Автор: Денис Аветисян
Все мы давно привыкли к тому, что увеличение контекстного окна больших языковых моделей неизбежно влечёт за собой квадратичный рост вычислительных затрат – и смирились с этим как с неизбежностью. Но, когда появляется работа вроде “Adamas: Hadamard Sparse Attention for Efficient Long-Context Inference”, предлагающая решить проблему, не просто оптимизируя существующие подходы, а переосмысливая саму структуру внимания, возникает вопрос: а не является ли эта кажущаяся простотой идея всего лишь очередной красивой математической абстракцией, оторванной от суровой реальности ограниченных ресурсов и реальных требований к скорости?
Когда «Революция» Начинает Задыхаться
Большие языковые модели (LLM) стали фундаментом современной обработки естественного языка. Но знаете ли вы, что эта самая «революционная» технология, как ни странно, начинает сдавать позиции при увеличении длины входной последовательности? И не надо рассказывать про «масштабирование» – рано или поздно все упирается в ресурсы. И вот, когда мы пытаемся заставить эти модели работать с действительно длинными документами или сложными диалогами, проявляется старая проблема – квадратичная сложность механизма внимания. Вроде бы, все просто: чем больше токенов, тем больше вычислений. Но кто-то же обещал нам «бесконечный контекст»?
Традиционные механизмы внимания, конечно, мощные. Но, как и все элегантные решения, они не выдерживают столкновения с реальностью. Квадратичная сложность означает, что вычислительные затраты и потребление памяти растут пропорционально квадрату длины последовательности. Помните, как в старой поговорке говорится: «Хорошо там, где нас нет»? Так и здесь: чем длиннее контекст, тем сложнее и дороже его обработать. Это, в свою очередь, ограничивает возможности LLM в решении задач, требующих глубокого понимания больших объемов текста или сложных диалогов. Как говорится, «все новое – это просто старое с худшей документацией».
И вот мы получаем ситуацию, когда LLM не могут эффективно рассуждать над длинными документами или сложными диалогами. Это, в свою очередь, негативно сказывается на производительности в задачах, требующих глубокого понимания контекста. Вспомните, как в Agile говорили про «быструю итерацию». Все работало, пока не пришёл Agile. Так и здесь: все обещали «революцию», а в итоге получили очередную проблему, которую нужно решать. И, знаете, иногда кажется, что DevOps – это когда инженеры смирились с тем, что проблемы никогда не закончатся.
Adamas: Очередная Попытка Выжать Максимум
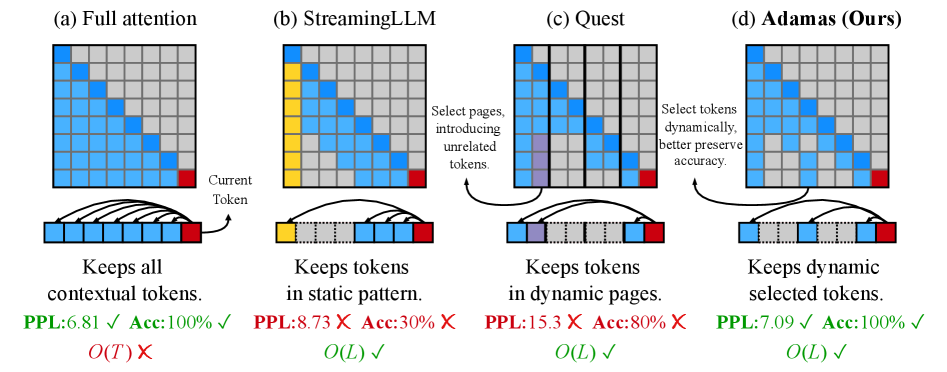
Разработчики, видимо, снова решили усложнить себе жизнь. В погоне за контекстным окном, они предлагают Adamas – новый механизм разреженного внимания. Ну, как новый… Скорее, очередную попытку выжать производительность из железа, которое всё равно рано или поздно сгорит. Но, признаюсь, подход интересный. Они утверждают, что используют преобразование Адамара, чтобы как бы «перераспределить дисперсию» и снизить вычислительные затраты. Звучит красиво, но, поверьте, в продакшене всё немного иначе.
Суть в том, что Adamas не просто отбрасывает лишние токены, а пытается сделать это умно. Ключевым элементом является так называемое «разбиение на группы» – своего рода квантование, которое сжимает векторы после преобразования Адамара. Идея, в принципе, не нова, но в данном случае, они утверждают, что это позволяет ещё больше повысить эффективность. Всё это, конечно, хорошо, но главное – чтобы не усложнило поддержку.
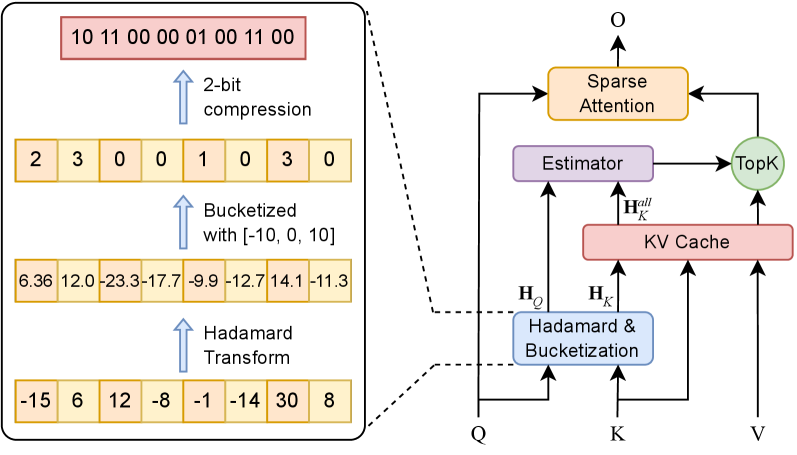
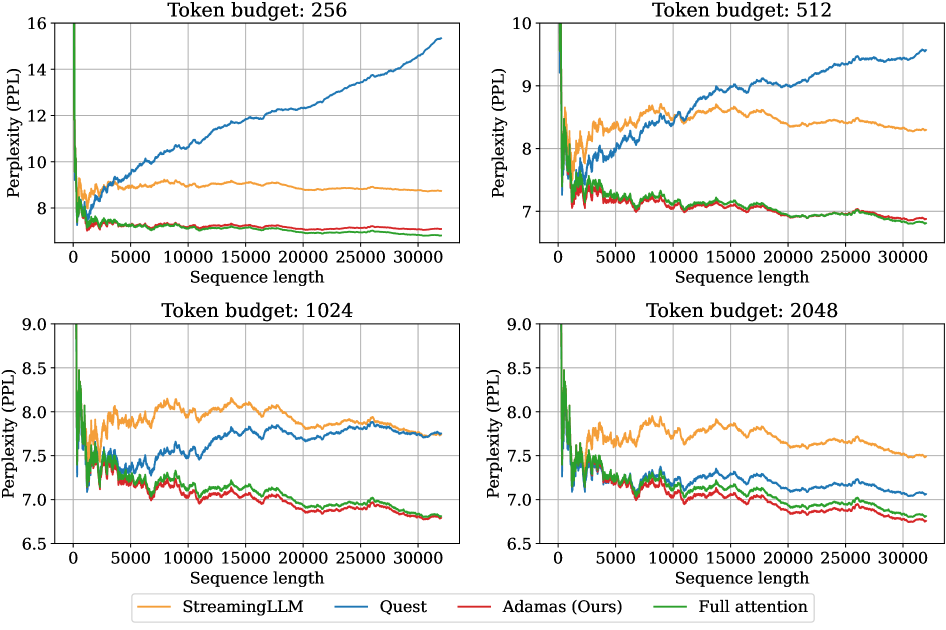
Для оценки похожести между токенами в этом сжатом пространстве используется, как они говорят, «оценщик расстояния Манхэттена». Ну, хорошо, пусть будет Манхэттен. Главное, чтобы не пришлось потом отлаживать всю эту математику в три часа ночи. Этот подход, по их словам, позволяет Adamas масштабироваться до значительно более длинных контекстов, чем традиционные механизмы внимания. Что ж, посмотрим, как это проявится в реальной жизни. В конце концов, всё, что можно задеплоить – однажды упадёт.
Они уверяют, что это всё очень эффективно и позволяет снизить вычислительные затраты. Ну, посмотрим. Я уже давно перестал верить красивым диаграммам. В любом случае, это очередная попытка выжать максимум из имеющегося железа. А железо, как известно, не вечно. Но зато красиво умирает.
LongBench: Почти Реальные Условия Эксплуатации
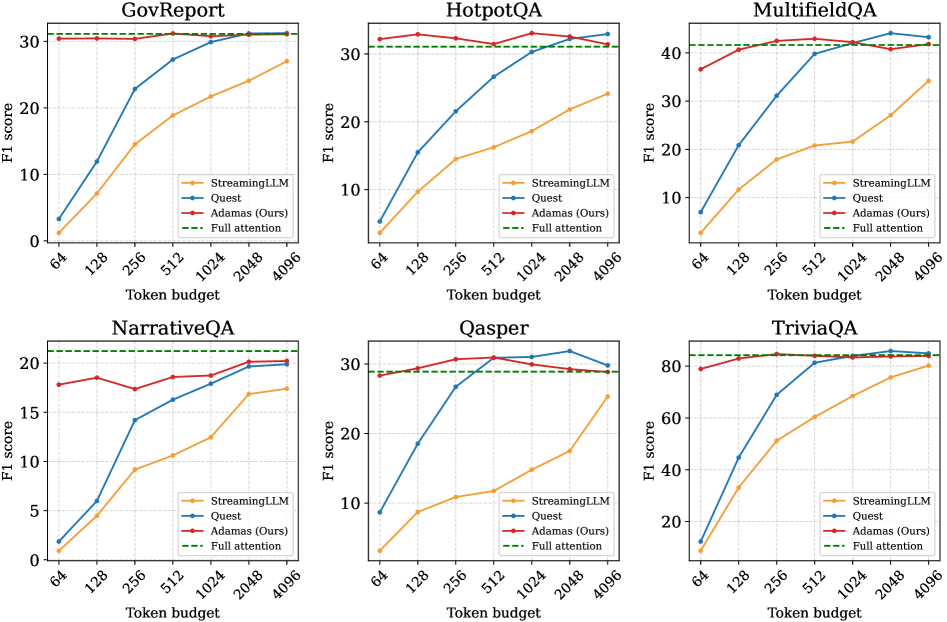
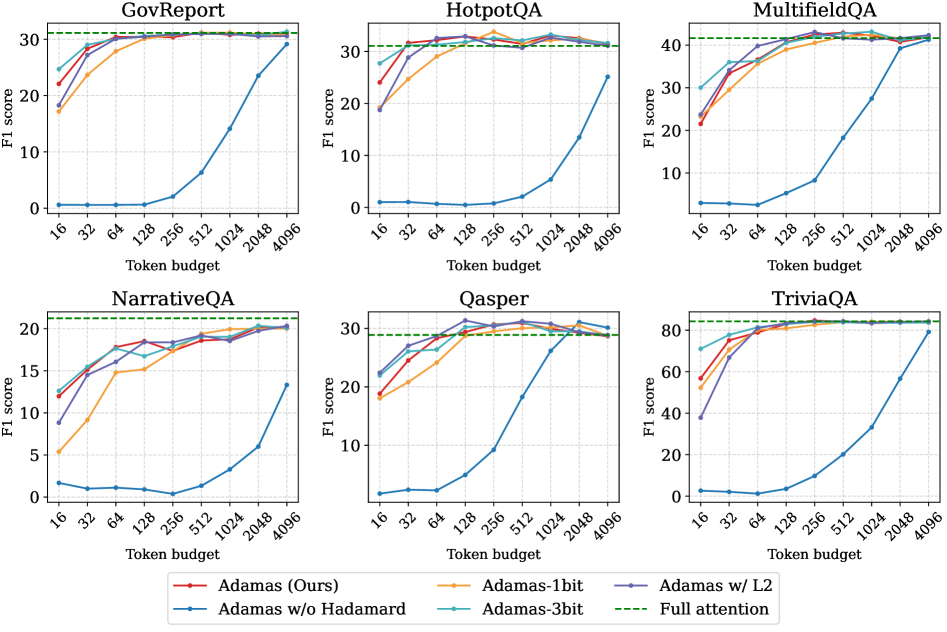
Итак, исследователи решили проверить Adamas на чём-то более сложном, чем синтетические тесты. Выбрали LongBench – этакий полигон для тех, кто утверждает, что их модель понимает длинные тексты. Понимает ли… ну, хотя бы пытается. Тестировали на всем, что там было: вопросы с ответами (Qasper, NarrativeQA, HotpotQA, MultiFieldQA), рефераты (GovReport), и даже на умение учиться по паре примеров (TriviaQA). В общем, на задачки, где нужно не просто прочитать текст, а ещё и подумать.
Результаты оказались предсказуемыми. Adamas, как ни странно, обошёл несколько других разреженных методов внимания, включая StreamingLLM и Quest. Что ж, хоть что-то работает как заявлено. Но самое интересное – Adamas показал вполне конкурентные результаты даже по сравнению с полномасштабным вниманием, реализованным, например, через FlashInfer. При этом, если верить графикам, ещё и работает быстрее. Конечно, все эти улучшения – лишь временное облегчение, и рано или поздно система всё равно упадёт под нагрузкой. Но пока что – неплохо.
Что касается конкретных цифр, то они, конечно, важны, но я бы не стал на них зацикливаться. Все эти бенчмарки – лишь приближение к реальным условиям эксплуатации. В продакшене всегда найдётся какой-нибудь краевой случай, который сломает все тесты. Но, судя по всему, Adamas действительно позволяет добиться некоторого улучшения производительности без значительной потери точности. Иногда этого достаточно, чтобы отсрочить неизбежное.
В общем, исследователи провели ожидаемые эксперименты и получили ожидаемые результаты. Надеюсь, они не слишком радуются этому успеху, потому что впереди ещё много работы. И помните: любая «революционная» технология завтра станет техдолгом.
За горизонтом бенчмарков: куда дальше?
Итак, очередная «революционная» технология. Что ж, авторы постарались, надо признать. Adamas, этот их механизм разреженного внимания, действительно снимает критическое узкое место при масштабировании больших языковых моделей. Всё больше данных, всё более сложные задачи… рано или поздно, даже самый мощный процессор начинает захлебываться. Здесь, похоже, они нашли способ облегчить нагрузку.
Использование преобразований Адамара и оценки расстояния Манхэттена… интересно. Вся эта гонка за оптимальной метрикой, за идеальным способом сравнить векторы… В очередной раз они доказывают, что не всегда нужно изобретать велосипед. Иногда, чтобы добиться улучшения, достаточно взглянуть на проблему под другим углом. Порой, даже самый простой способ оказывается самым эффективным.
Будущие исследования, как они пишут, будут сосредоточены на адаптивных шаблонах разреженности и интеграции Adamas с другими продвинутыми архитектурами языковых моделей. Звучит многообещающе, конечно. Но давайте не будем забывать, что в реальности всё немного сложнее. Любая, даже самая изящная схема, рано или поздно столкнётся с ограничениями аппаратного обеспечения, с непредсказуемостью пользовательских запросов, с неизбежными ошибками в коде.
В конечном счете, Adamas, если всё пойдёт по плану, позволит языковым моделям обрабатывать и понимать информацию в масштабах, которые ранее были недостижимы. Новые возможности в научных открытиях, в юридическом анализе, в творческом письме… звучит красиво. Но давайте помнить: инструмент – это всего лишь инструмент. Всё зависит от того, кто и как им пользуется. Впрочем, даже если всё пойдёт не совсем по плану, это всё равно будет полезный опыт. И еще один баг, который нужно исправить.
И да, еще один момент. Я уже вижу, как DevOps-инженеры будут ломать головы над тем, как это всё задеплоить в production. Мы не деплоим – мы отпускаем. И молимся, чтобы ничего не сломалось.
Исследование, представленное авторами, как обычно, пытается решить проблему масштабируемости внимания в больших языковых моделях. Они предлагают Adamas, основанный на Хадамард-преобразовании и квантовании. Звучит элегантно, но стоит помнить, что каждая «революционная» технология завтра станет техдолгом. Как говорил Карл Фридрих Гаусс: «Если бы я должен был выбрать одно число для описания моего метода, я бы выбрал ноль.» Гаусс, конечно, говорил о математике, но в контексте Adamas это напоминает о необходимости постоянно упрощать и отбрасывать избыточность. Авторы фокусируются на снижении вычислительной сложности, что, безусловно, важно, но в конечном итоге, всё упирается в то, как это решение будет работать в реальном продакшене. Посмотрим, как долго продлится этот «нулевой» этап.
Что дальше?
Исследователи представили Adamas – ещё одну попытку обуздать экспоненциальную сложность внимания в больших языковых моделях. Очевидно, что каждый новый «разреженный» механизм внимания – это, по сути, переизобретение костыля, замаскированное под элегантную математику. Хвалить Adamas за эффективность – всё равно что восхищаться инженером, который нашёл способ заставить «Запорожец» ехать быстрее «Роллс-Ройса» по бездорожью. Да, задача решена, но вопрос остаётся: зачем нам ещё больше «разреженных» моделей, когда большинство задач не требуют столь сложных вычислений?
Очевидные направления дальнейших исследований включают в себя оптимизацию Hadamard-преобразований для специфического оборудования и снижение вычислительных издержек, связанных с квантованием. Однако, истинный вызов заключается не в улучшении алгоритмов, а в признании того, что мы переоцениваем потребность в контексте огромной длины. Скорее всего, прод найдет способ сломать элегантность Adamas, заставив модель обрабатывать неструктурированные данные или запросы, которые не поддаются разрежению.
Нам не нужно больше разреженных механизмов внимания – нам нужно меньше иллюзий о том, что «больше» всегда означает «лучше». И, вероятно, через пять лет Adamas станет анекдотом, очередным пунктом в длинном списке архитектур, которые когда-то казались революционными.
Оригинал статьи: https://arxiv.org/pdf/2510.18413.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/