Автор: Денис Аветисян
Обзор современных методов мультимодального предварительного обучения, открывающих новые возможности для создания надежных автономных систем.
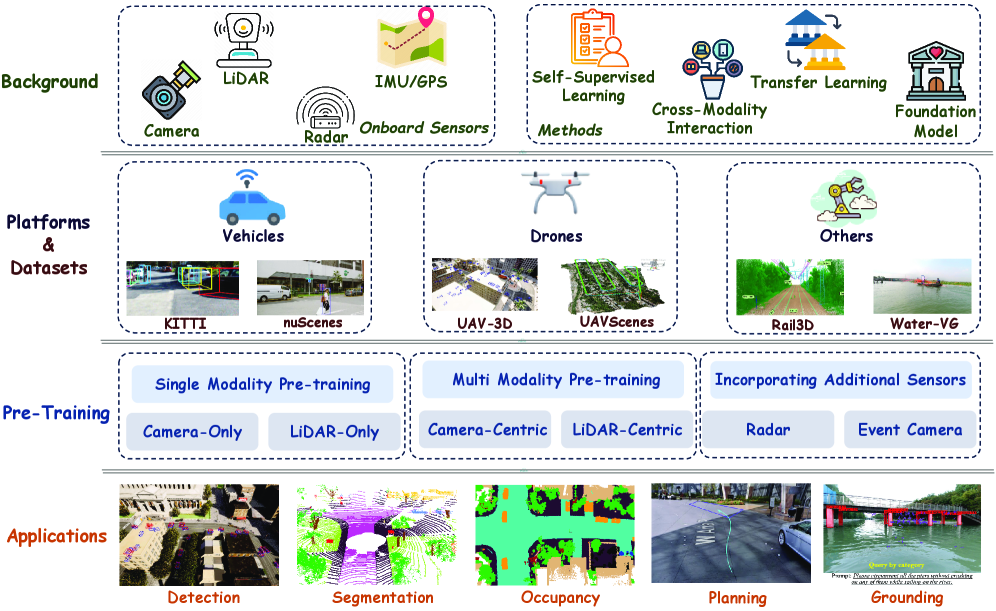
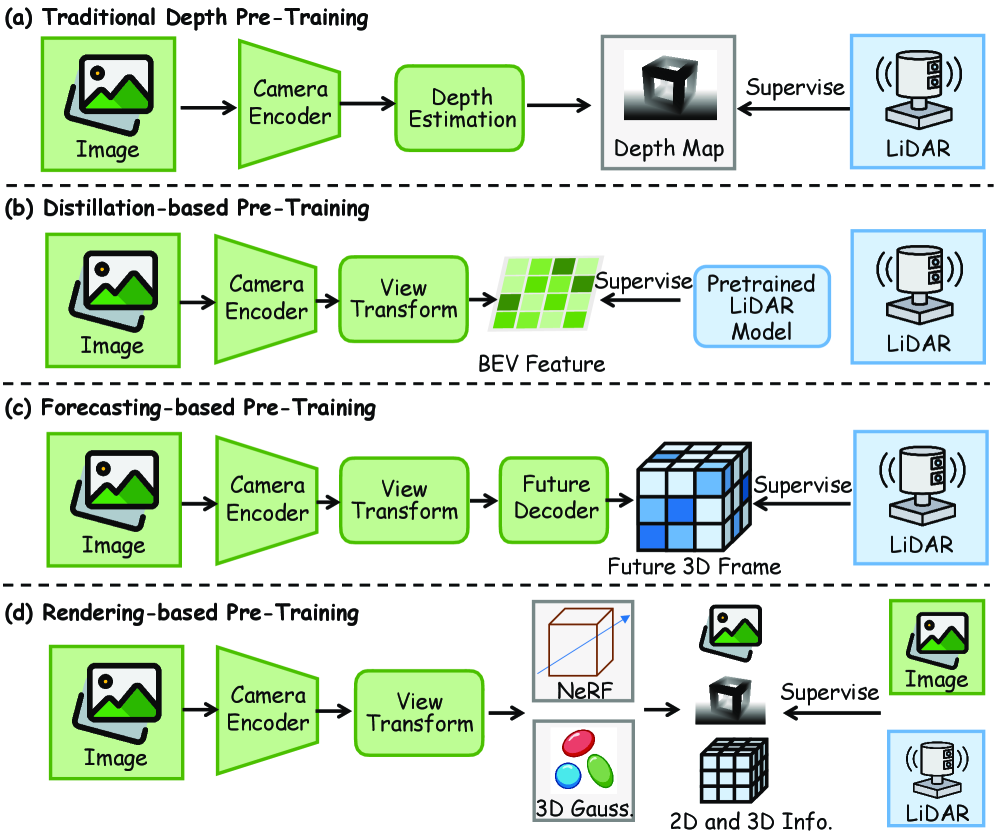
В статье рассматриваются методы мультимодального предварительного обучения для автономных систем, включая переход к фундаментальным моделям и генеративным моделям мира.
Несмотря на стремительное развитие автономных систем, создание истинного пространственного интеллекта на основе разнородных сенсорных данных остается сложной задачей. В работе ‘Forging Spatial Intelligence: A Roadmap of Multi-Modal Data Pre-Training for Autonomous Systems’ представлен всесторонний обзор современных подходов к мультимодальному предварительному обучению, определяющих прогресс в этой области. Ключевым выводом является формулировка единой таксономии парадигм предварительного обучения, от базовых одномодальных моделей до унифицированных фреймворков, способных к генерации целостных представлений для сложных задач, таких как 3D-обнаружение объектов. Какие перспективы открываются для создания универсальных мультимодальных моделей, способных обеспечить надежный пространственный интеллект для реальных автономных систем?
Ограничения Традиционной Робототехники и Необходимость Воплощенного Восприятия
Традиционные роботизированные системы, как правило, полагаются на детально проработанные карты окружающей среды, что значительно ограничивает их адаптивность и эффективность в реальных условиях. Вместо самостоятельного понимания пространства, роботы, использующие подобный подход, нуждаются в предварительном построении точной модели мира, где каждое препятствие и объект заранее занесены в память. Это делает их крайне уязвимыми к любым изменениям: перестановка мебели, появление новых объектов или даже незначительные отклонения от запланированной траектории могут привести к сбоям в работе или полной остановке. Подобная зависимость от статической информации делает роботов неспособными эффективно функционировать в динамичных, непредсказуемых средах, характерных для большинства реальных сценариев, и подчеркивает необходимость разработки более гибких и самообучающихся систем восприятия.
Современные роботизированные системы, полагающиеся на точную локализацию посредством GPS или LiDAR и предзаданные карты, демонстрируют хрупкость в условиях реального мира. Их функционирование критически зависит от соответствия текущей обстановки заранее запрограммированному окружению. Любые отклонения — изменение освещения, появление новых объектов, временные препятствия — приводят к сбоям в навигации и выполнении задач. Такая зависимость от абсолютной точности позиционирования делает роботов уязвимыми в динамичных средах, где изменения происходят непрерывно, и ограничивает их способность к автономной работе в непредсказуемых ситуациях. В результате, даже незначительные отклонения от ожидаемой картины мира могут привести к полному отказу системы, подчеркивая необходимость разработки более гибких и адаптивных подходов к восприятию окружающей среды.
Для создания действительно надежных и адаптируемых роботов требуется принципиально новый подход к восприятию окружающего мира. Вместо полагания на точные карты и абсолютное позиционирование, современные исследования направлены на разработку систем, способных формировать внутренние репрезентации пространства и контекста. Это означает, что робот должен не просто «видеть» объекты, но и понимать их взаимосвязь, предсказывать поведение и ориентироваться в незнакомой обстановке, подобно тому, как это делает человек. Такой подход предполагает создание «модели мира» внутри робота, позволяющей ему не только реагировать на текущие стимулы, но и планировать действия на основе прошлого опыта и ожиданий. Успешная реализация подобной системы позволит роботам функционировать в динамичной и непредсказуемой среде, значительно расширяя спектр их применения.
Современные системы распознавания объектов, используемые в робототехнике, часто сталкиваются с ограничениями при работе с незнакомыми предметами или ситуациями. Роботы, как правило, обучены идентифицировать лишь ограниченный набор объектов, заранее определенных в процессе обучения. В результате, при столкновении с новым, ранее не виденным объектом, или в непредсказуемой обстановке, система может оказаться неспособной корректно его идентифицировать или взаимодействовать с ним. Это существенно ограничивает возможности роботов в реальном мире, где разнообразие объектов и ситуаций бесконечно, и требует разработки принципиально новых подходов к восприятию, способных к обобщению и адаптации к неизвестному окружению. Необходимость распознавания «открытой лексики» — способности идентифицировать любой объект без предварительного обучения — является ключевой задачей для создания действительно автономных и гибких робототехнических систем.
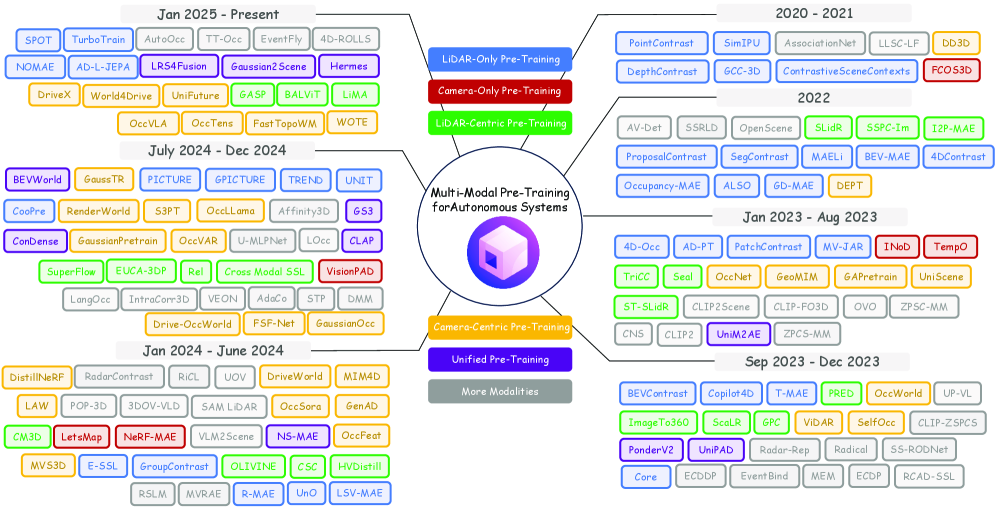
Пространственный Интеллект: Понимание Мира Без Явных Карт
Пространственный интеллект представляет собой принципиально новый подход к восприятию окружающей среды, позволяющий системам ориентироваться и взаимодействовать с ней без необходимости создания явных карт. В традиционных системах навигации и робототехнике требуется предварительное построение детальных моделей окружения, что ограничивает их адаптивность и вычислительную эффективность. Пространственный интеллект, напротив, обеспечивает возможность динамического понимания и интерпретации сенсорных данных (например, от IMU, GPS, камер) непосредственно в процессе взаимодействия со средой, что позволяет системам реагировать на изменения в реальном времени и действовать в непредсказуемых условиях без предварительной подготовки.
Построение непрерывного представления пространства и взаимосвязей между объектами достигается за счет интеграции данных, поступающих от различных сенсоров, таких как инерциальные измерительные блоки (IMU), системы глобального позиционирования (GPS) и камеры. IMU обеспечивают данные об ориентации и движении, GPS — о глобальном местоположении, а камеры — визуальную информацию об окружающей среде. Объединение этих данных позволяет системе формировать трехмерную модель пространства, отслеживать перемещение объектов и прогнозировать их возможное положение в будущем, создавая динамическое и актуальное представление окружающей действительности.
Технология 3D Gaussian Splatting обеспечивает эффективное представление и рендеринг сложных сцен за счет использования гауссовских сплэтов — параметрических трехмерных объектов, аппроксимирующих геометрию и внешний вид объектов. В отличие от традиционных методов, таких как триангуляционные сетки или воксели, гауссовские сплэты позволяют достичь высокой детализации при значительно меньшем объеме памяти и вычислительных затратах. Каждый сплэт описывается несколькими параметрами, включая положение, размер, ориентацию и цвет, что позволяет гибко моделировать сложные формы и текстуры. Алгоритмы рендеринга, основанные на гауссовских сплэтах, позволяют добиться фотореалистичного качества изображения с высокой частотой кадров, что критически важно для приложений, требующих интерактивного взаимодействия в реальном времени, таких как дополненная и виртуальная реальность.
В основе данной функциональности лежат надежные внутренние модели мира, представляющие собой структурированное представление окружающей среды, которое позволяет системе прогнозировать будущие состояния и принимать обоснованные решения. Эти модели не являются статичными; они постоянно обновляются на основе поступающих данных с датчиков и алгоритмов обработки информации. Способность предсказывать траектории движения объектов, изменения в окружающей среде и потенциальные препятствия критически важна для автономной навигации, планирования действий и адаптации к динамическим условиям. Точность и надежность этих моделей напрямую влияют на эффективность и безопасность работы системы в реальном времени.
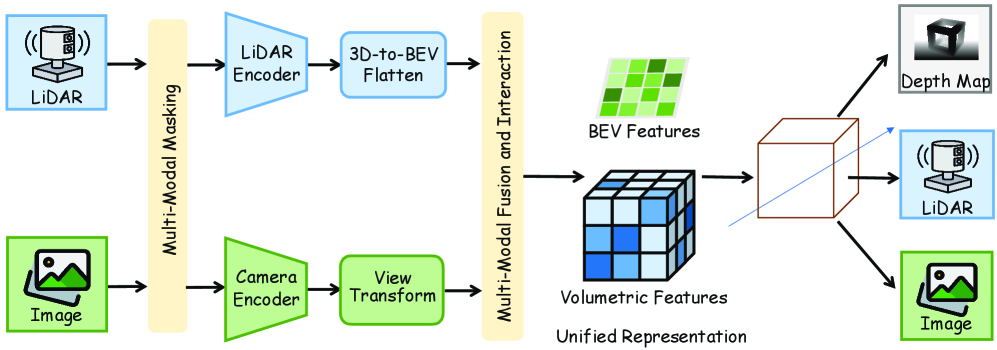
Самообучение: Извлечение Знаний из Немаркированных Данных
Самообучение (Self-Supervised Learning, SSL) представляет собой подход к машинному обучению, позволяющий роботам и системам восприятия извлекать полезные представления из немаркированных данных. В отличие от традиционных методов, требующих больших объемов вручную размеченных данных, SSL использует внутреннюю структуру самих данных для создания задач обучения. Это достигается путем сокрытия части данных и обучения модели предсказывать скрытые части, либо путем обучения модели различать различные представления одних и тех же данных. Использование немаркированных данных значительно расширяет возможности обучения, поскольку их получение обходится значительно дешевле и проще, чем маркированных данных, что позволяет создавать более надежные и обобщающие модели восприятия.
Методы обучения без учителя, такие как маскированное моделирование и контрастивное обучение, позволяют роботам устанавливать взаимосвязи между различными сенсорными модальностями без участия человека. Маскированное моделирование предполагает сокрытие части входных данных (например, пикселей изображения или точек облака) и обучение модели предсказывать скрытые элементы, что способствует пониманию контекста и структуры данных. Контрастивное обучение, в свою очередь, обучает модель отличать схожие (позитивные) примеры от различных (негативных), формируя представления, устойчивые к изменениям и шумам. Эти подходы позволяют роботу самостоятельно извлекать полезную информацию из необмеченных данных, что существенно снижает потребность в трудоемкой ручной разметке и повышает обобщающую способность модели.
Методы аугментации данных, такие как случайные повороты, масштабирование и добавление шума, активно используются для увеличения разнообразия обучающих выборок в задачах самообучения. Это позволяет моделям приобретать более устойчивые представления, менее чувствительные к вариациям входных данных. Применение аугментации данных способствует повышению обобщающей способности моделей, улучшая их производительность на новых, ранее не встречавшихся данных, и снижает риск переобучения, особенно при ограниченном объеме размеченных данных. Комбинация различных техник аугментации позволяет эффективно исследовать пространство возможных входных данных и обучать модели, способные к более надежной и точной обработке информации.
Предварительно обученные модели, созданные на основе самообучения (SSL), демонстрируют высокую эффективность в качестве кодировщиков многомодальной информации. В задачах 3D-обнаружения объектов, такие модели достигают средней точности обнаружения (mAP) в 71.17 пункта, что превосходит результаты предыдущих передовых решений. Это указывает на значительное улучшение способности моделей к обобщению и пониманию сложных сцен, благодаря использованию больших объемов неразмеченных данных в процессе обучения. Высокий показатель mAP подтверждает, что SSL является эффективным методом для создания надежных и точных систем восприятия.
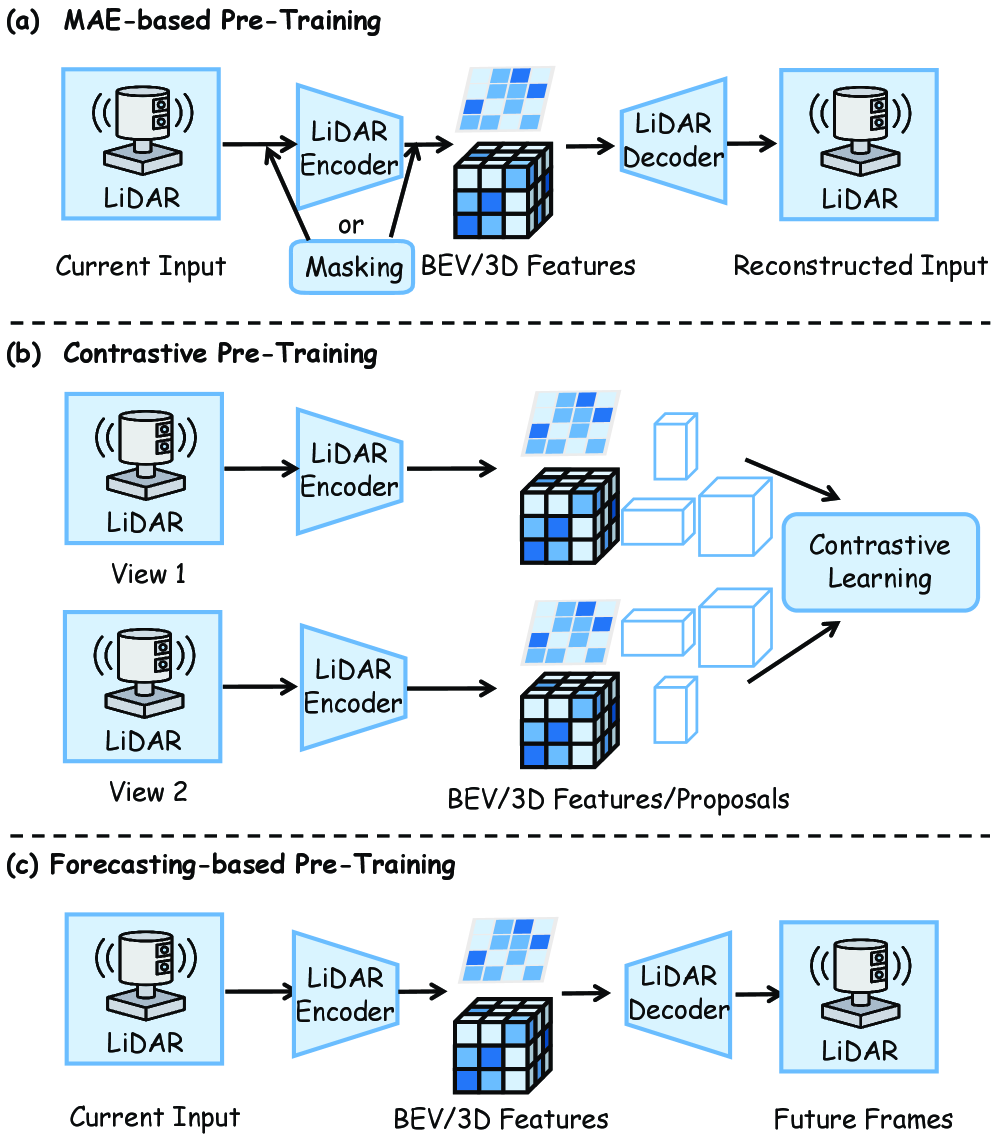
Визуально-Языковые Модели и Воплощенное Рассуждение: Новый Уровень Взаимодействия
Сочетание визуальной и лингвистической информации посредством моделей «зрение-язык» значительно расширяет возможности контекстуального понимания и способствует более естественному взаимодействию человека с роботами. Эти модели позволяют роботам не просто распознавать объекты на изображениях, но и интерпретировать их значение в контексте полученных языковых инструкций. Например, робот, получивший команду «Поставь красный кубик на синий», способен выделить из визуального потока нужные объекты, основываясь на их цвете, и выполнить указанное действие. Такое объединение модальностей позволяет преодолеть ограничения, присущие системам, оперирующим только визуальными или только текстовыми данными, и создает основу для интуитивно понятного и эффективного взаимодействия между человеком и машиной. В результате роботы становятся более адаптивными и способны выполнять сложные задачи, требующие не только распознавания объектов, но и понимания намерений пользователя.
Современные модели, объединяющие зрение и язык, демонстрируют впечатляющие способности к сложному рассуждению, позволяя роботам не просто реагировать на окружающую среду, но и понимать и выполнять поставленные задачи. Эти системы способны интерпретировать лингвистические инструкции, даже если они сформулированы неоднозначно или требуют логического вывода. Например, робот, обученный на подобной модели, может выполнить команду «Перенеси красный куб наверх синего», корректно идентифицировав объекты и выполнив последовательность действий, необходимых для выполнения задачи. Такое продвинутое рассуждение выходит за рамки простого распознавания образов и открывает возможности для создания роботов, способных решать сложные проблемы и адаптироваться к новым ситуациям, приближая их к уровню когнитивных способностей человека.
Разработка унифицированных рамок для многомодального обучения является ключевым фактором масштабирования систем, объединяющих зрение и язык. Исследования показывают, что использование визуальных приоритетов в таких рамках значительно повышает точность семантической сегментации LiDAR, достигая показателя mIoU в 77.27. Это демонстрирует потенциал интеграции визуальной информации для улучшения восприятия окружающей среды роботами, позволяя им более эффективно ориентироваться и взаимодействовать с миром даже при недостатке данных для обучения. Данный подход открывает новые возможности для создания надежных и адаптивных роботизированных систем, способных функционировать в сложных и непредсказуемых условиях.
Интеграция визуальной и лингвистической информации в робототехнике приводит к созданию систем, способных не просто воспринимать окружающий мир посредством сенсоров, но и понимать его смысл. Это достигается благодаря способности роботов анализировать полученные данные в контексте языковых инструкций и знаний, что позволяет им эффективно решать сложные задачи и адаптироваться к меняющимся условиям. Такое понимание выходит за рамки простого распознавания объектов; роботы начинают интерпретировать цели, намерения и отношения между элементами окружающей среды, что является ключевым шагом на пути к достижению истинной автономии и созданию интеллектуальных машин, способных действовать самостоятельно и разумно.
Будущее Робототехники: Масштабируемость, Адаптивность и Интеллект
Дальнейшие исследования направлены на расширение масштаба существующих моделей, чтобы обеспечить их функционирование в более сложных и реалистичных условиях. Это предполагает не только увеличение вычислительных мощностей, но и разработку новых алгоритмов, способных эффективно обрабатывать большие объемы данных и адаптироваться к изменяющейся обстановке. Особое внимание уделяется способности роботов к обучению в условиях неполной информации и к решению задач, требующих сложного планирования и координации действий. Успешное масштабирование позволит создавать робототехнические системы, способные автономно функционировать в динамичных и непредсказуемых средах, таких как городские пейзажи, промышленные предприятия или даже труднодоступные природные территории.
Разработка более эффективных и устойчивых алгоритмов самообучения является ключевым фактором для снижения потребности в огромных объемах размеченных данных и повышения способности роботов к обобщению полученных знаний. Традиционные методы машинного обучения требуют обширных наборов данных, что ограничивает их применение в реальных условиях, где сбор и разметка данных трудоемки и дороги. Самообучение, напротив, позволяет роботам извлекать полезную информацию непосредственно из необработанных сенсорных данных, таких как изображения и данные лидара, без необходимости в ручной разметке. Усовершенствованные алгоритмы самообучения, использующие, например, предсказание будущих состояний или восстановление замаскированных частей изображения, позволяют роботам формировать внутреннее представление об окружающей среде и эффективно адаптироваться к новым ситуациям. Повышение устойчивости этих алгоритмов к шуму и неполноте данных особенно важно для надежной работы роботов в сложных и динамичных условиях, открывая путь к созданию действительно автономных и гибких роботизированных систем.
Разработка методов переноса знаний между различными роботизированными платформами представляется ключевым фактором для ускорения внедрения автономных систем. Вместо того чтобы обучать каждую новую платформу с нуля, исследователи стремятся создать алгоритмы, позволяющие роботам эффективно использовать опыт, полученный на других устройствах. Это особенно важно, учитывая разнообразие существующих и разрабатываемых роботов — от промышленных манипуляторов до мобильных сервисных роботов и беспилотных летательных аппаратов. Успешный перенос знаний не только сокращает время и затраты на обучение, но и значительно повышает надежность и адаптивность роботов в новых, ранее не встречавшихся ситуациях, открывая возможности для широкого спектра практических применений в различных отраслях промышленности и повседневной жизни.
Исследования показали, что использование визуальных априорных знаний значительно повышает точность сегментации данных, полученных с лидаров, особенно в условиях ограниченного объема обучающих данных. В частности, применение подобных методов позволило добиться прироста в 4,5 процентных пункта по сравнению с традиционными подходами. Это демонстрирует потенциал интеграции визуальной информации для улучшения восприятия окружающей среды роботами, позволяя им более эффективно ориентироваться и взаимодействовать с миром даже при недостатке данных для обучения. Данный подход открывает новые возможности для создания надежных и адаптивных роботизированных систем, способных функционировать в сложных и непредсказуемых условиях.
В конечном счете, проводимые исследования направлены на создание робототехнических систем, превосходящих современные аналоги не только уровнем интеллекта, но и способностью к адаптации к изменяющимся условиям и устойчивостью к непредсказуемым ситуациям. Предполагается, что эти системы смогут функционировать в реальном мире, органично интегрируясь в повседневную жизнь и оказывая поддержку в различных сферах деятельности — от промышленности и логистики до здравоохранения и домашнего хозяйства. Такая интеграция предполагает не просто выполнение заданных программ, но и способность к самостоятельному обучению, решению новых задач и взаимодействию с окружающей средой и людьми, что позволит роботам стать полноценными помощниками и партнерами человека.
Исследование, представленное в данной работе, подтверждает важность многомодального предварительного обучения для развития пространственного интеллекта в автономных системах. Подход к созданию фундаментальных моделей и генеративных моделей мира позволяет системам не просто воспринимать данные, но и строить внутреннее представление о среде. Как отмечал Дэвид Марр: «Представление о мире не является пассивным отражением реальности, а активным построением модели, позволяющей прогнозировать и взаимодействовать с окружающей средой». Это особенно актуально в контексте безопасного развертывания автономных систем в реальных условиях, где способность к предсказанию и адаптации является ключевым фактором успеха.
Куда смотрит горизонт?
Представленная работа, по сути, демонстрирует, как модель становится своего рода микроскопом, а данные — объектом исследования. Однако, за кажущейся стройностью многомодального предобучения скрывается ряд нерешенных вопросов. Построение действительно “пространственного интеллекта” требует не просто слияния сенсорных потоков, но и формирования внутренней репрезентации мира, способной к абстракции и прогнозированию. До сих пор генеративные мировые модели остаются скорее амбициозной целью, чем достигнутой реальностью, и их способность к надежной экстраполяции в неизученных условиях вызывает обоснованные сомнения.
Особого внимания заслуживает проблема “хрупкости” этих систем. Незначительные изменения в входных данных могут приводить к катастрофическим ошибкам, что неприемлемо для автономных систем, функционирующих в реальном мире. Преодоление этой хрупкости потребует не только более совершенных алгоритмов, но и принципиально новых подходов к валидации и верификации, учитывающих неопределенность и стохастичность окружающей среды.
В конечном итоге, развитие многомодального предобучения — это не просто техническая задача, но и философский поиск. Попытка создать искусственный интеллект, способный к пространственному мышлению, заставляет задуматься о природе самого интеллекта и о том, что означает “понимать” мир. Ирония заключается в том, что, стремясь к созданию машины, способной видеть, мы, возможно, начинаем лучше понимать, как видим мы сами.
Оригинал статьи: https://arxiv.org/pdf/2512.24385.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Биосети в руках ИИ: Автоматизация системной фармакологии
- Квантовая Физика и Безопасность: Анализ Последних Новостей
- Сияние фотонов: новый уровень точности в предсказаниях столкновений частиц
- Трансформация нейросетей: от плотных моделей к разреженным экспертам без обучения
- Эхо чёрных дыр: как квантовая гравитация меняет гравитационные волны
- Искусственный интеллект на страже кода: новая оценка качества
- Квантовый поиск гравитационных волн: новый алгоритм для повышения точности
- Оптические Тензорные Ядра: Путь к Масштабируемым Вычислениям
- Квантовый скачок в многомасштабном моделировании
- StreamingVLM: когда даже бесконечный видоряд не сломает RoPE.
2026-01-01 18:32