Автор: Денис Аветисян
Исследователи предлагают инновационный подход к многоступенчатому логическому выводу, вдохновленный принципами диффузионных моделей, позволяющий языковым моделям самокорректироваться и повышать точность решения математических задач.
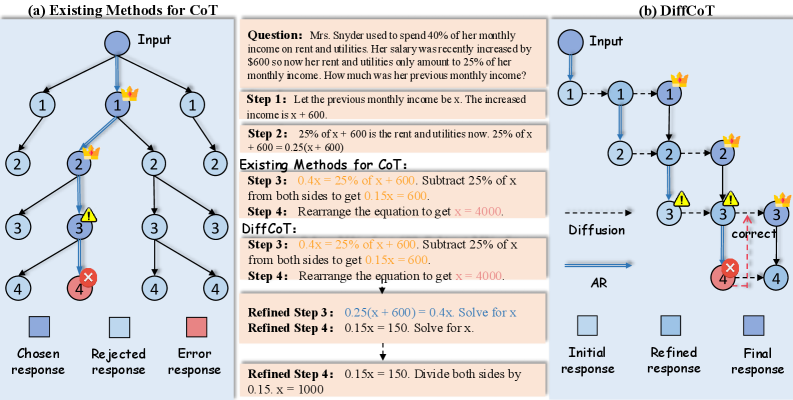
В статье представлена DiffCoT — структура, использующая диффузию для итеративной коррекции ошибок и оптимизации логических цепочек в больших языковых моделях.
Несмотря на успехи в многоступенчатом рассуждении, современные языковые модели подвержены накоплению ошибок и влиянию предвзятости экспозиции. В данной работе представлена методика DiffCoT: Diffusion-styled Chain-of-Thought Reasoning in LLMs, предлагающая новый подход к построению цепочек рассуждений, основанный на принципах диффузионных моделей. DiffCoT переформулирует процесс рассуждения как итеративное шумоподавление, позволяя моделям не только генерировать, но и корректировать промежуточные шаги, сохраняя при этом авторегрессию на уровне токенов. Способна ли подобная ревизия траектории рассуждений существенно повысить надежность и точность математических вычислений в больших языковых моделях?
Разрушая Цепочки: Слабость Авторегрессии
Стандартные авторегрессионные (AR) методы генерации, лежащие в основе современных больших языковых моделей, несмотря на свою мощь, проявляют уязвимость к накоплению ошибок при решении многошаговых задач, требующих логических рассуждений. В процессе генерации, каждая последующая стадия опирается на результат предыдущей, поэтому даже незначительная ошибка на раннем этапе может привести к каскаду неточностей, значительно снижая надежность итогового решения. Этот эффект, известный как “смещение экспозиции”, особенно заметен в сложных проблемах, требующих последовательного применения логики и математических операций, где любая неточность может исказить весь ход рассуждений и привести к неверному ответу. Подобные ограничения подчеркивают необходимость разработки более устойчивых к ошибкам механизмов генерации, способных поддерживать последовательность и точность рассуждений на протяжении всех этапов решения задачи.
Авторегрессионные модели, лежащие в основе современных генеративных систем, сталкиваются с проблемой, известной как “смещение экспозиции”. Суть её заключается в том, что ошибки, допущенные на ранних этапах многоступенчатого решения задачи, накапливаются и усугубляются с каждым последующим шагом. Подобный каскадный эффект снижает надёжность моделей в сложных сценариях, требующих глубокого логического мышления и точного вычисления. Изначальная неточность, даже незначительная, может привести к ошибочным выводам на более поздних стадиях, делая результат неверным и подрывая доверие к системе. Таким образом, данное смещение представляет собой серьёзное препятствие на пути к созданию искусственного интеллекта, способного решать сложные задачи с высокой точностью и надёжностью.
Тесты, такие как GSM8K, MATH и SVAMP, наглядно демонстрируют слабость стандартных подходов к многоступенчатому рассуждению, где даже незначительные ошибки на ранних этапах могут привести к серьезным искажениям в конечном результате. Эти бенчмарки выявляют потребность в более надежных и устойчивых системах, способных к глубокому логическому анализу. В этой связи, методика DiffCoT показывает значительное превосходство над существующими методами оптимизации предпочтений, последовательно демонстрируя более высокие результаты на указанных тестах и подтверждая свою эффективность в задачах, требующих сложного рассуждения и точного вывода.
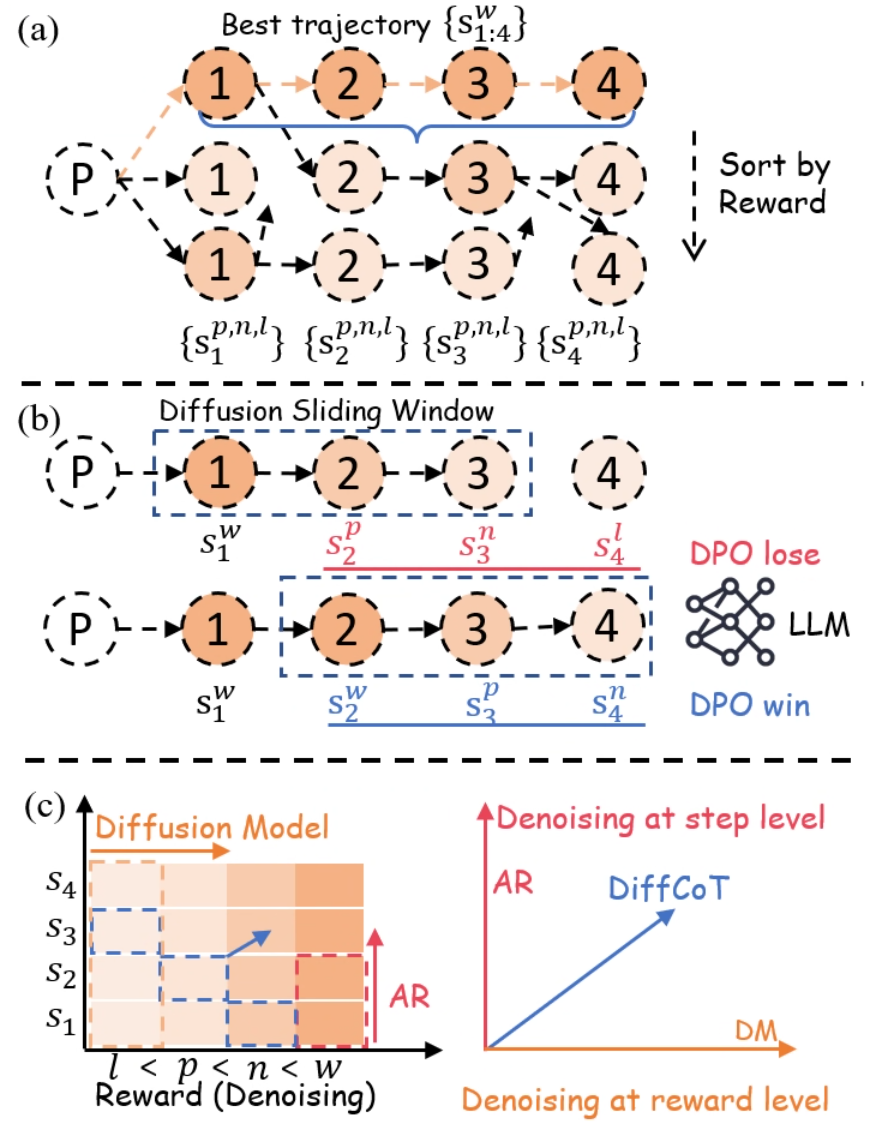
DiffCoT: Расшифровывая Рассуждения Итеративным Улучшением
DiffCoT представляет собой новую структуру, использующую принципы диффузионных моделей для улучшения логических рассуждений типа Chain-of-Thought (CoT). В отличие от традиционных методов, где цепочка рассуждений генерируется последовательно, DiffCoT рассматривает процесс рассуждения как процесс удаления шума, итеративно уточняя потенциальные решения. Данный подход позволяет модели постепенно приближаться к корректному ответу, начиная с зашумленного состояния, что обеспечивает более устойчивое и эффективное решение задач, требующих многоступенчатого логического вывода.
В отличие от традиционного последовательного формирования цепочки рассуждений (Chain-of-Thought), DiffCoT рассматривает процесс рассуждения как итеративное уточнение решения, аналогичное процессу шумоподавления в диффузионных моделях. Это означает, что вместо генерации шагов рассуждений один за другим, DiffCoT начинает с некоторого начального, возможно, шумного решения и постепенно его уточняет, уменьшая «шум» и приближаясь к оптимальному ответу. Каждая итерация уточнения основана на предыдущей, позволяя модели корректировать ошибки и исследовать различные варианты решения, не будучи жестко ограниченной первоначальными шагами. Этот подход позволяет DiffCoT более эффективно находить правильные решения, особенно в сложных задачах, где последовательное рассуждение может привести к накоплению ошибок.
Метод DiffCoT использует так называемое “Скользящее окно диффузии” для снижения влияния ошибок, допущенных на ранних этапах рассуждений. В отличие от последовательной генерации шагов, этот подход позволяет итеративно уточнять потенциальные решения, обеспечивая более гибкий поиск в пространстве возможных ответов. Экспериментальные данные демонстрируют, что DiffCoT стабильно превосходит существующие методы оптимизации предпочтений (Preference Optimization, PO) по показателям точности и эффективности, благодаря возможности корректировки ошибок и более широкому охвату вариантов решения.

Кодирование Причинности: Шум как Инструмент Рассуждения
Метод DiffCoT использует технику планирования шума, названную ‘Causal Diffusion Noise’, которая заключается в применении более сильного шума к последующим этапам рассуждений. Это позволяет закодировать зависимости между шагами, поскольку последующие этапы, подверженные большему воздействию шума, требуют более тщательной коррекции и уточнения. В отличие от традиционных диффузионных моделей, где шум обычно распределяется равномерно, данный подход позволяет приоритизировать уточнение критически важных компонентов логической цепочки, что влияет на конечный результат.
В отличие от традиционных диффузионных моделей, где шум обычно применяется равномерно ко всем этапам процесса, DiffCoT использует диффузионный шум, структурированный с учетом причинно-следственных связей. Это позволяет модели фокусироваться на уточнении критически важных компонентов рассуждений, а не на равномерном распределении вычислительных ресурсов. Применение структурированного шума позволяет DiffCoT приоритизировать этапы, оказывающие наибольшее влияние на конечный результат, что повышает эффективность и точность процесса рассуждений.
В рамках DiffCoT, процесс рассуждений рассматривается как последовательное удаление структурированного шума, добавленного с использованием техники ‘Causal Diffusion Noise’. Такой подход позволяет модели эффективно выявлять и корректировать ошибки на различных этапах рассуждений, что приводит к повышению точности получаемых решений. Экспериментальные данные демонстрируют, что данная архитектура обеспечивает существенно более высокую вероятность успешной коррекции при случайном искажении начальных этапов рассуждений (stochastic prefix corruption) по сравнению с методом Full-Step-DPO.
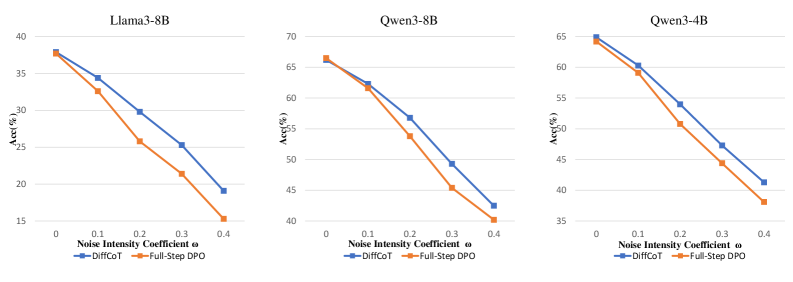
Выравнивание Рассуждений с Человеческими Предпочтениями: Искусство Оптимизации
Для дальнейшего повышения эффективности, модель DiffCoT может быть дополнена методами ‘Оптимизации предпочтений’, в частности, техникой ‘Оптимизации предпочтений на уровне шагов’. Данный подход позволяет модели обучаться на основе человеческих оценок, уточняя процесс рассуждений для соответствия желаемым стилям решения и уровням точности. Оптимизируя предпочтения на каждом этапе вывода, DiffCoT не просто находит решение, а стремится к наилучшему, оцениваемому экспертами, что подтверждается результатами на эталонных наборах данных, таких как GSM8K, SVAMP и MATH, где она демонстрирует превосходство над существующими методами оптимизации предпочтений.
Модель совершенствует свой процесс рассуждений благодаря обратной связи от людей, что позволяет ей адаптировать стиль решения задач и повышать точность ответов. Этот механизм обучения на предпочтениях позволяет системе не просто находить какое-либо решение, а формировать наиболее подходящий ответ, соответствующий ожиданиям экспертов. В результате, модель способна учитывать нюансы человеческого мышления и выдавать решения, которые не только верны, но и понятны и логичны с точки зрения человека, что значительно повышает ее практическую ценность и эффективность в решении сложных задач.
Модель DiffCoT, благодаря интеграции обучения на основе предпочтений, совершает переход от поиска просто какого-либо решения к нахождению оптимального, оцениваемого экспертами-людьми. Этот подход позволяет не только генерировать ответы, но и подстраивать сам процесс рассуждений под желаемые стили и уровни точности. В результате, DiffCoT демонстрирует стабильное превосходство над существующими методами оптимизации предпочтений (PO) на авторитетных бенчмарках, включая GSM8K, SVAMP и MATH, подтверждая свою способность к более качественному и человеко-ориентированному решению задач.
Будущее Надежных и Адаптивных Рассуждений: За пределами Авторегрессии
Метод DiffCoT демонстрирует значительный потенциал диффузионных подходов в решении ключевых задач искусственного интеллекта, связанных с рассуждениями. В отличие от традиционных авторегрессионных моделей, которые последовательно генерируют ответы, DiffCoT использует процесс диффузии, постепенно уточняя ответ из шума. Такой подход позволяет системе более эффективно справляться с неоднозначностью и сложностью задач, а также повышает устойчивость к ошибкам. Вместо предсказания следующего слова в последовательности, DiffCoT формирует ответ как результат постепенного удаления шума, что открывает новые возможности для создания более надежных и адаптивных систем рассуждений, способных решать сложные проблемы в различных областях знаний.
Предложенная схема открывает возможности для создания систем рассуждений, отличающихся повышенной устойчивостью, надежностью и способностью к адаптации. В отличие от традиционных подходов, новая методика позволяет справляться со сложными задачами в различных областях, включая обработку естественного языка, решение математических задач и анализ данных. Основываясь на принципах диффузии, система демонстрирует улучшенную способность к восстановлению после ошибок и адаптации к новым условиям, что делает её особенно перспективной для применения в критически важных областях, где требуется высокая степень надежности и точности. Потенциал данной архитектуры заключается в создании интеллектуальных систем, способных эффективно функционировать в условиях неопределенности и сложности, приближая нас к созданию действительно разумных машин.
Дальнейшие исследования в области диффузионного рассуждения, вероятно, сосредоточатся на разработке инновационных методов планирования шума и алгоритмов обучения предпочтениям. Оптимизация графика добавления и удаления шума позволит более эффективно направлять процесс рассуждения, повышая точность и скорость получения результатов. Параллельно, изучение алгоритмов, способных учитывать и адаптироваться к индивидуальным предпочтениям в ответах, откроет путь к созданию систем, генерирующих более релевантные и полезные решения для конкретных задач и пользователей. Такой подход обещает существенно расширить возможности диффузионных моделей в решении сложных проблем и адаптации к разнообразным условиям.
Исследование демонстрирует, что подход DiffCoT, основанный на принципах диффузии, позволяет языковым моделям не просто генерировать цепочки рассуждений, но и итеративно корректировать ошибки, рассматривая процесс решения как глобально пересматриваемую траекторию. Этот метод напоминает философское утверждение Бертрана Рассела: «Всё, что кажется само собой разумеющимся, следует подвергать сомнению». Подобно тому, как DiffCoT пересматривает шаги рассуждений для достижения более точного результата, Рассел призывал к постоянному критическому анализу устоявшихся истин. В контексте сложных математических задач, представленных в работе, способность к самокоррекции и пересмотру траектории решения представляется ключевым фактором повышения точности и надёжности вычислений.
Куда же дальше?
Представленная работа, по сути, взламывает стандартный алгоритм рассуждений. Вместо того, чтобы слепо следовать цепочке умозаключений, модель получает возможность ретроспективно пересматривать и исправлять собственные ошибки — своего рода самокоррекция на основе принципов диффузии. Однако, возникает вопрос: насколько эта “ревизия траектории” действительно приближает к истине, или же это лишь изящный способ маскировать фундаментальные недостатки в понимании? Не превращается ли исправление ошибок в бесконечный цикл, где модель совершенствуется в искусстве самообмана?
Очевидно, что текущая реализация DiffCoT — лишь первый шаг. Необходимо исследовать, как этот подход масштабируется на более сложные задачи, требующие не только математических, но и логических, и даже креативных способностей. Ключевым направлением представляется разработка метрик, способных оценивать не только конечный результат, но и качество самого процесса рассуждения — то есть, насколько эффективно модель идентифицирует и устраняет собственные заблуждения.
В конечном счете, DiffCoT ставит под сомнение саму концепцию “разумности” искусственного интеллекта. Если интеллект — это способность к адаптации и самосовершенствованию, то эта работа демонстрирует, что даже самые сложные модели нуждаются в механизмах обратной связи и самокритики. Возможно, будущее ИИ — это не создание идеальных машин, а разработка систем, способных признавать и исправлять собственные ошибки — то есть, учиться на своих неудачах, как и любой другой исследователь, стоящий перед лицом неизвестного.
Оригинал статьи: https://arxiv.org/pdf/2601.03559.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Ядерный синтез и Искусственный Интеллект: Новый подход к проектированию реакторов
- Карта ошибок: Анатомия сбоев больших языковых моделей
- Надежность ускорителей: от замысла до реализации
- Квантовые нейросети для реалистичной 3D-визуализации
- Квантовые схемы: универсальность и сложность
- Понимание видео: новый вызов для искусственного интеллекта
- Вода под микроскопом: как машинное обучение предсказывает таяние льда
- Обучение с подкреплением: новый взгляд на самообучение
- Искуственный интеллект: хрупкость смысла в сложных задачах
- Память как у живого мозга: новый подход к локальному AI
2026-01-11 05:34