Автор: Денис Аветисян
Новая модель машинного обучения позволяет эффективно восстанавливать неполные матрицы попарных сравнений, обеспечивая высокую точность и масштабируемость.
Предлагается подход на основе графового обучения для завершения разреженных матриц попарных сравнений с обеспечением мультипликативной согласованности.
Неполные матрицы попарных сравнений часто представляют собой серьезную проблему в задачах ранжирования и принятия решений. В данной работе, посвященной ‘Machine Learning Model for Sparse PCM Completion’, предложена масштабируемая модель машинного обучения для восстановления разреженных матриц попарных сравнений, сочетающая в себе классические подходы с методами обучения на графах. Ключевым результатом является достижение баланса между точностью восстановления и вычислительной эффективностью за счет использования графовых представлений и обеспечения мультипликативной согласованности. Позволит ли данная методика расширить возможности анализа данных в задачах, где важна оценка относительных предпочтений и согласованность суждений?
Основы сравнений: от выбора к ранжированию
Во многих задачах, с которыми сталкиваются специалисты в различных областях — от выбора инвестиционных проектов до оценки эффективности стратегий — необходимо ранжировать альтернативные варианты. Для формализации этого процесса часто используются матрицы попарных сравнений (PCM). В основе подхода лежит сопоставление каждого варианта с каждым другим, что позволяет выявить относительную важность одного перед другим. Такой метод позволяет структурировать сложный процесс принятия решений, переводя субъективные оценки в количественную форму, удобную для анализа и дальнейшей обработки. A_{ij} — элемент матрицы, отражающий предпочтение варианта i над вариантом j, и позволяет построить целостную систему оценки, учитывающую множество факторов и экспертных мнений.
Иерархический анализ процессов (ИЯП), или Analytic Hierarchy Process (AHP), представляет собой широко признанный и эффективный метод структурирования сложных задач принятия решений. В основе ИЯП лежит декомпозиция проблемы на иерархию критериев и альтернатив, позволяющая систематически оценивать и сравнивать различные варианты. Метод использует матрицы попарных сравнений PCM, где эксперты выражают предпочтения между альтернативами по каждому критерию. Эти оценки затем обрабатываются для вычисления приоритетов и, в конечном итоге, определения наиболее предпочтительного решения. Благодаря своей гибкости и способности учитывать субъективные суждения, ИЯП успешно применяется в самых разнообразных областях — от управления проектами и оценки рисков до выбора стратегий и распределения ресурсов.
Получение полных матриц попарных сравнений (МПС) зачастую представляет собой значительную проблему в процессе принятия решений. Практическая реализация требует от экспертов оценки каждого возможного сочетания альтернатив, что может быть трудоемким, особенно при большом количестве вариантов. Неполнота МПС, или её разреженность, возникает из-за нехватки времени, усталости экспертов или отсутствия четких предпочтений. Такая разреженность может приводить к неточностям в итоговой ранжировке альтернатив, искажая результаты анализа и снижая надежность принимаемых решений. Поэтому, разработка методов обработки и восстановления неполных МПС является важной задачей для повышения практической применимости и точности методов, использующих попарные сравнения.
Преодоление неполноты: традиционные и современные подходы
Метод наименьших квадратов в логарифмической форме (Log Least Squares, LLS) представляет собой традиционный подход к восстановлению полных матриц парных сравнений (PCM) на основе разреженных данных. Он предполагает, что разница между наблюдаемыми и предсказанными значениями парных сравнений минимизируется в логарифмической шкале. Несмотря на свою простоту и вычислительную эффективность, LLS может неточно отражать истинные предпочтения, особенно при значительной степени разреженности данных или наличии сложных взаимосвязей между оцениваемыми объектами. Это связано с тем, что метод не учитывает вероятностную природу парных сравнений и не позволяет оценить степень неопределенности в полученных оценках. В результате, восстановленные PCM могут содержать систематические искажения, влияющие на качество принимаемых решений.
Вероятностные модели, такие как модель Брэдли-Терри-Люсь (BTL), предоставляют статистически обоснованный подход к оценке скрытых (латентных) оценок на основе парных сравнений. В рамках этой модели, вероятность того, что объект A будет предпочтен объекту B, определяется функцией от разницы между их латентными оценками \hat{\theta}_A и \hat{\theta}_B . Оценка параметров модели производится с использованием методов максимального правдоподобия, что позволяет получить количественную оценку предпочтений и ранжировать объекты на основе вычисленных латентных оценок. Данный подход обеспечивает более надежные и интерпретируемые результаты по сравнению с некоторыми традиционными методами, особенно при работе с неполными данными.
Оценка надежности парных матриц сравнений (PCM) является критически важной для обеспечения валидности полученных результатов. Для этой цели широко используются два основных показателя: Индекс согласованности (CI) и Коэффициент согласованности (CR). CI = \frac{\sum_{i=1}^{n} (a_{ij} - \frac{1}{n-1}\sum_{k=1}^{n} a_{ik})}{(n-1)\sqrt{\frac{1}{n-1}\sum_{i=1}^{n} (\sum_{j=1}^{n} a_{ij})^2 - (\sum_{i=1}^{n} \sum_{j=1}^{n} a_{ij})^2/(n^2)}}, где a_{ij} — элемент матрицы PCM, а n — размер матрицы. CR, в свою очередь, рассчитывается как отношение CI к случайной согласованности (RI), полученной из таблиц случайных оценок. Значения CR, близкие к нулю, указывают на высокую степень согласованности и надежности PCM, в то время как высокие значения свидетельствуют о значительной случайности и требуют пересмотра данных или модели.
Машинное обучение для расширения возможностей PCM
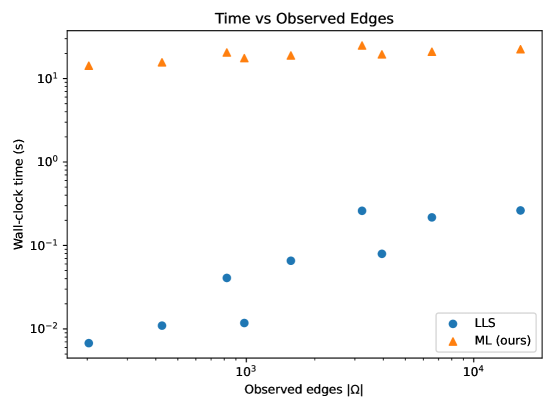
Предлагается новая модель машинного обучения (ML), разработанная специально для завершения разреженных парных матриц сравнения (PCM). Ключевой особенностью является вычислительная сложность, достигающая O(|Ω|log n) на эпоху, где |Ω| представляет количество элементов в разреженной PCM, а n — общее количество альтернатив. Такая сложность позволяет эффективно обрабатывать большие объемы данных по сравнению с традиционными методами, требующими обработки плотных матриц и, следовательно, имеющими более высокую вычислительную нагрузку. Данный подход позволяет значительно сократить время обработки и повысить масштабируемость алгоритма при работе с крупномасштабными PCM.
Модель использует векторные представления (embeddings) для кодирования альтернатив в пространстве меньшей размерности. Такой подход позволяет захватить сложные взаимосвязи между альтернативами, представляя их как точки в этом векторном пространстве. Каждая альтернатива отображается в ℝ^d, где d значительно меньше количества альтернатив, что снижает вычислительную сложность и позволяет эффективно моделировать предпочтения и зависимости между элементами. Близость векторов в этом пространстве отражает степень сходства или взаимозаменяемости соответствующих альтернатив, обеспечивая компактное и информативное представление данных для последующего анализа и завершения разреженных матриц парных сравнений (PCM).
Ключевым компонентом предложенной модели является функция потерь Triangle Loss, предназначенная для обеспечения мультипликативной согласованности в рамках PCM (Pairwise Comparison Matrix). Функция штрафует нарушения неравенства треугольника, которое гласит, что для любых трех альтернатив i, j и k должно выполняться условие: pref(i,k) ≥ pref(i,j) + pref(j,k), где pref(i,j) представляет собой предпочтение альтернативы i над альтернативой j. Нарушение этого неравенства указывает на несогласованность в предпочтениях и приводит к увеличению значения функции потерь, тем самым направляя процесс обучения модели к построению согласованной PCM.
Модель использует графовую нейронную сеть (GNN) для эффективного распространения информации по графу парных сравнений, что позволяет значительно ускорить процесс завершения разрешенных PCМ. Экспериментальные данные показывают, что на больших масштабах (n=1000) модель обеспечивает прирост скорости в 5-20 раз по сравнению с традиционными плотными методами. GNN эффективно агрегирует информацию от соседних узлов в графе, что позволяет модели учитывать взаимосвязи между альтернативами и повышать точность прогнозов при завершении разрешенных PCМ.
Ранжирование альтернатив: за пределами простого завершения
После завершения построения парных матриц сравнения (PCM), становится возможным применение передовых методов ранжирования, таких как Rank Centrality. Данный подход использует анализ на основе марковских цепей для определения значимости каждого элемента в наборе. По сути, Rank Centrality рассматривает процесс сравнения как случайное блуждание по графу, где узлы — это сравниваемые объекты, а вероятности переходов определяются значениями в PCM. Чем чаще «посетитель» возвращается к определенному узлу, тем выше его центральность и, следовательно, его ранг. Такой подход позволяет выявить не только наиболее предпочтительные варианты, но и установить иерархию между ними, учитывая взаимосвязи и косвенные сравнения, что существенно расширяет возможности анализа по сравнению с простым ранжированием на основе явных предпочтений.
Метод Serial Rank предлагает альтернативный подход к ранжированию, основанный на спектральной релаксации и использовании вектора Фидлера. Этот подход позволяет эффективно вычислять ранги элементов, рассматривая матрицу смежности графа и находя ее главный собственный вектор — вектор Фидлера. Вместо прямого вычисления рангов, Serial Rank преобразует задачу в задачу решения системы линейных уравнений, что значительно ускоряет процесс, особенно для больших графов. Спектральная релаксация, в данном случае, позволяет сгладить шум и получить более стабильные и надежные ранги, что делает метод особенно полезным в ситуациях, когда данные неполны или содержат ошибки. \textbf{v}_1 — вектор Фидлера, является первым собственным вектором матрицы Лапласа графа, и его компоненты используются в качестве рангов узлов.
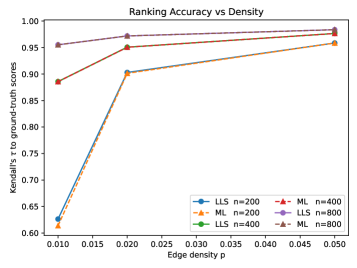
Для оценки эффективности разработанных методов ранжирования использовались синтетические данные, полученные на основе графов Эрдеша-Реньи, что позволило провести контролируемые эксперименты и исключить влияние случайных факторов. Результаты показали, что среднеквадратичная ошибка (RMSE) на отложенных парах не превышает 0.01 ± 0.002, что сопоставимо с показателями базовой модели LLS. Такая высокая точность указывает на потенциал предложенных алгоритмов для решения задач ранжирования в различных областях, где требуется надежная и эффективная оценка альтернатив.
Исследование, представленное в данной работе, демонстрирует, что даже в условиях разреженных матриц парных сравнений, возможно достижение высокой точности завершения, используя возможности графового обучения. Этот подход особенно ценен, поскольку позволяет балансировать между вычислительной эффективностью и качеством получаемых результатов. Как однажды заметил Анри Пуанкаре: «Математика — это искусство дать верное определение». В контексте данной работы, это означает, что правильно определенная структура графа и алгоритм завершения матрицы являются ключом к успешному решению задачи. Особенно важно, что модель обеспечивает согласованность результатов, что критически важно для сохранения целостности и достоверности рейтингов, формируемых на основе этих данных.
Куда Ведет Этот Путь?
Представленная работа, стремясь к завершению разреженных матриц попарных сравнений, неизбежно сталкивается с фундаментальным вопросом: насколько долго любое улучшение в этой области сможет противостоять энтропии? Любой алгоритм, даже самый элегантный, подвержен старению, а его эффективность — лишь временное состояние. Использование графовых представлений и обеспечение мультипликативной согласованности — это лишь попытка замедлить неизбежное, отсрочить момент, когда новые данные потребуют пересмотра всей структуры.
Очевидным направлением дальнейших исследований представляется разработка моделей, способных не просто завершать матрицы, но и оценивать степень их изменчивости во времени. Необходимо учитывать, что ранг матрицы, как и любая другая метрика, — это лишь снимок в определенный момент времени. Истинная задача заключается в построении систем, способных адаптироваться к изменяющимся условиям, предсказывать будущие изменения и, возможно, даже предвидеть моменты, когда полная перестройка матрицы становится неизбежной.
Откат к более простым моделям, потеря точности — это не провал, а скорее путешествие назад по стрелке времени, возвращение к более устойчивым, хотя и менее детализированным представлениям. Важно помнить, что совершенство — это иллюзия, а достойное старение — единственный реальный критерий оценки любой системы. Поиск баланса между точностью и устойчивостью — вот истинный вызов, стоящий перед исследователями в этой области.
Оригинал статьи: https://arxiv.org/pdf/2601.04366.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Карта ошибок: Анатомия сбоев больших языковых моделей
- Надежность ускорителей: от замысла до реализации
- Квантовые нейросети для реалистичной 3D-визуализации
- Квантовые сети под контролем: новая библиотека для моделирования гибридных схем
- Оптимизация запросов: Новый подход для сложных рабочих процессов
- Когда Больше – Не Значит Лучше: О Ловушках Улучшения Рассуждений Искусственного Интеллекта
- DanQing: Новый масштаб для китайского искусственного интеллекта
- Нейросеть предсказывает сродство антител к COVID-19
- Накапливая опыт: мультимодальные агенты, которые учатся на ходу
- Квантовый щит для искусственного интеллекта
2026-01-11 20:49