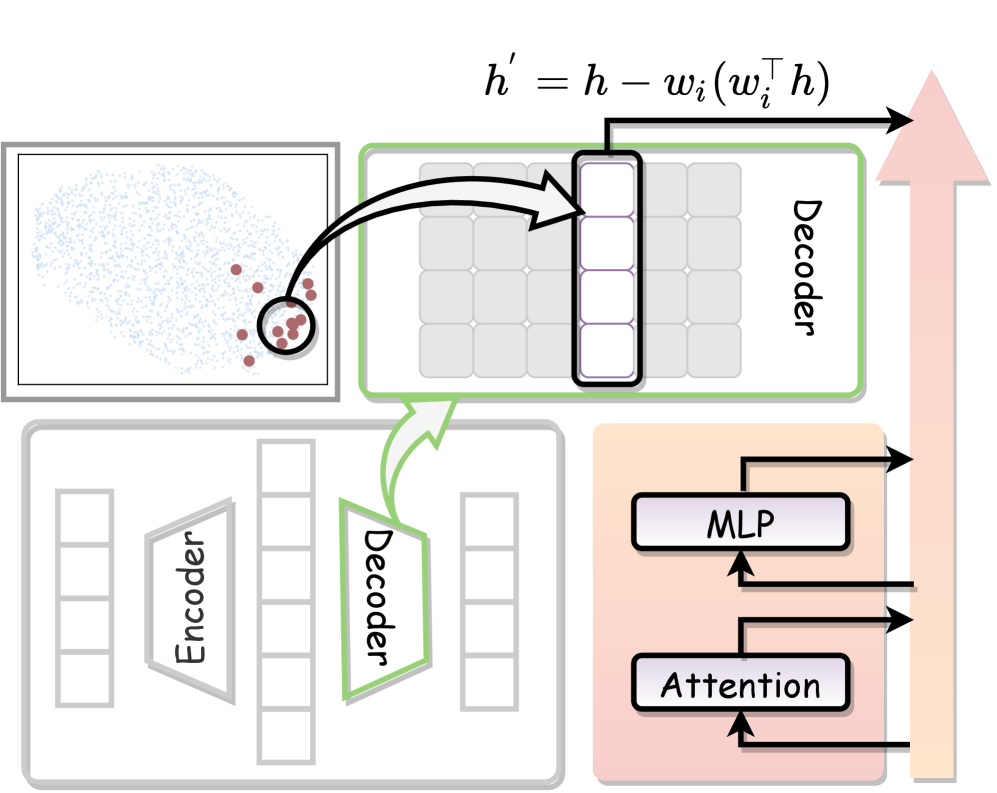
Для целенаправленного управления ответами модели используется метод построения контрастных наборов данных на основе разности средних значений (Difference-of-Means). Этот подход заключается в вычислении разницы между векторами активаций для пар примеров, демонстрирующих желаемое и нежелаемое поведение. Полученная разностная величина затем используется для создания набора данных, который позволяет модели обучиться различать и воспроизводить конкретные шаблоны ответов. Эффективность метода заключается в возможности точечного воздействия на поведение модели, основываясь на количественных различиях в ее внутренних представлениях, а не на ручной настройке или сложных правилах.
Анализ векторов активаций выявил соответствие между определенными векторами и узнаваемыми паттернами рассуждений, такими как Рефлексия и Бэктрекинг. В частности, обнаружено, что отдельные векторы активаций коррелируют с процессами самоанализа и пересмотра решения, характерными для Рефлексии, а другие — с последовательными попытками и отступами, определяющими Бэктрекинг. Это позволяет предположить, что внутреннее представление модели отражает не только факты, но и стратегии решения задач, и что эти стратегии могут быть идентифицированы и манипулируемы через анализ векторов активаций.
Исследования показали, что длина ответа модели напрямую связана с определенными паттернами рассуждений. Вмешательство в векторы уверенности (confidence vectors) при решении задач AIME25 привело к значительному снижению количества шагов, связанных с рефлексией (от 90.53 до 33.77) и возвратом (backtracking) (от 35.50 до 5.93). Это демонстрирует, что изменение структурных свойств ответа, таких как его длина, позволяет целенаправленно управлять стратегиями рассуждений, используемыми моделью.
От Обнаружения к Контролю: Влияние и Перспективы Развития
Механизм RISE представляет собой ценный инструмент для аудита и отладки процессов рассуждений, реализуемых большими языковыми моделями (LLM). Данный фреймворк позволяет детально проанализировать, какие именно элементы входных данных оказывают наибольшее влияние на принимаемые моделью решения, выявляя потенциальные ошибки или предвзятости в логике рассуждений. В отличие от традиционных «черных ящиков», RISE обеспечивает прозрачность, позволяя исследователям и разработчикам понимать, как модель приходит к своим выводам, и, соответственно, улучшать её надежность и точность. Визуализация вклада различных элементов входных данных помогает идентифицировать критически важные факторы, влияющие на результат, и выявлять случаи, когда модель полагается на нерелевантную информацию или демонстрирует нелогичное поведение. Таким образом, RISE способствует построению более надежных и понятных систем искусственного интеллекта.
Понимание фундаментальных механизмов, лежащих в основе работы больших языковых моделей, является ключевым фактором для создания действительно надежных и заслуживающих доверия систем искусственного интеллекта. Глубокий анализ процессов рассуждения позволяет выявлять уязвимости и неточности, которые могут привести к ошибочным результатам. В результате, становится возможным целенаправленное улучшение архитектуры и алгоритмов, повышение устойчивости к манипуляциям и обеспечение предсказуемости поведения. Такой подход, ориентированный на внутреннюю логику работы моделей, позволяет не просто исправлять ошибки, но и создавать системы, способные к самодиагностике и адаптации, что особенно важно для применения в критически важных областях, таких как медицина, финансы и безопасность.
Исследование, проведенное с использованием модели DeepSeek-R1-1.5B и набора данных MATH, демонстрирует значительный потенциал целенаправленного контроля над процессом рассуждений больших языковых моделей. В ходе работы была разработана стратегия «управления», позволяющая повысить точность решения математических задач на 4.66 пункта, при этом сократив количество используемых токенов на 13.69%. Полученные результаты свидетельствуют о возможности оптимизации работы ИИ, не только улучшая качество ответов, но и снижая вычислительные затраты, что открывает перспективы для создания более эффективных и доступных интеллектуальных систем.
Высокая согласованность аннотаций, превышающая 85% при оценке разными языковыми моделями и с использованием сопоставления ключевых слов, подтверждает надежность и валидность предложенной методологии. Такой уровень согласия демонстрирует, что используемые критерии оценки и интерпретации рассуждений моделей являются объективными и воспроизводимыми, что критически важно для обеспечения достоверности результатов и дальнейшего развития направлений контролируемого управления рассуждениями искусственного интеллекта. Полученные данные позволяют с уверенностью утверждать, что предложенный подход к анализу и отладке процессов рассуждений больших языковых моделей является эффективным и может быть использован для повышения их надежности и точности.
Исследование, представленное в данной работе, демонстрирует, что сложные системы искусственного интеллекта, подобные большим языковым моделям, проявляют неожиданные формы рассуждений. Авторы предлагают метод RISE, позволяющий выявить эти скрытые паттерны без необходимости ручной разметки данных. Это напоминает о том, как архитектурные решения неизбежно формируют будущее системы, определяя ее сильные и слабые стороны. Как однажды заметил Г.Х. Харди: «Математика — это не просто игра с цифрами, а искусство логического мышления». Аналогично, в контексте ИИ, RISE позволяет взглянуть на внутреннюю «логику» модели, раскрывая ее способность к рефлексии и уверенности, и подчеркивая, что масштабируемость — это лишь оправдание усложнения системы.
Куда же это всё ведёт?
Представленная работа, по сути, лишь зафиксировала закономерность: системы сложны не потому, что мы плохо их строим, а потому что хаос всегда найдёт способ проявиться. RISE не «открывает» разум модели, а скорее создаёт карту трещин, по которым течет её внутреннее состояние. Этот подход, безусловно, позволяет манипулировать проявлениями «рассуждений», но вопрос о том, что именно контролируется, остаётся открытым. Ведь архитектура — это лишь способ откладывать хаос, а не побеждать его.
Очевидным направлением дальнейших исследований является расширение сферы применения подобных методов. Не стоит ограничиваться лишь «рассуждениями» — любые сложные проявления поведения модели, от генерации изображений до управления роботами, представляют собой сложные экосистемы внутренних состояний. Однако, стоит помнить: нет лучших практик, есть лишь выжившие. Каждый архитектурный выбор — это пророчество о будущем сбое, и RISE лишь даёт возможность увидеть этот сбой раньше.
В конечном счёте, задача не в том, чтобы построить идеально «рассуждающую» систему, а в том, чтобы научиться сосуществовать с её непредсказуемостью. Порядок — это кеш между двумя сбоями. И понимание того, как эти сбои проявляются и как ими можно управлять — вот истинная ценность подобных исследований.
Оригинал статьи: https://arxiv.org/pdf/2512.23988.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Трансформация нейросетей: от плотных моделей к разреженным экспертам без обучения
- Квантовая Физика и Безопасность: Анализ Последних Новостей
- Сияние фотонов: новый уровень точности в предсказаниях столкновений частиц
- Эхо чёрных дыр: как квантовая гравитация меняет гравитационные волны
- Биосети в руках ИИ: Автоматизация системной фармакологии
- Оптические Тензорные Ядра: Путь к Масштабируемым Вычислениям
- Марс и магнитное поле: новый взгляд с помощью нейросетей
- Нейронные сети: Архитектура как ключ к масштабируемости
- Квантовые смеси: от капель жидкости до сверхтекучих кристаллов
- Искусственный интеллект и рефакторинг кода: что пока умеют AI-агенты?
2026-01-01 10:06