Автор: Денис Аветисян
Исследователи представили PILOT-Bench — комплексную платформу для оценки способности искусственного интеллекта рассуждать в области патентного права, ориентированную на анализ апелляций в PTAB.
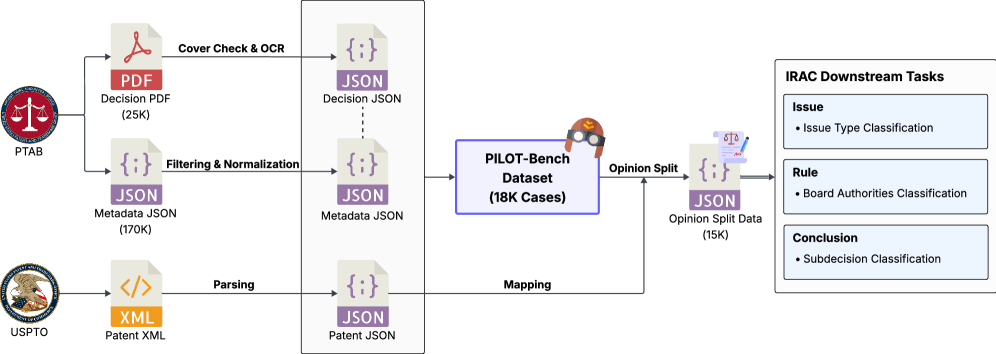
PILOT-Bench — это бенчмарк и система оценки, предназначенная для проверки навыков логического мышления больших языковых моделей при решении юридических задач в сфере патентных апелляций, с использованием структуры IRAC (Проблема-Правило-Применение-Вывод).
Несмотря на растущий интерес к применению больших языковых моделей (LLM) в юридической практике, систематической оценки их способности к структурированному правовому анализу в патентной сфере до настоящего времени не проводилось. В данной работе представлена PILOT-Bench: A Benchmark for Legal Reasoning in the Patent Domain with IRAC-Aligned Classification Tasks — первая специализированная база данных и оценочный фреймворк, предназначенные для анализа юридических рассуждений LLM в контексте апелляций, рассматриваемых Патентным советом по апелляциям и пересмотру (PTAB) в США, с акцентом на соответствие структуре IRAC (Issue-Rule-Application-Conclusion). Полученные результаты демонстрируют значительный разрыв в возможностях правового анализа между коммерческими и открытыми LLM, что ставит вопрос о перспективных направлениях разработки и обучения моделей для решения сложных юридических задач в патентной области.
Вызов юридического мышления для больших языковых моделей
Несмотря на впечатляющую способность генерировать текст, современные большие языковые модели (LLM) испытывают трудности с задачами, требующими глубокого и структурированного рассуждения, особенно в сложных правовых областях. В то время как LLM успешно справляются с имитацией языковых паттернов, их возможности по применению логики, анализу прецедентов и синтезу информации для решения правовых проблем остаются ограниченными. Эта сложность обусловлена тем, что правовые задачи требуют не просто извлечения фактов или повторения заученных правил, а способности к критическому мышлению и построению аргументации, что выходит за рамки возможностей, основанных исключительно на статистическом анализе больших объемов текста. Таким образом, хотя LLM могут казаться компетентными в обработке правовой информации, их способность к подлинному правовому рассуждению нуждается в дальнейшей разработке и оценке.
Существующие оценочные тесты для больших языковых моделей (LLM) зачастую не способны в полной мере проверить их способность применять юридические нормы к конкретным ситуациям. Это приводит к завышенной оценке реального уровня рассуждений. Многие из этих тестов сконцентрированы на простом извлечении информации или сопоставлении фактов, не требуя от модели глубокого анализа правовых принципов и их применения к сложным контекстам. В результате, LLM могут демонстрировать кажущуюся компетентность, успешно отвечая на вопросы, основанные на прямом воспроизведении заученных данных, но терпят неудачу при решении задач, требующих оригинального применения правовых норм к новым, не встречавшимся ранее сценариям. Недостаточная сложность и неадекватность существующих методик оценки препятствуют объективному определению истинных возможностей LLM в области юридического мышления и создают иллюзию более высокой производительности, чем есть на самом деле.
Особенная сложность для больших языковых моделей (LLM) представляет собой патентное право, где успешное применение закона требует не просто знания нормативных актов, но и умения анализировать сложные взаимосвязи между статутами и прецедентами. Патентные споры часто строятся на интерпретации прошлых решений и установлении их релевантности к новым изобретениям, что требует от модели способности к тонкому юридическому анализу и выстраиванию аргументации, основанной на прецедентном праве. В отличие от областей, где достаточно поиска информации в базе данных, патентное право предполагает синтез различных источников, выявление скрытых связей и прогнозирование возможных судебных решений, что выходит за рамки стандартных возможностей LLM по обработке естественного языка и требует более глубокого понимания юридических принципов.
Точное юридическое рассуждение требует не просто извлечения информации из памяти, но и способности к синтезу данных и их применению в рамках конкретной правовой системы. Иными словами, недостаточно просто знать содержание закона или прецедента; необходимо уметь сопоставлять факты дела с соответствующими нормами, выявлять релевантные принципы и применять их для разрешения конкретной юридической проблемы. Такой процесс требует от модели не только обширных знаний, но и способности к логическому анализу, абстрагированию и построению аргументированных выводов, что значительно превосходит возможности простого поиска и воспроизведения информации. Эффективное юридическое рассуждение предполагает понимание контекста, целей закона и возможных последствий применения той или иной нормы, что является сложной задачей даже для человека, не говоря уже об искусственном интеллекте.
PILOT-Bench: Новый эталон для оценки юридического мышления
PILOT-Bench — это новый эталон, разработанный для оценки способности больших языковых моделей (LLM) к юридическому мышлению, специализирующийся на контексте апелляций ex parte в Патентном совете по апелляциям и пересмотру (PTAB). В отличие от общих тестов юридической грамотности, PILOT-Bench фокусируется конкретно на задачах, возникающих в процессе апелляции, требуя от моделей анализа патентных требований, предшествующего уровня техники и аргументов сторон. Эта специализация позволяет более точно оценить способность LLM к применению юридических принципов в реальных патентных спорах, что делает PILOT-Bench ценным инструментом для оценки и совершенствования моделей искусственного интеллекта в области патентного права.
В основе PILOT-Bench лежит использование реальных данных из патентного ведомства США (USPTO), включающих материалы апелляций, представленных в Патентную апелляционную комиссию (PTAB). Это обеспечивает высокую практическую значимость и релевантность оценки возможностей больших языковых моделей (LLM) в контексте патентного права. Используемые данные включают аргументы апеллянтов, заключения экспертов и решения комиссии, что позволяет проводить оценку LLM на основе реальных юридических кейсов и сценариев, с которыми сталкиваются специалисты в данной области.
Структура задач в PILOT-Bench основана на методологии IRAC (Issue, Rule, Application, Conclusion), что требует от больших языковых моделей (LLM) демонстрации последовательного подхода к решению юридических задач. Данный подход предполагает выделение проблемы (Issue), определение применимого правила (Rule), его применение к конкретным фактам дела (Application) и формулирование логического вывода (Conclusion). Использование IRAC позволяет оценить не только способность LLM к пониманию юридических текстов, но и умение структурированно анализировать информацию и делать обоснованные заключения, имитируя процесс юридического мышления.
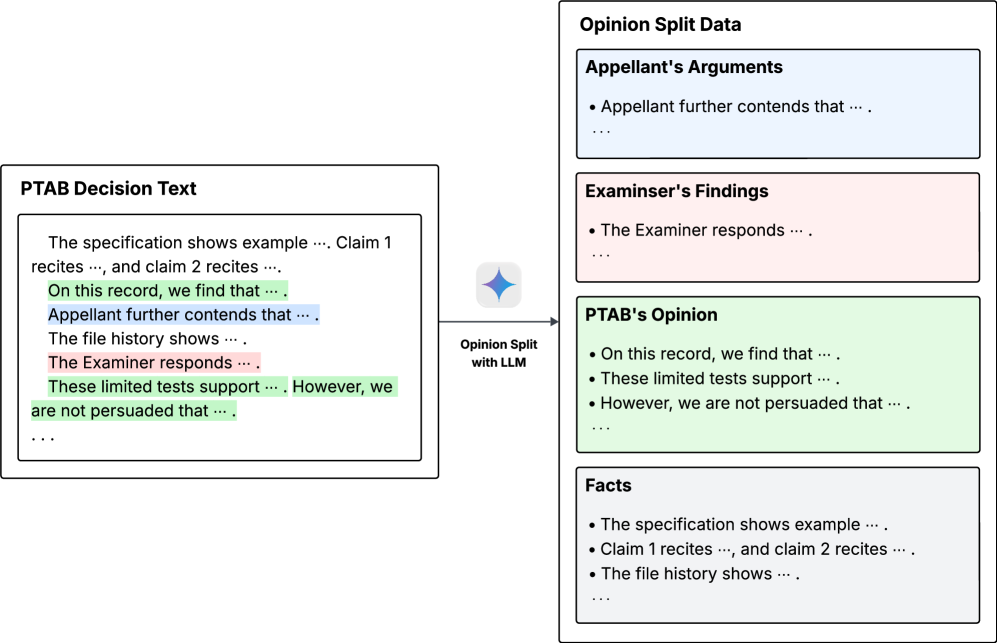
Для предотвращения утечки данных и обеспечения справедливой оценки, в PILOT-Bench реализован процесс “Разделения Мнений” (Opinion Split). Он заключается в разделении исходных материалов на три отдельные части: аргументы апеллянта, выводы эксперта и решение Палаты апелляций. Такое разделение исключает возможность для языковой модели простого воспроизведения фрагментов из уже существующих решений или аргументов, требуя от нее самостоятельного анализа и применения правовых норм к конкретным фактам. Каждая часть предоставляется модели как отдельный входной сигнал, что позволяет оценить ее способность к логическому мышлению и построению юридически обоснованных заключений, а не к простому запоминанию и воспроизведению информации.
Оценка рассуждений посредством целевых классификационных задач
PILOT-Bench включает в себя три основных классификационных задачи, предназначенных для оценки различных аспектов юридического мышления. Задача классификации типов вопросов (Issue Type Classification) направлена на определение спорных оснований, указанных в апелляционной жалобе по патентным делам, что требует понимания юридических норм. Классификация авторитетов совета (Board Authorities Classification) оценивает способность прогнозировать процессуальные нормы, цитируемые в качестве основания для решения PTAB, проверяя знание юридической практики. Задача классификации подрешений (Subdecision Classification) оценивает способность языковой модели предсказывать окончательный исход апелляции PTAB, демонстрируя комплексные возможности юридического рассуждения.
Классификация типа проблемы (Issue Type Classification) представляет собой задачу, направленную на оценку способности больших языковых моделей (LLM) определять спорные правовые основания в делах о патентных апеллях. В рамках данной задачи LLM требуется продемонстрировать понимание соответствующих патентных законов и нормативных актов, чтобы корректно идентифицировать конкретные статьи и пункты законодательства, которые являются предметом спора в рассматриваемом деле. Точность определения спорных правовых оснований служит показателем способности модели к анализу юридических текстов и пониманию сложных правовых концепций.
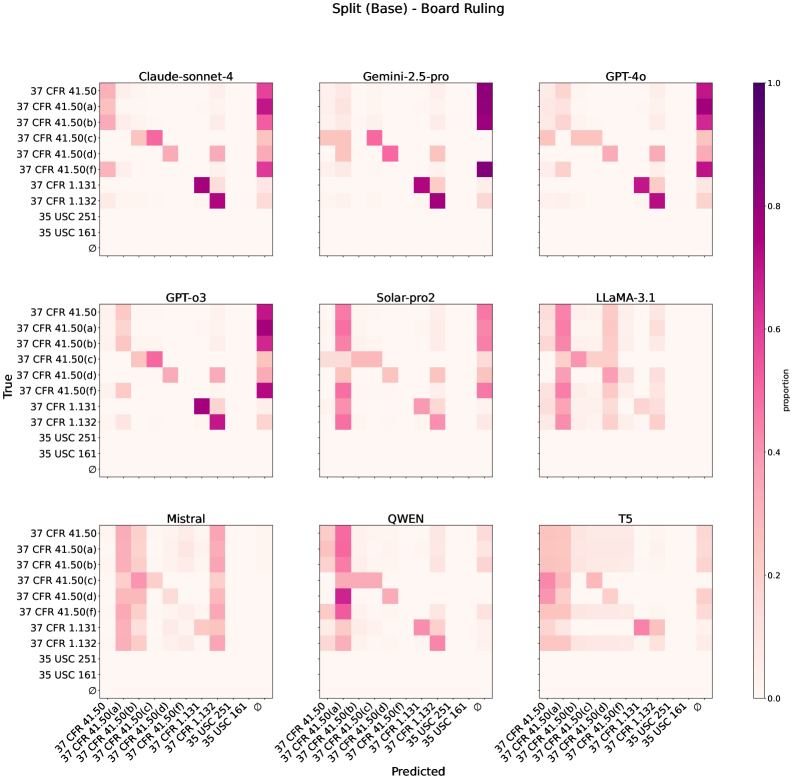
Классификация цитируемых нормативных актов (Board Authorities Classification) оценивает способность языковой модели предсказывать процессуальные нормы, на которые ссылается решение Патентной апелляционной комиссии (PTAB). Данная задача призвана проверить знание модели прецедентного права и умение соотносить конкретные обстоятельства дела с соответствующими нормативными положениями, используемыми в юридической практике PTAB. Точность прогнозирования цитируемых норм является показателем понимания моделью процедурных аспектов патентных споров и способности к юридическому анализу.
Классификация итоговых решений (Subdecision Classification) оценивает способность языковой модели предсказывать окончательный исход апелляции в Патентной апелляционной комиссии (PTAB). Эта задача требует от модели комплексного анализа представленных аргументов и доказательств, а также понимания прецедентного права и нормативных актов, регулирующих деятельность PTAB. Успешное выполнение этой классификации демонстрирует способность модели к всестороннему юридическому рассуждению и прогнозированию, что является ключевым показателем её пригодности для решения сложных юридических задач.

Метрики производительности и последствия для разработки LLM
Для оценки классификационных способностей больших языковых моделей (LLM) в рамках PILOT-Bench используется комплексный подход, включающий метрики Macro-F1 и Micro-F1. В отличие от простой точности, эти метрики позволяют получить более детальное представление о сильных и слабых сторонах моделей. Macro-F1 особенно важен при работе с несбалансированными данными, что часто встречается в юридической сфере, где одни типы правовых вопросов возникают значительно чаще других. Micro-F1, в свою очередь, учитывает общее количество правильно классифицированных примеров, предоставляя общую оценку производительности. Комбинация этих двух метрик позволяет исследователям не только определить общую эффективность модели, но и выявить области, требующие дальнейшей оптимизации и улучшения, обеспечивая более глубокое понимание её возможностей и ограничений.
В задачах классификации, особенно в юридической сфере, часто встречается дисбаланс классов — некоторые типы правовых вопросов возникают значительно чаще других. Метрика Macro-F1 играет ключевую роль в оценке производительности моделей в таких условиях, поскольку она усредняет точность и полноту по каждому классу, придавая равный вес всем категориям, независимо от их частоты. Это позволяет избежать ситуации, когда модель демонстрирует высокую общую точность за счет успешной классификации наиболее распространенных вопросов, игнорируя при этом редкие, но потенциально важные случаи. Таким образом, Macro-F1 предоставляет более объективную и информативную оценку способности модели к решению юридических задач, где учет всех типов вопросов имеет первостепенное значение.
Оценка производительности закрытых больших языковых моделей (LLM) показала, что они достигают точности совпадения (Exact Match) в диапазоне от 55 до 60% при решении задачи определения типа правовой проблемы (Issue Type). Данный показатель демонстрирует способность моделей к корректной классификации различных юридических вопросов, хотя и указывает на наличие пространства для улучшения. Точность совпадения измеряет долю случаев, когда предсказанный моделью тип проблемы полностью совпадает с фактическим, что является строгим критерием оценки, отражающим способность модели к точной идентификации ключевых аспектов правовых задач.
В ходе оценки, закрытые языковые модели продемонстрировали высокий уровень производительности в задаче определения типа проблемы, достигнув показателя Micro-F1 в 0.80. Этот результат свидетельствует о способности моделей эффективно классифицировать различные юридические вопросы, что является ключевым аспектом для автоматизации юридических процессов и поддержки специалистов. Высокий показатель Micro-F1 указывает на то, что модели не только хорошо распознают наиболее распространенные типы проблем, но и сохраняют точность при работе с менее часто встречающимися категориями, обеспечивая сбалансированную и надежную работу в различных сценариях применения.
Исследования показали, что увеличение длины входных данных в два раза за счет добавления текста обоснования может негативно сказаться на производительности языковых моделей при решении задачи определения органов, принимающих решения. Данный эффект подчеркивает критическую важность продуманного подхода к проектированию входных данных. Несмотря на потенциальные преимущества расширения контекста, чрезмерное увеличение длины запроса может привести к снижению точности, поскольку модели испытывают трудности с обработкой и анализом более объемной информации. Таким образом, оптимальная длина входных данных должна определяться экспериментально, с учетом конкретной задачи и архитектуры используемой языковой модели, для достижения наилучшего баланса между полнотой информации и производительностью.
Исследование представляет собой попытку структурировать сложную задачу юридического рассуждения в рамках бенчмарка PILOT-Bench. Подход, ориентированный на IRAC-структуру, позволяет разложить процесс анализа патентных апелляций на более управляемые компоненты. Это напоминает о важности фундаментальных принципов в построении сложных систем. Как однажды заметил Давид Гильберт: «Вся математика зиждется на логике». Подобно этому, надежная оценка юридических моделей требует четкой логической структуры и возможности последовательного применения правил к конкретным ситуациям. Бенчмарк PILOT-Bench, акцентируя внимание на структуре аргументации, стремится к созданию более прозрачной и воспроизводимой оценки способностей моделей к юридическому рассуждению.
Куда Ведет Эта Дорога?
Представленный бенчмарк PILOT-Bench, безусловно, является шагом вперед в оценке способностей больших языковых моделей к юридическому мышлению. Однако, стоит признать, что сама постановка задачи — классификация по элементам IRAC — лишь приближение к реальному процессу принятия решений. Юридическая аргументация редко предстает в столь четкой, структурированной форме; скорее, она представляет собой сложную сеть взаимосвязанных доводов, контекстуальных нюансов и неявных предположений. Очевидно, что оценка способности модели к пониманию этих нюансов, а не просто к их воспроизведению, остается открытым вопросом.
Настоящий вызов заключается не в увеличении объема данных для обучения, а в разработке метрик, способных уловить суть юридической аргументации — ее логическую последовательность, убедительность и соответствие прецедентному праву. Простая классификация по IRAC — это лишь скелет; необходима плоть и кровь — способность модели к критическому анализу, выявлению противоречий и прогнозированию исхода дела. Пока же, остается наблюдать, как эти модели успешно имитируют юридическое мышление, не обязательно его понимая.
Будущие исследования должны сосредоточиться на разработке более сложных сценариев, требующих от моделей не только извлечения информации из текста, но и применения юридических принципов к новым ситуациям. И, возможно, стоит задуматься о том, что истинная «юридическая грамотность» модели заключается не в ее способности решать юридические задачи, а в ее умении признать границы своей компетенции и обратиться к человеческому эксперту, когда это необходимо.
Оригинал статьи: https://arxiv.org/pdf/2601.04758.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Ядерный синтез и Искусственный Интеллект: Новый подход к проектированию реакторов
- Надежность ускорителей: от замысла до реализации
- Карта ошибок: Анатомия сбоев больших языковых моделей
- Квантовые нейросети для реалистичной 3D-визуализации
- Роботы учатся на собственном опыте: новый подход к обучению с подкреплением
- Искуственный интеллект: хрупкость смысла в сложных задачах
- Понимание видео: новый вызов для искусственного интеллекта
- Искусственный интеллект или ловкость рук? Как языковые модели обходят правила в программировании
- Квантовые вихри в графеновой спирали
- Диффузия и обучение с подкреплением: новый подход к масштабированию
2026-01-11 10:45