Автор: Денис Аветисян
Новая платформа позволяет масштабировать модели, объединяющие зрение и язык, для глубокого понимания длинных видеороликов в фармацевтической отрасли.
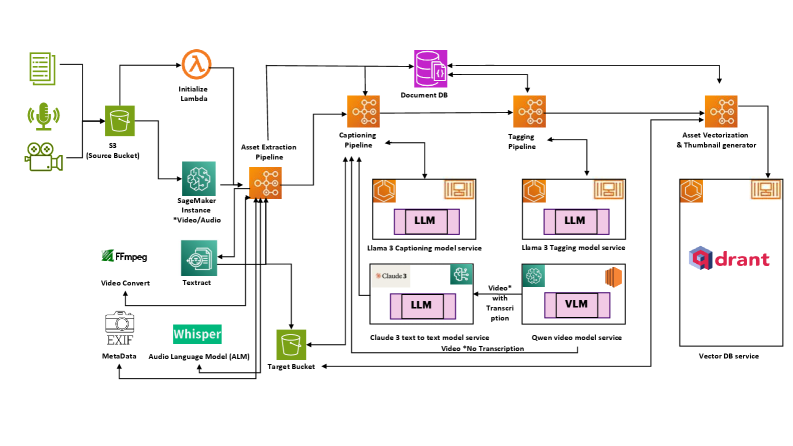
Исследование посвящено масштабированию мультимодальных моделей для анализа видеоданных в промышленном масштабе и решению задач временной синхронизации.
Несмотря на успехи моделей, объединяющих зрение и язык, их масштабирование для обработки длинных видео в промышленных условиях остается сложной задачей. В работе ‘Scaling Vision Language Models for Pharmaceutical Long Form Video Reasoning on Industrial GenAI Platform’ представлен промышленный GenAI фреймворк для анализа фармацевтических видео, включающий более 25 тысяч видеофайлов и 888 аудиозаписей на 20 языках. Исследование выявило ключевые факторы, влияющие на эффективность обработки длинных видео, такие как роль мультимодальности, выбор механизма внимания и ограничения по временной синхронизации. Какие практические решения позволят преодолеть эти ограничения и создать масштабируемые мультимодальные системы для промышленного анализа видеоконтента?
Погоня за мультимодальностью: от теории к практике
Традиционные системы искусственного интеллекта, как правило, демонстрируют высокую эффективность при работе с данными одного типа — будь то текст, изображения или звук. Однако, реальный интеллект, присущий человеку, базируется на одновременной обработке и интеграции информации, поступающей по различным каналам восприятия. Способность комбинировать визуальные данные с текстовым описанием, звуковые сигналы с тактильными ощущениями — это фундаментальная характеристика разумного поведения. Поэтому, для создания действительно интеллектуальных систем, способных к полноценному взаимодействию с окружающим миром, необходимо преодолеть ограничения одномодального подхода и перейти к моделям, способным эффективно обрабатывать и объединять разнородные входные данные.
Визуально-языковые модели (ВЯМ) стремительно становятся ключевой технологией, позволяющей машинам не просто распознавать изображения, но и понимать их содержание, подобно человеческому восприятию. Эти модели объединяют возможности компьютерного зрения и обработки естественного языка, что позволяет им анализировать визуальную информацию и сопоставлять ее с текстовыми описаниями. В результате, машины приобретают способность «видеть» и «понимать» окружающий мир, интерпретируя сложные сцены, объекты и действия. Данный подход открывает широкие возможности для автоматизации задач, требующих понимания визуального контекста, таких как анализ видеоконтента, создание автоматических подписей к изображениям и разработка интеллектуальных систем наблюдения.
Обработка длинных видеофрагментов представляет собой серьезную вычислительную задачу для современных мультимодальных моделей, в частности, моделей «зрение-язык». Традиционные подходы требуют значительных временных затрат на анализ и интерпретацию визуального контента. Однако, разработанная платформа генеративного искусственного интеллекта позволяет существенно оптимизировать этот процесс. Согласно проведенным исследованиям, платформа демонстрирует снижение трудозатрат на обработку длинных видео на 94.4% по сравнению с ручной инспекцией, что эквивалентно экономии 252.5 часов рабочего времени. Это достигается за счет оптимизации алгоритмов и эффективного использования вычислительных ресурсов, позволяя более оперативно извлекать полезную информацию из видеоданных и повышать общую производительность анализа.
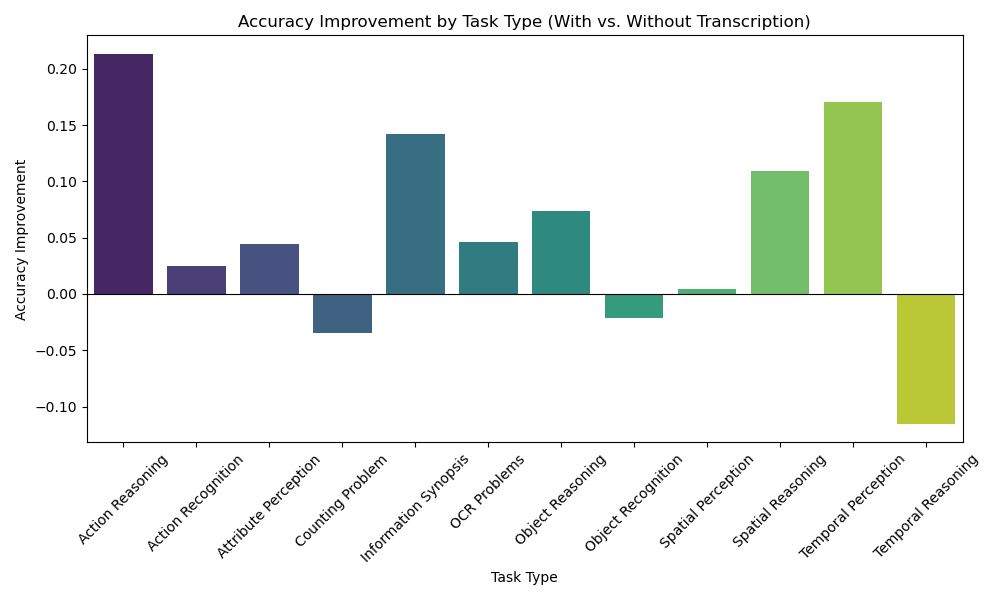
Оптимизация производительности VLM: вычислительные стратегии
Эффективные механизмы внимания, такие как FlashAttention и FlashAttention-2, играют ключевую роль в снижении потребления памяти и ускорении обучения видео-языковых моделей (VLM). Традиционные механизмы внимания требуют хранения промежуточных результатов в памяти, что становится узким местом при обработке длинных видеопоследовательностей. FlashAttention и FlashAttention-2 оптимизируют процесс вычисления внимания, переупорядочивая вычисления и минимизируя количество операций чтения/записи в память. Это достигается за счет использования тайлового подхода и повторного вычисления некоторых значений, что позволяет существенно сократить потребление памяти и увеличить скорость обучения, особенно при работе с большими объемами данных и высокими разрешениями видео.
Для обработки длинных видеофайлов в задачах анализа видео с использованием больших визуальных моделей (VLM) применяются методы разделения видео и сжатия. Разделение видео предполагает его фрагментацию на более короткие, управляемые сегменты, что снижает требования к объему памяти и вычислительным ресурсам. Сжатие видео, в свою очередь, уменьшает размер каждого сегмента, дополнительно оптимизируя процесс обработки. Комбинация этих техник позволяет VLM эффективно анализировать видеофайлы большой продолжительности, не сталкиваясь с ограничениями по памяти или времени обработки.
Использование мощных графических процессоров, таких как NVIDIA A100, является критически важным для ускорения обучения и инференса видео-языковых моделей (VLM). На платформе AWS EC2 g5.24xlarge, модель Qwen-7B демонстрирует время обработки одного видео в 1 минуту, в то время как Gemini-2-Flash требует 3 минуты. Эти показатели подтверждают значительное увеличение скорости обработки видео при использовании специализированного аппаратного обеспечения для задач VLM.
Оптимизации, реализованные в нашей системе, позволили добиться снижения времени обработки видео на 88% по сравнению с ручным просмотром. Данное улучшение достигается за счет комбинации эффективных вычислительных стратегий, включая оптимизированные механизмы внимания и методы разделения и сжатия видеоданных. В результате, время, необходимое для анализа видеоматериалов, значительно сокращается, что повышает эффективность и масштабируемость процессов, связанных с обработкой видеоинформации.
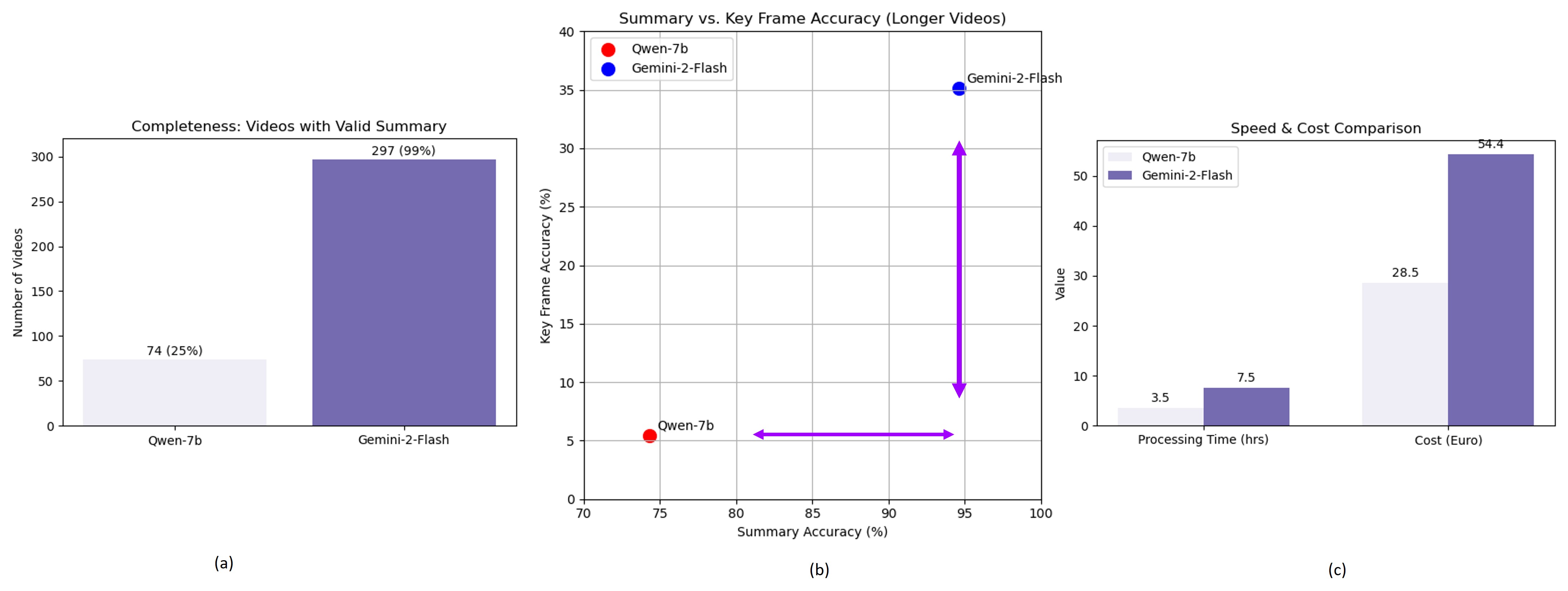
Расширение возможностей VLM: данные и рассуждения
Интеграция дополнительных источников данных, таких как расшифровки аудио и субтитры, значительно повышает способность видео-языковой модели (VLM) к пониманию видеоконтента. Аудио- и текстовая информация дополняют визуальные данные, предоставляя VLM контекст и детали, которые могут быть не очевидны только из видеоряда. Это особенно важно для понимания речи, идентификации объектов, невидимых в кадре, и интерпретации сложных сценариев. Использование этих дополнительных данных позволяет модели более точно извлекать информацию из видео, улучшая её способность отвечать на вопросы, генерировать описания и выполнять другие задачи, связанные с анализом видеоконтента.
Использование метаданных значительно расширяет контекстуальное понимание видеомодели (VLM), позволяя ей более точно интерпретировать визуальные сцены. Метаданные, такие как временные метки, описание сцены, информация об актерах и объектах, предоставляют VLM дополнительную информацию, недоступную непосредственно из визуального контента. Это позволяет модели связывать визуальные данные с более широким контекстом, улучшая точность распознавания объектов, понимание действий и общую интерпретацию видео. В частности, метаданные могут помочь VLM разрешать неоднозначность в визуальных сценах и более эффективно обрабатывать сложные или необычные ситуации.
Современные видео-языковые модели (VLM), такие как Gemini Pro и Qwen-VL, демонстрируют передовые результаты на различных мультимодальных бенчмарках, в частности MMBench. Эта платформа позволяет оценить способность моделей к комплексному анализу видео- и текстовой информации. Результаты тестов на MMBench показывают, что данные модели превосходят предыдущие поколения VLMs в задачах, требующих понимания взаимосвязей между визуальным и текстовым контентом, включая ответы на вопросы, визуальное обоснование и генерацию описаний видео.
Результаты экспериментов демонстрируют повышение точности работы видео-языковых моделей (VLM) при использовании мультимодальной интеграции данных. В среднем, точность увеличилась на 3.9% для видеороликов различной длительности. Наиболее заметный прирост точности наблюдается для длинных видео — 7.9%, а также для видео средней длительности — 5.0%. Данные показатели подтверждают эффективность использования дополнительных модальностей данных для улучшения понимания видеоконтента VLM.
Способность к рассуждению на основе ключевых кадров является критически важной для видео-языковых моделей (VLM). Вместо обработки всего видеопотока, VLM, обладающие данной способностью, выделяют и анализируют наиболее значимые моменты, представленные в виде ключевых кадров. Это позволяет значительно снизить вычислительную нагрузку и повысить эффективность анализа, особенно при работе с длинными видеороликами. Выделение ключевых кадров обеспечивает фокусировку на релевантной информации, что улучшает точность и скорость ответов модели на вопросы о содержании видео.
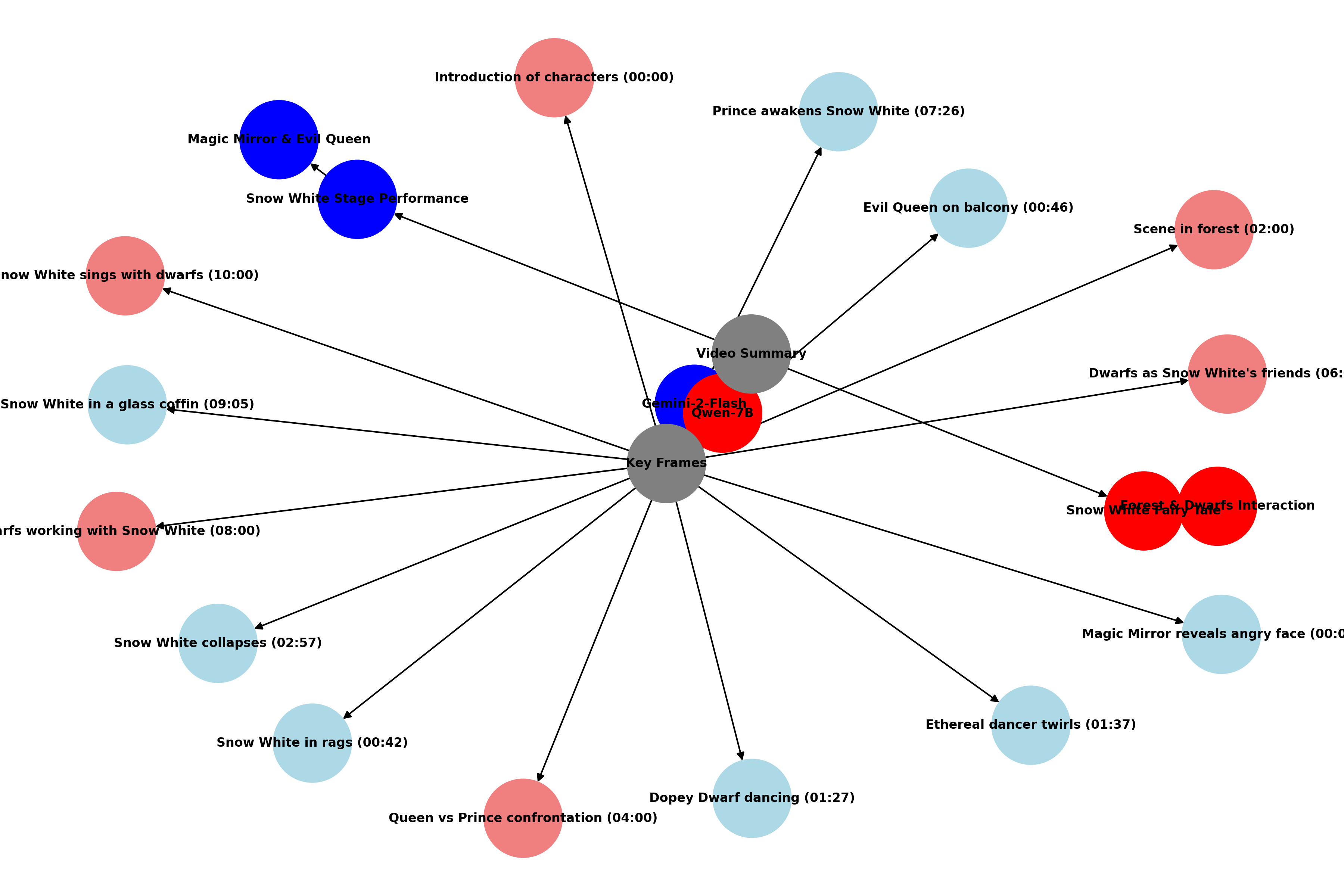
Подтверждение и оценка производительности VLM
Для обеспечения объективной оценки прогресса в области видео-языковых моделей (VLM) необходимы стандартизированные бенчмарки. Такие платформы, как Video-MME, предоставляют тщательно отобранные наборы данных и метрики, позволяющие сравнивать различные модели по ключевым задачам видеопонимания, таким как распознавание действий, ответы на вопросы о видео и генерация описаний. Использование таких бенчмарков позволяет исследователям не только отслеживать улучшения в производительности, но и выявлять слабые места существующих моделей, направляя дальнейшие разработки в сторону более эффективных и надежных систем анализа видеоинформации. Без строгой, количественной оценки, прогресс в этой области оставался бы субъективным и затруднительным для воспроизведения.
Для повышения точности анализа видеоданных и автоматической генерации их кратких описаний, а также выбора наиболее значимых ключевых кадров, всё чаще применяются графы знаний. Эти структуры позволяют представить информацию, извлеченную из видео, в виде взаимосвязанных сущностей и отношений между ними. Вместо обработки необработанного видеопотока, алгоритмы работают с организованным представлением данных, что существенно повышает эффективность и позволяет выявлять скрытые закономерности. Например, граф знаний может отразить, что «человек» выполняет «действие» с «объектом» в «месте», что позволяет системе не просто распознать элементы на кадре, но и понять контекст происходящего. Такая организация информации открывает новые возможности для создания более осмысленных и информативных резюме видеоконтента, а также для точного определения ключевых моментов, заслуживающих внимания.
Несмотря на использование более стандартизированного оборудования, такого как NVIDIA A10G, оптимизированные видео-языковые модели (VLM) демонстрируют впечатляющие результаты в задачах анализа видеоданных. Это свидетельствует о том, что ключевым фактором высокой производительности является не только вычислительная мощность, но и эффективность архитектуры модели и алгоритмов оптимизации. Исследования показывают, что тщательно настроенные VLM способны эффективно использовать ресурсы даже относительно скромного оборудования, обеспечивая высокую точность распознавания объектов, понимания действий и формирования связных описаний видеоконтента. Такой прогресс открывает возможности для широкого внедрения VLM в различные приложения, от автоматического монтажа видео до систем видеонаблюдения и помощи в обучении, делая передовые технологии анализа видео доступнее для более широкого круга пользователей и разработчиков.
Механизм Scaled Dot-Product Attention продолжает оставаться ключевым элементом в архитектурах современных видео-языковых моделей (VLM). Этот подход позволяет эффективно обрабатывать последовательности видеокадров, выделяя наиболее релевантные признаки и устанавливая взаимосвязи между ними. В основе Scaled Dot-Product Attention лежит вычисление весов внимания, определяющих вклад каждого кадра в конечное представление видео. Благодаря этому, модели способны фокусироваться на важных деталях, игнорируя несущественный шум, что критически важно для задач видеопонимания. Attention(Q, K, V) = softmax(\frac{QK^T}{\sqrt{d_k}})V — данная формула демонстрирует принцип работы механизма, где Q, K и V представляют собой запросы, ключи и значения соответственно, а d_k — размерность ключей. Постоянное совершенствование и оптимизация Scaled Dot-Product Attention, в сочетании с другими передовыми технологиями, обеспечивает повышение производительности и точности VLMs в различных приложениях, таких как видео-классификация, обнаружение объектов и генерация описаний видео.
Эта работа, посвященная масштабированию Vision-Language Models для обработки длинных фармацевтических видео, неизбежно столкнется с проблемой «техдолга». Авторы, конечно, увлечены вниманием к мультимодальности и временной синхронизации, но можно предположить, что в продакшене найдется способ сломать любую, даже самую элегантную архитектуру. Как метко заметила Фэй-Фэй Ли: «Искусственный интеллект должен помогать людям, а не заменять их». И это не просто гуманистический призыв, а суровая реальность: система, которая не учитывает человеческий фактор и не предусматривает возможность отладки, обречена на провал. Документация, как всегда, будет оптимистичной, но реальность внесет свои коррективы, и тогда станет ясно, что «если баг воспроизводится — значит, у нас стабильная система».
Что дальше?
Представленная работа, безусловно, демонстрирует возможность масштабирования мультимодальных моделей для анализа фармацевтических видеоданных. Однако, не стоит забывать, что любая “бесконечная масштабируемость” — это лишь вопрос времени и ресурсов, пока не возникнет новая узкая точка. Проблемы временной синхронизации и эффективной работы механизмов внимания в длинных видеорядах — это не новые вызовы. Вспомните аналогичные дискуссии о рекуррентных сетях в 2015-м. Все красиво работало на демонстрационных примерах, а потом наступил продакшен.
Более того, возникает вопрос: действительно ли фармацевтическая индустрия нуждается в столь сложной аналитике видео? Или же достаточно простых, но надёжных алгоритмов, которые не требуют колоссальных вычислительных мощностей? Часто бывает, что элегантное решение, которое «точно взлетит», оказывается непрактичным из-за банальной стоимости владения. Если тесты показывают зелёный свет, это, скорее всего, означает, что они вообще ничего не проверяют.
В перспективе, вероятно, стоит обратить внимание не столько на усложнение архитектур, сколько на разработку методов интерпретируемости и верификации. Важно понимать, почему модель принимает то или иное решение, особенно в критически важных областях, таких как фармацевтика. В противном случае, все эти сложные системы станут просто дорогими чёрными ящиками, которые рано или поздно дадут сбой.
Оригинал статьи: https://arxiv.org/pdf/2601.04891.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Карта ошибок: Анатомия сбоев больших языковых моделей
- Надежность ускорителей: от замысла до реализации
- Квантовые нейросети для реалистичной 3D-визуализации
- От основ к интеллекту: как объединить машинное обучение и большие языковые модели
- Оптимизация запросов: Новый подход для сложных рабочих процессов
- Квантовые нейросети: на пути к скорости и точности
- Роботы учатся на собственном опыте: новый подход к обучению с подкреплением
- Искусственный интеллект как ученый: новый подход к научному познанию
- Адаптивное обучение в условиях неопределенности: новый подход к управлению рисками
- Искуственный интеллект: хрупкость смысла в сложных задачах
2026-01-11 15:44