Автор: Денис Аветисян
Новое исследование анализирует, как принципы диффузионных моделей, успешно применяемые в генерации изображений, сталкиваются с особенностями дискретной структуры и зависимостей в естественном языке.
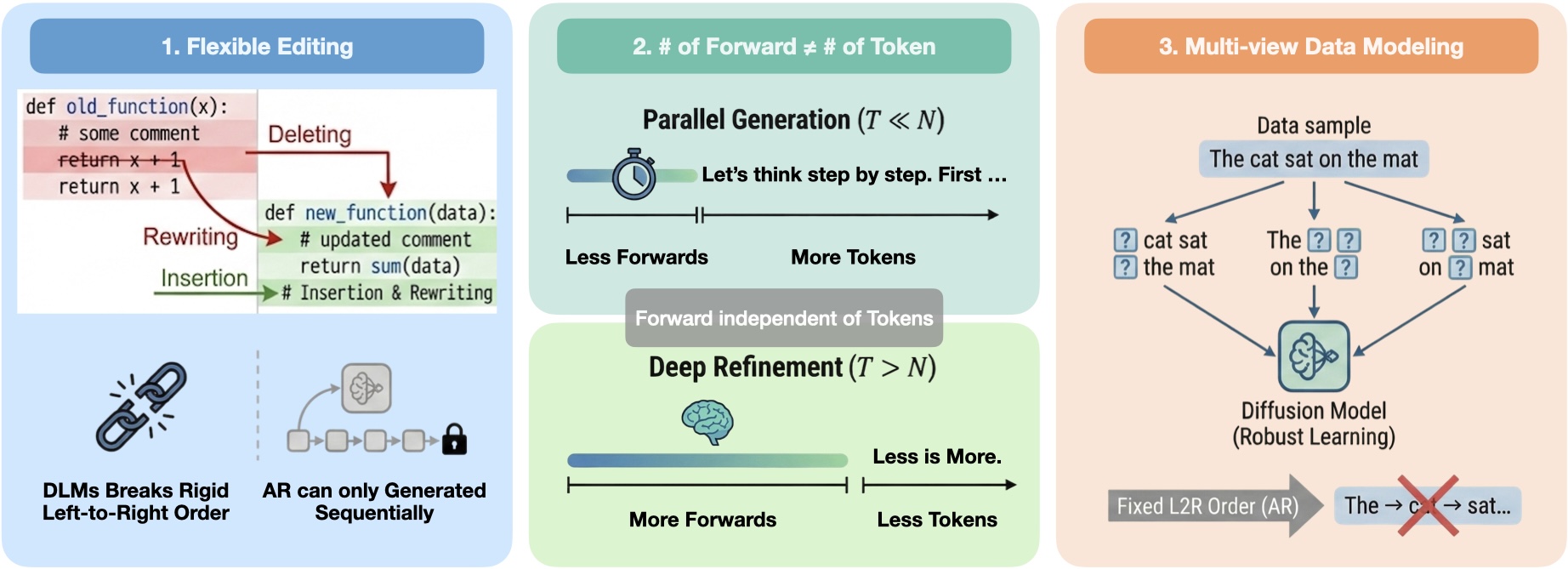
Анализ проблем применения диффузионных моделей к языку и определение ключевых свойств для структурно согласованных языковых моделей.
Несмотря на привлекательные свойства диффузионных моделей для генерации текста, их прямое применение сталкивается с трудностями из-за дискретной и структурированной природы языка. В работе ‘On the Role of Discreteness in Diffusion LLMs’ предпринята попытка переосмыслить диффузионное языковое моделирование, выделив пять ключевых свойств, отличающих общие принципы диффузии от специфических требований обработки естественного языка. Показано, что существующие подходы, оперирующие либо непрерывными вложениями, либо дискретными токенами, отражают компромисс между этими свойствами, не учитывая особенности распределения информации и зависимости между токенами. Какие новые архитектуры и методы обучения позволят создать более когерентные и эффективные диффузионные языковые модели, учитывающие структурные особенности текста?
Преодолевая Авторегрессию: Необходимость Новых Языковых Моделей
Традиционные авторегрессионные модели, несмотря на значительные успехи в обработке естественного языка, сталкиваются с трудностями при улавливании всей сложности языковых зависимостей. Эти модели, по сути, предсказывают следующее слово, основываясь на предыдущих, что зачастую приводит к упрощению понимания текста. Вместо того чтобы учитывать взаимосвязи между отдалёнными частями предложения или улавливать структурные особенности, они фокусируются на последовательном предсказании, что ограничивает их способность к более глубокому анализу и пониманию смысла. Игнорирование нелинейных взаимодействий и долгосрочных зависимостей приводит к тому, что модели могут испытывать трудности с интерпретацией сложных предложений или пониманием контекста, требующего учета более широкого круга информации, чем просто предшествующий текст.
Традиционные языковые модели, основанные на последовательном предсказании, зачастую фокусируются на установлении связи между непосредственно следующими словами, упуская из виду более широкие контекстуальные взаимосвязи. Такой подход ограничивает их способность к тонкому пониманию и логическому выводу, поскольку модель не учитывает общую структуру и смысл текста. Вместо того чтобы анализировать предложение как единое целое, она рассматривает его как цепочку отдельных элементов, что препятствует выявлению скрытых смыслов и сложных зависимостей. В результате, даже при успешном предсказании следующего слова, модель может испытывать трудности с ответами на вопросы, требующие более глубокого понимания контекста и способности к абстрактному мышлению.
Существенная проблема современных языковых моделей заключается в их ограниченной способности учитывать дальнодействующие связи и структурную организацию текста, выходя за рамки простого последовательного анализа. Традиционные подходы, ориентированные на предсказание следующего слова в последовательности, часто упускают из виду более глубокие семантические отношения и контекстуальные зависимости, существующие между удаленными частями текста. Это затрудняет понимание сложных предложений, выявление ключевых аргументов и обобщение информации. Исследования показывают, что для достижения истинного лингвистического понимания необходимо моделировать не только локальные, но и глобальные зависимости, учитывая иерархическую структуру текста и взаимосвязь между различными его элементами. Разработка моделей, способных эффективно обрабатывать эти сложные взаимосвязи, является ключевой задачей для дальнейшего развития искусственного интеллекта и обработки естественного языка.
Диффузионные Модели Вступают в Лингвистическую Область
Диффузионные языковые модели (DLM) представляют собой новый подход к генерации текста, заимствующий принципы диффузионных моделей, изначально разработанных для работы с изображениями. В отличие от традиционных методов, основанных на авторегрессии, DLM оперируют с текстовыми последовательностями посредством процесса постепенного добавления шума и последующего восстановления исходного сигнала. Этот процесс позволяет модели изучать распределение вероятностей текста, не опираясь на предсказание следующего токена в последовательности, что потенциально обеспечивает более гибкую и разнообразную генерацию текста. Основное отличие заключается в переходе от детерминированной генерации, характерной для авторегрессионных моделей, к вероятностному процессу, управляемому диффузией и шумоподавлением.
В отличие от авторегрессионных моделей, диффузионные языковые модели (DLM) не опираются на последовательное предсказание следующего токена. Вместо этого, DLM функционируют посредством процесса постепенной деградации входного текста до случайного шума, а затем — обратного процесса постепенного восстановления исходного сигнала из этого шума. Этот подход позволяет модели обучаться на основе принципа шумоподавления, а не на предсказании следующего символа в последовательности, что принципиально отличает DLM от традиционных языковых моделей, таких как рекуррентные нейронные сети или трансформеры, использующие авторегрессию.
В основе диффузионных языковых моделей (DLM) лежит концепция постепенного разрушения и восстановления текстовых последовательностей, заимствованная из области диффузионных моделей. Ключевым является использование “гладкой коррупции” — процесса добавления шума к данным таким образом, чтобы изменения происходили плавно и контролируемо. Важным свойством успешных DLM является наличие “управляемых промежуточных состояний” — состояний, возникающих в процессе коррупции и восстановления, которые могут быть эффективно смоделированы и использованы для генерации текста. Наш фреймворк определяет эти свойства — гладкую коррупцию и управляемые промежуточные состояния — как определяющие факторы, влияющие на эффективность и стабильность диффузионных языковых моделей.
Навигация в Дискретности: Дискретные vs. Непрерывные DLM
Применение диффузионных моделей к дискретным токенам требует особого подхода, поскольку прямое применение стандартных методов, разработанных для непрерывных данных, часто оказывается неэффективным. Это связано с тем, что операции добавления шума и последующего восстановления, оптимизированные для непрерывных пространств, плохо адаптируются к дискретной природе токенов. Непосредственное добавление гауссовского шума к дискретным значениям приводит к потере информации и ухудшению качества генерируемых последовательностей. В связи с этим, для работы с дискретными данными используются альтернативные методы, такие как маскирование токенов или специальные схемы добавления шума, учитывающие дискретность данных.
Дискретные диффузионные вероятностные модели (DLM) для работы с дискретными данными, такими как текстовые токены, применяют методы маскирования токенов для внесения возмущений в исходную последовательность. В процессе обучения, часть токенов заменяется специальным символом маски, что позволяет модели научиться восстанавливать исходные данные на основе контекста. В отличие от этого, непрерывные DLM оперируют в пространстве непрерывных вложений, используя гауссовский шум для создания возмущений. Это позволяет применять стандартные методы диффузии, разработанные для непрерывных данных, непосредственно к векторным представлениям входных данных, избегая необходимости в специальных подходах к дискретным данным.
Маскированная дискретная диффузия представляет собой практичный подход к искажению и восстановлению дискретных токенов, используемый в задачах языкового моделирования. В отличие от непрерывных моделей, работающих с зашумленными эмбеддингами, данный метод непосредственно оперирует с дискретными токенами, заменяя часть из них специальным токеном маскировки. Процесс обучения заключается в предсказании исходных токенов по замаскированному входу, что позволяет модели изучать вероятностное распределение над последовательностями токенов. Эффективность подхода обусловлена тем, что он позволяет избежать проблем, связанных с применением гауссовского шума к дискретным данным, и обеспечивает более стабильное и предсказуемое обучение модели.
Преодоление Препятствий: Коллапс Частотности и Маржинальная Ловушка
Явление “коллапса частотности” представляет собой проблему в дискретных языковых моделях (DLM), заключающуюся в предсказании наиболее часто встречающихся токенов, несмотря на контекст. Это происходит из-за потери информации в процессе намеренной коррупции входных данных, необходимой для обучения модели. В частности, стратегии равномерной коррупции (uniform corruption) усугубляют данную проблему, поскольку не учитывают важность различных токенов в последовательности, приводя к повышенной вероятности предсказания распространенных, но не всегда релевантных токенов. В результате модель теряет способность генерировать разнообразные и контекстуально точные последовательности.
Проблема «маржинальной ловушки» возникает в моделях, обучаемых на предсказание отдельных токенов, поскольку они испытывают трудности с обеспечением долгосрочных зависимостей и структурных ограничений внутри последовательности. В процессе обучения модель оптимизируется для точного предсказания каждого токена независимо, что приводит к игнорированию взаимосвязей между удаленными токенами и нарушению общей структурной целостности последовательности. Это особенно заметно в задачах, требующих соблюдения грамматических правил или логической последовательности, где корректное предсказание отдельных токенов недостаточно для формирования связного и осмысленного текста. В результате модель может генерировать локально корректные фрагменты, но испытывать затруднения с поддержанием общей когерентности и согласованности всей последовательности.
Параллельная декодировка представляет собой подход к решению проблемы «маргинальной ловушки», возникающей при обучении моделей предсказанию отдельных токенов. Вместо последовательного обновления маскированных позиций, параллельная декодировка обновляет сразу несколько позиций одновременно. Это позволяет модели учитывать зависимости между несколькими токенами в последовательности, способствуя более эффективному применению долгосрочных зависимостей и структурных ограничений, которые сложно обеспечить при последовательном подходе. В результате, модель получает возможность генерировать более связные и грамматически корректные последовательности, избегая локальных оптимумов, характерных для последовательной декодировки.
Будущее Языкового Моделирования: За Пределами Текущих Ограничений
Диффузионные языковые модели представляют собой принципиально новый подход к моделированию языка, отличающийся от традиционных методов. Вместо прямого предсказания следующего слова, эти модели постепенно добавляют шум к тексту, а затем обучаются восстанавливать исходный сигнал. Такой процесс, вдохновленный принципами диффузии в физике, позволяет моделям генерировать более разнообразные и реалистичные тексты, избегая некоторых проблем, свойственных авторегрессионным моделям, например, склонности к повторениям или генерации предсказуемых фраз. Вместо того, чтобы конкурировать с существующими подходами, диффузионные модели успешно дополняют их, предлагая альтернативный механизм для решения задач обработки естественного языка и открывая новые возможности для создания более интеллектуальных и адаптивных систем.
В настоящее время значительные усилия исследователей направлены на совершенствование стратегий намеренного искажения данных и методов декодирования в диффузионных языковых моделях. Эти работы призваны смягчить проблемы, такие как “коллапс частотности” — тенденция к вырождению модели до предсказуемых и повторяющихся последовательностей — и так называемую “маргинальную ловушку”, при которой модель фокусируется на наиболее вероятных, но менее информативных элементах. Улучшение процессов “зашумления” и последующего восстановления данных позволяет моделям генерировать более разнообразные и креативные тексты, избегая застревания в локальных оптимумах и повышая общую устойчивость системы к непредсказуемым входным данным. Особое внимание уделяется разработке новых алгоритмов декодирования, которые эффективно используют информацию, полученную в процессе “очистки” данных, для создания связных и осмысленных текстов.
Перспективные исследования в области диффузионных языковых моделей (DLM) направлены на разработку усовершенствованных механизмов шумоподавления, способных более эффективно восстанавливать исходный сигнал из зашумленных данных. Помимо этого, активно изучается возможность интеграции DLM с другими передовыми языковыми технологиями, такими как трансформеры и нейронные сети с вниманием, для создания гибридных систем. Ожидается, что подобный симбиоз позволит преодолеть текущие ограничения DLM, обеспечивая более глубокое и нюансированное понимание языка, а также значительно повышая надежность и точность генерируемых текстов. Такой подход открывает новые горизонты в области обработки естественного языка, способствуя созданию более интеллектуальных и адаптивных систем.
Исследование роли дискретности в диффузионных языковых моделях подчёркивает фундаментальное несоответствие между непрерывными предположениями, лежащими в основе диффузии, и дискретной природой языка. Авторы справедливо отмечают, что эффективное моделирование зависимостей в тексте требует особого подхода к структуре моделей. Как заметил Давид Гильберт: «В математике нет траектории, ведущей к истине. Можно лишь искать доказательства». Эта фраза отражает суть работы: стремление к доказательству корректности модели, а не просто к её работоспособности на тестовых примерах. Доказательство структурного выравнивания и минимизация потерь информации при дискретизации становятся ключевыми факторами для создания масштабируемых и устойчивых языковых моделей.
Куда двигаться дальше?
Представленное исследование, хотя и выявляет фундаментальные несоответствия между непрерывной природой диффузионных моделей и дискретной структурой языка, лишь обнажает глубину проблемы. Утверждать, что простое «выравнивание структур» решит все, — наивно. Ведь сама идея «выравнивания» предполагает возможность адекватного представления зависимости слов в непрерывном пространстве, что пока остается неподтвержденным. Следует признать: существующие подходы к кодированию текста, в конечном итоге, неизбежно приводят к потере информации, и это не устраняется косметическими улучшениями.
Будущие работы должны сосредоточиться не на «затыкании дыр» в существующих архитектурах, а на поиске принципиально новых подходов. Необходимо исследовать возможности применения категорной теории или других математических инструментов, способных адекватно описывать иерархическую структуру языка. Альтернативным путем представляется разработка дискретных диффузионных моделей, которые, отказавшись от непрерывности, смогут напрямую оперировать символами и их взаимосвязями. Иначе, все усилия будут тщетны, и мы продолжим строить сложные системы, которые лишь имитируют понимание, а не демонстрируют его.
Очевидно, что простое увеличение размера моделей и объемов данных не является решением. Требуется строгое математическое обоснование каждого этапа процесса, начиная с кодирования текста и заканчивая генерацией. Иначе, мы обречены на бесконечную гонку за параметрами, в которой истинная элегантность и математическая чистота будут принесены в жертву эмпирическому успеху. И это, пожалуй, самое печальное.
Оригинал статьи: https://arxiv.org/pdf/2512.22630.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Трансформация нейросетей: от плотных моделей к разреженным экспертам без обучения
- Эхо чёрных дыр: как квантовая гравитация меняет гравитационные волны
- Квантовая Физика и Безопасность: Анализ Последних Новостей
- Сияние фотонов: новый уровень точности в предсказаниях столкновений частиц
- Биосети в руках ИИ: Автоматизация системной фармакологии
- Волшебство по запросу: ИИ создает заклинания в игре
- Неупорядоченные системы с неэрмитовыми эффектами
- Луна раскрывает свои секреты: Искусственный интеллект восстанавливает древнюю формулу
- Квантовые сети связи: оптимизация расписания для спутниковой передачи
- Квантовый горизонт: взгляд изнутри
2026-01-02 09:28