Автор: Денис Аветисян
Новый подход к моделям, объединяющим видео и текст, позволяет точнее понимать временные связи в видео и генерировать более релевантные ответы.
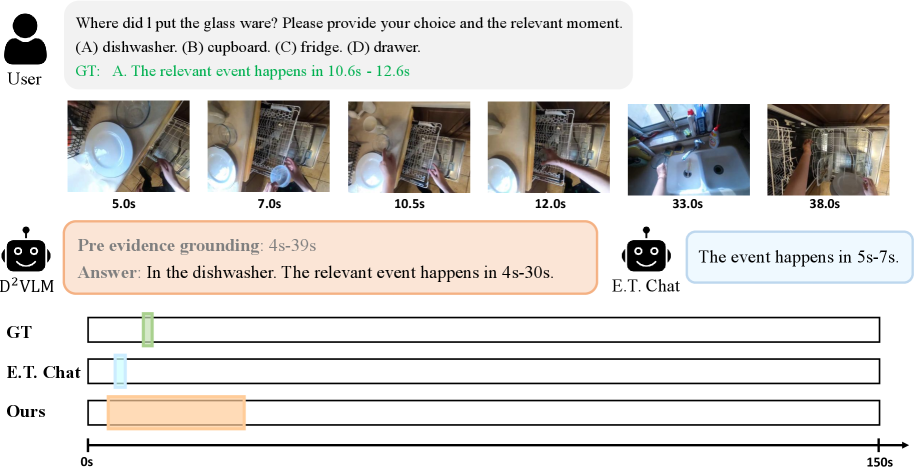
В статье представлена модель D2VLM, использующая факторное обучение для разделения временной привязки событий от генерации текстовых ответов, что повышает производительность и точность.
Несмотря на значительный прогресс в области видео-языковых моделей, точное временное привязывание событий по-прежнему представляет собой сложную задачу. В работе ‘Factorized Learning for Temporally Grounded Video-Language Models’ предложен новый подход, основанный на разделении задач временного определения и генерации текстового ответа, что позволяет улучшить понимание видеоконтента. Авторы представляют D²VLM — фреймворк, использующий «определение, а затем ответ со ссылкой на доказательства», а также алгоритм факторной оптимизации предпочтений, учитывающий вероятностное моделирование временных рамок. Сможет ли такой факторный подход стать основой для создания более надежных и точных видео-языковых моделей будущего?
Временная Привязка: Главная Преграда для Понимания Видео
Несмотря на значительные успехи в области обработки видео, традиционные видео-языковые модели (Video LLM) часто испытывают трудности с точным определением временной последовательности событий. Эта проблема, известная как «временная привязка» (temporal grounding), существенно ограничивает возможности более глубокого анализа и логических выводов. Модели, не способные корректно установить, когда именно происходит то или иное действие, склонны к ошибкам при ответе на вопросы, требующие понимания временных взаимосвязей, и не могут полноценно интерпретировать сложные видеосюжеты. В результате, даже при наличии обширных знаний о визуальном контенте, модели оказываются неспособными к построению целостной картины происходящего и выдают неточные или неполные результаты, что снижает их эффективность в задачах, требующих контекстуального понимания видеоинформации.
Попытки одновременного обучения моделей видеопонимания определению временных границ событий и генерации текстовых ответов, известные как “связанная цель обучения”, зачастую приводят к неоптимальным результатам. Сложность заключается в тесной взаимосвязи этих двух задач: ошибки в определении момента наступления события немедленно влияют на качество генерируемого текста, и наоборот. Такой подход создает переплетенные сложности, затрудняя модели эффективное разделение и освоение каждой задачи по отдельности. В результате, модель может испытывать трудности с точным определением времени события и предоставлением соответствующего, последовательного текстового описания, что снижает общую эффективность системы видеопонимания.

D2VLM: Разделение Задач для Улучшения Видео-Рассуждений
В рамках D2VLM предложена архитектура, явно разделяющая этапы временной привязки событий (temporal event grounding) и генерации текстового ответа. Традиционные подходы, объединяющие эти процессы в единую модель, часто демонстрируют ограниченную эффективность, поскольку ошибки на этапе привязки событий напрямую влияют на качество генерируемого текста. Разделение позволяет модели независимо обрабатывать визуальную информацию и определять временные рамки событий, а затем использовать эту информацию для формирования более точного и релевантного текстового ответа. Это разделение способствует повышению надежности и интерпретируемости модели, а также упрощает процесс обучения и отладки.
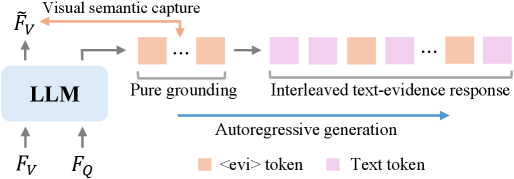
Ключевым элементом предложенной архитектуры D2VLM является “Evidence Token” — механизм, предназначенный для захвата семантики событий на уровне отдельных кадров видео. Этот токен представляет собой векторное представление, кодирующее визуальную информацию, относящуюся к конкретному событию, и служит для предоставления модели сфокусированного контекста. В отличие от подходов, оперирующих с глобальными видео-признаками, Evidence Token позволяет модели концентрироваться на релевантных визуальных деталях, необходимых для ответа на конкретный вопрос о видео. Это достигается путем выделения признаков из ключевых кадров и их последующей агрегации в векторное представление, которое затем используется в процессе генерации текстового ответа.
Процесс генерации в D2VLM основан на итеративном, взаимосвязанном создании текстового ответа и временной привязки событий. Модель последовательно уточняет как понимание визуальных событий во времени (временная привязка), так и генерируемый текст. На каждой итерации, анализ визуальных данных и текущий текстовый фрагмент используются для улучшения друг друга. Это позволяет модели динамически фокусироваться на наиболее релевантных визуальных признаках, необходимых для точного ответа на вопрос, и одновременно формировать связный и логичный текстовый ответ, учитывающий временной контекст происходящего на видео.
Обеспечение Согласованности и Эффективности в D2VLM
В архитектуре D2VLM реализовано ограничение согласованности (Consistency Constraint), которое обеспечивает когерентность генерируемых токенов-доказательств на протяжении всего процесса генерации. Данное ограничение функционирует путем непрерывной проверки соответствия между текущим генерируемым токеном и ранее сгенерированными, что позволяет предотвратить отклонения от исходного контекста и поддерживать логическую связность доказательств. Это достигается за счет интеграции механизма, который оценивает вероятность соответствия каждого нового токена с существующей последовательностью, и корректирует процесс генерации в случае обнаружения несоответствий. Такой подход способствует повышению достоверности и релевантности генерируемых доказательств, что критически важно для задач, требующих высокой точности и надежности.
Для снижения вычислительных затрат в D2VLM используется ряд эффективных технологий. В частности, применяется метод LoRA (Low-Rank Adaptation), позволяющий оптимизировать большие модели с меньшими затратами ресурсов. В качестве видеокодировщика используется ViT-G/14, а декодером выступает Phi-3-Mini-3.8B. Выбор данных архитектур и техник оптимизации позволяет добиться высокой производительности при сохранении качества генерации и снижении требований к вычислительной мощности.
В архитектуре D2VLM процесс сопоставления видео и текста (grounding) отделен от генерации текстового ответа. Данный подход позволяет добиться повышения точности временного сопоставления (Temporal Grounding), измеренного на базе данных E.T. Bench. В ходе тестирования D2VLM продемонстрировал среднее увеличение показателя F1 на 7.0% по сравнению с существующими передовыми методами в задачах Temporal Grounding, что свидетельствует о более эффективном определении соответствия между визуальными событиями и генерируемым текстом.

Согласование с Предпочтениями для Улучшения Взаимодействия с Видео
В основе данной системы лежит концепция обучения с учетом предпочтений, достигаемая благодаря явному моделированию вероятностной временной привязки. Это позволяет модели не просто отвечать на вопросы о видео, но и генерировать ответы, максимально соответствующие заданным критериям и ожиданиям пользователя. Вместо абстрактного понимания содержания, система учитывает когда и как определенные события происходят во времени, что критически важно для точного и релевантного ответа. Такой подход позволяет моделировать не только семантическое содержание видео, но и динамику происходящих действий, обеспечивая более естественное и осмысленное взаимодействие с пользователем. В результате, генерируемые ответы оказываются более точными, контекстуально уместными и лучше соответствуют индивидуальным предпочтениям, что значительно улучшает пользовательский опыт в задачах, таких как ответы на вопросы о видео и генерация подробных описаний происходящего.
Для повышения эффективности обучения и создания более качественных наборов данных используется метод факторизованной оптимизации предпочтений. Суть подхода заключается в разделении сложной задачи оптимизации на несколько более простых, что позволяет более точно настроить модель под желаемые критерии. В процессе факторизованного синтеза данных генерируются разнообразные сценарии и ситуации, учитывающие различные предпочтения и факторы, влияющие на взаимодействие с видео. Это позволяет модели не только отвечать на вопросы, но и предвидеть потребности пользователя, делая взаимодействие более интуитивным и эффективным. В результате, модель получает возможность более гибко адаптироваться к различным запросам и контекстам, что приводит к улучшению качества ответов и повышению общей удовлетворенности пользователя.
Предложенный подход значительно повышает эффективность систем ответа на вопросы по видео и обогащает пользовательский опыт в приложениях, таких как плотное описание видеоконтента. Экспериментальные данные демонстрируют ощутимый прогресс: наблюдается увеличение показателя F1 на 4.0% и CIDEr на 2.5% при работе с набором данных YouCook2. Кроме того, точность R@1 (при IoU=0.5) улучшилась на 4.4% при использовании набора данных Charades-STA. Эти результаты свидетельствуют о том, что модель способна более точно интерпретировать видеоконтент и предоставлять более релевантные и содержательные ответы, что открывает новые возможности для интерактивных видеоприложений.
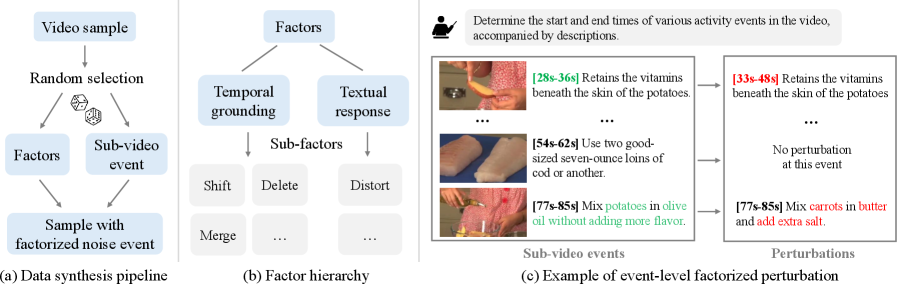
Исследование демонстрирует, как D2VLM разделяет временную привязку событий от генерации текстового ответа, что, в сущности, является очередным способом усложнить то, что когда-то было относительно простым. Разделение задач — вещь хорошая, конечно, пока не превращается в бесконечную цепочку микросервисов, каждый из которых требует отдельной команды поддержки. Как метко заметил Ян Лекун: «Машинное обучение — это просто переусложненная форма программирования». И в данном случае, это особенно заметно. Стремление к более точной временной привязке событий, достигаемое за счёт факторизованного обучения и использования «токенов доказательств», лишь подтверждает эту истину — элегантная теория разбивается о суровую реальность продакшена. Система стабильно падает, значит, хотя бы последовательна.
Куда же дальше?
Предложенный подход к факторизованному обучению, безусловно, представляет интерес, однако иллюзия полной декомпозиции задачи на «временную привязку» и «генерацию текста» — это лишь удобная абстракция. Продакшен всегда найдёт способ показать, что эти процессы неразрывно связаны, и что оптимизация одного компонента неизбежно приведёт к регрессии в другом. В конечном счёте, архитектура — это не схема, а компромисс, переживший деплой.
Наиболее вероятным направлением развития представляется не дальнейшее усложнение модели, а более глубокое понимание природы «доказательств», используемых для временной привязки. Что на самом деле представляет собой «релевантный фрагмент видео»? И как избежать ситуации, когда всё, что оптимизировано для «точности», рано или поздно оптимизируют обратно для «скорости»? Попытки создать универсальный набор «доказательств» обречены на провал; контекст всегда будет диктовать свои условия.
Вместо погони за идеальной декомпозицией, возможно, стоит сосредоточиться на создании моделей, способных к «мягкой» временной привязке — моделей, которые не требуют абсолютной точности в определении момента времени, а способны учитывать неопределенность и вероятностный характер визуальной информации. Это, конечно, потребует отказа от привычных метрик оценки, но в конечном итоге, мы не рефакторим код — мы реанимируем надежду.
Оригинал статьи: https://arxiv.org/pdf/2512.24097.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Биосети в руках ИИ: Автоматизация системной фармакологии
- Квантовая Физика и Безопасность: Анализ Последних Новостей
- Сияние фотонов: новый уровень точности в предсказаниях столкновений частиц
- Трансформация нейросетей: от плотных моделей к разреженным экспертам без обучения
- Эхо чёрных дыр: как квантовая гравитация меняет гравитационные волны
- Искусственный интеллект на страже кода: новая оценка качества
- Квантовый поиск гравитационных волн: новый алгоритм для повышения точности
- Оптические Тензорные Ядра: Путь к Масштабируемым Вычислениям
- Квантовый скачок в многомасштабном моделировании
- StreamingVLM: когда даже бесконечный видоряд не сломает RoPE.
2026-01-01 11:37