Автор: Денис Аветисян
Исследователи представили LooC — инновационный метод векторной квантизации, позволяющий значительно уменьшить размер кодовых книг без потери качества реконструкции изображений.

В статье представлен LooC — метод композиционной векторной квантизации с низкоразмерной кодовой книгой, демонстрирующий передовые результаты в задачах сжатия данных и реконструкции изображений.
Векторная квантизация, несмотря на свою эффективность в дискретизации данных, сталкивается с противоречием между необходимостью увеличения ёмкости кодовых книг и поддержанием их компактности. В данной работе представлена новая методика — LooC: Effective Low-Dimensional Codebook for Compositional Vector Quantization — использующая эффективную низкоразмерную кодовую книгу для композиционной векторной квантизации. Предложенный подход позволяет добиться повышения производительности и значительного сокращения размера кодовой книги за счёт переосмысления взаимосвязи между кодовыми векторами и векторами признаков, а также за счёт введения механизма экстраполяции-интерполяции. Сможет ли LooC стать универсальным модулем для различных задач, использующих векторную квантизацию, и открыть новые горизонты в области сжатия и реконструкции данных?
Преодолевая Размерность: Вызовы Квантования Представлений
Обработка и хранение данных высокой размерности представляет собой серьезную проблему для современных вычислительных систем. По мере увеличения числа признаков, описывающих каждый объект, экспоненциально возрастает объем необходимых ресурсов для их анализа и хранения. Это явление, известное как «проклятие размерности», приводит к замедлению вычислений, увеличению потребления памяти и снижению эффективности алгоритмов машинного обучения. Сложность заключается в том, что при увеличении размерности пространства данных, плотность распределения точек уменьшается, что затрудняет поиск значимых закономерностей и приводит к переобучению моделей. В связи с этим, разработка методов, способных эффективно работать с данными высокой размерности, является критически важной задачей для многих областей науки и техники, включая компьютерное зрение, обработку естественного языка и анализ генома.
Проблема “проклятия размерности” является фундаментальным препятствием при обработке данных высокой размерности. По мере увеличения числа признаков, объём данных, необходимого для адекватного представления пространства признаков, экспоненциально возрастает. Это приводит к значительному увеличению вычислительной сложности и потребляемых ресурсов, затрудняя эффективный анализ и обработку информации. Традиционные методы, такие как поиск ближайших соседей или обучение моделей, становятся непрактичными из-за экспоненциального роста требуемых вычислений и памяти. В результате, обработка данных высокой размерности часто становится узким местом в различных приложениях, начиная от компьютерного зрения и заканчивая обработкой естественного языка, требуя разработки инновационных подходов к снижению вычислительной сложности и сохранению информативности данных.
Векторная квантизация представляет собой перспективный подход к обработке данных высокой размерности, позволяющий преобразовать непрерывные значения в дискретные представления, что значительно снижает требования к объему памяти и вычислительным ресурсам. Однако, несмотря на свою привлекательность, данный метод не лишен сложностей. Основная проблема заключается в потере информации при дискретизации и возможности возникновения неточностей. Эффективность векторной квантизации напрямую зависит от качества создаваемого кодового словаря и способности алгоритма правильно сопоставлять входные данные с ближайшими векторами в этом словаре. Неоптимальный выбор кодового словаря или несовершенство алгоритма сопоставления может привести к существенной деградации качества представления данных и снижению производительности системы.
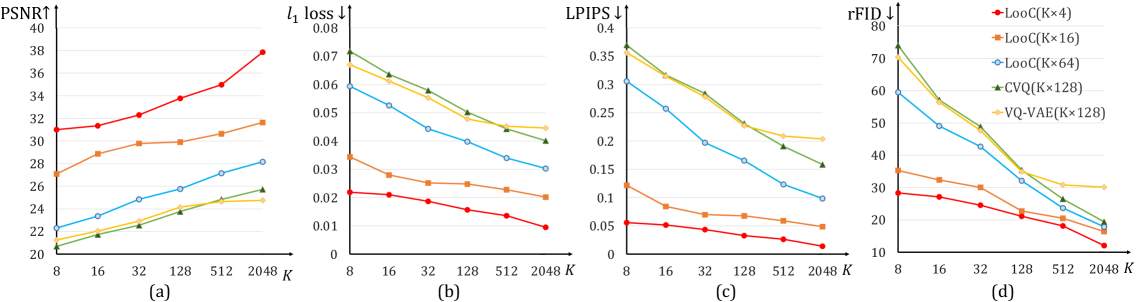
В задачах векторной квантизации, где непрерывные данные преобразуются в дискретные представления для экономии ресурсов, часто возникает проблема “коллапса кодовой книги” (Codebook Collapse). Суть её заключается в том, что лишь незначительная часть доступных векторов в кодовой книге фактически используется для представления данных, что снижает эффективность сжатия и информативность представления. Большинство существующих методов страдают от неполного использования кодовой книги, приводя к избыточности и потере информации. Однако, разработанный подход LooC демонстрирует значительное улучшение, обеспечивая 100%-ное использование всех векторов кодовой книги как при K=256, так и при K=1024, что позволяет добиться более компактного и информативного представления данных и существенно повысить эффективность обработки многомерных данных.
Композиционное Квантование: Углубленный Анализ Представлений
Композиционное векторное квантование (CompositionalVQ) представляет собой усовершенствованный подход к квантованию, заключающийся в разделении входных признаков на подсегменты. Вместо обработки признаков как единого целого, CompositionalVQ позволяет более детально анализировать и представлять данные, повышая гранулярность представления. Это достигается путем квантования каждого подсегмента отдельно, что позволяет точнее отразить сложные характеристики данных и снизить потери информации при сжатии. Разделение на подсегменты позволяет более эффективно кодировать данные, особенно в случаях, когда различные части признака имеют разную важность или требуют разной степени детализации.
Композиционное квантование обеспечивает более эффективное представление сложных данных за счет разделения признаков на субсегменты. Такой подход позволяет захватывать более тонкие детали по сравнению с традиционными методами квантования, которые оперируют с признаками как с единым целым. Разделение на субсегменты дает возможность более точно моделировать вариативность данных и, следовательно, повышает точность представления, особенно в случаях, когда небольшие изменения в признаках имеют существенное значение. Это приводит к снижению потерь информации при квантовании и улучшению качества реконструкции данных после деквантования.
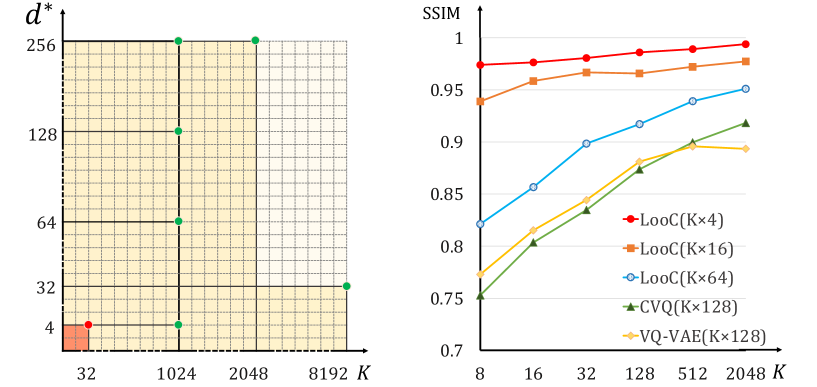
Метод LooC использует композиционный подход к квантованию, обеспечивая компактность и высокую производительность за счет применения низкоразмерной кодовой книги. В ходе исследований было достигнуто до 4-кратного уменьшения размера кодовой книги по сравнению с современными аналогами, что позволяет существенно снизить требования к памяти и вычислительным ресурсам без потери качества представления данных. Это достигается за счет эффективного разделения признаков на подсегменты и их последующего квантования с использованием оптимизированной кодовой книги.
Метод LooC использует процедуру ‘ExtrapolationByInterpolation’ для улучшения качества квантования путем сглаживания и усиления признаков. Данный подход заключается в интерполяции между векторами кода в кодовой книге для получения более точного представления исходного вектора признаков. Это позволяет уменьшить погрешность, возникающую при квантовании, и повысить эффективность представления данных, особенно в случаях, когда исходные признаки содержат шум или незначительные вариации. По сути, ‘ExtrapolationByInterpolation’ создает более плавный переход между дискретными уровнями квантования, что приводит к более точному восстановлению исходных данных.

Квантование в Действии: Восстановление и Генерация Изображений
Методика LooC успешно применяется как в задачах восстановления изображений (Image Reconstruction), так и в задачах генерации изображений (Image Generation). В процессе восстановления LooC позволяет эффективно воссоздавать исходные изображения из сжатого представления, минимизируя потери качества. В задачах генерации LooC обеспечивает создание новых, реалистичных изображений, используя квантованное латентное пространство для управления характеристиками генерируемого контента. Эффективность LooC подтверждается результатами, демонстрирующими высокую производительность в обеих областях применения.
Эффективное квантование латентного пространства в LooC позволяет добиться компактного представления изображений и упростить операции манипулирования ими. Квантование преобразует непрерывные значения в дискретные коды, что снижает требования к памяти и вычислительным ресурсам. Это достигается за счет использования кодовых книг (codebooks), которые представляют собой набор дискретных векторов, аппроксимирующих латентные представления. Применение LooC позволяет представлять изображения с высокой степенью точности, используя ограниченное число дискретных кодов, что повышает эффективность как задач реконструкции, так и генерации изображений.
Экспериментальные результаты демонстрируют практическую эффективность композиционной квантизации, позволяющей достичь высокой производительности при снижении вычислительных затрат. В частности, модель LooC достигла значения rFID 19.22 на наборе данных CIFAR10, используя кодовую книгу размером 32×4, и показала значение PSNR 34.51. Эти показатели подтверждают, что применение композиционной квантизации позволяет эффективно представлять и обрабатывать изображения, сохраняя при этом высокое качество реконструкции и генерации.
Архитектура LooC позволяет создавать «Универсальный Кодовый Словарь» (UniversalCodebook), применимый к различным наборам данных. В отличие от традиционных методов, требующих обучения отдельного кодового словаря для каждого датасета, LooC использует единый, обобщенный кодовый словарь, что значительно снижает вычислительные затраты и упрощает процесс переноса знаний между задачами. Этот подход основан на способности LooC эффективно квантовать латентное пространство и извлекать общие признаки, присущие различным типам изображений, обеспечивая тем самым возможность использования одного и того же кодового словаря для реконструкции и генерации изображений из разных источников.
Расширяя Инструментарий: Взаимодополняющие Методы
Метод ProductQuantization значительно расширяет возможности векторной квантизации, позволяя эффективно работать с данными высокой размерности. Вместо того чтобы квантовать все пространство признаков сразу, ProductQuantization разбивает его на несколько подпространств меньшей размерности. В каждом из этих подпространств применяется независимая квантизация, что значительно снижает вычислительную сложность и объем памяти, необходимые для хранения и обработки данных. Такой подход позволяет представлять векторы признаков в виде набора кодов, соответствующих различным подпространствам, сохраняя при этом достаточную точность представления и обеспечивая эффективный поиск ближайших соседей даже в очень больших наборах данных. \mathbb{R}^d пространство признаков разбивается на m подпространств, каждое размерности d/m .
Автоэнкодеры с векторной квантизацией, известные как VQ-VAE, представляют собой инновационный подход к представлению данных, объединяющий преимущества автоэнкодеров и векторной квантизации. В основе этой архитектуры лежит идея сжатия данных путем отображения входных данных в дискретное пространство кодов, представленное кодовой книгой. Автоэнкодер обучается реконструировать входные данные из этих дискретных представлений, что способствует извлечению компактных и информативных признаков. Использование векторной квантизации позволяет существенно уменьшить размерность данных, сохраняя при этом важную информацию, что особенно полезно в задачах обработки изображений, аудио и видео. Такой подход не только улучшает эффективность хранения и передачи данных, но и открывает новые возможности для генерации и анализа данных, позволяя создавать более реалистичные и качественные результаты.
Метод CVQ (Codebook Vector Quantization) направлен на решение проблемы «коллапса кодовой книги», часто возникающей в системах векторной квантизации. В отличие от традиционных подходов, где векторы кодовой книги остаются фиксированными, CVQ динамически обновляет неактивные векторы, то есть те, которые редко используются в процессе квантизации. Этот процесс адаптации позволяет избегать ситуации, когда большая часть кодовой книги становится неиспользуемой, что существенно повышает устойчивость и эффективность модели. За счет непрерывного обучения и обновления неактивных векторов, CVQ поддерживает более сбалансированное представление данных и, как следствие, улучшает качество генерируемых или реконструируемых данных, что подтверждается результатами, демонстрирующими превосходство над другими методами, такими как VQGAN.
Совокупность представленных подходов ярко демонстрирует универсальность и потенциал векторной квантизации в современной науке о данных. В частности, разработанная методика LooC подтверждает свою эффективность, достигая показателя rFID в 5.66 на датасете CelebA (при обучении на FFHQ с K=256). Этот результат существенно превосходит аналогичный показатель VQGAN, составляющий 10.2, что свидетельствует о значительном улучшении качества генерируемых изображений и повышении стабильности процесса обучения. Данное достижение подчеркивает перспективность векторной квантизации как мощного инструмента для решения задач, связанных с обработкой и генерацией данных.
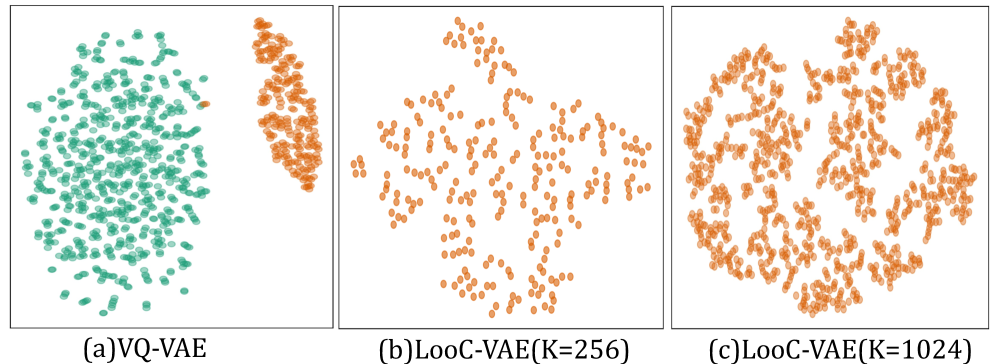
Исследование, представленное в данной работе, демонстрирует, как эффективная организация данных может значительно улучшить результаты в задачах кодирования и реконструкции изображений. Подобно тому, как микроскоп позволяет изучить мельчайшие детали объекта, предложенный метод LooC использует низкоразмерный композиционный кодекс для раскрытия скрытых закономерностей в данных. Эндрю Ын однажды заметил: «Самое сложное — не построить модель, а получить данные для ее обучения». Эта фраза прекрасно иллюстрирует суть представленного подхода: оптимизация кодекса позволяет более эффективно использовать имеющиеся данные, избегая коллапса кодекса и повышая качество реконструкции, что является ключевым в задачах сжатия и генерации изображений.
Куда Далее?
Представленная работа, безусловно, демонстрирует эффективность подхода к векторной квантизации с использованием компактного, композиционного кодекса. Однако, истинное понимание системы требует не только достижения высоких метрик, но и анализа границ применимости. Проблема «коллапса» кодекса, хотя и смягчена, не решена окончательно. Дальнейшие исследования должны быть направлены на формальное описание условий, при которых данный эффект проявляется, и разработку методов его предсказания, а не только пост-фактум коррекции.
Особенно интересным представляется вопрос о масштабируемости предложенного подхода к данным, отличающимся большей сложностью и размерностью, чем изображения. Способность сохранять информативность при существенном снижении размерности кодекса — это не просто техническая задача, но и философский вопрос о природе представления информации. Можно ли действительно «упаковать» суть явления в ограниченное число векторов, или неизбежно теряется что-то важное?
В перспективе, стоит рассмотреть возможность интеграции композиционных кодексов с другими методами сжатия и представления данных, такими как нейронные сети с разреженными связями или волновые преобразования. Возможно, истинный прогресс лежит не в совершенствовании одной конкретной техники, а в создании гибридных систем, использующих сильные стороны различных подходов. Иначе говоря, не стремиться к «идеальному» кодексу, а создавать гибкую и адаптивную систему представления данных.
Оригинал статьи: https://arxiv.org/pdf/2601.00222.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Когда мнения расходятся: как модели принимают решения при конфликте данных
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Шёпот языков: как дрессировать цифрового голема для забытых наречий.
- Взгляд в будущее: как теория динамических систем преобразит анализ временных рядов
- Визуальные объекты: новый инструмент для обучения моделей
- Масштабирование интеллекта: Обучение TeleChat3-MoE
- Белки-хамелеоны: Пределы предсказания гибкости структуры
- Переключение намагниченности в квантовых антиферромагнетиках: новые горизонты для терагерцовой спинтроники
- Ускорение генерации текста: новый подход к спекулятивному декодированию
- Визуальный интеллект: обучение рассуждению через головоломки
2026-01-05 18:31